
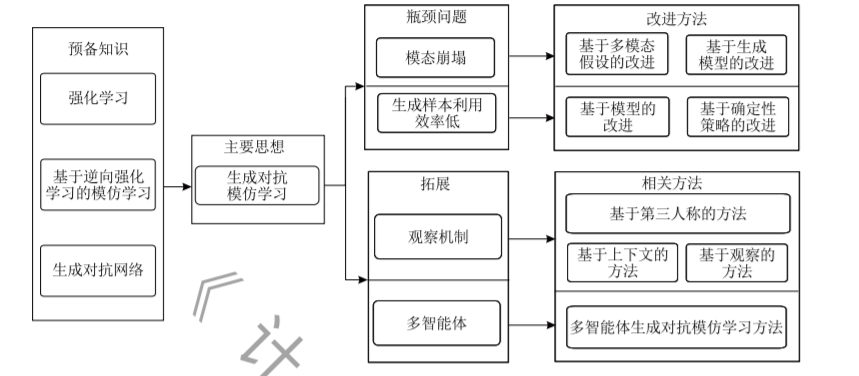
模仿学习研究如何从专家的决策数据中进行学习,以得到接近专家的决策模型。同样学习如何决策的强化学习往往只根据环境的滞后反馈进行学习。与之相比,模仿学习能从决策数据中获得更为直接的反馈。它可以分为行为克隆、基于逆向强化学习的模仿学习两类方法。基于逆向强化学习的模仿学习把模仿学习的过程分解成逆向强化学习和强化学习两个子过程,并反复迭代。逆向强化学习用于推导符合专家决策数据的奖赏函数,而强化学习基于该奖赏函数学习策略。基于生成对抗网络的模仿学习方法从基于逆向强化学习的模仿学习发展而来,其中最早出现且最具代表性的是生成对抗模仿学习方法(Generative Adversarial Imitation Learning,简称GAIL)。生成对抗网络由两个相对抗的神经网络构成,分别为判别器和生成器。GAIL的特点是用生成对抗网络框架求解模仿学习问题,其中,判别器的训练过程可类比奖赏函数的学习过程,生成器的训练过程可类比策略的学习过程。与传统模仿学习方法相比,GAIL具有更好的鲁棒性、表征能力和计算效率。因此,它能够处理复杂的大规模问题,并可拓展到实际应用中。然而,GAIL存在着模态崩塌、环境交互样本利用效率低等问题。最近,新的研究工作利用生成对抗网络技术和强化学习技术等分别对这些问题进行改进,并在观察机制、多智能体系统等方面对GAIL进行了拓展。本文综述了这些有代表性的工作,并探讨这类算法未来的发展趋势,最后进行了总结。
http://cjc.ict.ac.cn/online/onlinepaper/ljh-2020119221607.pdf
计算机学报
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)

专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源





