【前沿】Pytorch开源VQA神经网络模块,让你快速完成看图问答
【导读】近期,NLP专家Harsh Trivedi使用Pytorch实现了一个视觉问答的神经模块网络,想法是参考CVPR2016年的论文《Neural Module Networks》,通过动态地将浅层网络片段组合成更深结构的模块化网络。这些模块可以通过联合训练来自由组合。代码已经在Github上开源,让我们来看下。
更多结果可以参考这个链接。
https://github.com/HarshTrivedi/nmn-pytorch/blob/master/visualize_model.ipynb
Neural Module Network (NMN) for VQA in Pytorch
注释:这不是一个用于神经模块网络训练的官方资源库。
NMN是通过动态地将浅层网络片段组合成更深结构的模块化网络。这些模块可以通过联合训练来自由组合。本代码是用PyTorch实现的视觉问答的神经模块网络。大部分想法直接来自下面的文章:
Neural Module Networks: Jacob Andreas, Marcus Rohrbach, Trevor Darrell and Dan Klein. CVPR 2016.
如果您在工作中使用本代码,请引用上述文章。我们在下面介绍重现实验结果的说明,首先看一下结果演示:
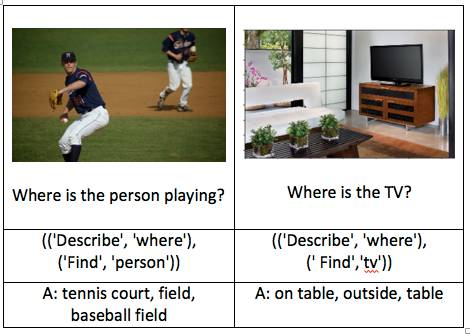
演示:
更多结果可以用visualize_model.ipynb看到。
https://github.com/HarshTrivedi/nmn-pytorch/blob/master/visualize_model.ipynb



依赖关系:
下面是项目的主要python依赖项: torch, torchvision caffe, matplotlib,numpy, matplotlib and sexpdata
你还需要有斯坦福的解析器(https://nlp.stanford.edu/software/lex-parser.shtml)。一旦加载完成,请确保在.bashrc中设置STANFORDPARSER,以便使目录$STANFORDPARSER / libexec /包含有stanford-parser.jar
下载数据:
您需要从VQA网站下载图像、注释和问题。你也需要下载VGG模型文件来预处理图像。为了节省您的时间和精力,确保下载的文件放置在合适的目录结构中,我准备了几个download.txt。
在根目录查找中运行以下命令 find . | grep download.txt。您应该能够看到以下包含download.txt的目录:
./preprocessing/lib/download.txt
./raw_data/Annotations/download.txt
./raw_data/Images/download.txt
./raw_data/Questions/download.txt每个download.txt都具有特定的指令,您需要在相应的目录中运行wget命令。确保文件与下载数据后相应的download.txt中提到的文件相同。
预处理:
预处理目录包含预处理raw_data所需的脚本。预处理数据被存储在preprocessed_data中。这个仓库中的所有脚本都在一些set上运行。下载数据时,默认设置(目录名称)是train2014和val2014。你可以通过使用pick_subset.py构建一个像train2014-sub,val2014-sub这样的问题类型特定的子集。您需要确保训练/测试/验证集名称与以下脚本中一致(通常在代码顶部设置)。默认情况下,所有内容都可以在默认设置上运行,但是如果您需要特定设置,则需要按照以下注释操作。您需要按顺序运行以下脚本:
1. python preprocessing/pick_subset.py
[# Optional: If you want to operate on spcific question-type ]
2. python preprocessing/build_answer_vocab.py
[# Run on your Training Set only]
3. python preprocessing/build_layouts.py
[# Run on your Training Set only]
4. python preprocessing/build_module_input_vocab.py
[# Run on your Training Set only]
5. python preprocessing/extract_image_vgg_features.py
[# Run on all Train/ Test / Val Sets]备忘录:添加setting.py以确保set名称可以用于实验的全局配置。
运行实验:
你可以用命令python train_cmp_nn_vqa.py训练模型,准确率/损失日志存在logs/cmp_nn_vqa.log。当训练完成后,选择的模型自动保存在saved_models/cmp_nn_vqa.pt。
可视化模型:
选择保存的模型,并通过运行visualize_model.ipynb将其可视化。
模型评估:
运行命令pythonevaluation/evaluate.py可以对模型进行评估,在stdout上可以看到一个简短的总结报告。
接下来的计划:
添加更多的文档;
做一些代码清理工作;
在VQA数据集上记录此实现的结果;
在PyTorch中实现NMN的简短博客。
有问题?
请在hjtrivedi@cs.stonybrook.edu上发邮件给我,我会尽快把它修理好。
参考链接:
https://github.com//HarshTrivedi/nmn-pytorch
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



