【深度学习RNN/LSTM中文讲义】循环神经网络详解,复旦邱锡鹏老师《神经网络与深度学习》报告分享03(附pdf下载)
点击上方“专知”关注获取专业AI知识!

【导读】复旦大学副教授、博士生导师、开源自然语言处理工具FudanNLP的主要开发者邱锡鹏(http://nlp.fudan.edu.cn/xpqiu/)老师撰写的《神经网络与深度学习》书册,是国内为数不多的深度学习中文基础教程之一,每一章都是干货,非常精炼。邱老师在今年中国中文信息学会《前沿技术讲习班》做了题为《深度学习基础》的精彩报告,报告非常精彩,深入浅出地介绍了神经网络与深度学习的一系列相关知识,基本上围绕着邱老师的《神经网络与深度学习》一书进行讲解。专知希望把如此精华知识资料分发给更多AI从业者,为此,专知特别联系了邱老师,获得他的授权同意分享。邱老师特意做了最新更新版本,非常感谢邱老师!专知内容组围绕邱老师的讲义slides,进行了解读,请大家查看,并多交流指正! 此外,请查看本文末尾,可下载最新神经网络与深度学习的slide。
既昨天给大家带来了复旦邱锡鹏老师《神经网络与深度学习》讲义报告分享01,和 复旦邱锡鹏老师《神经网络与深度学习》讲义报告分享02 今天继续为大家带来基础模型这一部分。
邱老师的报告内容分为三个部分:
概述
机器学习概述
线性模型
应用
基础模型
前馈神经网络
卷积神经网络
循环神经网络
网络优化与正则化
应用
进阶模型
记忆力与注意力机制
无监督学习
概率图模型
深度生成模型
深度强化学习
模型独立的学习方式
哈工大在事理图谱方面的探索
【特此注明】本报告材料获邱锡鹏老师授权发布,由于笔者能力有限,本篇所有备注皆为专知内容组成员通过根据报告记录和PPT内容自行补全,不代表邱锡鹏老师本人的立场与观点。
邱老师个人主页: http://nlp.fudan.edu.cn/xpqiu/
课程Github主页:https://nndl.github.io/
神经网络与深度学习

开始介绍循环神经网络。

在前馈神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力。在生物神经网络中,神经元之间的连接关系要复杂的多。前馈神经网络可以看着是一个复杂的函数,每次输入都是独立的,即网络的输出只依赖于当前的输入。但是在很多现实任务中,网络的输入不仅和当前时刻的输入相关,也和其过去一段时间的输出相关。比如一个有限状态自动机,其下一个时刻的状态(输出)不仅仅和当前输入相关,也和当前状态(上一个时刻的输出)相关。前馈网络是一个静态网络,明显不能不处理这种情况。此外,序列数据的长度一般是不固定的,比如视频、语音、文本等。而前馈神经网络要求输入和输出的维数都是固定的,不能任意改变。因此,当处理这一类和时序相关的问题时,就需要一种能力更强的模型。

循环神经网络循环神经网络(Recurrent NeuralNetworks,RNN)通过使用带自反馈的神经元,能够处理任意长度的序列。RNN也经常被翻译为递归神经网络。这里为了区别与另外一种递归神经网络(RecursiveNeural Networks),我们称为循环神经网络。
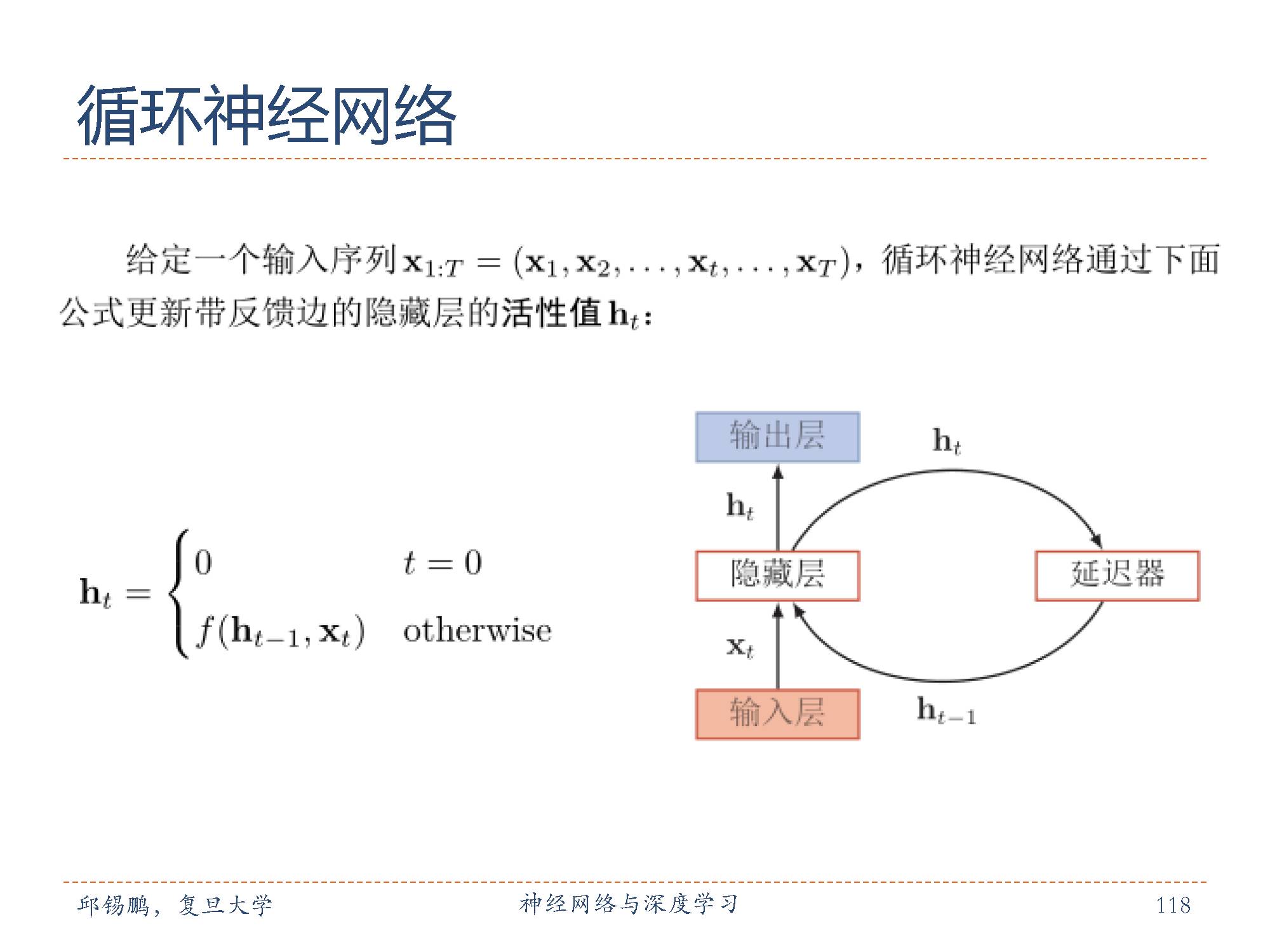
从数学上讲,公式可以看成一个动态系统。动态系统(dynamical system)是一个数学上的概念,指系统状态按照一定的规律随时间变化的系统。具体地讲,动态系统是使用一个函数来描述一个给定空间(如某个物理系统的状生活中很多现象都可以态空间)中所有点随时间的变化情况。因此,隐藏层的活性值ht 在很多文献上动态系统来描述,比如钟摆晃动、台球轨迹等。也称为状态(state)或隐状态(hidden states)。理论上循环神经网络可以近似任意的非线性动态系统。
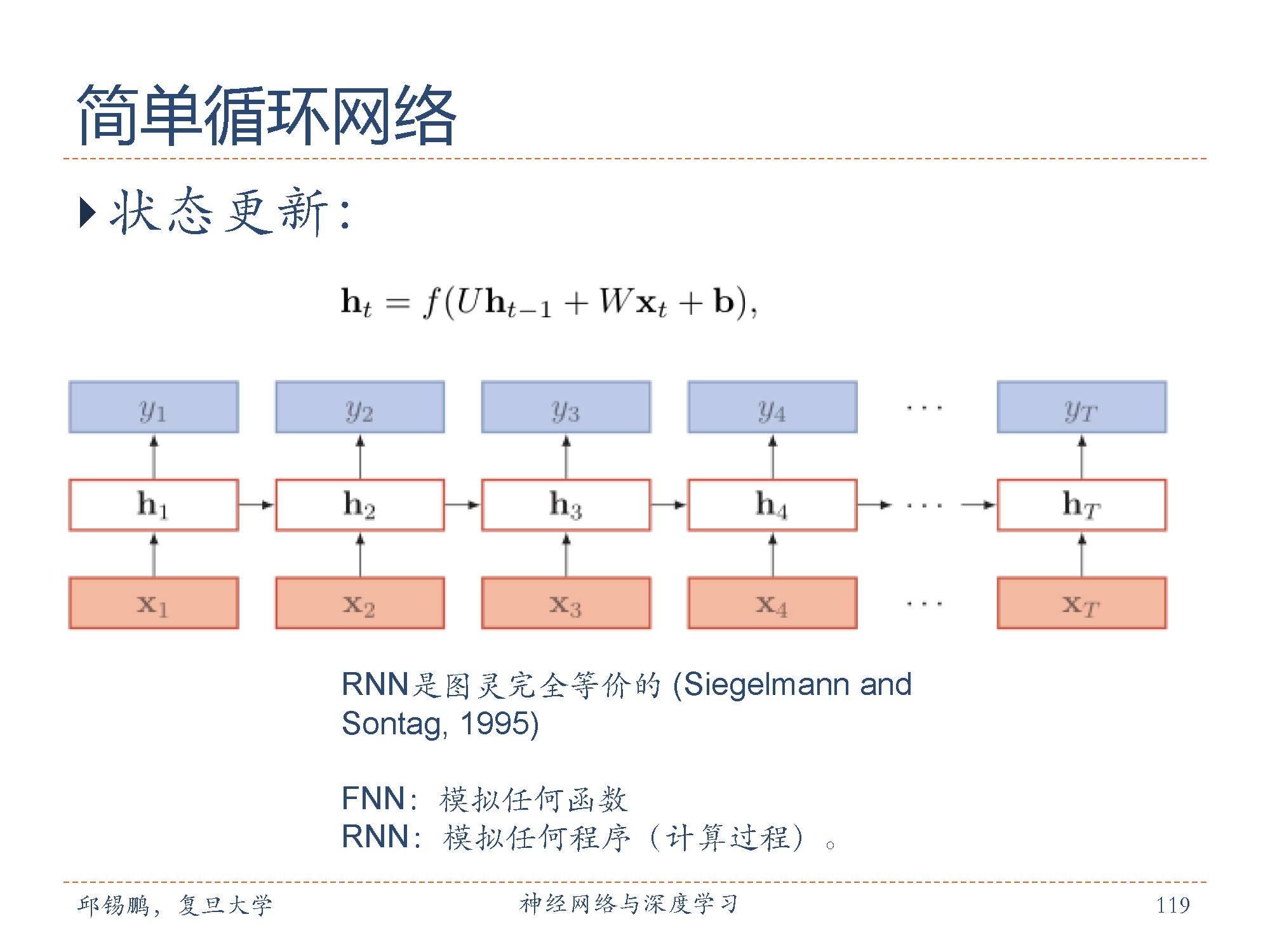
如果我们把每个时刻的状态都看作是前馈神经网络的一层的话,循环神经网络可以看作是在时间维度上权值共享的神经网络。图中给出了按时间展开的循环神经网络。

循环神经网络可以应用到很多不同类型的机器学习任务。根据这些任务的特点可以分为以下多种模式
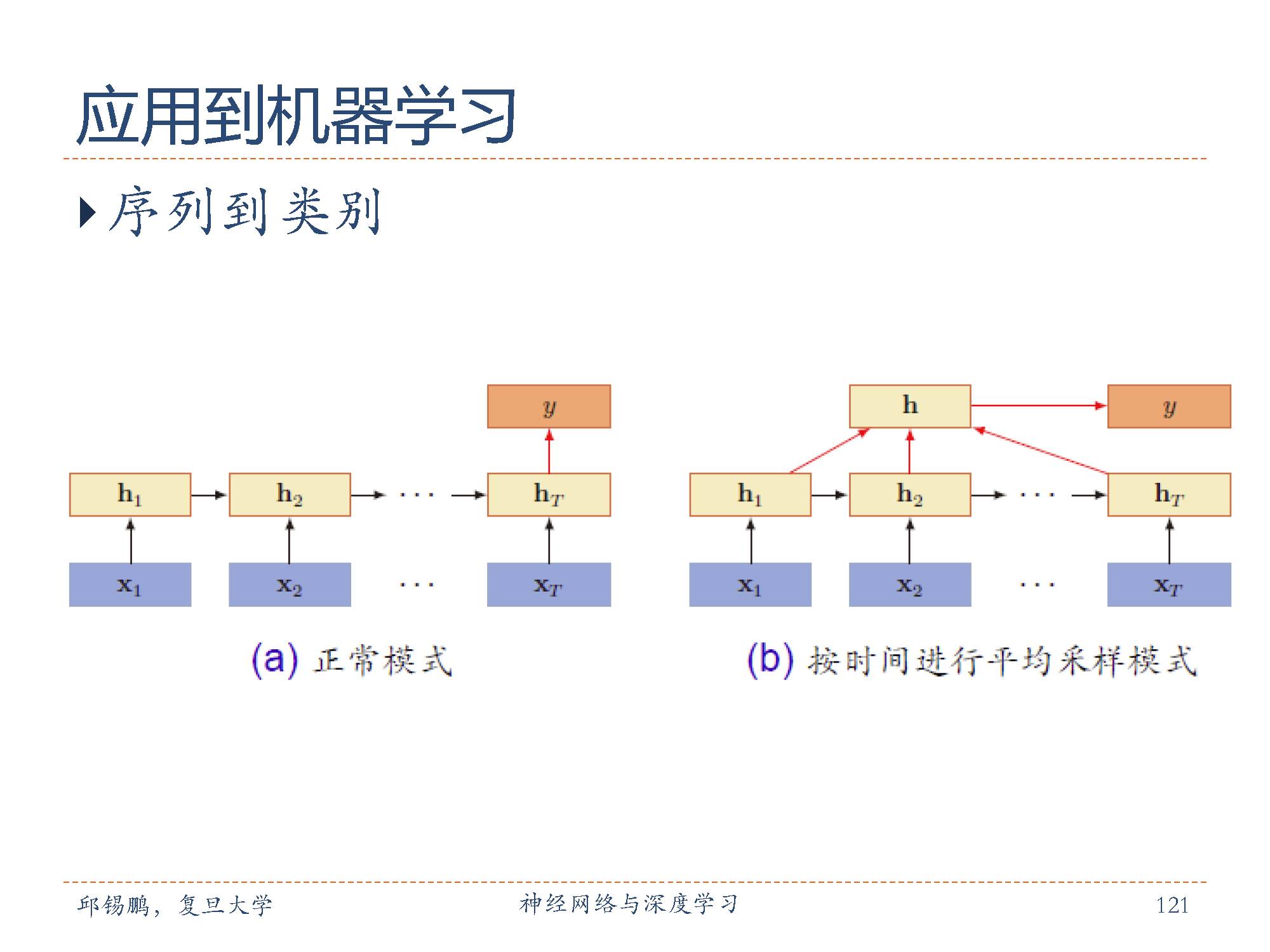
序列到类别模式:这种模式就是序列数据的分类问题。输入为序列,输出为类别。比如在文本分类中,输入数据为单词的序列,输出为该文本的类别。
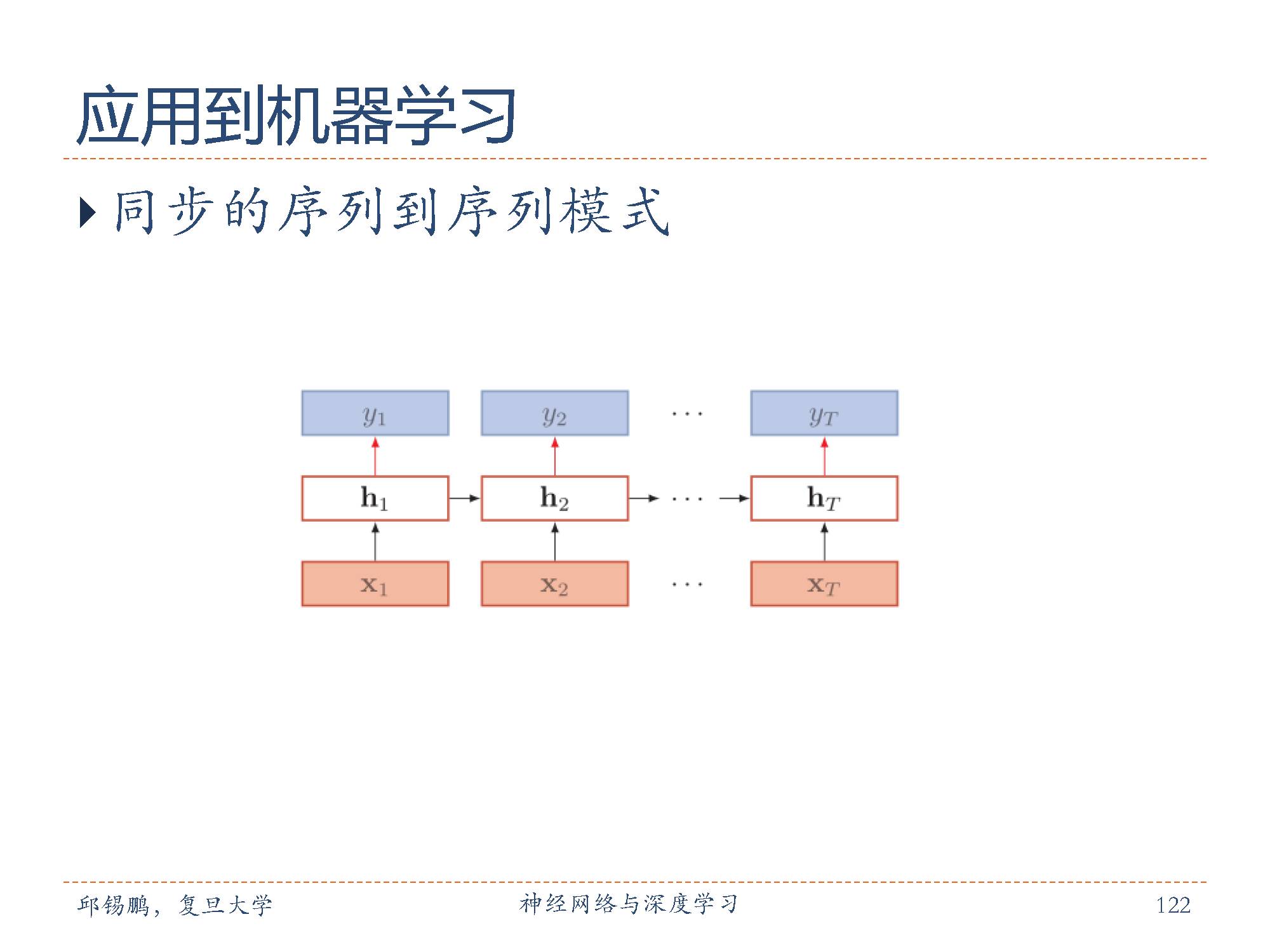
这种模式就是机器学习中的序列标注(Sequence Labeling)任务,即每一时刻都有输入和输出,输入序列和输出序列的长度相同。比如词性标注(Part-of-Speech Tagging)中,每一个单词都需要标注其对应的词性标签。
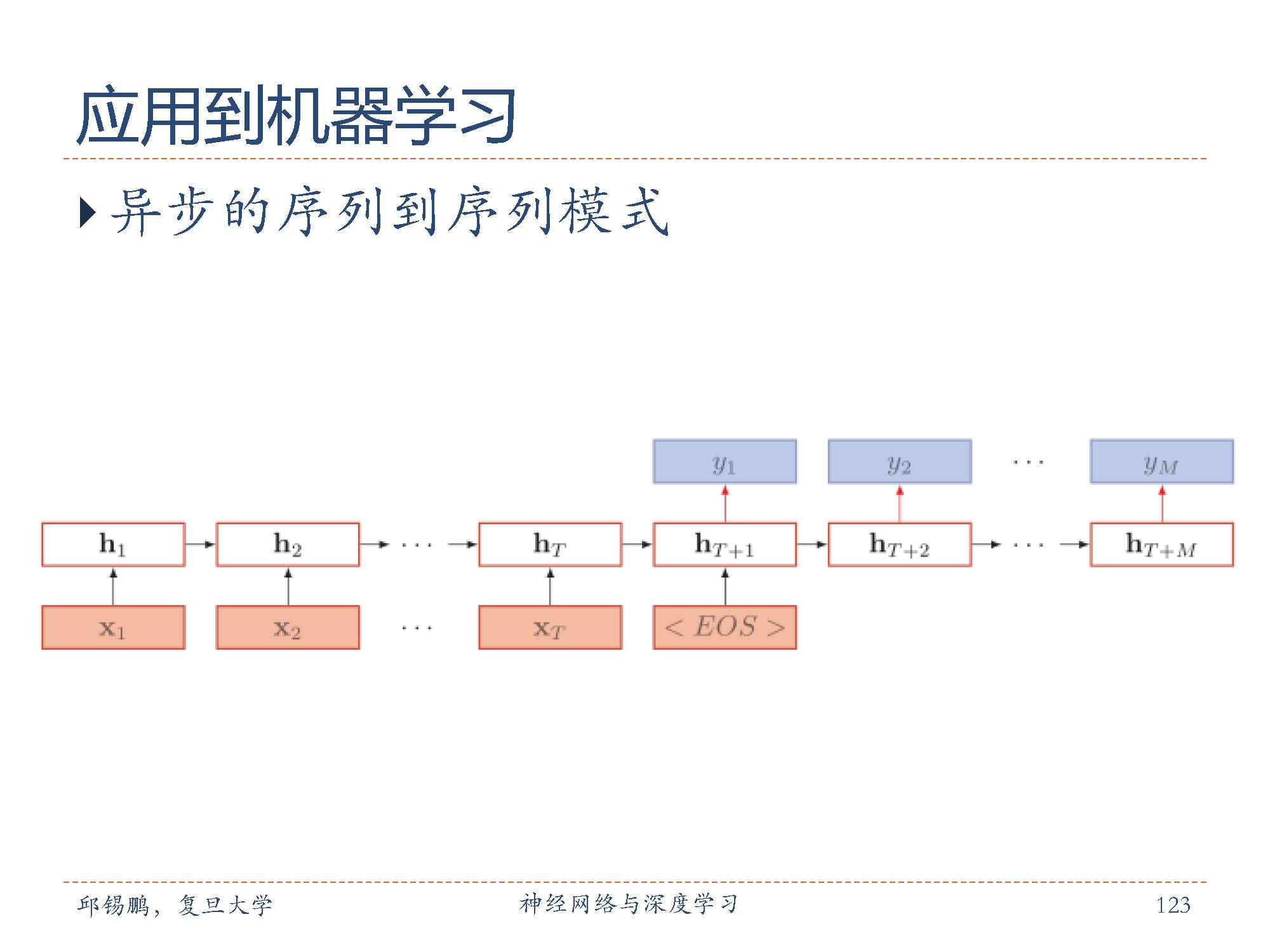
这种模式也称为编码器-解码器(EncoderDecoder)模型,即输入和输出不需要有严格的对应关系,也不需要保持相同的长度。比如在机器翻译中,输入为源语言的单词序列,输出为目标语言的单词序列。

循环神经网络的参数可以通过梯度下降方法来进行学习。循环神经网络中存在一个递归调用的函数 f(·),因此其计算参数梯度的方式和前馈神经网络不同不太相同。在循环神经网络中主要有两种计算梯度的方式:随时间反向传播(BPTT)和实时循环学习(RTRL)算法。
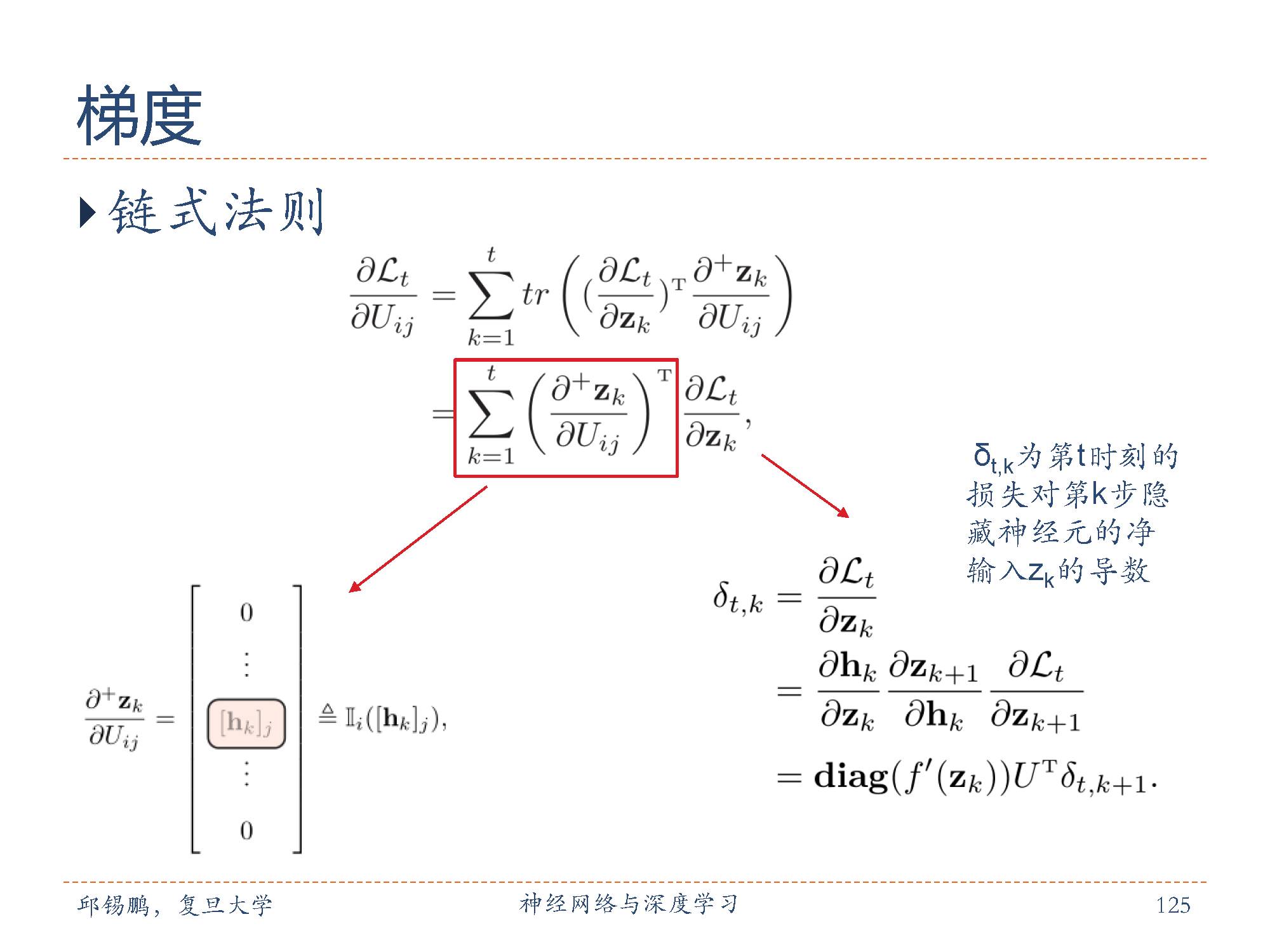
下面开始介绍链式法则
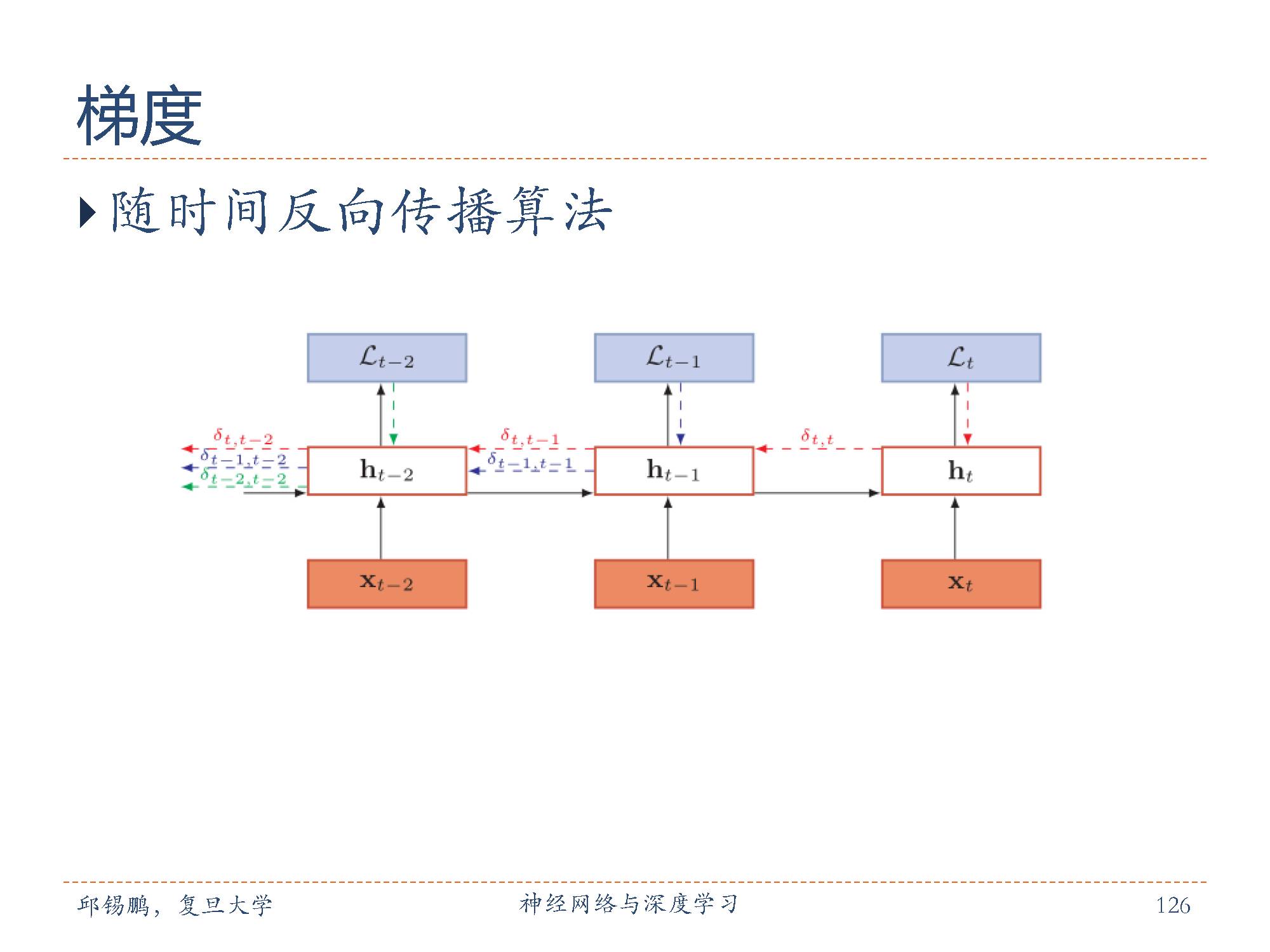
随时间反向传播(backpropagationthrough time,BPTT)算法的主要思想是通过类似前馈神经网络的错误反向传播算法 [Werbos, 1990] 来进行计算梯度。 BTPP算法将循环神经网络看作是一个展开的多层前馈网络,其中“每一层”对应循环网络中的“每个时刻”。这样,循环神经网络就可以按按照前馈网络中的反向传播算法进行计算参数梯度。在“展开”的前馈网络中,所有层的参数是共享的,因此参数的真实梯度是将所有“展开层”的参数梯度之和。

一般而言,循环网络的梯度爆炸问题比较容易解决,一般通过权重衰减或梯度截断来避免。梯度消失是循环网络的主要问题。除了使用一些优化技巧外,更有效的方式就是改变模型。

虽然简单循环网络从理论上可以建立长时间间隔的状态之间的依赖关系,但是由于梯度爆炸或消失问题,实际上只能学习到短期的依赖关系。这就是长期依赖问题(Long-Term Dependencies Problem)。

改变模型变形方式。
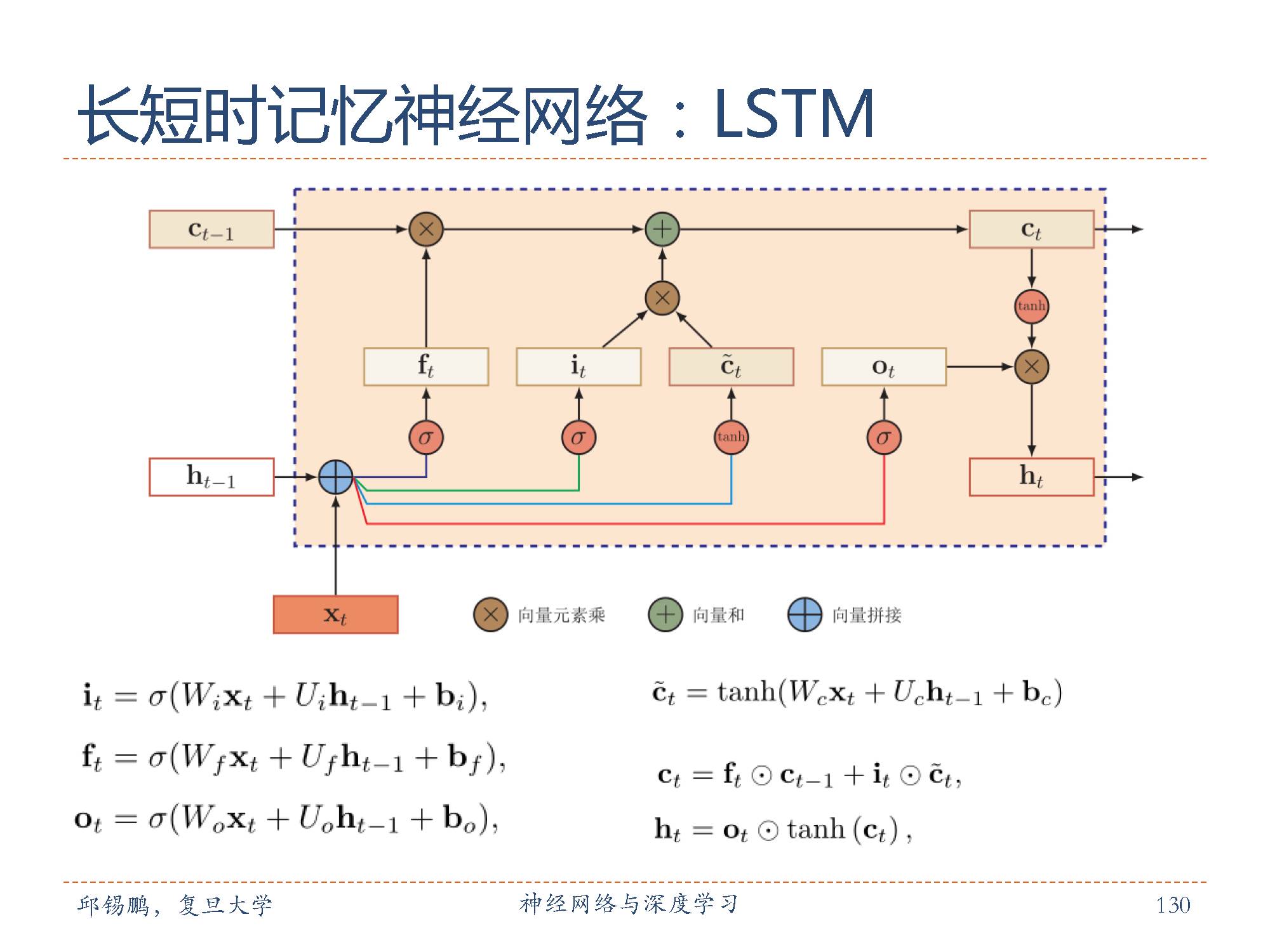
长短期记忆(Long Short-Term Memory,LSTM)网络[Gers et al.,2000, Hochreiter and Schmidhuber, 1997]是循环神经网络的一个变体,可以有效地解决简单循环神经网络的梯度爆炸或消失问题。

LSTM网络引入门机制(Gating Mechanism)来控制信息传递的路径。目前主流的LSTM网络用的三个门来动态地控制内部状态的应该遗忘多少历史信息,输入多少新信息,以及输出多少信息。
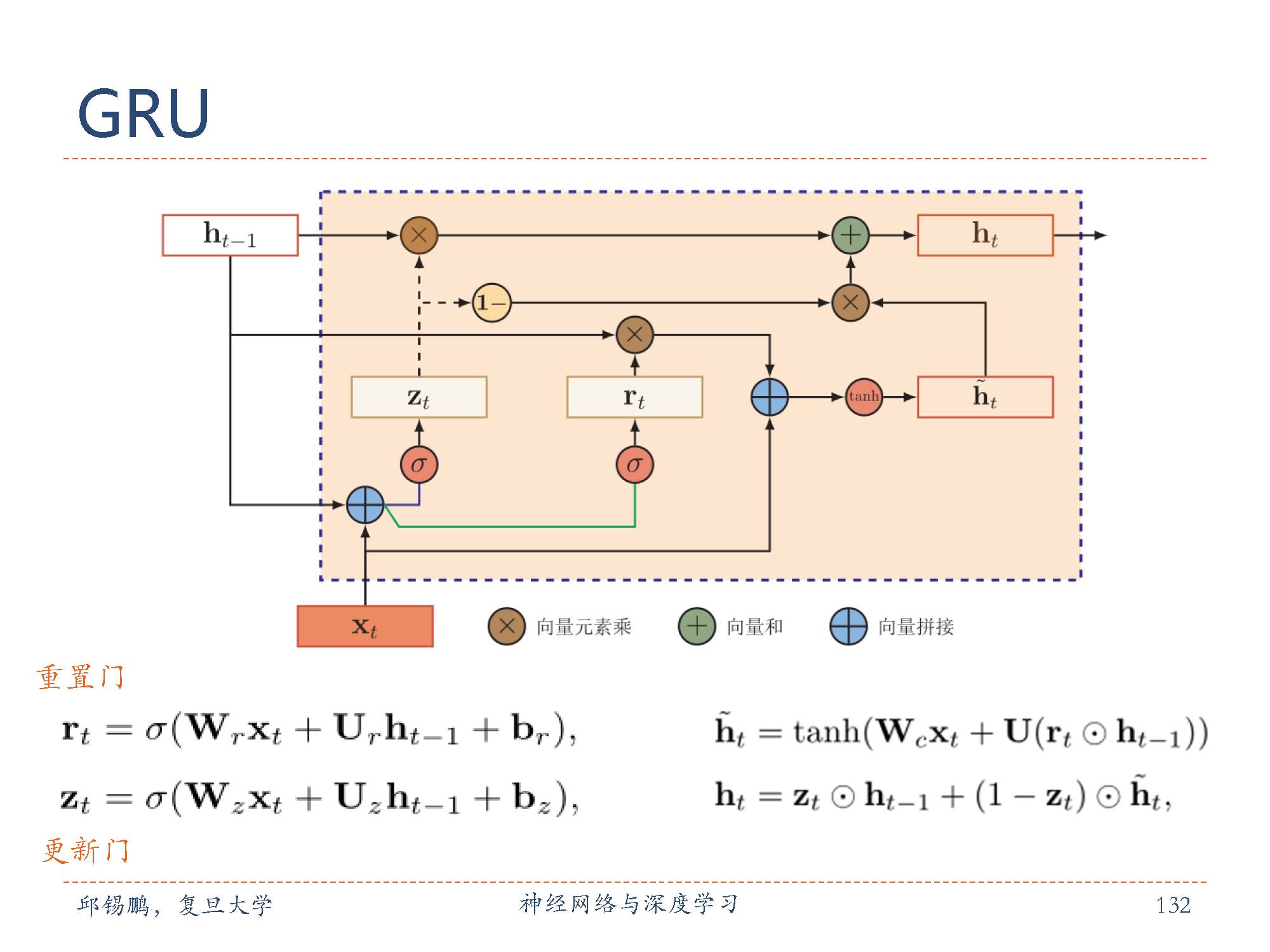
门控制循环单元(gated recurrent unit,GRU)网络 [Cho et al.,2014, Chung et al., 2014]是一种比LSTM网络更加简单的循环神经网络。GRU也是 引入门机制来控制信息更新的方式。在 LSTM网络中,输入门和遗忘门是互补关系,用两个门比较冗余。GRU将输入门与和遗忘门合并成一个门:更新门(Update Gate)。同时,GRU也不引入额外的记忆单元,直接在当前状态ht 和历史状态ht−1 之间引入线性依赖关系。
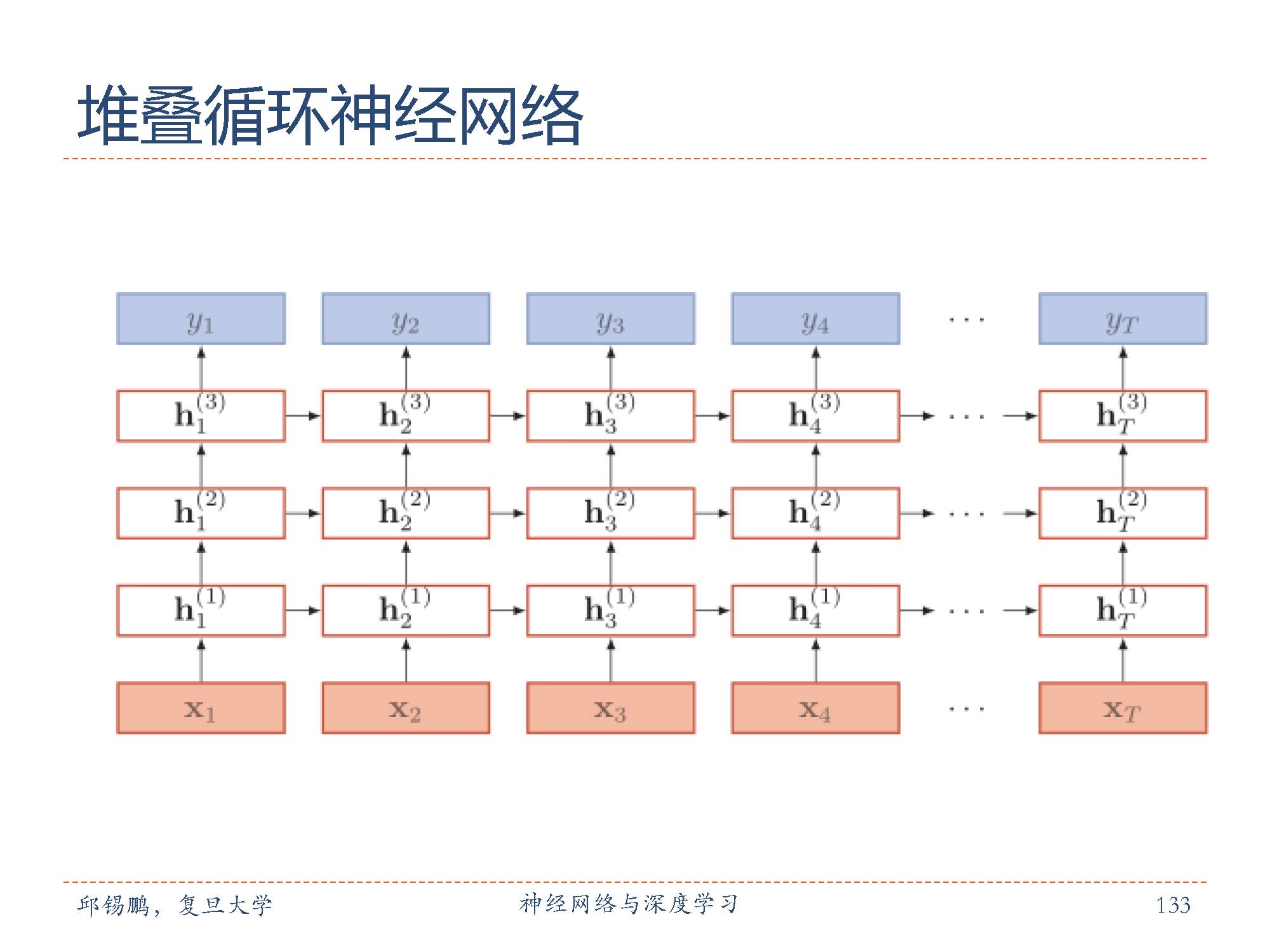
按时间展开的堆叠循环神经网络。第l 层网络的输入是第l − 1 层网络的输出。
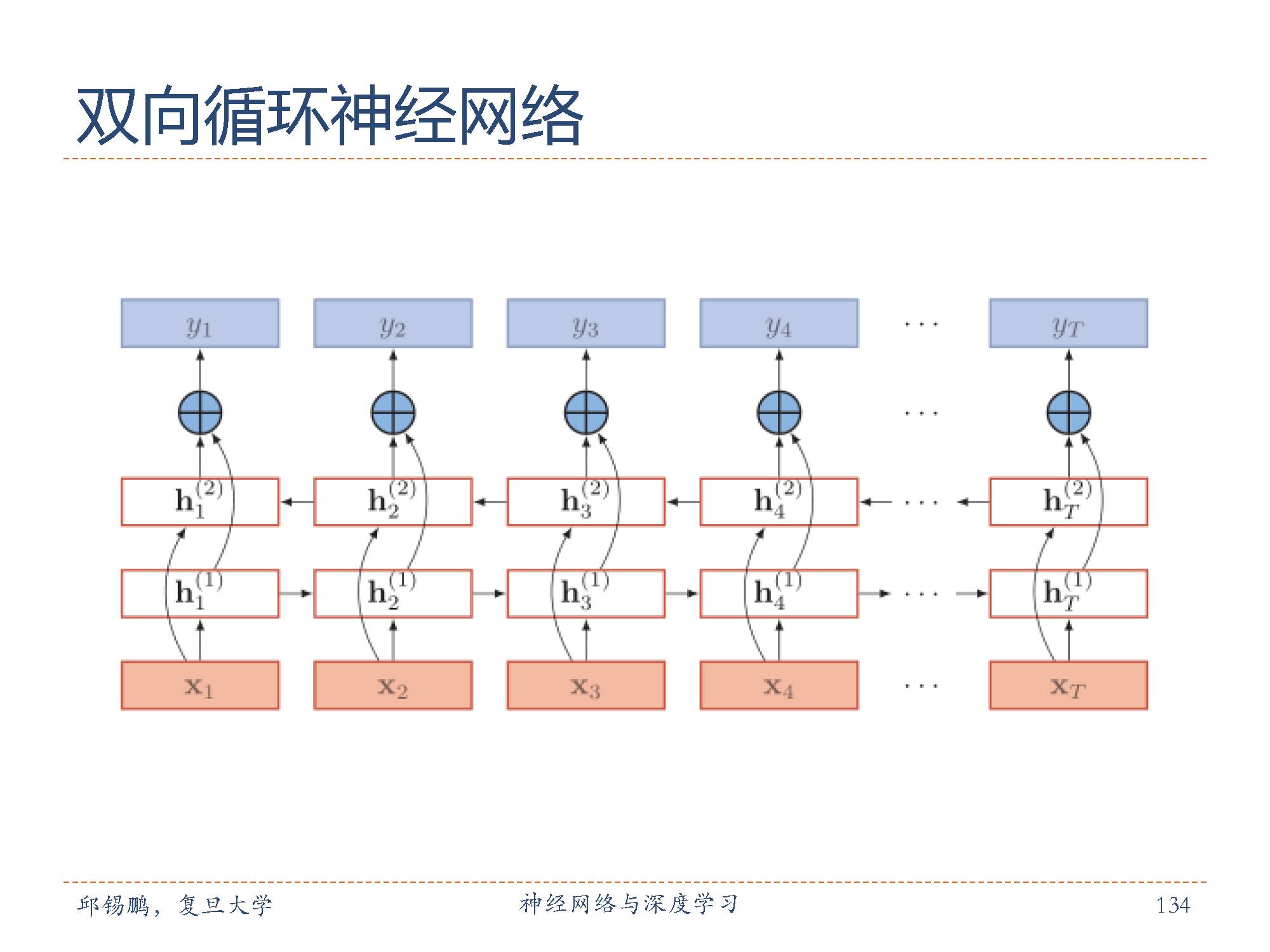
在有些任务中,一个时刻的输出不但和过去时刻的信息有关,也和后续时刻的信息有关。比如给定一个句子,其中一个词的词性由它的上下文决定,即包含左右两边的信息。因此,在这些任务中,我们可以增加一个按照时间的逆序来传递信息的网络层,来增强网络的能力。双向循环神经网络(Bidirectional Recurrent Neural Network,Bi-RNN)由两层循环神经网络组成,它们的输入相同,只是信息传递的方向不同。
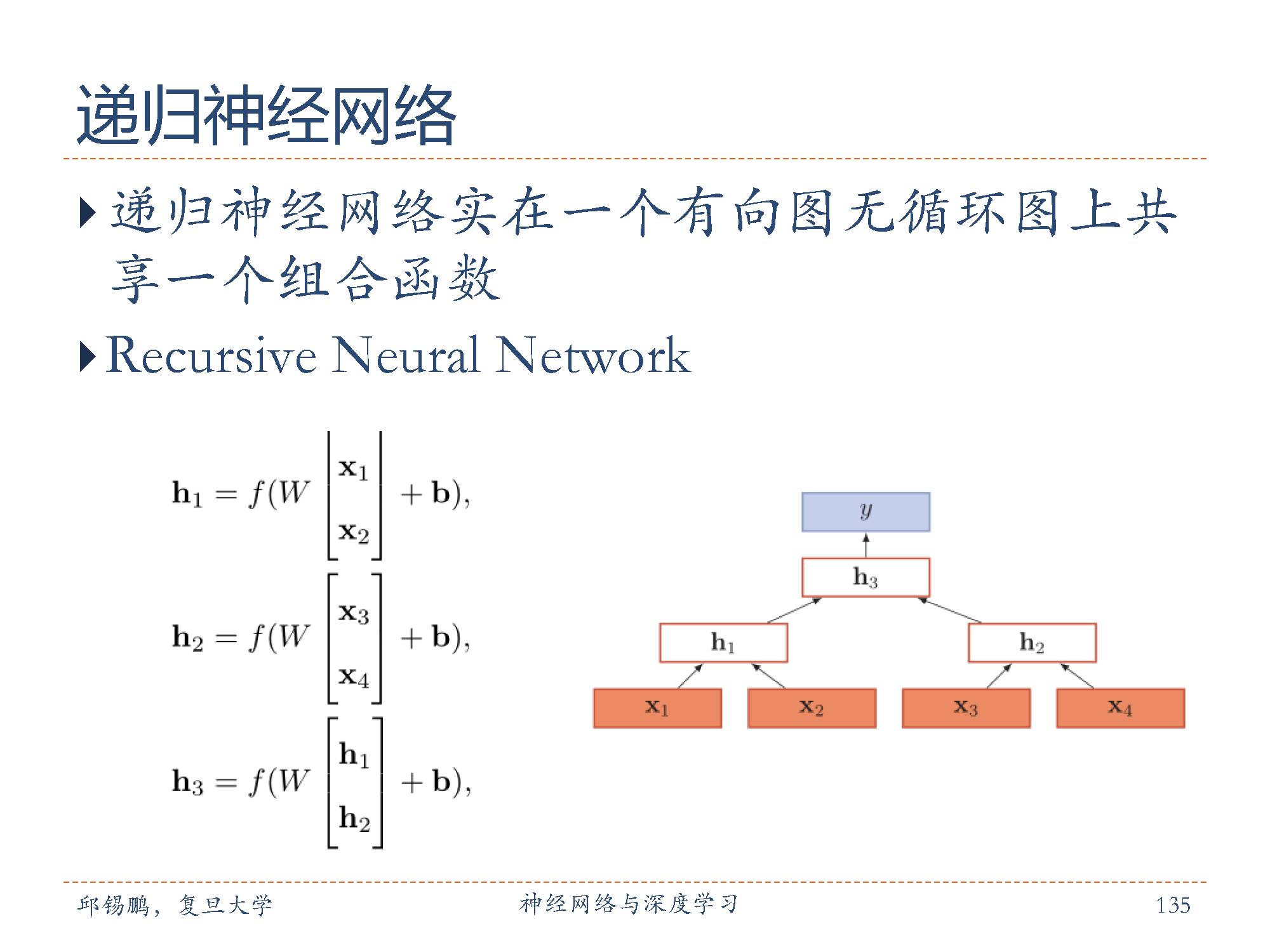
下面开始介绍递归神经网络
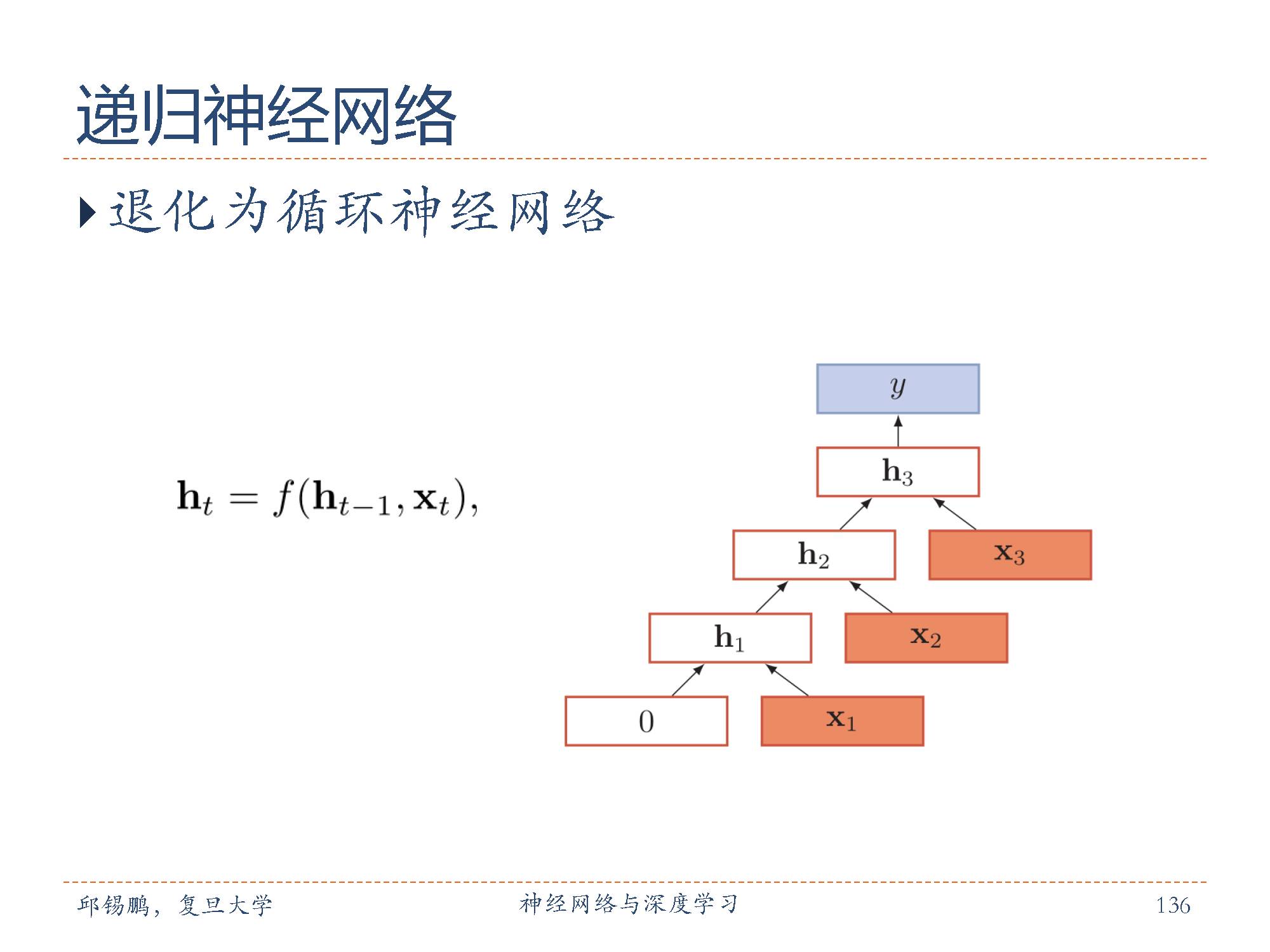
递归神经网络(Recursive Neural Network,RNN或RecNN)是循环神经网络的扩展。如果把循环神经网络展开,可以看作是在时序维度上共享一个组合函数,而递归神经网络实在一个有向图无循环图上共享一个组合函数 [Pollack, 1990]。递归神经网络的一般结构为层次结构。
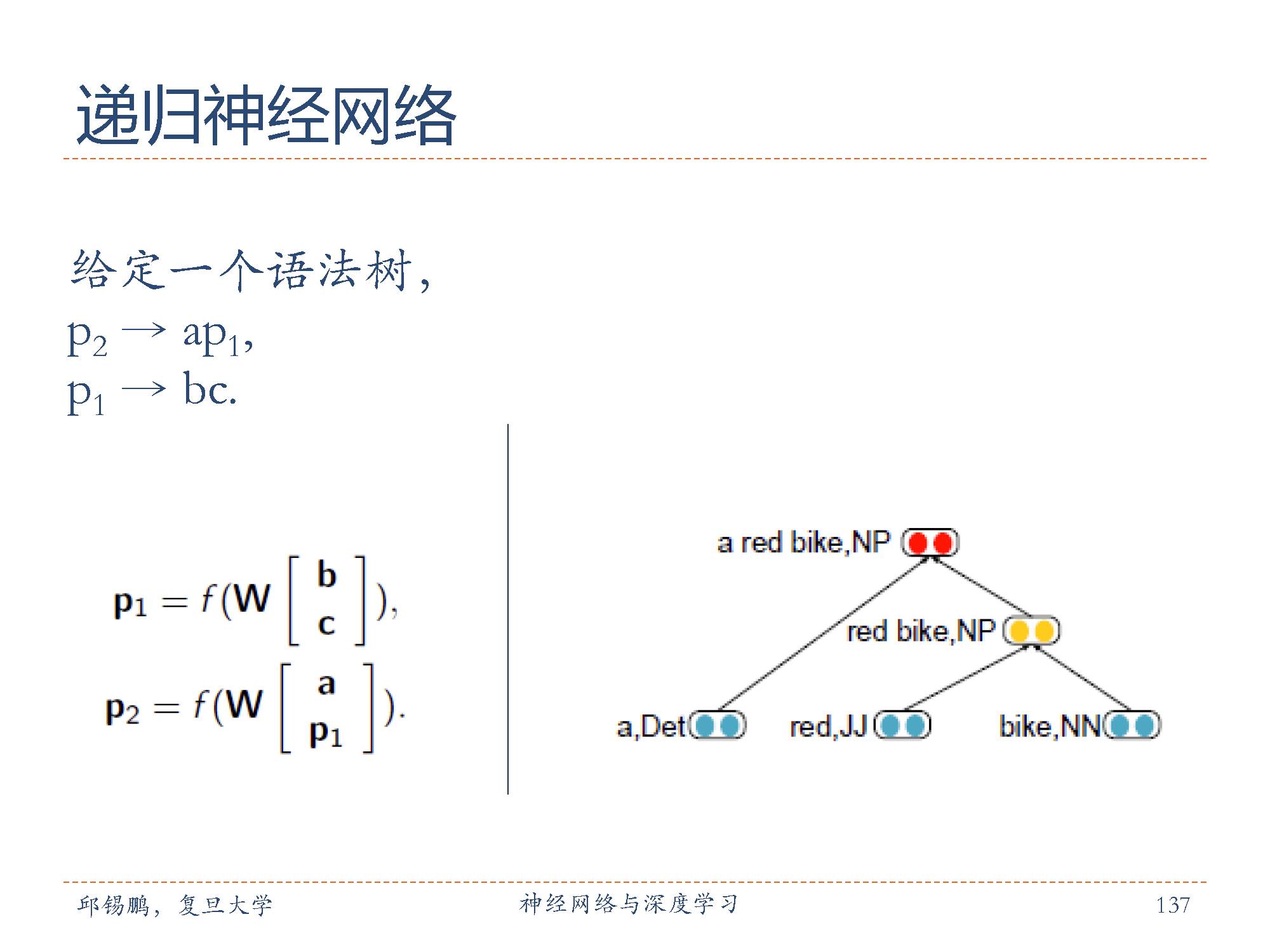
递归神经网络主要用来建模自然语言句子的语义[Socher et al., 2011, 2013]。给定一个句子的语法结构(一般为树状结构),可以使用递归神经网络来按照句法的组合关系来合成一个句子的语义。句子中每个短语成分可以在分成一些子成分,即每个短语的语义都可以由它的子成分语义组合而来,并进而合成整句的语义。

下面开始讲循环网络的应用。
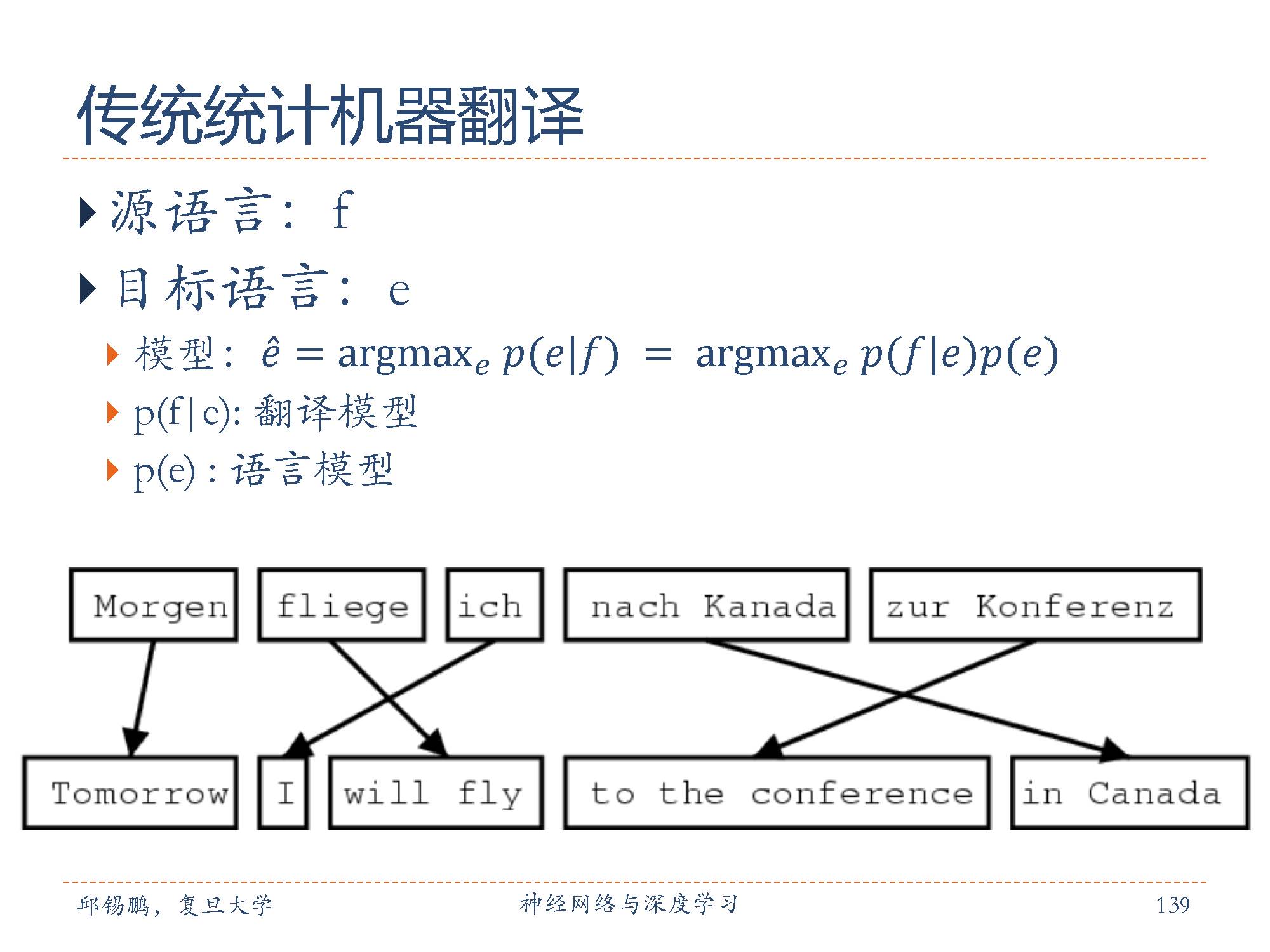
统计机器翻译(Statistical Machine Translation, SMT)是指基于统计学习模型的机器翻译方法,随着九十年代初基于统计学习的IBM统计机器翻译模型的提出以来,早期从基于单词的模型转向基于短语的模型,本世纪初逐渐扩展到基于句法的翻译建模,目前发展到基于语义的翻译模型和基于神经元网络的翻译模型,逐渐取代了传统基于手写规则的方法,成为目前学术界和工业界机器翻译研究的主流方法。
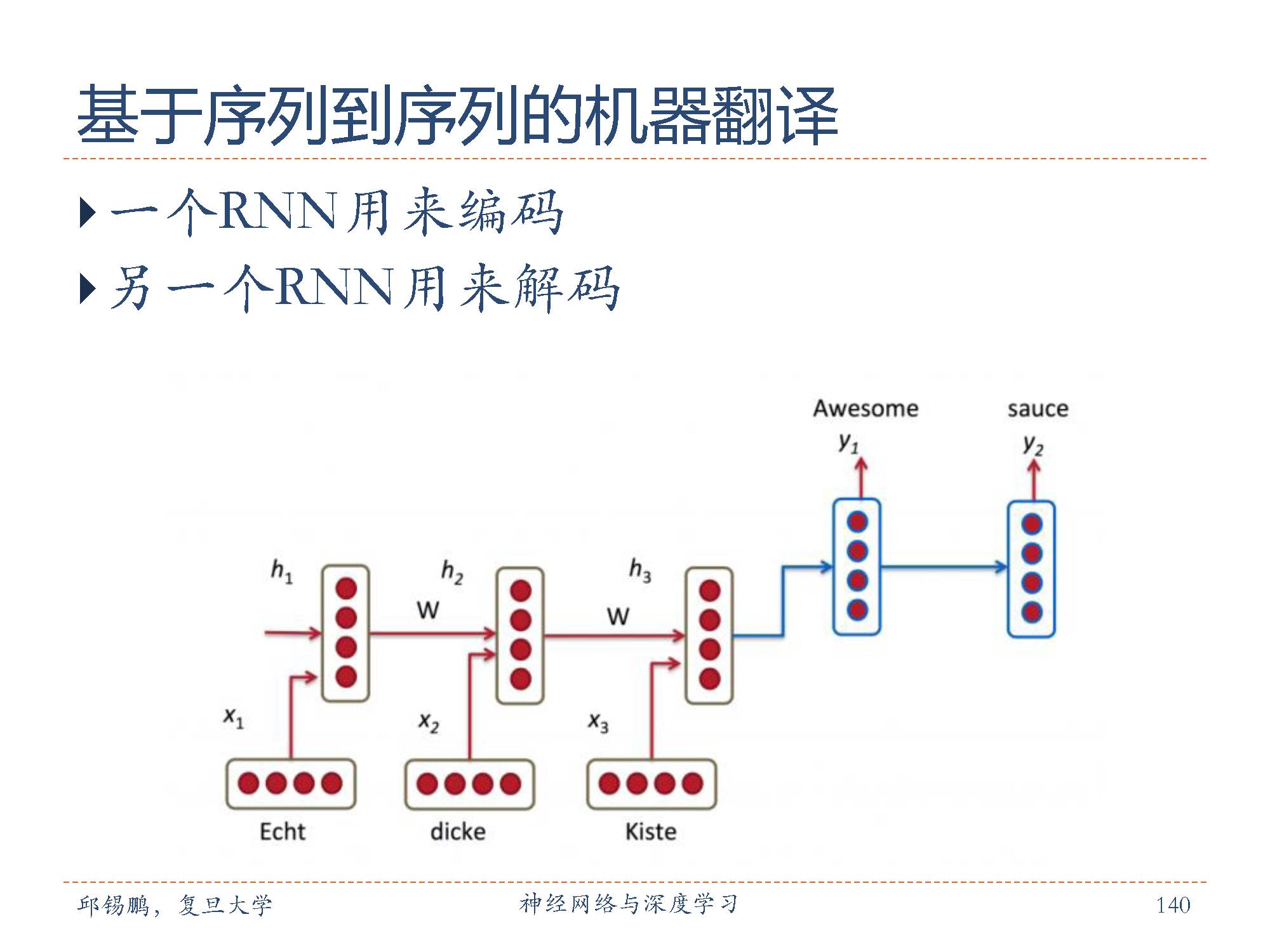
序列到序列的翻译并不依赖翻译规则及各类特征的定义,因此更适合利用机器学习技术自动获取隐含表示(如向量表示),进而利用这种表示直接进行翻译建模。

利用cnn对图像进行编码,紧接着用RNN输出文本描述图片。


基于RNN字符级别的语言模型

RNN语言模型

RNN语言模型

RNN语言模型

RNN语言模型通过Trunp的历史twitter信息,自动生成符合其语气的推文。

虽然神经网络具有非常强的表达能力,但是当应用神经网络模型到机器学习时依然存在一些难点。主要分为两大类:(1)优化问题:神经网络模型是一个非凸函数,再加上在深度网络中的梯度消失问题,很难进行优化;另外,深度神经网络模型一般参数比较多,训练数据也比较大,会导致训练的效率比较低。(2)泛化问题:因为神经网络的拟合能力强,反而容易在训练集上产生过拟合。因此,在训练深度神经网络时,同时也需要掌握一定的技巧。目前,人们在大量的实践中总结了一些经验技巧,从优化和正则化两个方面来提高学习效率并得到一个好的网络模型。
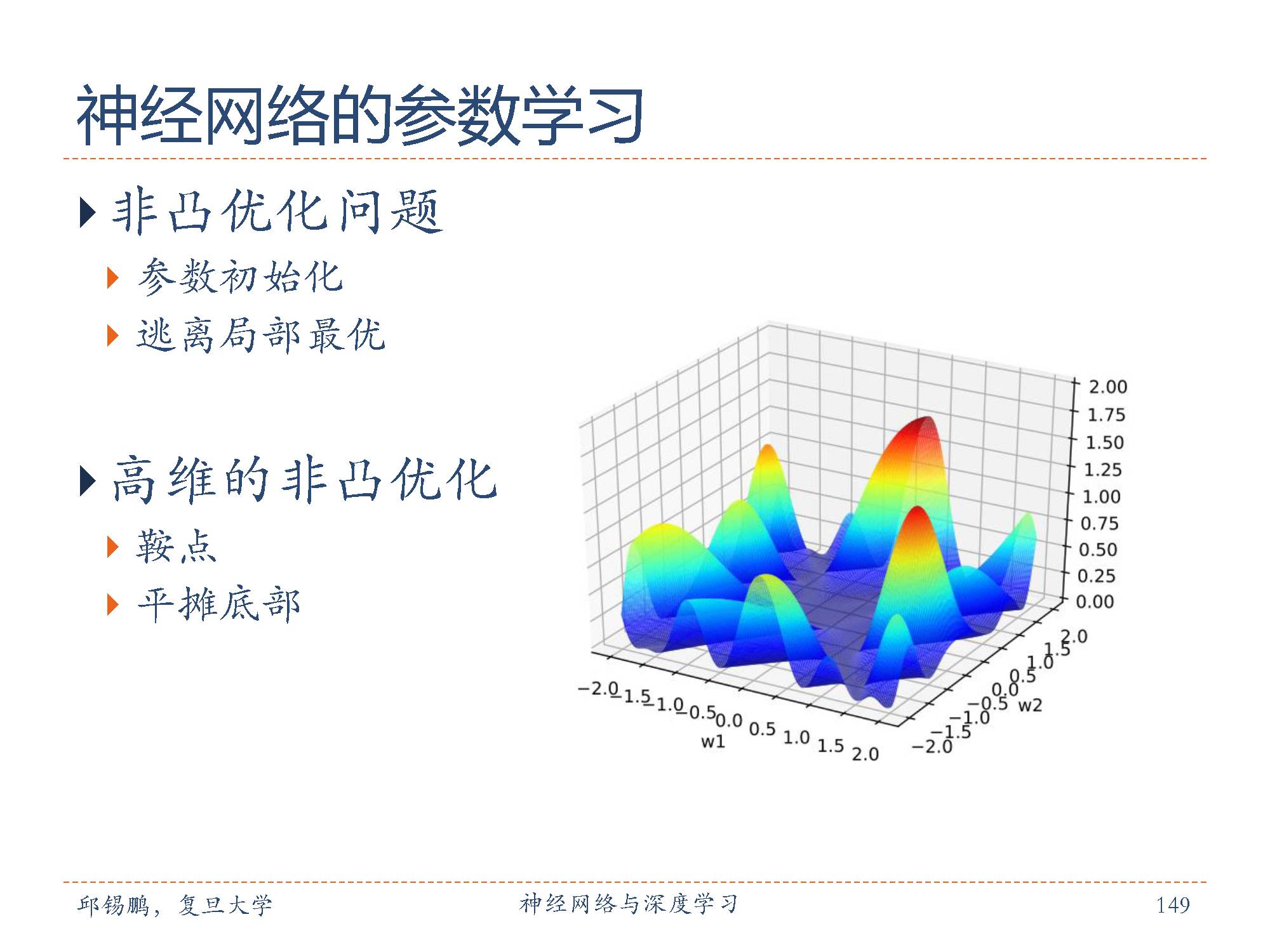
深度神经网络的参数非常多,其参数学习是在非常高维空间中的非凸优化问题,其挑战和在低维空间的非凸优化问题有所不同。低维空间的非凸优化问题主要是存在一些局部最优点。采用梯度下降方法时,不合适的参数初始化会导致陷入局部最优点,因此主要的难点是如何选择初始化参数和逃离局部最优点。

神经网络的训练过程中的参数学习是基于梯度下降法进行优化的。梯度下降法需要在开始训练时给每一个参数赋一个初始值。这个初始值的选取十分关键。在感知器和logistic回归的训练中,我们一般将参数全部初始化为0。但是这在神经网络的训练中会存在一些问题。因为如果参数都为 0,在第一遍前向计算时,所有的隐层神经元的激活值都相同。这样会导致深层神经元没有区分性。这种现象也称为对称权重现象。
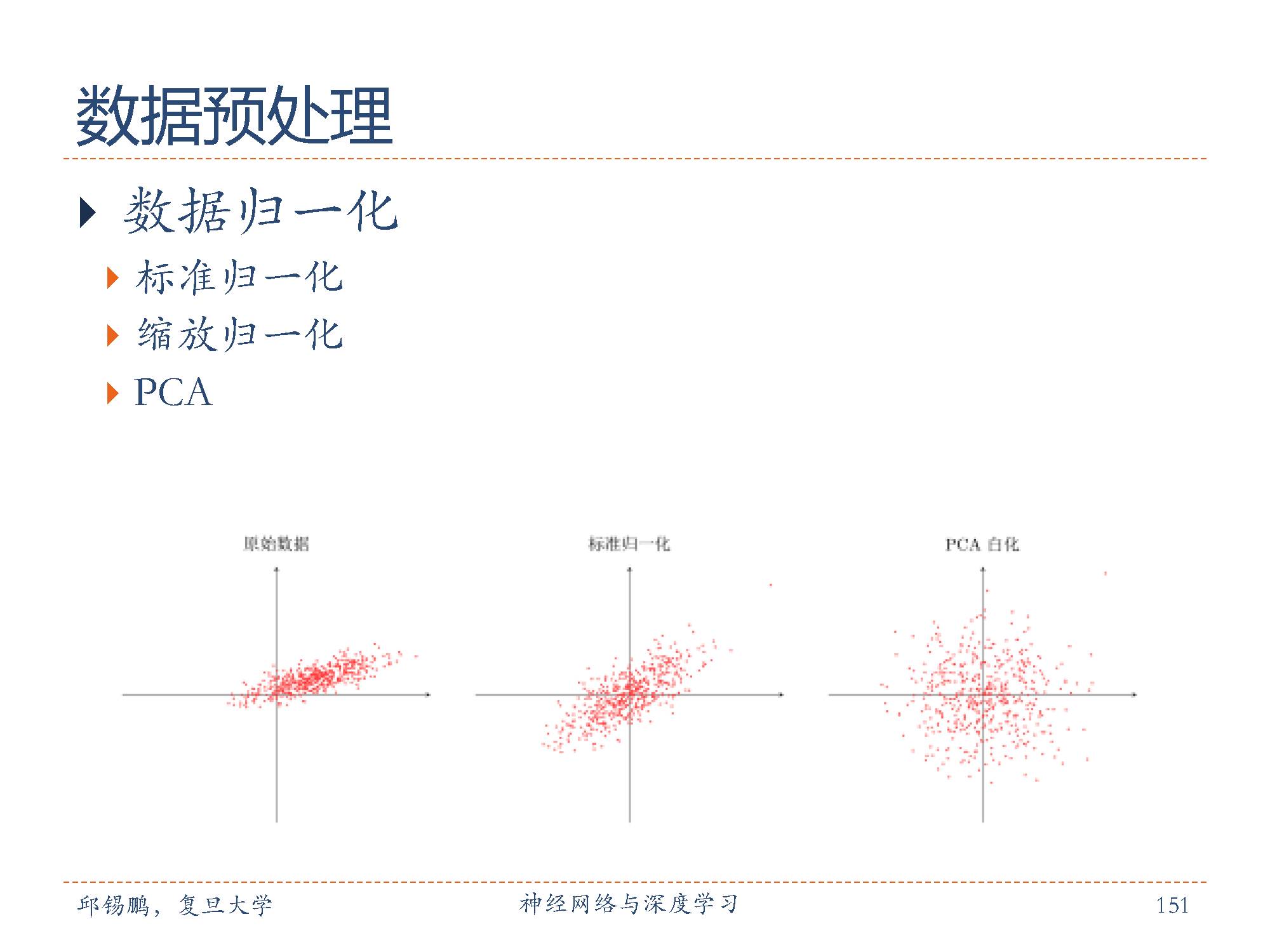
一般而言,原始的训练数据中,每一维特征的来源以及度量单位不同,会造成这些特征值的分布范围往往差异很大。当我们计算不同样本之间的欧式距离时,取值范围大的特征会起到主导作用。这样,对于基于相似度比较的机器学习方法(比如最近邻分类器),必须先对样本进行预处理,将各个维度的特征归一化到同一个取值区间,并且消除不同特征之间的相关性,才能获得比较理想的结果。虽然神经网络可以通过参数的调整来适应不同特征的取值范围,但是会导致训练效率比较低。
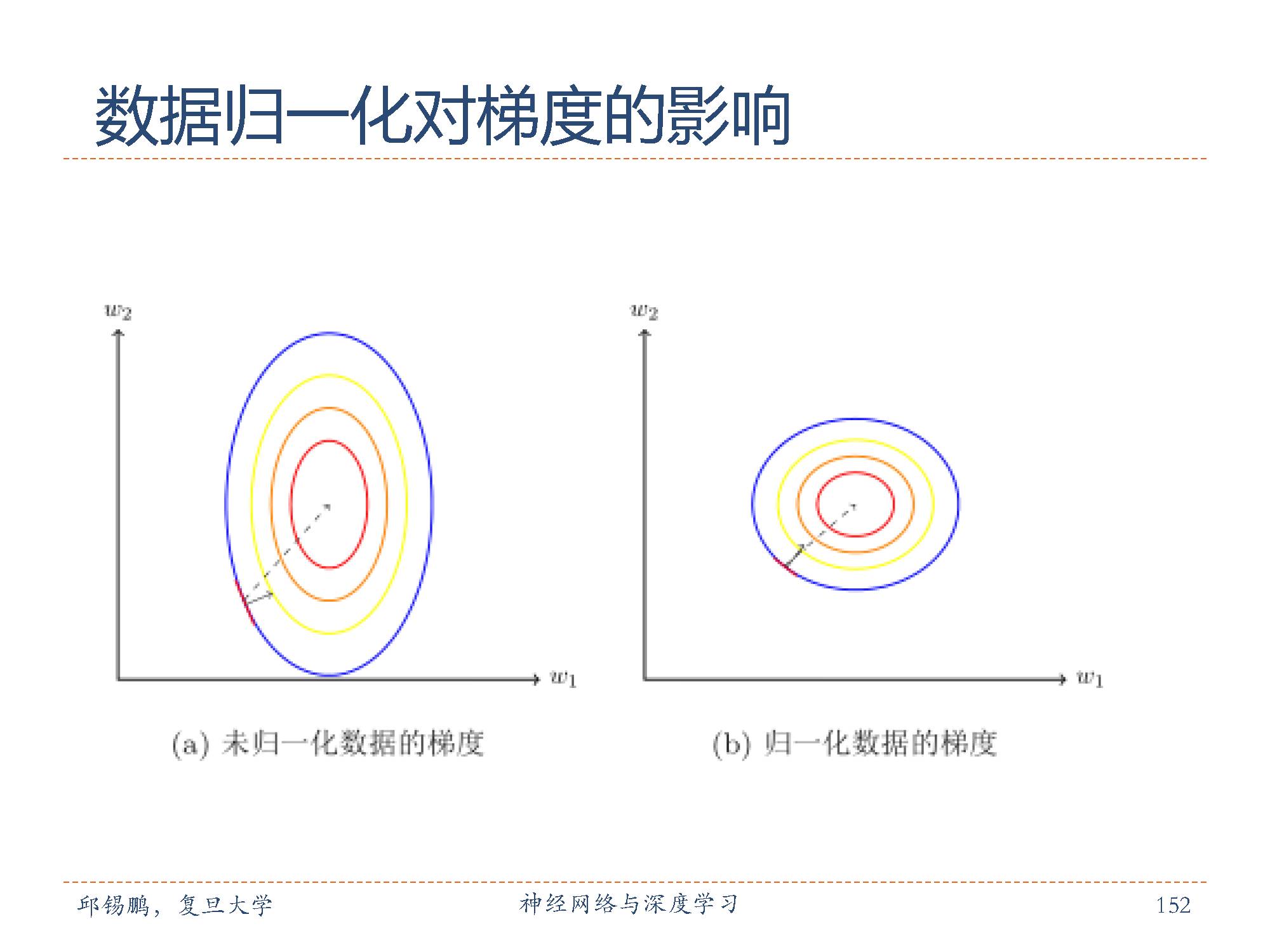
除了参数初始化之外,不同特征取值范围差异比较大时还会梯度下降法的搜索效率。图左给出了数据归一化对梯度的影响。其中,图右为未归一化数据的等高线图。取值范围不同会造成在大多数位置上的梯度方向并不是最优的搜索方向。当使用梯度下降法寻求最优解时,会导致需要很多次迭代才能收敛。如果我们把数据归一化为取值范围相同,如图右所示,大部分位置的梯度方向近似于最优搜索方向。这样,在梯度下降求解时,每一步梯度的方向都基本指向最小值,训练效率会大大提高。

标准归一化会使得输入的取值集中的0附近,如果使用sigmoid型激活函数时,这个取值区间刚好是接近线性变换的区间,减弱了神经网络的非线性性质。因此,为了使得归一化不对网络的表示能力造成负面影响,我们可以通过一个附加的缩放和平移变换改变取值区间。

在梯度下降中,学习率α的取值非常关键,如果过大就不会收敛,如果过小则收敛速度太慢。从经验上看,学习率在一开始要保持大些来保证收敛速度,在收敛到最优点附近时要小些以避免来回震荡。因此,比较简单直接的学习率调整可以通过学习率衰减(learning ratedecay)的方式来实现。除了固定衰减率的调整学习率方法外,还有些自适应地调整学习率的方法,比如AdaGrad、RMSprop、AdaDelta等。这些方法都对每个参数设置不同的学习率。
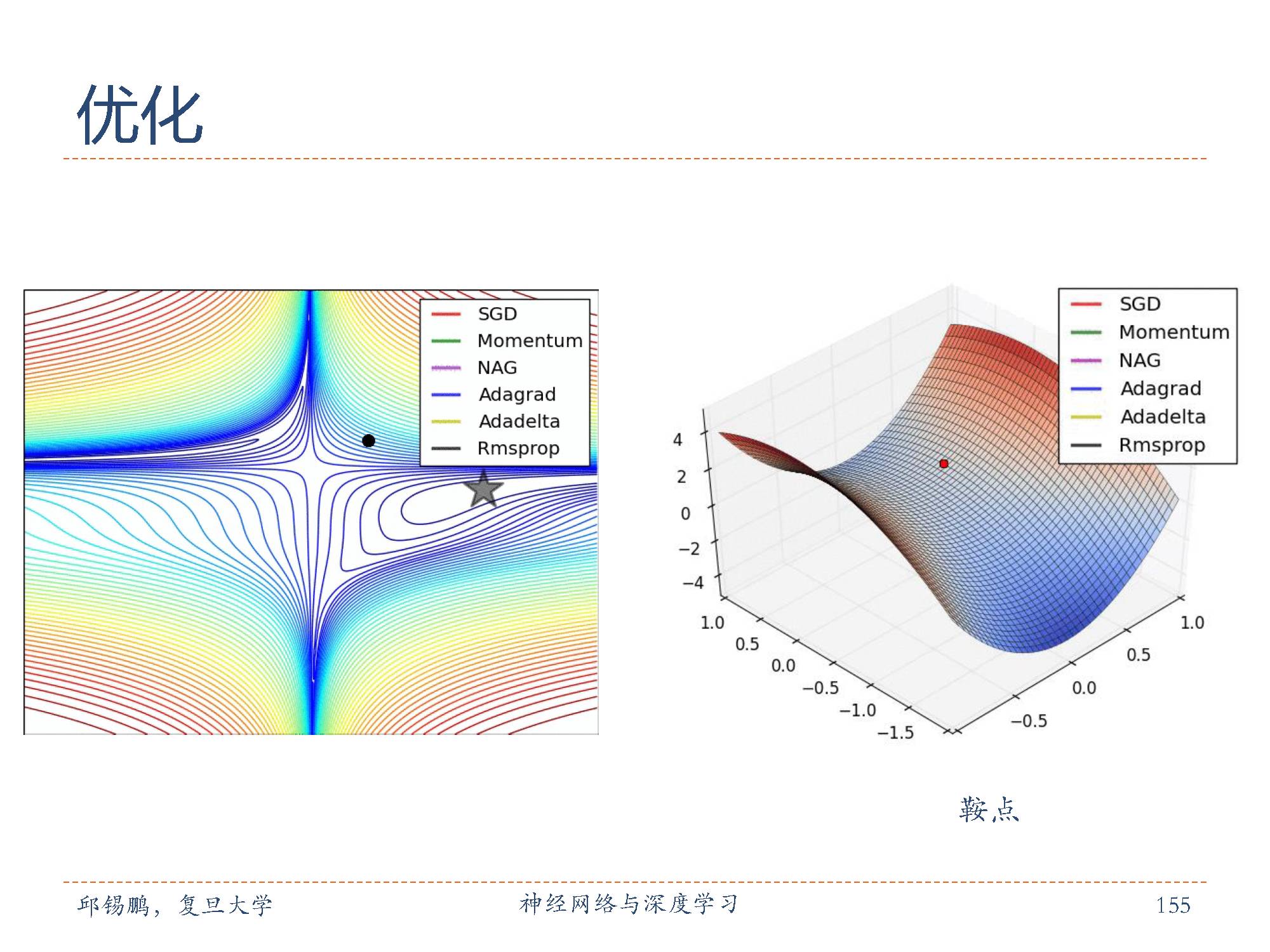
不同优化方法梯度下降速度的可视化。

除了可学习的参数之外,神经网络模型中还存在很多超参数。这些超参数对模型的性能也十分关键。

超参数的优化问题是一个组合优化问题,没有通用的优化方法。对于超参数的设置,一般用网格搜索(Grid Search)或者人工搜索的方法来进行。假设总共有K 个超参数,第k 个超参数的可以取mk 个值。如果参数是连续的,可以将参数离散化,选择几个“经验”值。
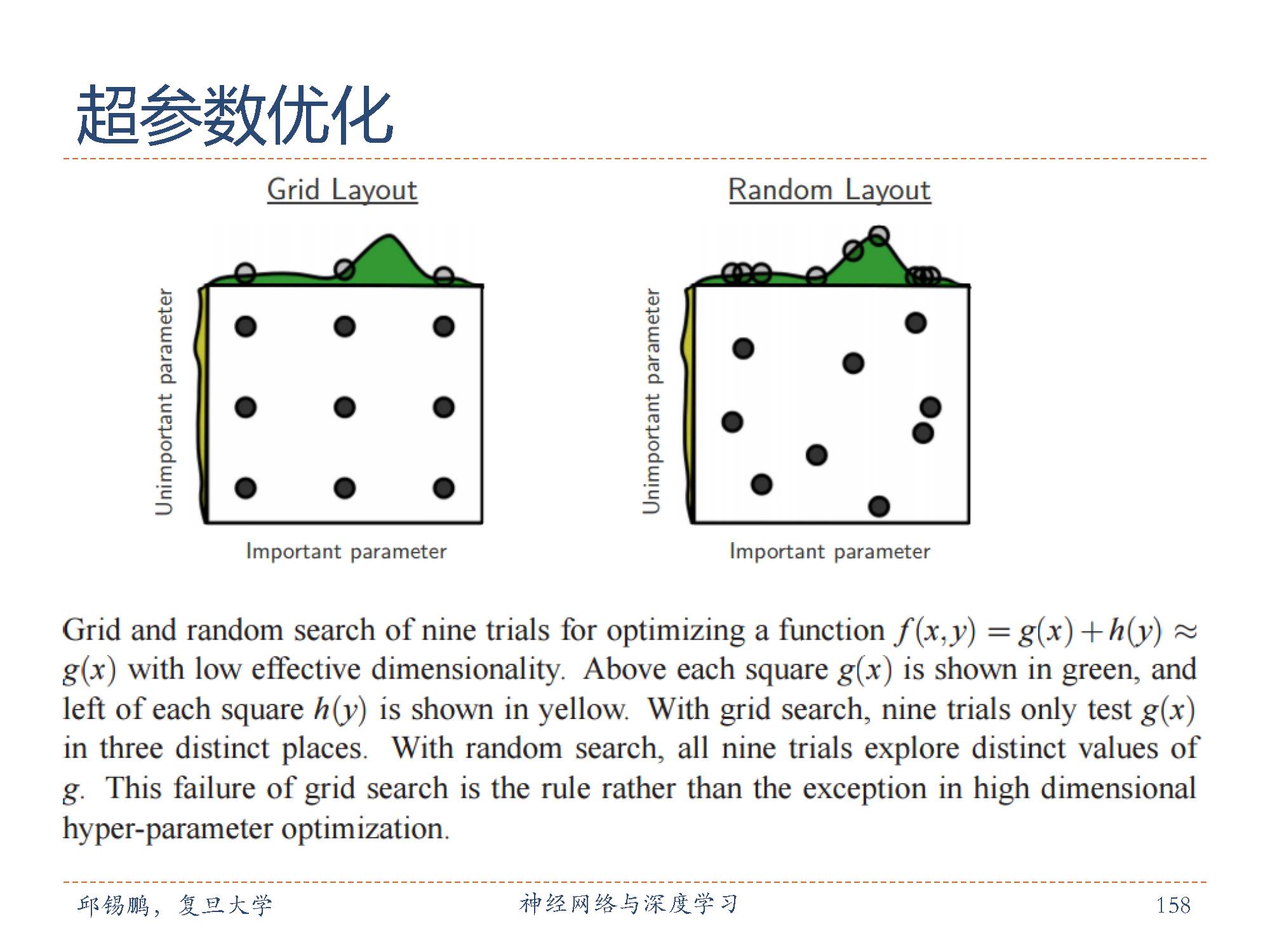
所谓网格搜索就是根据这些超参数的不同组合分别训练一个模型,然后评价这些模型在检验数据集上的性能,选取一组性能最好的组合。

机器学习模型的关键是泛化问题,即在样本真实分布上的期望风险最小化。对于同样,最小化神经网络模型在训练数据集上的经验风险并不是唯一目标。由于神经网络的拟合能力非常强,其在训练数据上的错误往往都可以降到非常低(比如错误率为0),因此如果提高神经网络的泛化能力反而成为影响模型能力的最关键因素。在传统的机器学习中,提高泛化能力的方法主要是限制模型复杂度,比如采用权重衰减等方式。而在训练深度神经网络时,特别是在过度参数(overparameterized)时,权重衰减的效果往往不如浅层机器学习模型中显著。因此训练深度学习模型时,往往还会使用其它的正则化方法,比如数据增据的数量。强、早期停止、丢弃法、集成法等。
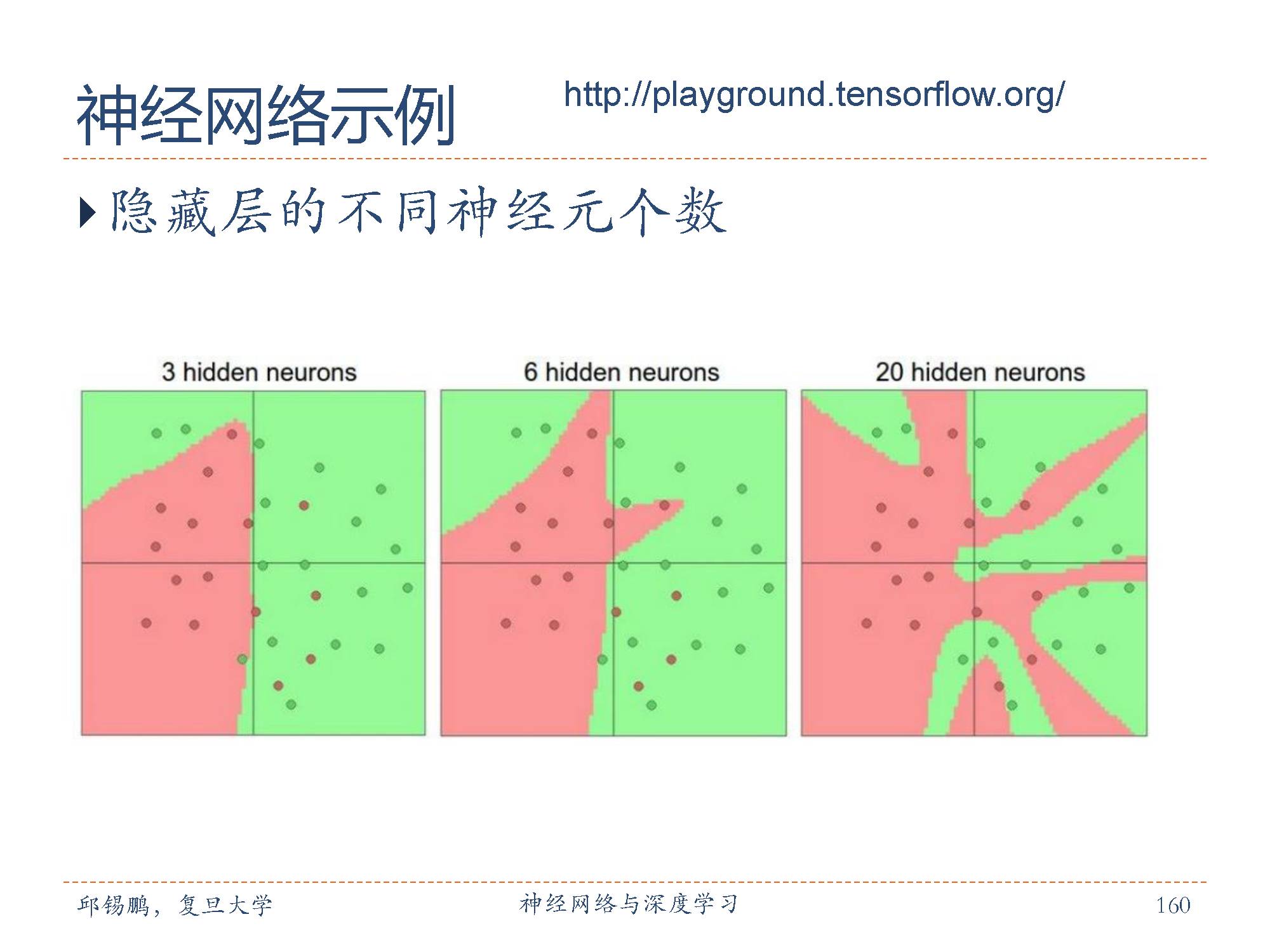
可以看出隐含层神经元个数越多模型的表示能力越强。
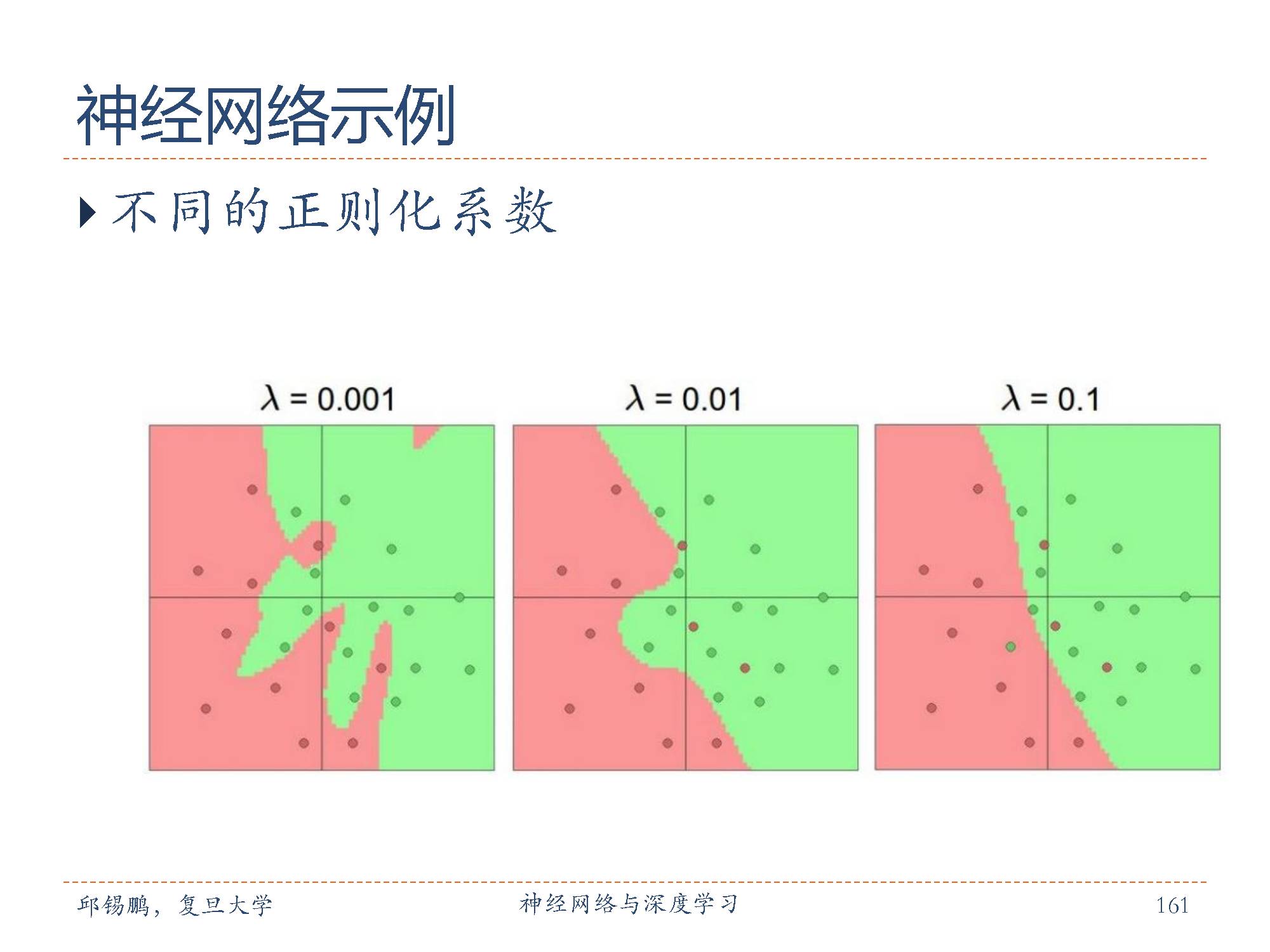
正则项与模型之间的权重,值越大分类边界越平滑,用于避免过拟合。
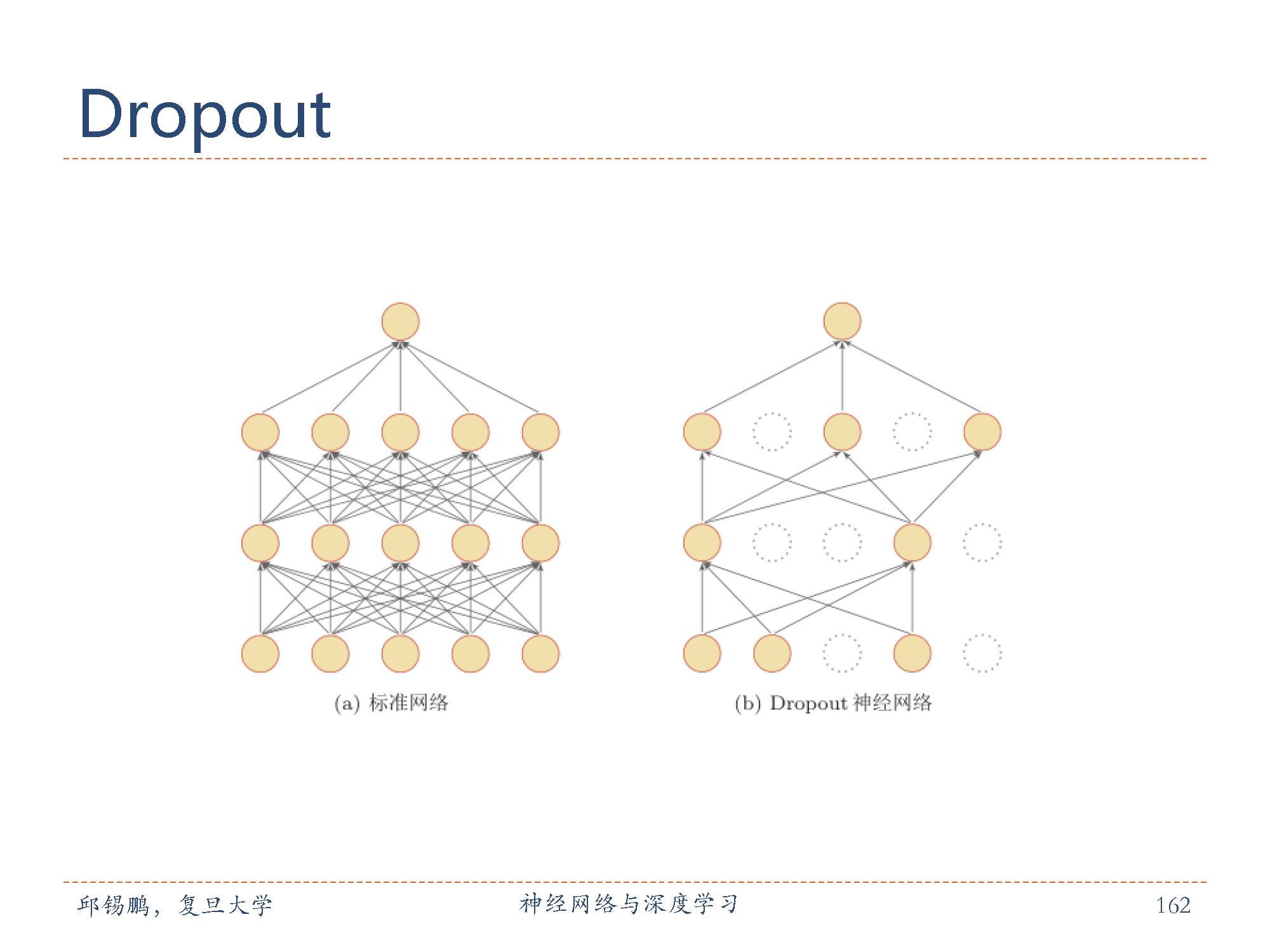
训练一个大规模的神经网络经常容易过拟合。过拟合在很多机器学习中都会出现。一般解决过拟合的方法有正则化、早期终止、集成学习以及使用验证集等。Srivastava et al. [2014]提出了适用于神经网络的避免过拟合的方法,叫 dropout方法(丢弃法),即在训练中随机丢弃一部分神经元(同时丢弃其对应的连接边)来避免过拟合。

这是在使用深度学习网络时候的一些经验,大家可以借鉴参考参考。
第二部分的深度学习基础模型部分结束了,敬请期待下一期的深度学习部分——进阶模型。
特别提示-邱老师深度学习slide-part3下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“nndl3” 就可以获取本部分pdf下载链接~~
请对深度学习感兴趣的同学,扫描如下二维码,加入专知深度学习群,交流学习~

欢迎转发分享专业AI知识!
请查看更多,登录专知,获取更多AI知识资料,请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录,顶端搜索主题,查看获得对应主题专知荟萃全集知识等资料!如下图所示~
请扫描专知小助手,加入专知人工智能群交流~

专知荟萃知识资料全集获取(关注本公众号-专知,获取下载链接),请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
【专知荟萃07】自动文摘AS知识资料全集(入门/进阶/代码/数据/专家等)(附pdf下载)
【专知荟萃08】图像描述生成Image Caption知识资料全集(入门/进阶/论文/综述/视频/专家等)
【专知荟萃09】目标检测知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃10】推荐系统RS知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃11】GAN生成式对抗网络知识资料全集(理论/报告/教程/综述/代码等)
【专知荟萃12】信息检索 Information Retrieval 知识资料全集(入门/进阶/综述/代码/专家,附PDF下载)
【专知荟萃13】工业学术界用户画像 User Profile 实用知识资料全集(入门/进阶/竞赛/论文/PPT,附PDF下载)
【专知荟萃14】机器翻译 Machine Translation知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃15】图像检索Image Retrieval知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃16】主题模型Topic Model知识资料全集(基础/进阶/论文/综述/代码/专家,附PDF下载)
【专知荟萃17】情感分析Sentiment Analysis 知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
-END-
欢迎使用专知
专知,一个新的认知方式! 专注在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



