【干货】一文读懂什么是变分自编码器
【导读】本文是工程师Irhum Shafkat的一篇博文,主要梳理了变分自编码器的相关知识。我们知道,变分自编码器是一种生成模型,在文本生成、图像风格迁移等诸多任务中有显著的效果,那么什么是变分自编码器?它存在什么问题?它有什么改进算法?本文较为全面地讲解了变分自编码器的相关内容,分别介绍:标准变分自编码器的结构、存在的问题以及相关的解决思路,并预测了变分自编码器的改进方向,相信能给您的研究带来一些启发。
Intuitively Understanding Variational Autoencoders
直观地了解变分自动编码器
为什么该方法在创作文本、艺术作品甚至音乐方面如此有用。
与使用标准的神经网络作为回归器或分类器相比,变分自动编码器(VAEs)是强大的生成模型,它可以应用到很多领域,从生成假人脸到合成音乐等。
这篇文章将探讨VAE是什么、背后的原理、以及它作为一种强大的媒体生成工具的用途。
▌首先,什么是变分?
当使用生成模型时,您可能只生成一个看起来与训练数据类似的输出,您可以使用VAE执行此操作。 但更多的时候,你想要在特定方向上改变或者探索你拥有的数据的变化,而不是在随机方式的变化。 这是VAE相比目前可用的其他方法的优势所在。
▌解码标准自动编码器
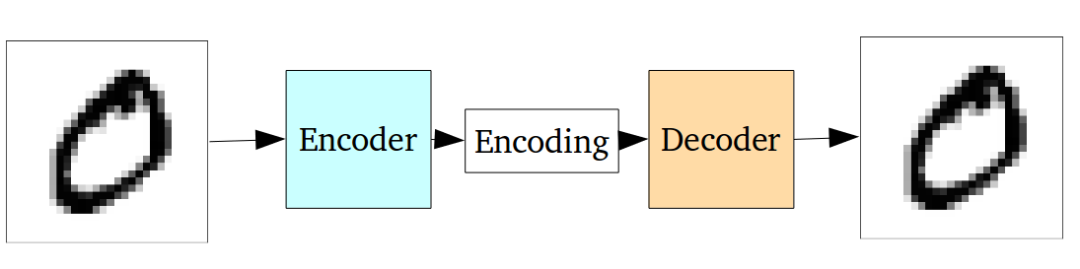
一个自动编码器网络实际上是一对相连的网络,一个编码器和一个解码器。 编码器网络接收输入,并将其转换成较小的密集表示,解码器网络可以使用该表示将其转换回原始输入。
如果您不熟悉编码器网络,但是熟悉卷积神经网络(CNN),很可能您已经知道编码器的功能了。
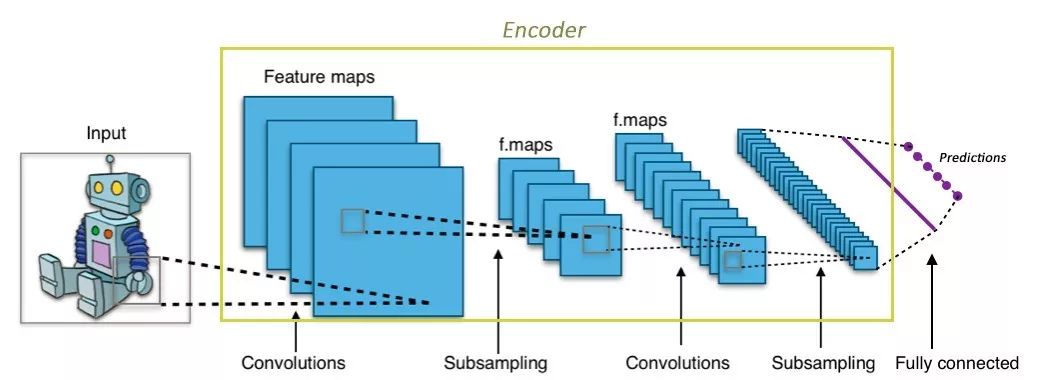
任何CNN的卷积层都接收大的图像(例如尺寸为299x299x3的三阶张量),并将其转换为更加紧凑,密集的表示(例如,尺寸为1000的1阶张量)。 这个密集的表示然后通过全连接层,并输入到分类器网络用来分类图像。
编码器与CNN是相似的,它只是一个网络,接受一个输入,产生一个小得多的表示(编码),并且能包含足够的信息,为网络的下一部分提供所需的输出格式。 通常,编码器与网络的其他部分一起训练,通过反向传播进行优化,以产生对于手头任务特别有用的编码。 就像在CNN中,所生成的1000维编码对于分类特别有用。
Autoencoders采取这个想法,并使编码器生成的编码有利于重建自己的输入。
整个网络通常作为一个整体进行训练。损失函数通常是输出和输入之间的均方误差或交叉熵,称为重构损失,这会限制网络网络输入与输出的不同。
由于编码(它仅仅是中间隐藏层的输出)比输入少得多,所以编码器必须选择丢弃信息。编码器学习在有限的编码中保留尽可能多的相关信息,并智能地丢弃不相关的部分。解码器学习采取编码,并妥善重建成一个完整的形象。他们一起组成一个自动编码器。
▌标准自动编码器的问题
标准自动编码器学会生成紧凑的表示和重建他们的输入,但除了能用于一些应用程序,如去噪自动编码器,他们是相当有限的。
自动编码器的基本问题在于,它们将其输入转换成其编码矢量,其所在的潜在空间可能不连续,或者允许简单的插值。
例如,在MNIST数据集上训练一个自编码器,并从2D潜在空间中可视化编码,可以看到不同簇的形成。 这是有道理的,因为每种图像类型的不同编码使得解码器对它们进行解码变得更容易。如果你只是复制相同的图像,这是不错的。
但是当你建立一个生成模型时,你不想准备复制你输入的相同图像。你想从潜在的空间随机抽样,或者从一个连续的潜在空间中产生输入图像的变化。
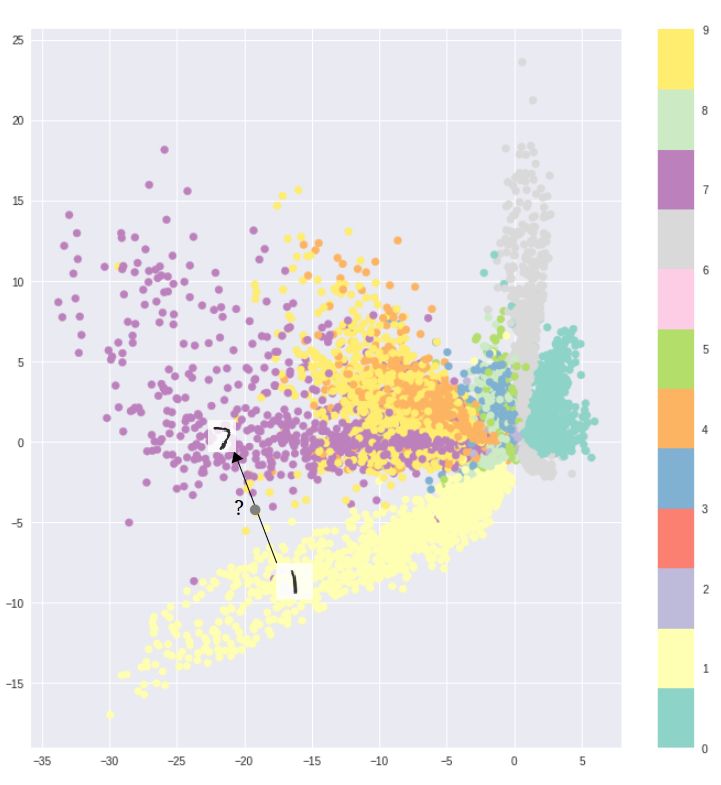
如果空间有不连续性(例如簇之间的间隙)并且从那里采样/产生变化,则解码器将产生不切实际的输出,因为解码器不知道如何处理该潜在空间的区域。 在训练期间,从未看到来自该潜在空间区域的编码矢量。
▌变分自动编码器
变分自动编码器(VAEs)具有一个独特的性质,可以将它们与vanilla自动编码器分离开来,正是这种特性使其在生成建模时非常有用:它们的潜在空间在设计上是连续的,允许随机采样和插值。
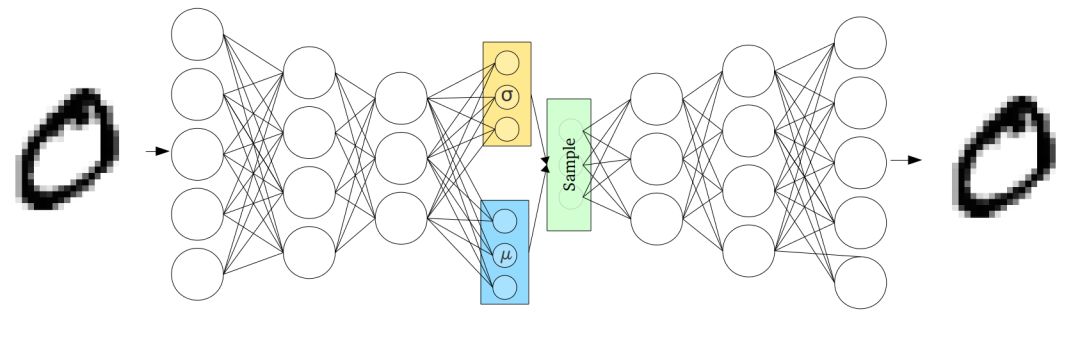
它通过做一些约束来达到这个目的:使编码器不输出大小为n的编码矢量,而是输出两个大小为n的矢量:平均矢量μ和另一个标准偏差矢量σ。
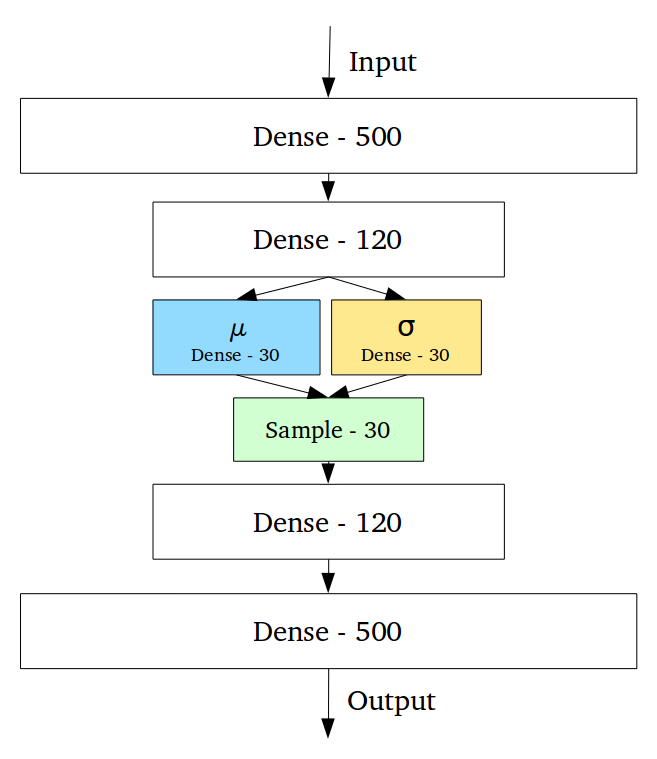

这种随机生成意味着,即使对于相同的输入,虽然平均值和标准偏差保持不变,但是实际编码会在采样过程中发生些许变化。
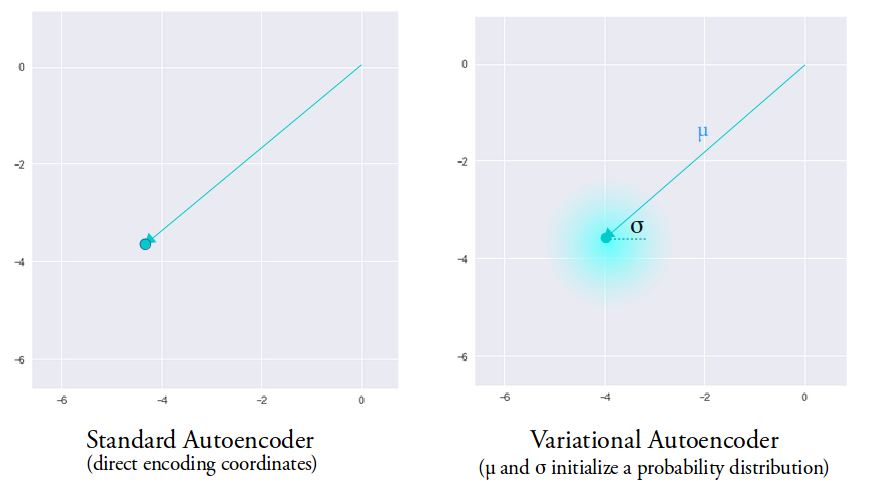
直观地,平均向量控制输入的编码的中间位置,而标准偏差控制“区域”,即编码可以改变多少。 由于编码是从“圆”(分布)内的任意位置随机产生的,因此解码器不仅可以获得指向该类样本的潜在空间中的单个点,而且所有附近的点也都是相同的。 这使得解码器不仅能够解码潜在空间中的单个特定编码(使可解码的潜在空间不连续),而且还能够稍微改变,因为解码器作用在相同输入编码的一系列变化上。 在代码中:
# build your encoder upto here. It can simply be a series of dense layers,
a convolutional network
# or even an LSTM decoder. Once made,
flatten out the final layer of the encoder, call it hidden.
latent_size = 5
mean = Dense(latent_size)(hidden)
# we usually don't directly compute the stddev σ
# but the log of the stddev instead, which is log(σ)
# the reasoning is similar to why we use softmax,
instead of directly outputting
# numbers in fixed range [0, 1], the network can
output a wider range of numbers which we can later compress down
log_stddev = Dense(latent_size)(hidden)
def sampler(mean, log_stddev):
# we sample from the standard normal a matrix of batch_size * l
atent_size (taking into account minibatches)
std_norm = K.random_normal(shape=(K.shape(mean)[0], latent_size),
mean=0, stddev=1)
# sampling from Z~N(μ, σ^2) is the same as
sampling from μ + σX, X~(0,1)
return mean + K.exp(log_stddev) * std_norm
该模型现在通过改变一个样本的编码而产生一定程度的局部变化,导致在局部尺度上潜在空间的平滑,即产生相似的样本。 理想情况下,为了在类之间进行插值,我们希望样本之间的重叠也不太相似。 然而,由于对矢量μ和σ可以采用什么样的值没有限制,编码器可以学习为不同的类别生成非常不同的μ,将它们聚类在一起并使σ最小,从而确保对于相同的样本编码本身的变化不大(即解码器的不确定度较低)。 这允许解码器有效地重建训练数据。
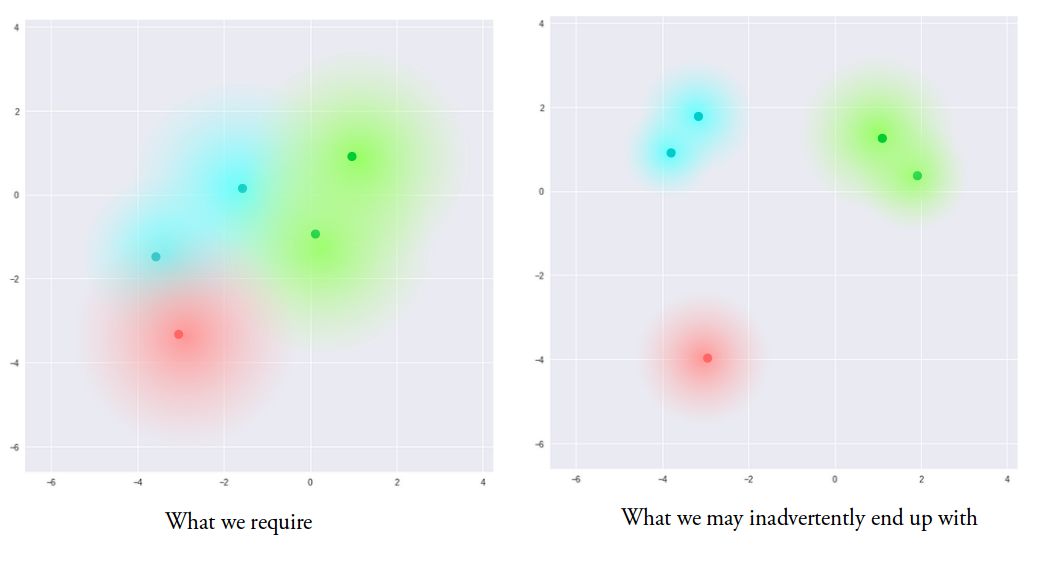
我们理想的要求是编码,所有这些编码尽可能地彼此接近,但仍然是独特的,允许平滑插值,并且能够构建新的样本。
为了强制做到这一点,我们在损失函数中引入Kullback-Leibler散度(KL散度[2])。 两个概率分布之间的KL散度只是衡量它们相互之间有多大的分歧。 这里最小化KL散度意味着优化概率分布参数(μ和σ),使其与目标分布的概率分布参数非常相似。
对于VAE,KL损失是X中个体X〜N(μ,σ²)与标准正态分布[3]之间所有KL分支的总和。 当μ= 0,σ= 1时,最小化以下公式。
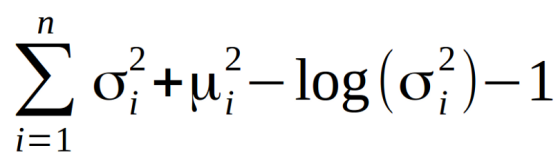
直观地说,这种损失鼓励编码器将所有编码(对于所有类型的输入,例如所有MNIST数字号)均匀地分布在潜在空间的中心周围。 如果它试图通过把它们聚集到特定的地区而远离原样本来“作弊”,将会受到惩罚。
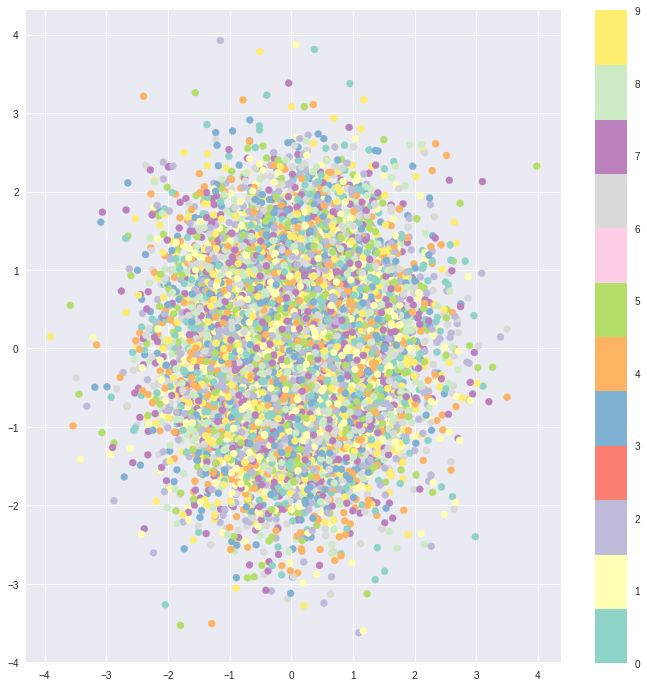
现在,使用纯粹的KL损失导致潜在空间的编码密集地分布在潜在空间的中心附近,几乎不考虑临近编码之间的相似性。 解码器认为从这个空间不可能解码出任何有意义的东西,因为它确实没有任何意义。
然而,将两者一起进行最优化会导致产生一个潜在的空间,其通过聚类来保持邻近编码在局部尺度上的相似性,然而在全局范围内,在潜在空间的原始位置附近(比较轴与原始轴)是非常密集的。
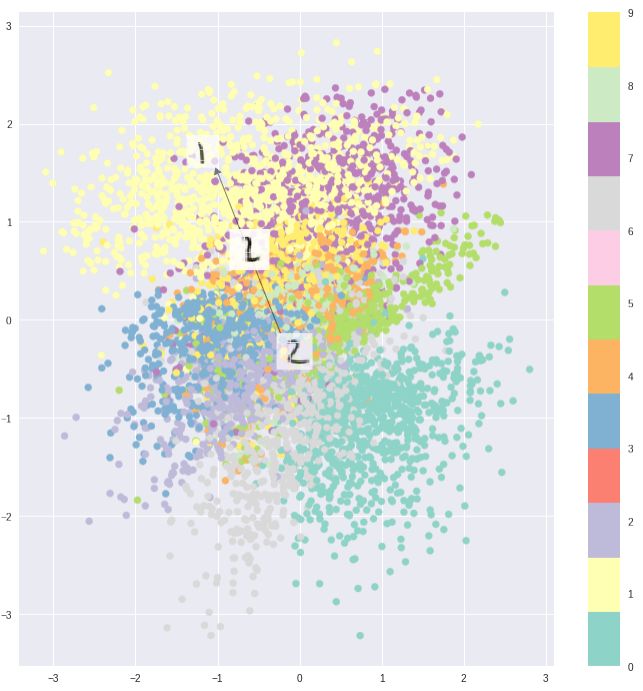
直观地说,这是由重建损失的集群形成性质和KL损失的密集包装性质达到的平衡,形成解码器可以解码的不同簇。 这很好,因为它意味着当随机生成时,如果从编码向量的相同分布(N〜(0,I))中采样一个向量,则解码器将成功解码它。 而且,如果你正在插入,那么在簇之间没有突然的间隙,但是一个平滑的组合特征是解码器可以理解的。
def vae_loss(input_img, output):
# compute the average MSE error, then scale it up, ie.
simply sum on all axes
reconstruction_loss = K.sum(K.square(output-input_img))
# compute the KL loss
kl_loss = - 0.5 * K.sum(1 + log_stddev - K.square(mean) -
K.square(K.exp(log_stddev)), axis=-1)
# return the average loss over all images in batch
total_loss = K.mean(reconstruction_loss + kl_loss)
return total_loss
▌矢量运算
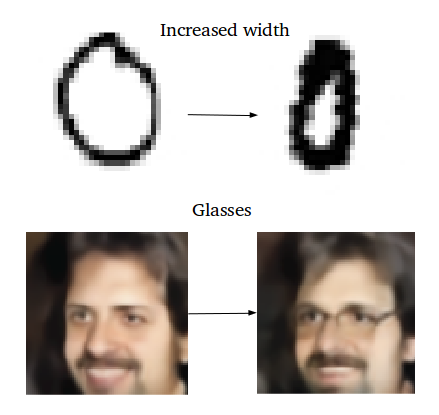
那么我们如何产生这些我们所说的平滑插值呢?在这里,可以认为是在潜在空间上简单的矢量运算。
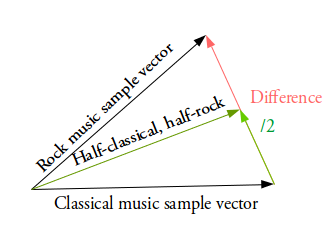
例如,如果您希望在两个样本之间的中间位置生成一个新的样本,只需找出它们的样本向量之间的差异,并将差异的一半加到原始样本上,然后对其进行简单的解码即可。
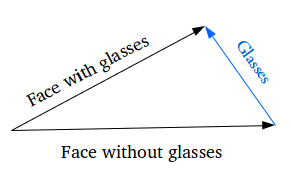
添加新的样本特征如何生成特定的特征?如在脸上生成眼镜。首先,找到两个样本,一个戴眼镜,一个没有,从编码器获得它们的编码矢量,并保存差异。 将这个新的“眼镜”矢量添加到其他脸部图像,并解码它。
▌下一个研究方向?
在变分自动编码器上还存在很多需要改进的地方。 实际上,你可以用一个卷积 - 解卷积编码器 - 解码器对(比如这个项目[4])替换标准的全连接的密集编码器 - 解码器来产生很好的合成人脸照片。

您甚至可以使用LSTM编码器 - 解码器对来训练一个自动编码器,用于连续的,离散的数据(用GAN等方法不可能实现的),生成合成文本,甚至插入MIDI样本之间,如Google Brain的Magenta MusicVAE [5]:
VAE可以处理明显不同类型的数据,顺序或非顺序,连续或离散,标记或完全不标记,使其成为非常强大的生成工具。 我希望你现在能够理解VAE是如何工作的,而且你也可以在自己的研究中使用它们。
Notes
Latent Constraints: Conditional Generation from Unconditional Generative Models
Kullback-Leibler Divergence Explained
KL divergence between two univariate Gaussians
Deep Feature Consistent Variational Autoencoder
Hierarchical Variational Autoencoders for Music
Further reading:
Tutorial on Variational Autoencoders
Tutorial — What is a variational autoencoder?
Implementations:
Building Autoencoders in Keras
Convolutional-deconvolutional autoencoder in Keras
参考链接:
https://towardsdatascience.com/intuitively-understanding-variational-autoencoders-1bfe67eb5daf
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



