剑桥大学计算机系博士孙琳:自然语言处理(NLP)的发展以及在教育领域的应用情况(附报告pdf下载)
点击上方“专知”关注获取专业AI知识!



大家好!我是孙琳,很高兴参加TAB教育科技论坛,今天分享的题目是“教育应用中的自然语言处理”。首先我先做一下自我介绍,我是剑桥大学计算机系的博士,博士研究的方向是自然语言处理, 2011年的时候,我们一起创立了校宝在线的前身,当时就想要把自然语言处理的技术用在教育当中。校宝在线的业务是为中国的民办学校提供SaaS解决方案,包括ERP、LMS等,同时把人工智能的技术应用在这些软件解决方案当中。我自己在业余时间还保持做研究,目前是剑桥大学语言实验室的研究员,每年还会坚持发Paper,同时也是很多学术杂志和国际会议的审稿人。

今天为什么给大家讲“自然语言处理”和“教育”这个题目呢?其实大家都知道人工智能,特别在教育中的应用是最近的热点,相关的信息也非常多,相信大家也可以看到。但是作为人工智能当中一个非常重要的领域:自然语言处理跟教育结合的相关信息,却并不是特别多。我自己也找过,无论是中文还是英文都不多,我想这是一个非常好的机会能把我自己对于这方面的一些思考分享出来给供在座的各位大咖和各位创业者们做一个参考。

自然语言处理其实是人工智能里面一个非常重要的分支,其他的分支大家也非常了解,比如说计算机视觉、语音,包括机器学习、深度学习,这些都是人工智能的分支,它也常常被叫做计算语言学。它核心的目标就是把人的语言也就是自然语言转换成计算机可以执行的命令。简单来说就是让计算机读懂人的语言。所以说NLP关注的核心其实是语言或者更通俗一点来说是文本。

自然语言处理,我个人认为是人工智能领域里面最难的一个领域,它最大的难点在哪里?首先,因为自然语言处理相对于语音和视觉来说是高度抽象化的表现,它不是信号,而是一些非常抽象化的理念。大家都认为人类的语言有非常强的逻辑性,其实人类的语言逻辑性并不强。我给大家举一个例子,大家看这句话“我从来没说他偷过钱。”这句话有6种理解方法,我一一列出来了。比如说我可以这么来说:“我从来没说他偷过钱。”这个意思就是可能别人说过,但是我没有说。第三个可以说“我从来没有说他偷过钱”,可能我确实没有说,但是我用其他的方式暗示过。除了这6种以外,如果把这个句子加长的话,变成“我从来没说他偷过我的钱。”那么就有7种解释,不光有1到6,还有第7种解释,这个句子可以变得更长,这个歧义就会更多。对于计算机来讲,如果单单给它这一句输入,要做到真正语境上的理解是不可能的事情。要做到真实语境上的理解可能需要更多的辅助信息和上下文的信息,不然是没有任何可能性的。

其次,我们要理解人的语言不能光靠逻辑,还要有非常强的知识库,要有很多知识才能正确理解人类语言。我举个例子,下面两句话中,第一句话We gave monkeys the bananas because they were hungry。这个地方的they指猴子。第二句话We gave monkeys the bananas because they were over ripe。这个地方的they指香蕉。对于计算机来说这两句话看起来结构非常相似,句式也非常类似,所以计算机必须知道猴子饿了,香蕉不能饿,猴子不能烂的,香蕉才能烂,才能对这句话有一个正确的理解,不然是完全无法知道。
再次,人的语言还有一个非常大的特性即组合性。我们通过字母组合成词,通过词组合成短语,短语组成句子、句子组成段落、段落组成文章。如果单单抽出里面一部分进行解析的话,比如说解析字母、解析词,我们就算理解了词的意思也不能表现出人本来的含义,因为单个抽出词是没有意义的,人的自然语言表达的含义往往就在这些组合当中,恰恰是学习这些复杂的组合对于计算机来说是一件非常难的事情。
最后,人类语言是非常灵活和开放的。开放是什么意思?人的语言是随着时间而改变的,不停的有新词冒出来,以前词的意思也会随着时间有完全不同的意思。比如说“灌水”、“潜水”,这两个词在网络时代有了完全不同的含义。对于计算机来说怎么能够实时的学会这些新词、发现新的用法,也是非常有挑战性的。

研究自然语言处理,通常有三种方法。第一种,机器学习的方法,也包括深度学习。简单来说我们收集海量的文本、数据,建立语言模型,解决自然语言处理的很多任务。第二种,规则和逻辑的方法。虽然人的语言不是完完全全有逻辑,但是里面还是有很强的逻辑性的,一些传统的逻辑、原理都可以用在上面,其实这也是人工智能最早主要的研究方法,只不过90年代之后大家逐渐的开始更多的采用机器学习的方法,而不是采用逻辑和规则的方法。现在基本上在自然语言处理研究当中,这两个占的比例是二八开。逻辑规则和机器学习的比例,20%是逻辑和规则,80%是机器学习,也有两者结合。第三种,语言学的方法。因为自然语言处理离不开语言学,我们可以把自然语言处理看成语言学下面的一个分支,不单单看成人工智能下面的一个分支。语言学一句话归纳起来就是对人的语言现象的研究。它不关心怎么写得好,关心的是你写了什么。所有人类语言现象的研究都可以归为语言学,对于语言学家来说他们是很多自然语言处理任务的设计师,由他们提出问题,把框架勾勒出来;当然解决问题则要靠研究人员用机器学习、规则和逻辑的方法把这个框架填上,把问题解决掉。
常见的比较成功的自然语言处理的应用包括搜索引擎、机器翻译、语音识别和问答系统。其中,语音识别技术传统上来说算是自然语言处理下面的一个任务,但是近些年已经单独列成一个研究领域,因为在目标和研究方法上和自然语言处理是迥异的,所以往往把语音识别单列成跟NLP并排的研究领域。

下面这个图里的概念大家已经非常熟悉了,其实它们都是人工智能下面的子领域,两者是平行的。而深度学习是机器学习的一个子领域。也就是说对于自然语言处理来说,用非深度学习的方法来做自然语言处理的任务也是没有问题的。
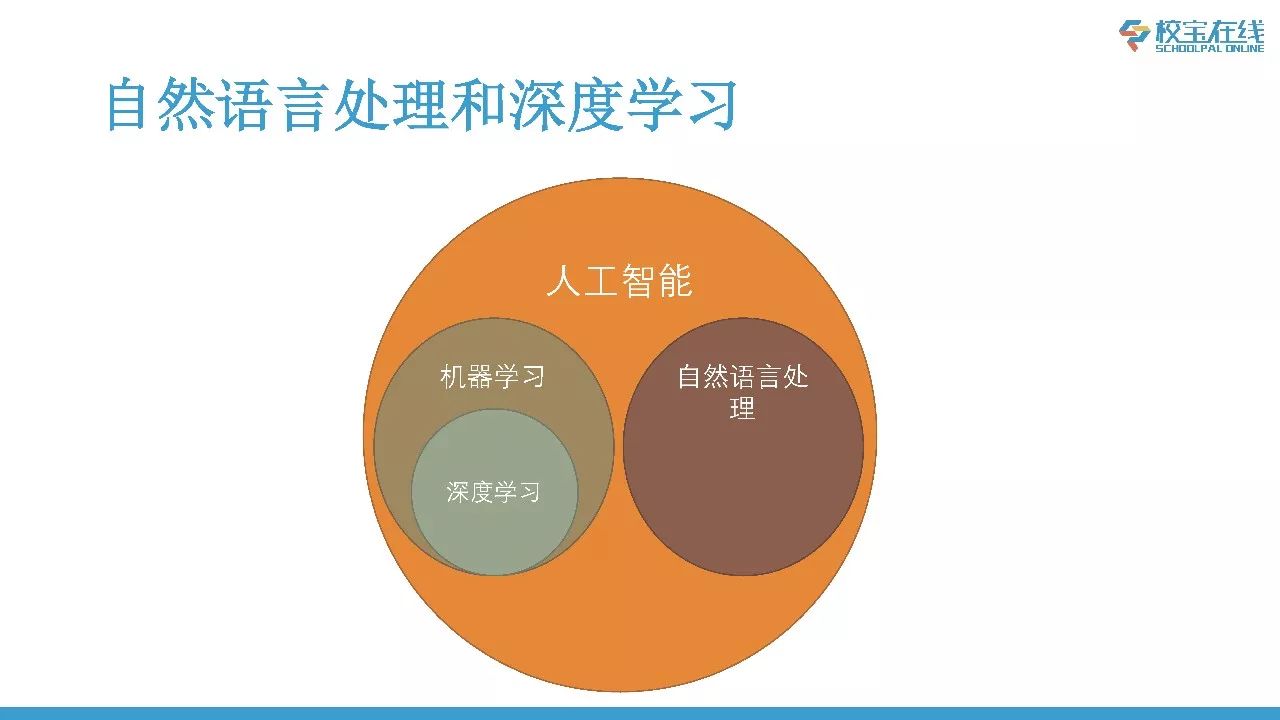
自然语言处理和深度学习之间是什么关系呢?深度学习为自然语言处理提供了很多新的模型和方法。因为深度学习最早在计算机视觉和计算机语音方面取得了非常重大的突破,所以很早就被用在NLP的各个研究领域当中了。到今天为止,可以说它基本上在所有NLP的任务当中都取得了成功。现在对于NLP的各种任务,能见到的最好的模型几乎都用到深度学习了。
但是跟其他领域内不一样的是:NLP上面深度学习带来的改进并不大。比如说我们在视觉或者在语音上面错误率的降低可以达到40%、50%,但是在NLP上面超过10%的改进都是非常少见的,很多都是1%、2%的改进。另外还有一个非常要命的问题,其实深度学习都是非常复杂的非线性模型,这对于研究人员来说也是黑盒。所以说人类很难理解一个模型背后所代表的语言学现象以及怎样用语言学的理论去解释深度学习的模型。之所以做不到这一点,是因为我们没有办法把深度学习模型对于很多问题的解决方案放进传统的语言学框架里面,这对于研究人员来说是很大的一个困扰。

目前我们已经有非常好的语音识别系统了,现在基本上达到了人类的水平,在理想环境里可以达到95%以上的正确率。同样我们也有比较正确的机器翻译系统,正确率换算过来也可以有70%到80%,虽然离人的水平还有一定的差距,但是已经是可用的状态。除了这两个以外,自然语言处理(NLP)的应用目前进展不大。举一个最简单的例子,比如词性标注,在一个句子当中,动词、名词、形容词,这个任务是非常简单、非常基础的任务。但是句子级别(一句话一个词不错才算对)目前的正确率只有57%,而且从2009年到2017年间正确率提高了不到1%,无论使用深度学习、各种模型、各种方法,花了八年时间也是只是提高了不到1%。

另外一个例子是句法分析,就组合式句法分析来说,我们今天没有比十一年前做得更好,无论是用深度学习还是其他任何方法,十一年没有改进过。谷歌在去年推出了谷歌SyntaxNet,号称是世界上面最优秀的句法分析器,其实对比四年前最好的系统也只提了2%,当然谷歌用了目前最好的深度学习技术,也仅仅做到了这样。还有多轮对话系统,目前正确率最多只能做到60%,这其实是完全不可用的状态。深度学习的模型,其实在NLP的各个领域都取得了成功,不是说不成功,只是没有取得在视觉、语音领域那么大的成功。

在讨论AI的时候,我心里面的第一反映其实是它跟教育是最契合的一个点,但大家好像提得比较少。我觉得语言是大家学习的对象,母语或外语都是对自然语言的研究。第二教师的授课、教材也都是自然语言,所以说我很惊讶的发现大家对AI展望的时候有时候比较忽略NLP方面的一些信息。这也是今天我为什么会讲这个主题的原因。
我把NLP的教育应用分成三大类:
(1)跟语言教学相关的应用。包括外语和母语教育(自动评分,辅导口语写作等)
(2)教育文本处理。一是教材的编订。举个例子,在所有剑桥官方出版的英语教材的封皮上面都有黄色的小标志,估计大家买书的时候直接忽略掉了,那上面写的是什么意思呢?它表示这本书用剑桥国际语料库通过语言学和自然语言处理的方法来检测书本里面内容的正确性和适用性,而且是在非常大的大数据、语料库上面完成的。二是文本阅读分级,大家比较熟悉的是蓝思。三是文本简化,生成题目。
(3)对话系统,使用自然语言进行教学。让每个学生都能够有一个个人学习助理,有问题可以问它。但是目前来说这方面的应用,见到的系统比较少,因为在基础研究上面还是需要更大的进步才能让它有更好的应用。

下面看几个具体的应用:
NLP和教育结合的第一个应用是作文打分,这是成熟的应用。ETS E-Rater用在托福、GMAT、GRE考试当中了。现在考托福,写作里面一部分分数是电脑自动评分的。ETS E-Rater和人工的打分数据非常接近了。我们校宝在线1Course也可以达到ETS E-Rater水平,而且可以给出详细的反馈。我们不仅会给出分数,而且会给出非常详细的学习建议以及得分的要点。
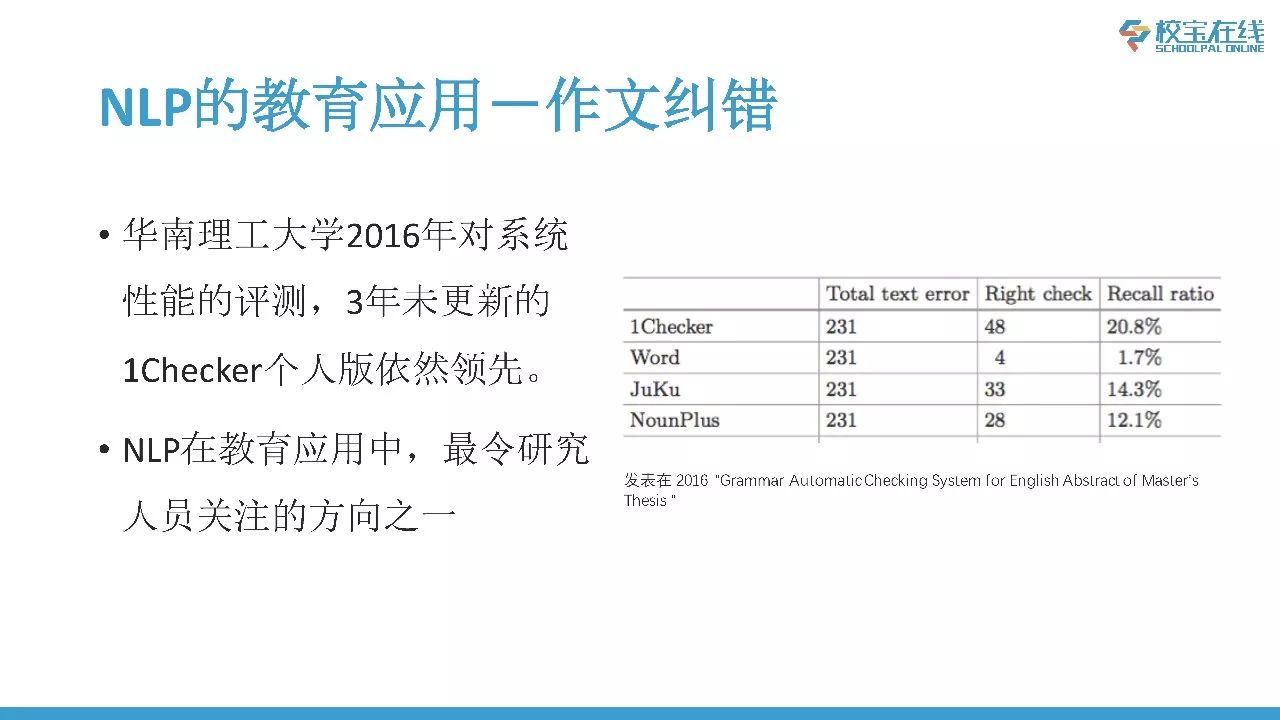
第二个应用是作文的纠错。比如学生作文当中拼写、语法以及其他的各种错误,通过计算机看了之后可以给出相关的修改建议,包括润色,会建议学生更高级的表达、更符合的表达。这方面的提供商蛮多的,我们最早在2011年的时候推出了一个完全免费的针对个人用户的产品1Checker,今天完全可以用,但是已经很多年没有更新过了。还有其他的供应商,包括国内有句酷批改网,国际上面也有Grammarly等等。我就说1Checker,原理是通过一个语言模型,用计算机阅读学生的作文,找出可能错的一些点,然后对这些点生成不同的建议,最后用模型根据用户不同的水平过虑和重新对建议进行排序,这是对于纠错方面基本的原理。我自己比较惊讶的是去年华南理工大学对于市面上面很多作文纠错的供应商做了一个对比实验,发现1Checker已经三年没有更新了,但是依然领先于其他的供应商。因为作文纠错是作文评分的基础,我相信如果他们采用我们非个人版的系统还会有更大的提升。作文纠错和作文打分,是NLP在教育当中的应用最成功也是最受人关注的两块。


其他的应用包括简答题的评分,简答题的自动评分其实是只能针对于有固定答案的非开放性的简答题。什么叫做开放性的简答题?比如说你最难忘的一件事情,这是开放性的。非开放性的,指的有几套固定答案的,或者让你描述一个现象,这些都属于可以自动批改的简答题。原理上面跟机器翻译很相似,把学生的答案和正确的答案进行比较。目前来说国际上面有两套比较通行的简答题评分的引擎,一个是牛津的那套,精度非常高,对于每道题都要手写规则。还有一个非常成功的是ETS E-Rater,在某些任务当中可以达到人的水平。

下面一个常见的应用是阅读分级。大家可能听说过蓝思(Lexile)阅读分级,这里面涉及到两个关键信息:词汇频率和平均句子长度。其实词的频度是词汇难度的表现,在大的语料库和文本当中,比如说所有的人民日报或其他报纸,如果一个词汇少见可能就是比较难的词。平均句长是语法复杂度的体现。大家觉得蓝思(Lexile)阅读分级的算法不难,但它的效果是非常好的,它可以给利用计算机给很多的文本、书籍进行自动处理、分析这些书籍的难度,然后对于不同水平的学习者给他们提供不同难度的学习资料。

另外一个应用是“词汇测试”,我在国内看到的比较少,在欧洲、美国看得蛮多的,它是对于词汇自动生成选择题。给定一篇文章,计算机自动根据学习者的水平找到合适的句子,找到合适的词然后自动生成迷惑项,自动生成学生的练习题。这个好处是老师不需要提前对于阅读理解、阅读材料或者词汇掌握情况准备,只需要准备阅读材料就好了。原理和步骤:(1)找到学习者能够读懂的句子;(2)找到适合他水平的待测试的词;(3)生成迷惑项。迷惑项的生成很有讲究,迷惑项要足够迷惑才可以,它们在非常小的上下文里面都是可以讲得通的,但是放在整句当中正确的只有一个,最大化他的迷惑性,最大化测试的效果,这个应用在国内的见的不是特别的多。

目前研究的方向还是主要集中于自动纠错和自动打分,我估算了一下,大体占到每年Paper发表量的70%。从目前自动纠错研究来看,只有40%到60%比例的错误是可以被检测并改正的,离人的水平、教师的水平依然是非常遥远的。从目前自动打分研究来看,特定任务上面,比如是托福、雅思这种应试作文上面基本上已经达到了人的水平,但是对于更有挑战性的文本目前也处于一个停滞不前的状态,也没有很大的突破。另外一个问答系统、对话系统,和学生的个人助手,类似这种研究相对来说并不是特别多,主要原因是由于这些方面需要基础研究层面有更大的突破,才能在教育应用中更好的找到自己的一席之地。目前主要的两个研究机构是ETC和Cambridge assesment。

最后给大家分享一点我自己的结论,通过我刚才跟大家说的,深度学习可以说在人工智能应用上面已经非常成功了,但是在NLP和教育结合的点上,不能通过深度学习在人工智能应用上的成功来推测NLP会在教育应用中或者深度学习通过NLP在教育中的应用就能成功,这个点我是完全看不到的。因为首先在NLP的研究领域上面,深度学习就没有带来像视觉、语音的突破。如果再应用到教育上面,那可能是更未来的事情,但我相信这也不是一个坏事,未来还是蛮有希望的,我希望深度学习包括机器学习,在对话系统、问答系统,有在视觉、语音上面那么大的突破。通过解决根本的问题,然后可以用在教育中,这是非常大的需求,个人的智能助理,可以给你一些必要的帮助,就像一个虚拟的老师一样。
另外还有一个非常难受的问题即黑盒问题,这是教育行业一个非常特殊的需求。因为深度学习这种模型都是高度非线性的、非常复杂的模型,尤其现在流行的是端到端,你给我输入输出就行了,中间完全用模型搞定,人干预的地方很少。那问题来了,对于教育来说往往需要的不仅仅是一个准确的结果,还需要你推理的过程。比如说我做打分,分数正确是很重要,但是对于学生来说需要知道为什么得了这个分数,具体哪写的不好,怎么改进。对于全黑盒的模型来说,即便是深度学习最终革新了NLP,大大提高了NLP任务的准确度,可是对于老师还是学生来说还是很难读懂和解释的。这个黑盒问题怎么解决,也是需要研究人员想办法的。

特别提示-孙博士slide下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“nlpedu” 就可以获取pdf下载链接~~
请查看更多,登录专知,获取更多AI知识资料。请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录,顶端搜索主题,查看获得对应主题专知荟萃全集知识等资料!如下图所示~
请扫描专知小助手,加入专知人工智能群交流~

专知荟萃知识资料全集获取(关注本公众号-专知,获取下载链接),请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
【专知荟萃07】自动文摘AS知识资料全集(入门/进阶/代码/数据/专家等)(附pdf下载)
【专知荟萃08】图像描述生成Image Caption知识资料全集(入门/进阶/论文/综述/视频/专家等)
【专知荟萃09】目标检测知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃10】推荐系统RS知识资料全集(入门/进阶/论文/综述/视频/代码等)
【专知荟萃11】GAN生成式对抗网络知识资料全集(理论/报告/教程/综述/代码等)
【专知荟萃12】信息检索 Information Retrieval 知识资料全集(入门/进阶/综述/代码/专家,附PDF下载)
【专知荟萃13】工业学术界用户画像 User Profile 实用知识资料全集(入门/进阶/竞赛/论文/PPT,附PDF下载)
【专知荟萃14】机器翻译 Machine Translation知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃15】图像检索Image Retrieval知识资料全集(入门/进阶/综述/视频/代码/专家,附PDF下载)
【专知荟萃16】主题模型Topic Model知识资料全集(基础/进阶/论文/综述/代码/专家,附PDF下载)
【专知荟萃17】情感分析Sentiment Analysis 知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
【专知荟萃18】目标跟踪Object Tracking知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
【专知荟萃19】图像识别Image Recognition知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
【专知荟萃20】图像分割Image Segmentation知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
-END-
欢迎使用专知
专知,一个新的认知方式! 专注在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



