【深度前沿】基于深度学习的智能视频分析,微软亚洲研究院梅涛博士ACM MM 2017 Tutorial解读
【导读】第25届ACM国际多媒体会议(ACM Multimedia, 简称ACM MM)于2017年10月23日至27日在美国硅谷Mountain View隆重举行。微软亚洲研究院资深研究员梅涛博士为大会带来了题为《Deep Learning for Intelligent Video Analysis》的分享报告, 介绍了基于深度学习的智能视频分析相关的最新成果。为此,专知内容组整理了的梅涛博士的slides,进行了解读,请大家查看,并多交流指正! 此外,请查看本文末尾,可下载最新ACM MM 2017 slide。
Deep Learning for Intelligent Video Analysis
基于深度学习的智能视频分析
【摘要】
视频分析是近几十年来计算机视觉和多媒体领域最根本研究课题之一。这是一个非常具有挑战性的问题,因为通常视频是一个有着有很大的差异性和复杂性的信息密集媒体。由于深度学习技术的发展,计算机视觉和多媒体领域的研究人员现在利用深度学习技术能够大幅度的提高视频分析的性能,并开始在分析视频上开辟了许多新的研究方向。本教程将介绍视频分析理解研究的最新进展,从最前沿的深度学习所广泛采用的基础神经网络模型开始讲起,到视频表示学习和视频分类及识别的基本挑战,最终到计算机视觉和语言领域的一些新兴领域。
这是根据梅涛老师在ACM Multimedia 2017上的tutorial记录而来,梅涛老师的个人主页是:https://www.microsoft.com/en-us/research/people/tmei/。
本Tutorial Slide材料获梅涛博士授权发布。由于笔者能力有限,本篇所有备注皆为专知内容组成员通过ACM Multimedia 2017上的tutorial记录自行补全,不代表梅涛博士本人的立场与观点,特此注明。

这一页就开始了基于深度学习的智能视频分析的介绍了。
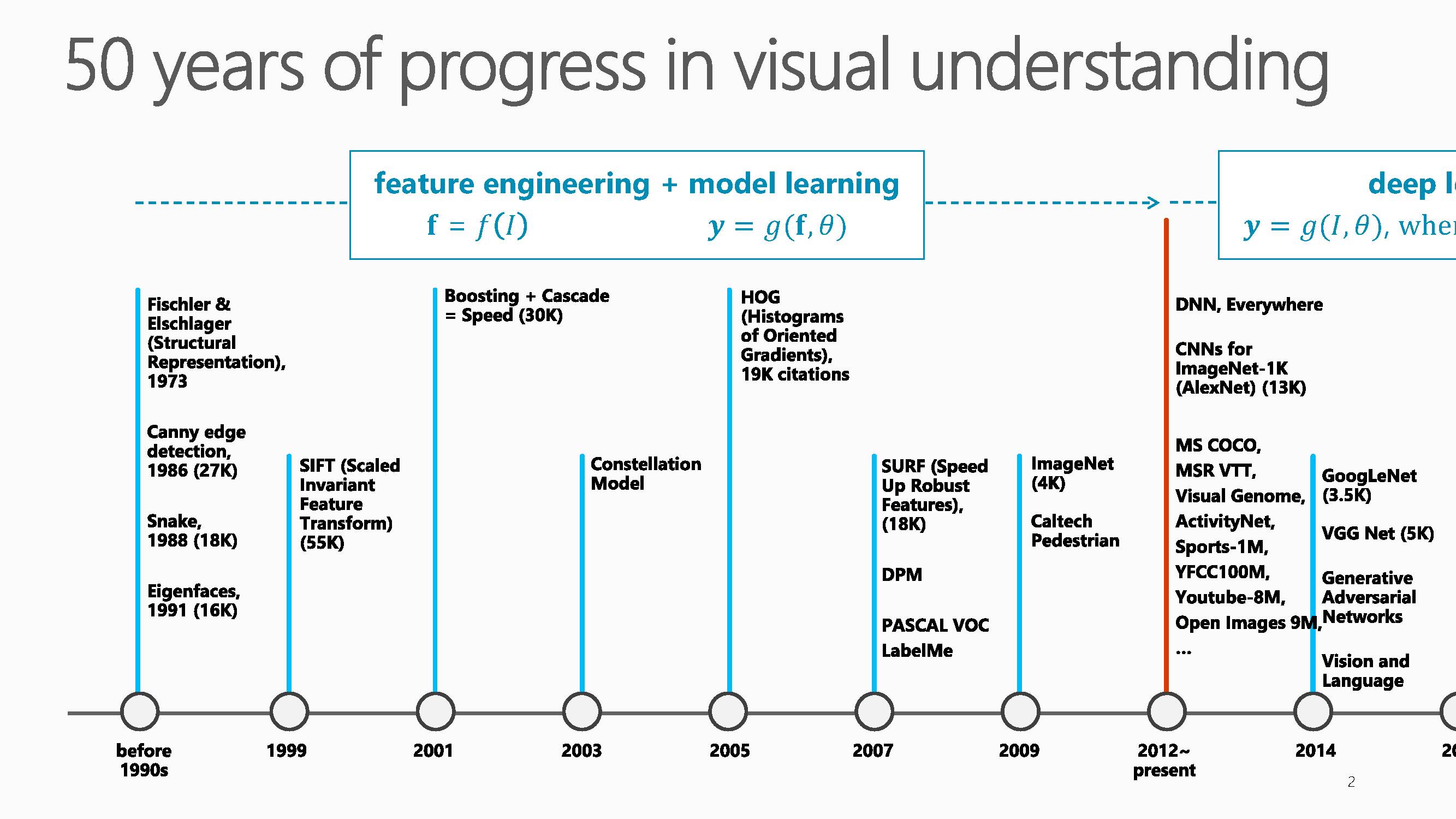
近五十年的视觉理解研究进程可以分为两大阶段,第一个阶段是2012年之前的特征工程+模型学习方法,第二个阶段是2012年至今的深度学习方法。
大家可以从这个图中看到CV的一些进展,举几个例子,比如说这篇论文SIFT(Scaled Invariant Feature Transform)文,已经被引用55000次了。另外,如果大家做人脸识别就会知道,需要定位人脸的区域。梅涛老师团队在2001年有一个方法是Boosting +Cascade,做快速的人脸定位。到今天为止,虽然大家知道做人脸定位有很多深度学习的方法,但是这个方法依然是最先的必经的步骤之一。这个论文到目前为止已被引用了30000次,在学术界有一篇论文被引用超过10000次已经是相当了不起了。到了2012年以后,基本上所有人都在用深度学习,从Hinton的学生用AlexNet在ImageNet上面能得到近乎15%的错误率,从那开始,所有视觉的东西都在用CNN,代表性的有GoogLeNet,AlexNet等等,我们的任务也会越来越多,越来越有挑战,比如现在正在做的从图片中生成语言,不仅要在图片或视频中打上一些标签,还要把这些标签变成能用自然语言描述的一句话。
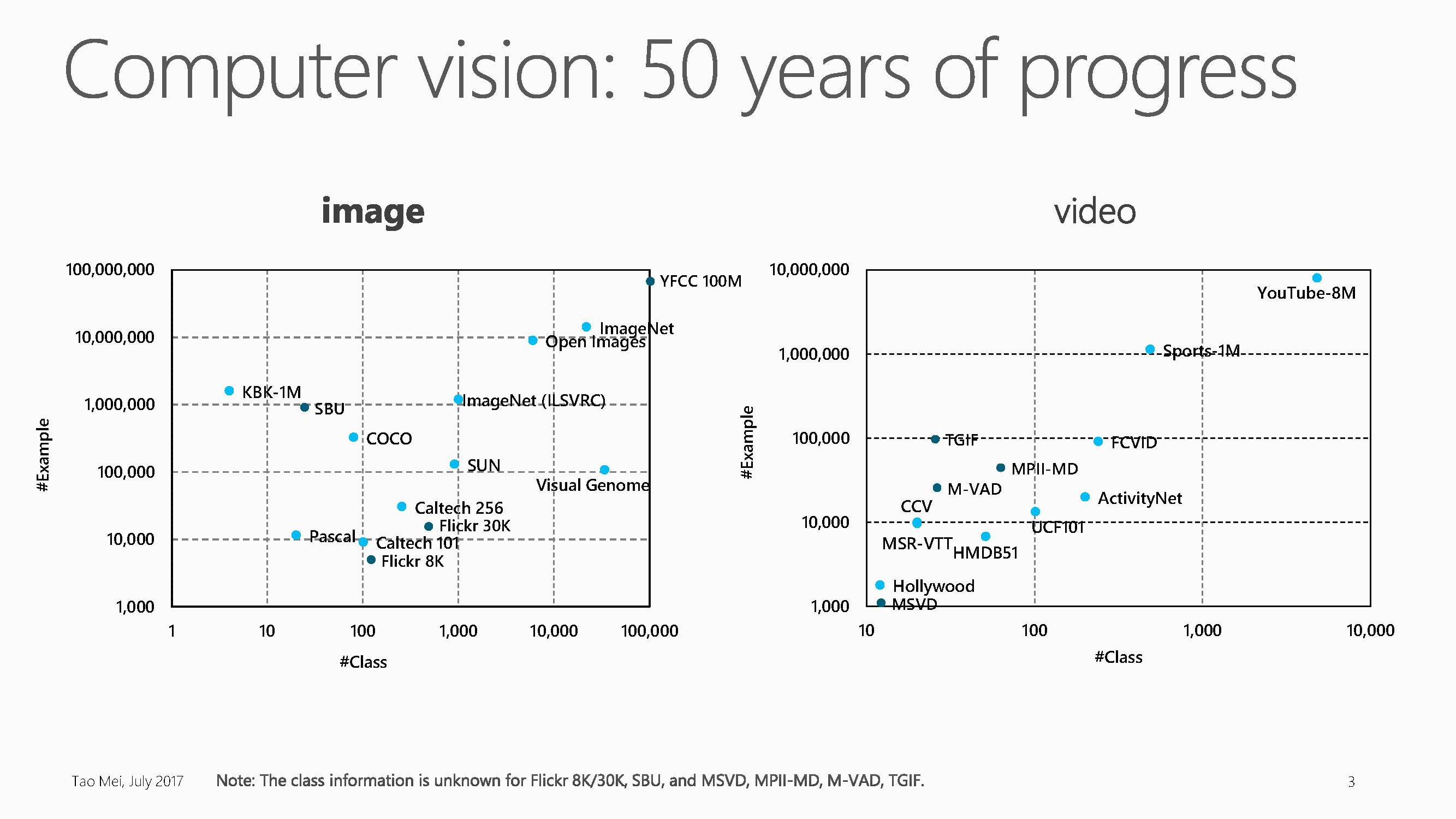
这五十年来,用于计算机视觉研究的数据库规模也呈爆发式增长。
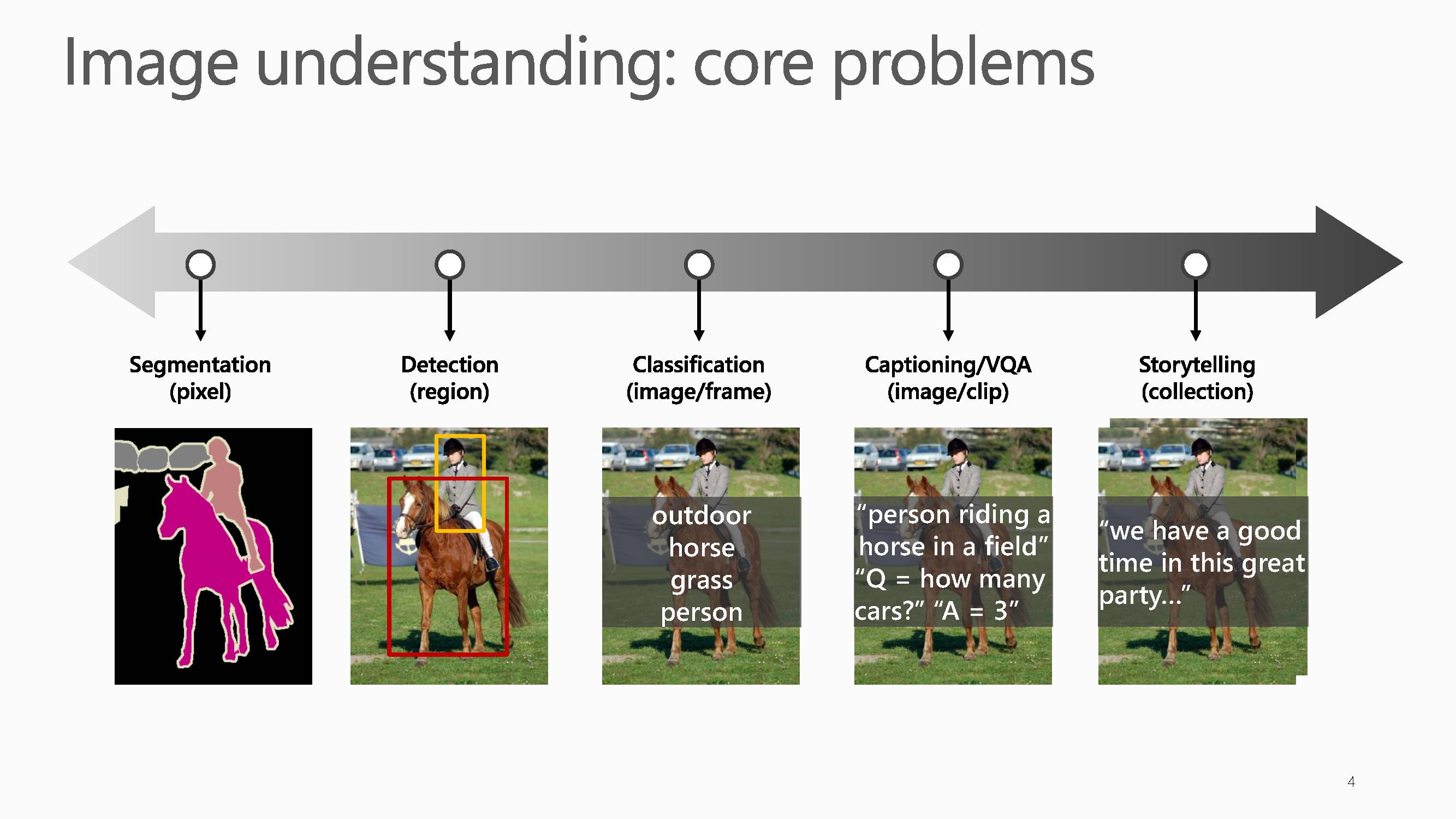
图像理解主要包含五大核心问题:
图像分割、目标检测、图像分类、图像文字描述、图像故事生成。
这五大核心问题目前的最好的解决方案都是基于深度学习算法的。
如果把这五个核心问题展开来看,从像素级别理解图片、视频的步骤如下:
第一步确定每个像素属于什么类;
第二步是区域识别,此时不关心每个像素类别但是关心边界在什么位置;
第三步是传统分类;
第四步要根据视频生成词汇,最后生成句子。
第五步更深入研究能否根据照片生成一个完整的故事描述。
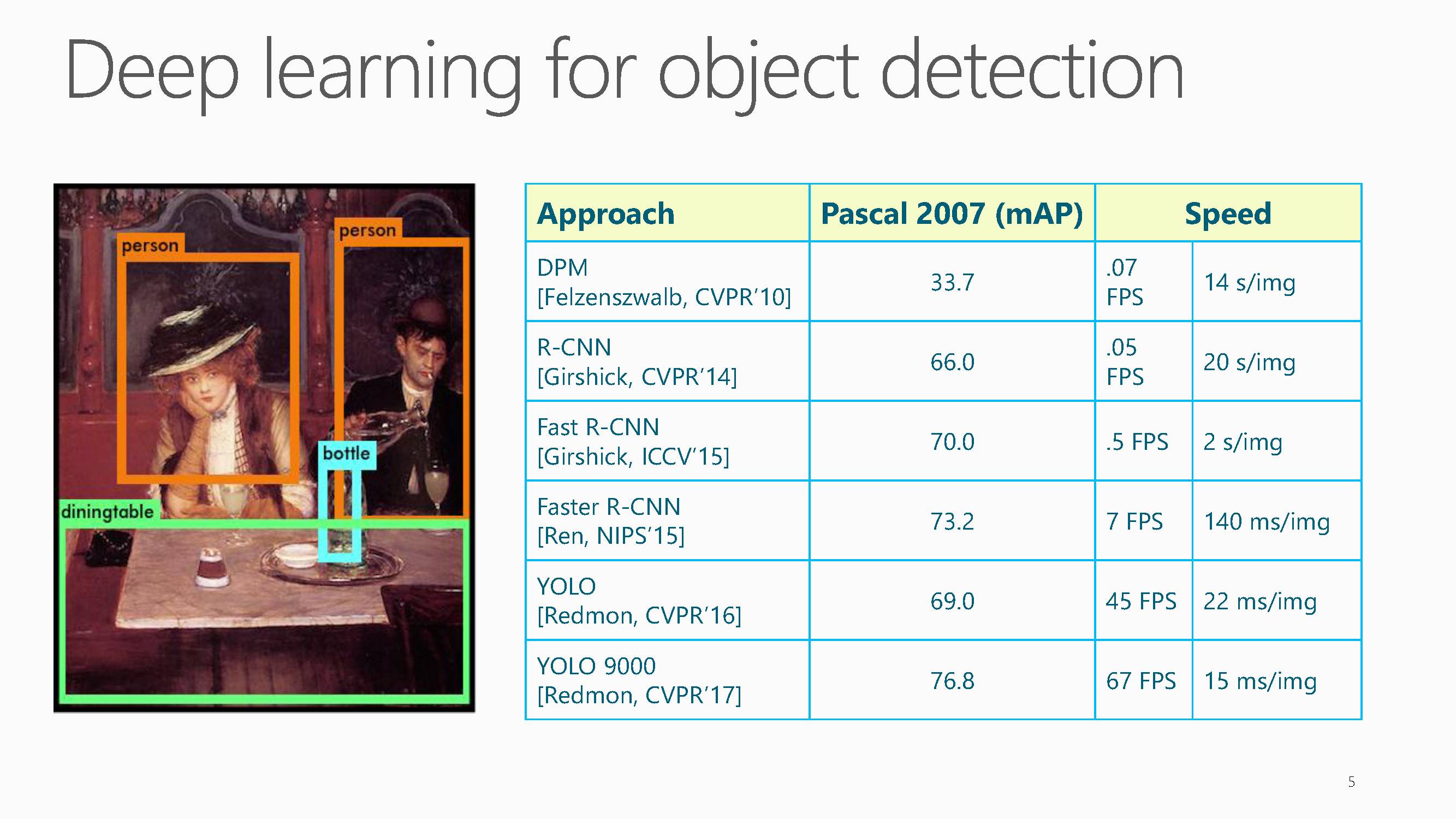
在目标检测中,从DPM, R-CNN, Fast R-CNN,Faster R-CNN到YOLO, YOLO 9000,基于深度学习的物体检测精度越来越高,速度越来越快。

在图像分割中,基于深度学习的方法也取得了令人振奋的效果,如上图是在COCO数据集上的分割效果。

在Image captioning 中,这是基于深度学习的图像文字描述生成效果,从右边图可以看出目前的效果更加精细化。
左图是两年前生成的结果。微软有一个MicrosoftCaptionBot 产品,当你上传图片的时候CaptionBot会告诉你这张图片内容是:a boat is docked in front of a building 。在一年前进行了改进,在生成文字描述的时候又加入其他信息。比如右侧图片人们站在建筑前,同时给出了每个人对应的名字。但是其中一个人没有对应人名,这是因为奥巴马的母亲不在庆典邀请列表里,这是一个问题。改进后的技术不仅可以识别人的名字,还能做场景理解的任务。这是image caption,对于视频也是一样的。

基于深度学习生成的诗歌已经出版(微软小冰的结果)。小冰还可以写诗,最近发表了一个小冰诗集。小冰说:“看那星,闪烁的几颗星,西山上的太阳,青蛙儿正在远远的浅水,她嫁给了人间许多的颜色”。

将深度学习的任务和人的智力水平结合起来,可以认为,物体分类、检测与分割达到的是3岁孩童的水平。视觉文字描述、诗歌生成、视觉问答达到的是5岁孩童的水平。

当前,全世界现在每天有超过50%的人在线看视频,每天在Facebook上会观看37亿个视频,YouTube上每天会观看5亿小时时长的视频。我们做视频,大家首先想到的就是做广告,视频上面的广告每年都是30%的速度递增的,在YouTube上面也是每年30%的增长态势。人们在视频上花的时间是图片上的2.6倍。视频的生成比文字和图片要多1200%。

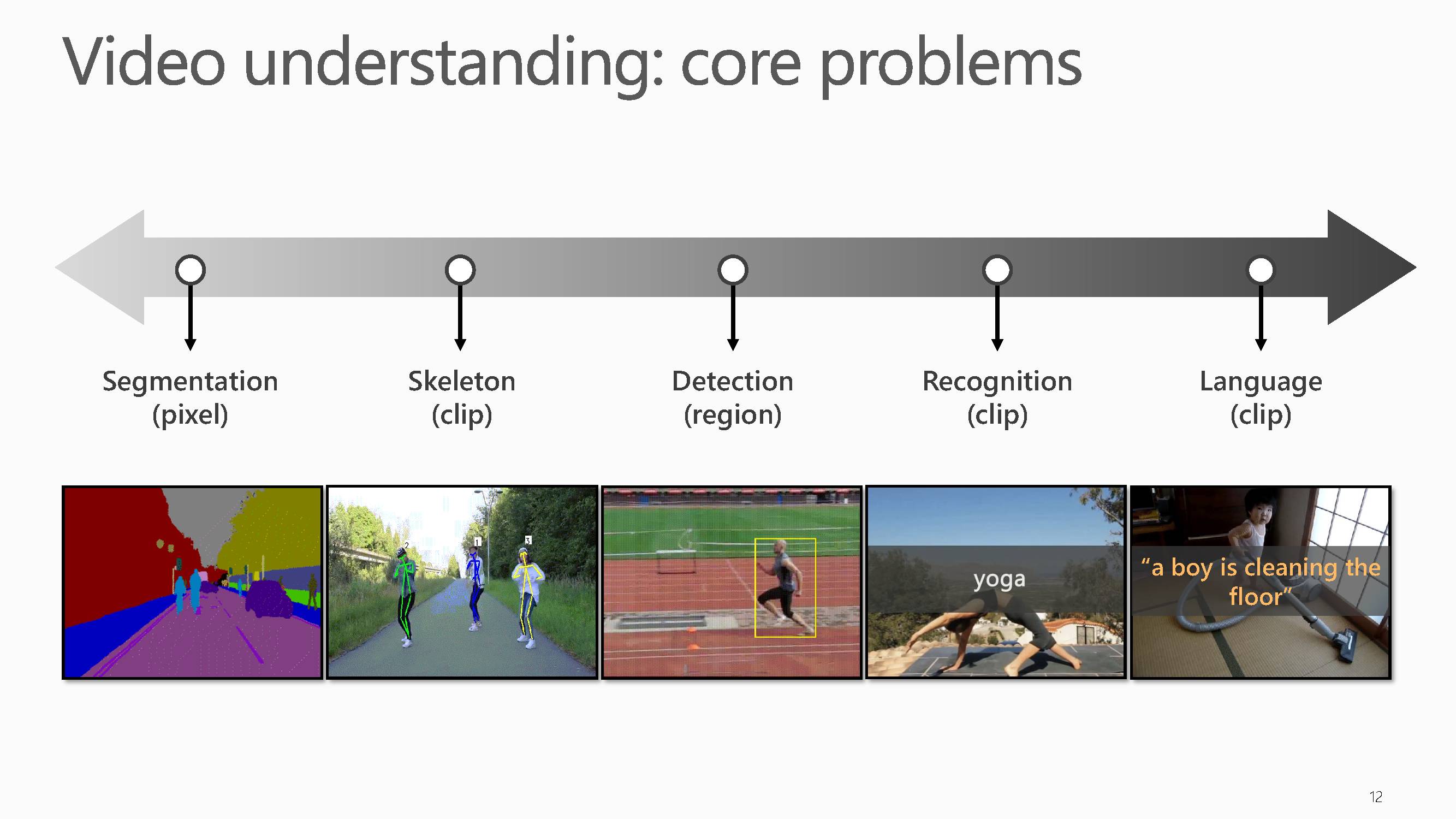
从图像到视频,理解一个视频必须理解每一个帧里面的运动。视频场景理解同样包含五大主要任务:
视频像素分割、视频目标骨架提取、视频物体检测、视频目标识别、视频文字描述生成。

关于视频的理解,梅涛老师主要介绍了四大部分内容。
视频表示学习
视频分类(又称动作识别)
视频文字描述
视频语义分割
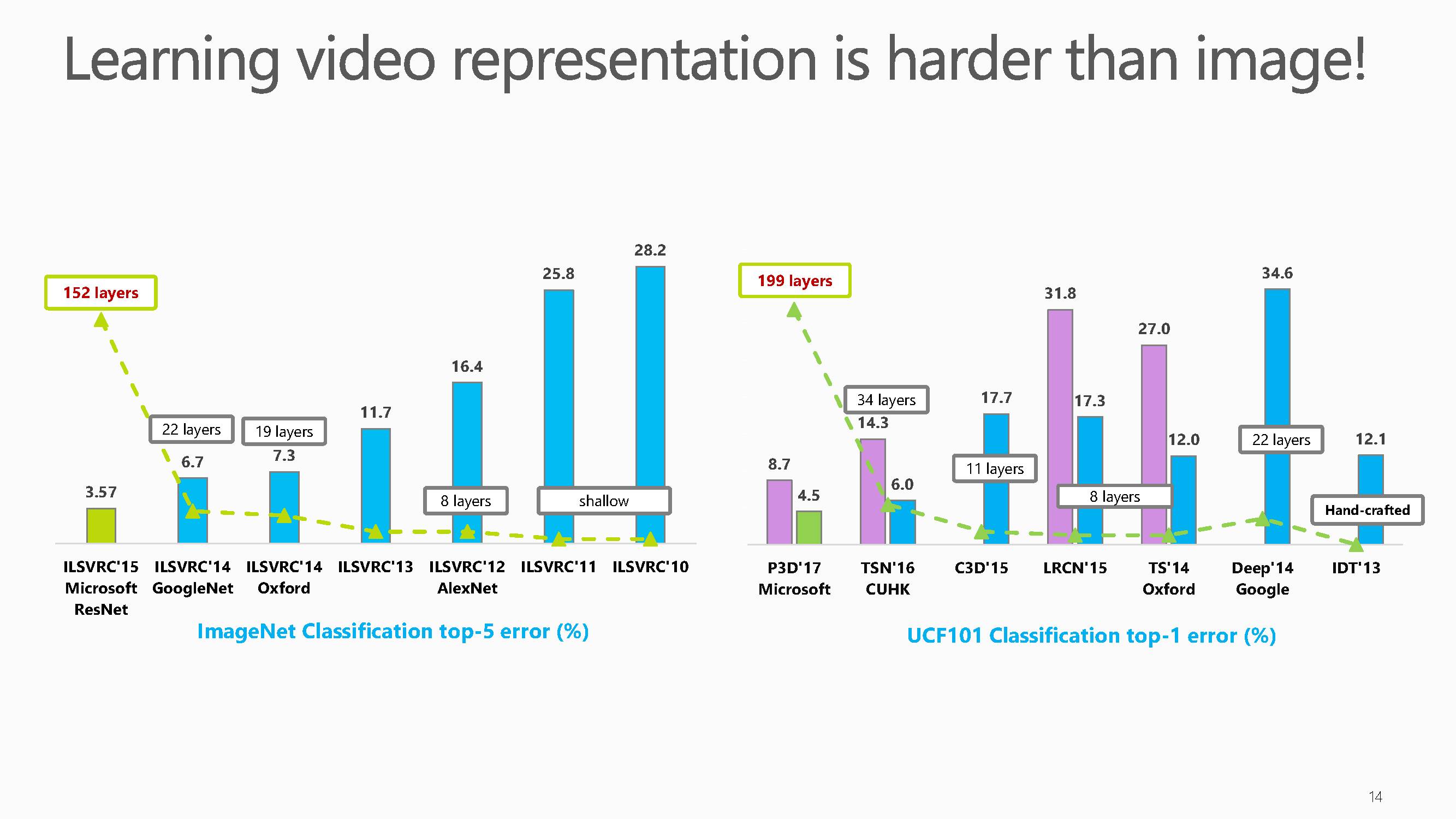
这张图对比了深度学习近年来在图像数据集ImageNet 和视频数据集UCF-101数据集上的结果,从中我们可以看出视频表示学习显著难于图片内容表示。
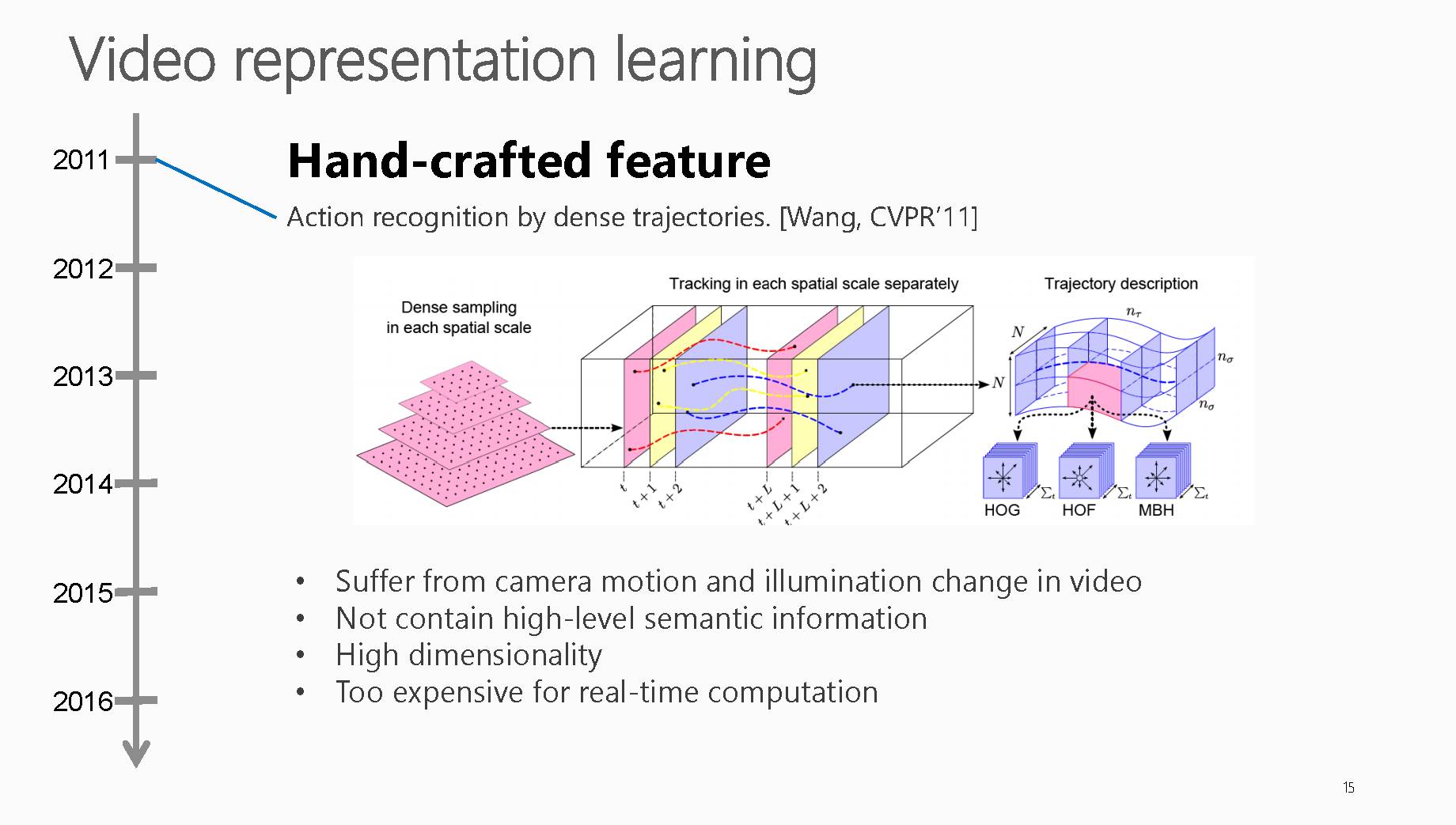
视频表示学习早期广泛使用的方法是手工特征的提取。
这类方法有着四大明显缺点:
对于相机运动和光照变化较为敏感
不包含高层语义信息
特征维度太高
计算太耗时
PPT中提到文献是CVPR2011年,文献标题是:Actionrecognition by dense trajectories,
网址链接:http://ieeexplore.ieee.org/document/5995407/
也是早期比较有代表性使用Dense Trajectories算法来对人的运动轨迹进行描述。
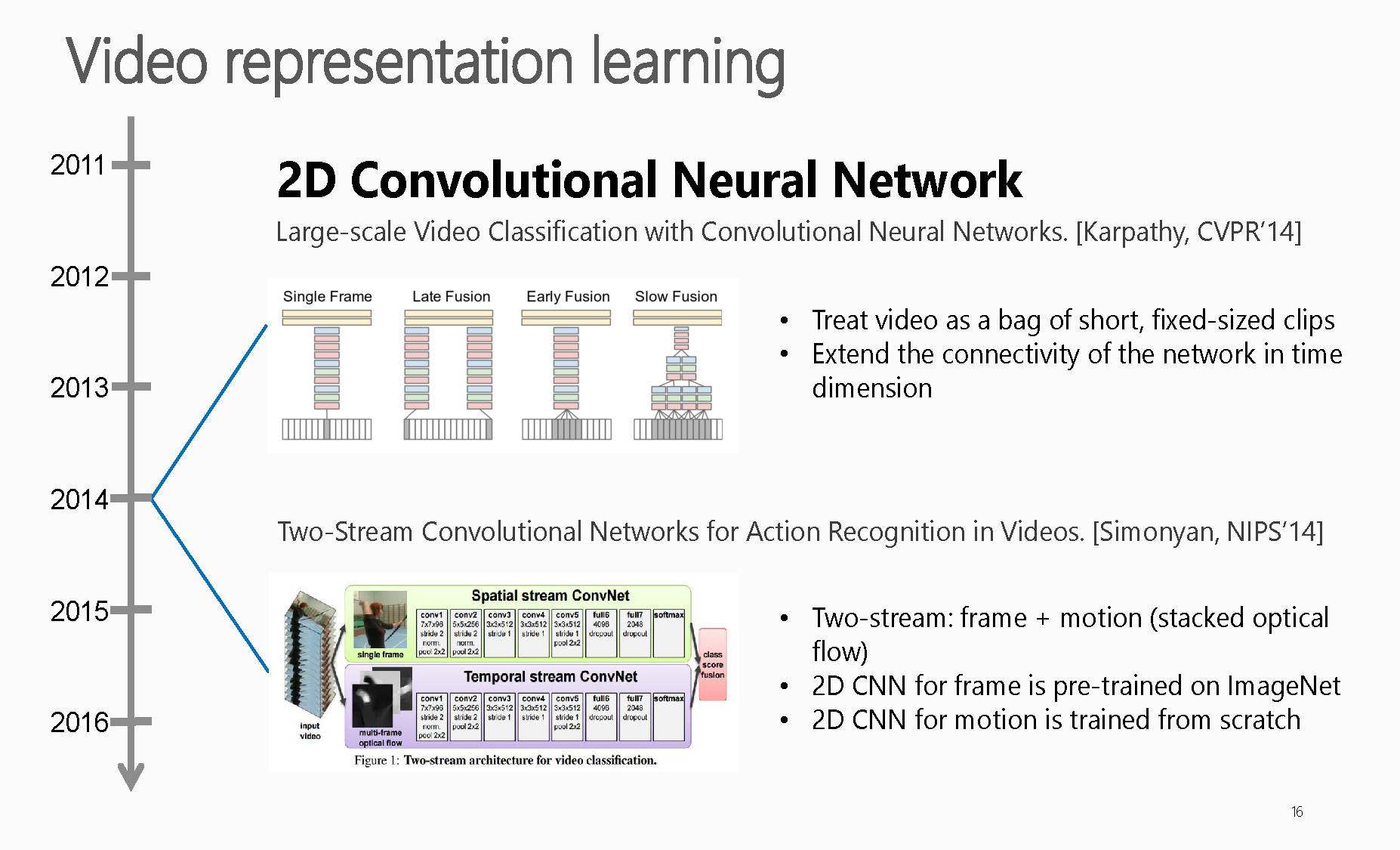
随着深度学习技术的发展,早期基于深度学习的视频表示是基于2D卷积神经网络(2D-CNN),
上述提及的是一篇是CVPR2014的,文章标题是
Large-scale Video Classification withConvolutional Neural Networks, CVPR2014,链接:http://ieeexplore.ieee.org/document/6909619/。
文章在多种方法上将CNNs延伸到大规模数据集的视频分类上,其贡献点是.将CNN拓展,用于视频分类,使用两种不同的分辨率的帧分别作为输入,输入到两个CNN中,在最后的两个全连接层将两个CNN统一起来,两个流分别是低分辨率的内容流和采用每一个帧中间部分的高分辨率流,并且应用提出的网络在UCF101数据集,得到了当时比较好的效果。
另一篇是NIPS2014,文章标题是Two-Stream Convolutional Networks for Action Recognition in Videos,链接是:https://arxiv.org/abs/1406.2199。
这篇文章是比较经典的一篇将双流网络应用到动作识别上的一篇论文,大体意思是将视频分帧送入第一个卷积神经网络进行训练来提取静态特征,同时将从视频中提取出的光流图送进另外一个卷积神经网络来提取动态特征。最终将两个网络softmax层输出的分值进行一个融合。
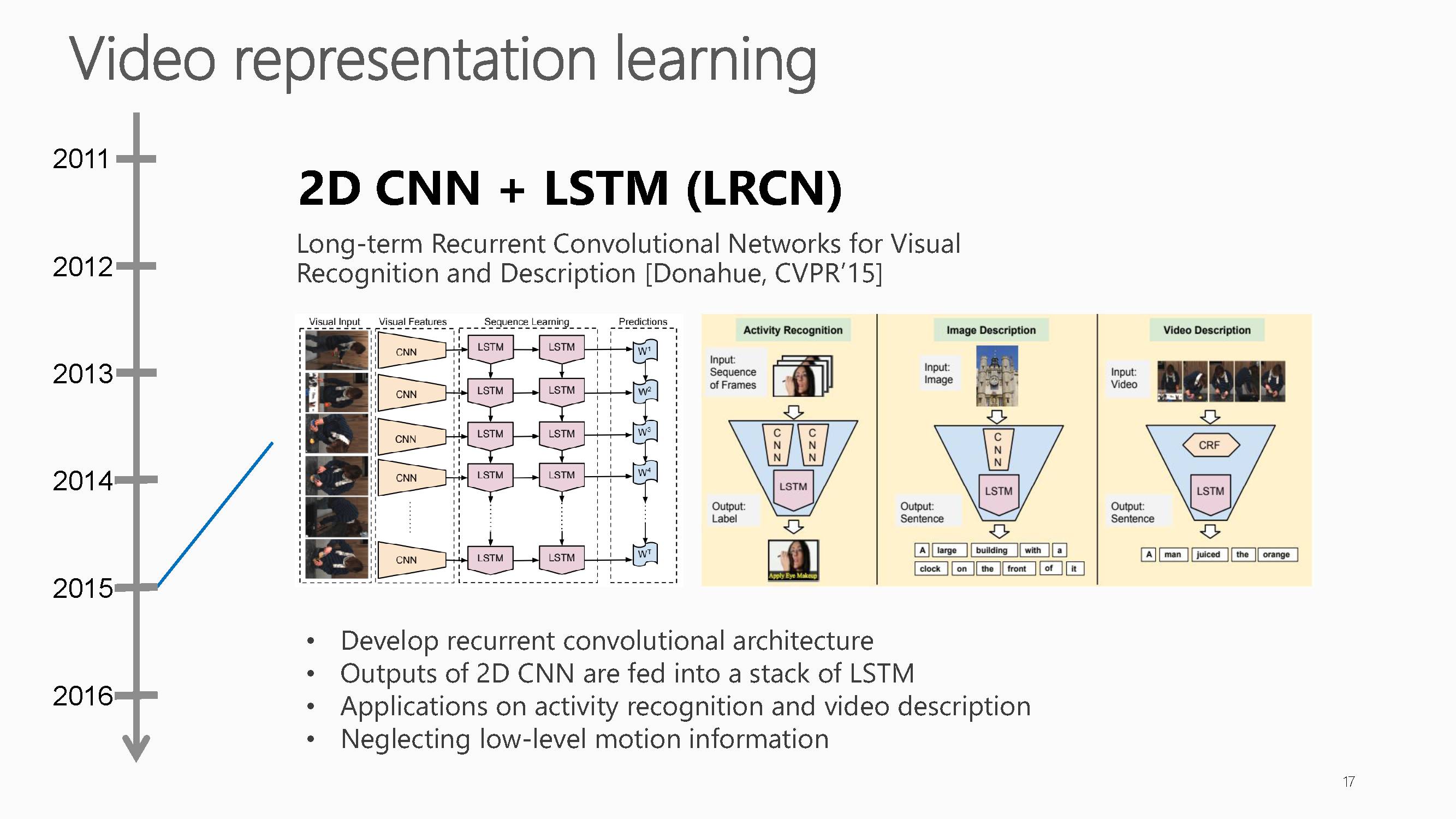
随后2015年有研究将2D-CNN与LSTM结合起来学习时序信息。但基于2D-CNN的方法忽略了视频的底层运动信心。
这篇工作是CVPR2015,文章标题是Long-term Recurrent Convolutional Networks for Visual Recognitionand Description,
链接是:https://arxiv.org/abs/1411.4389。
这篇是属于很早探索cnn+rnn解决高层次视频理解的文章。
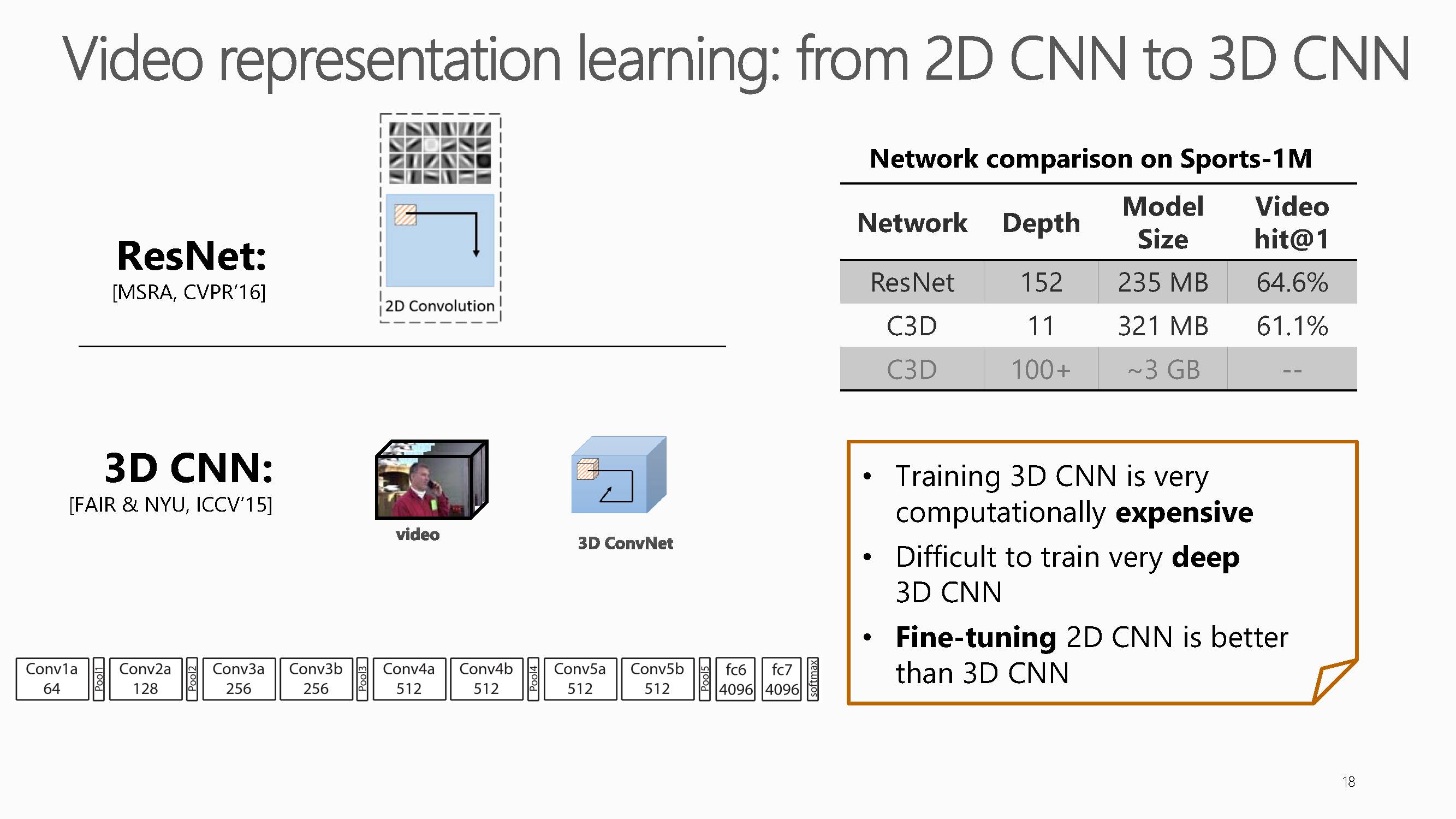
为了解决2D-CNN的缺陷,随后3D-CNN网络被提出。但传统3D-CNN缺点也较为明显,
1、训练耗费资源、
2、很难训练较深的3D-CNN网络。
3、2d方式微调后比3d更好
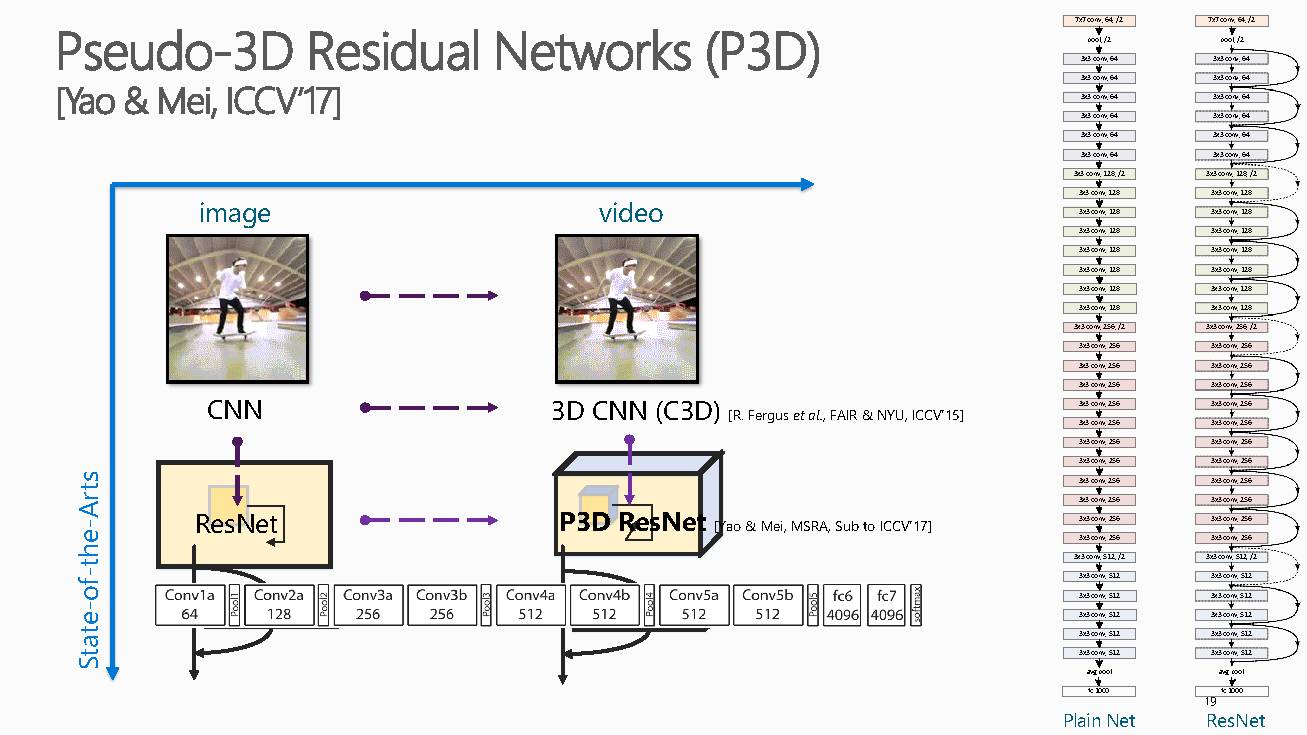
基于上述问题,梅涛老师组里在ICCV2017上发表了一篇P3D网络,获得了目前最好的视频表示能力。
这项工作主要集中在如何利用大量视频数据来训练视频专用的深度三维卷积神经网络,它提出了一种基于伪三维卷积(Pseudo-3D Convolution)的深度神经网络的设计思路,并实现了迄今为止最深的199层三维卷积神经网络。通过该网络学习到的视频表达,在多个不同的视频理解任务上取得了稳定的性能提升。具体可以看下面文章原文理解,具体就不介绍了。
文章标题Learning Spatio-TemporalRepresentation with Pseudo-3D Residual Networks,
链接:https://www.microsoft.com/en-us/research/wp-content/uploads/2017/10/iccv_p3d_camera.pdf
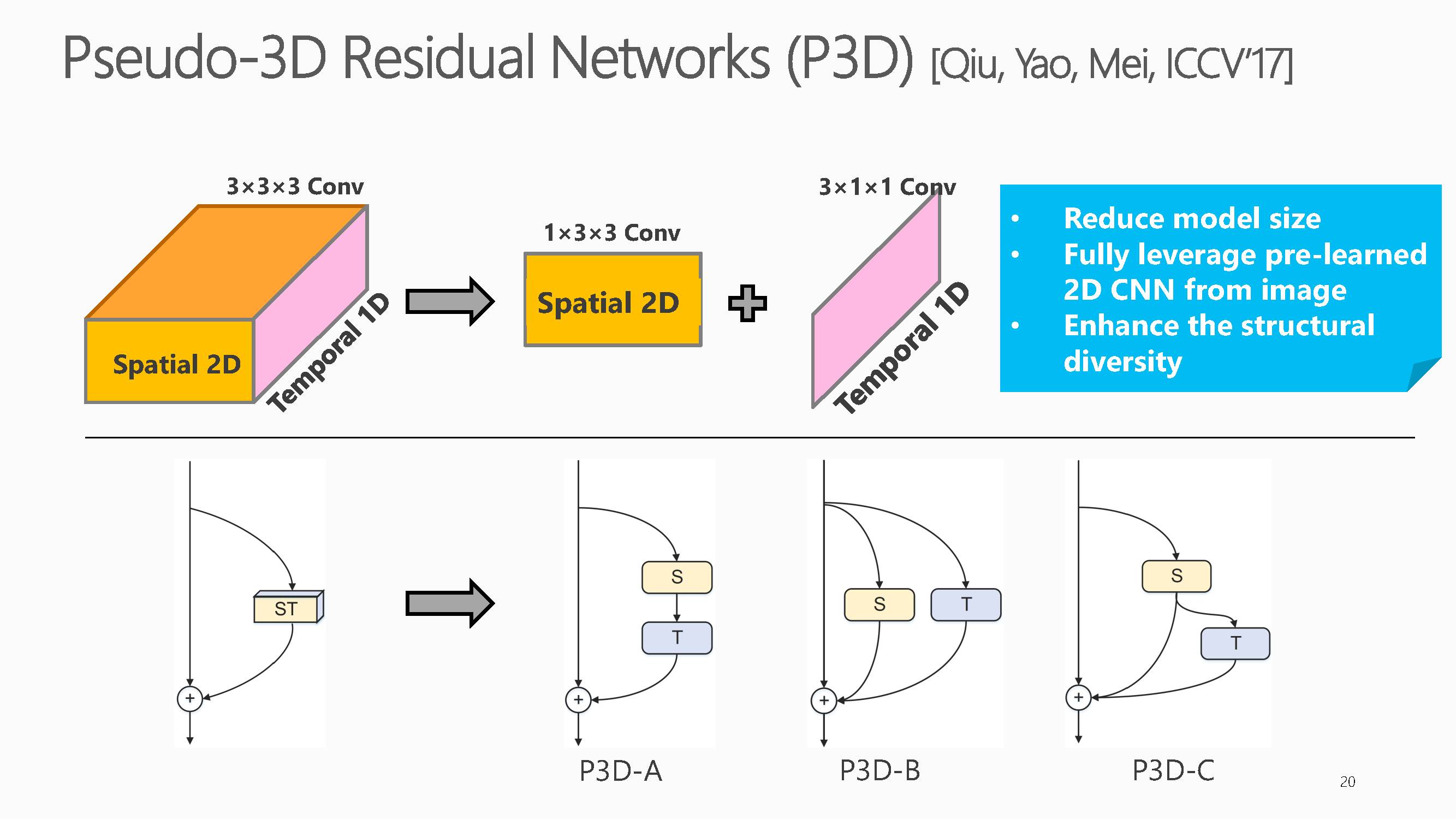
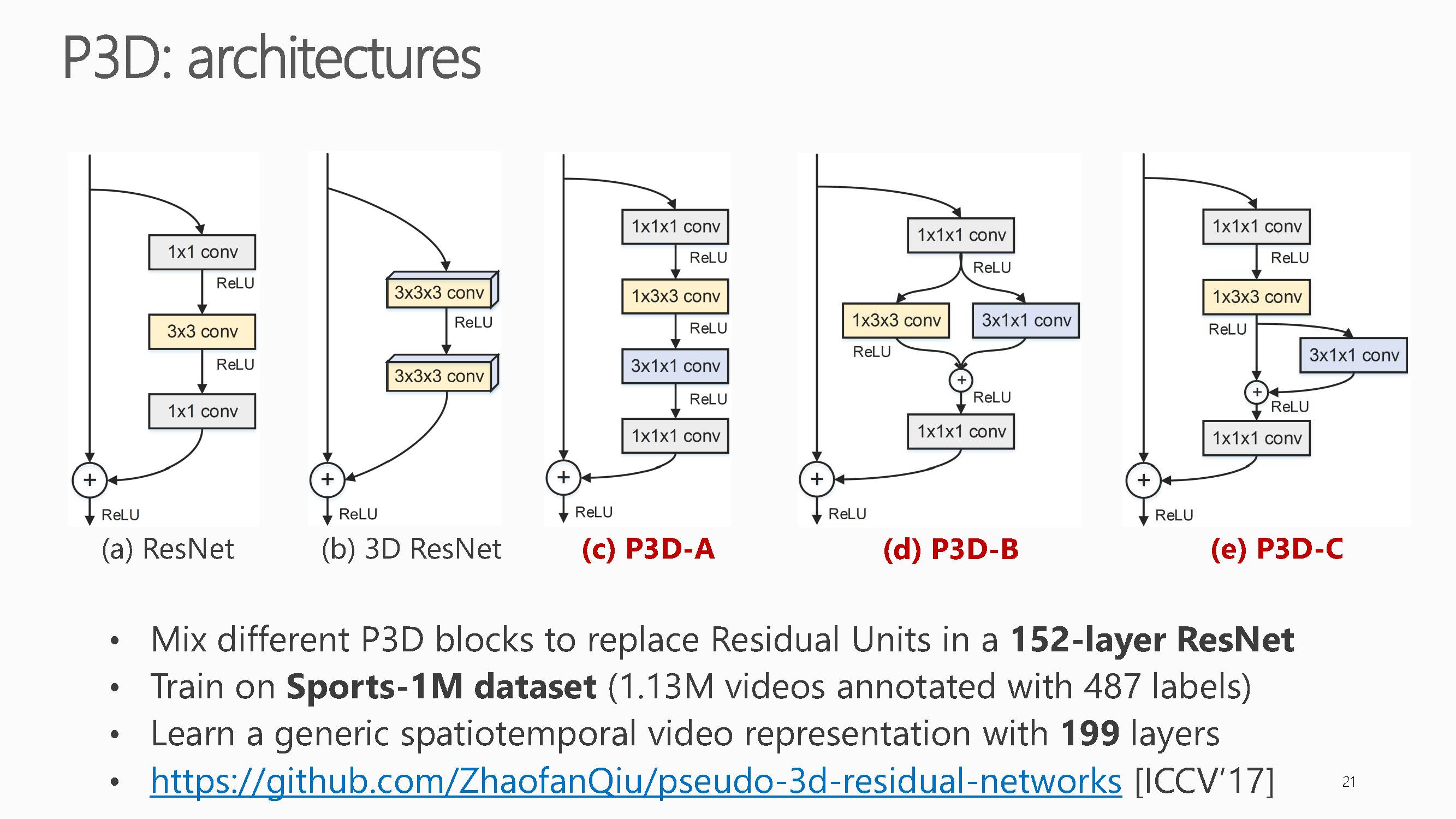
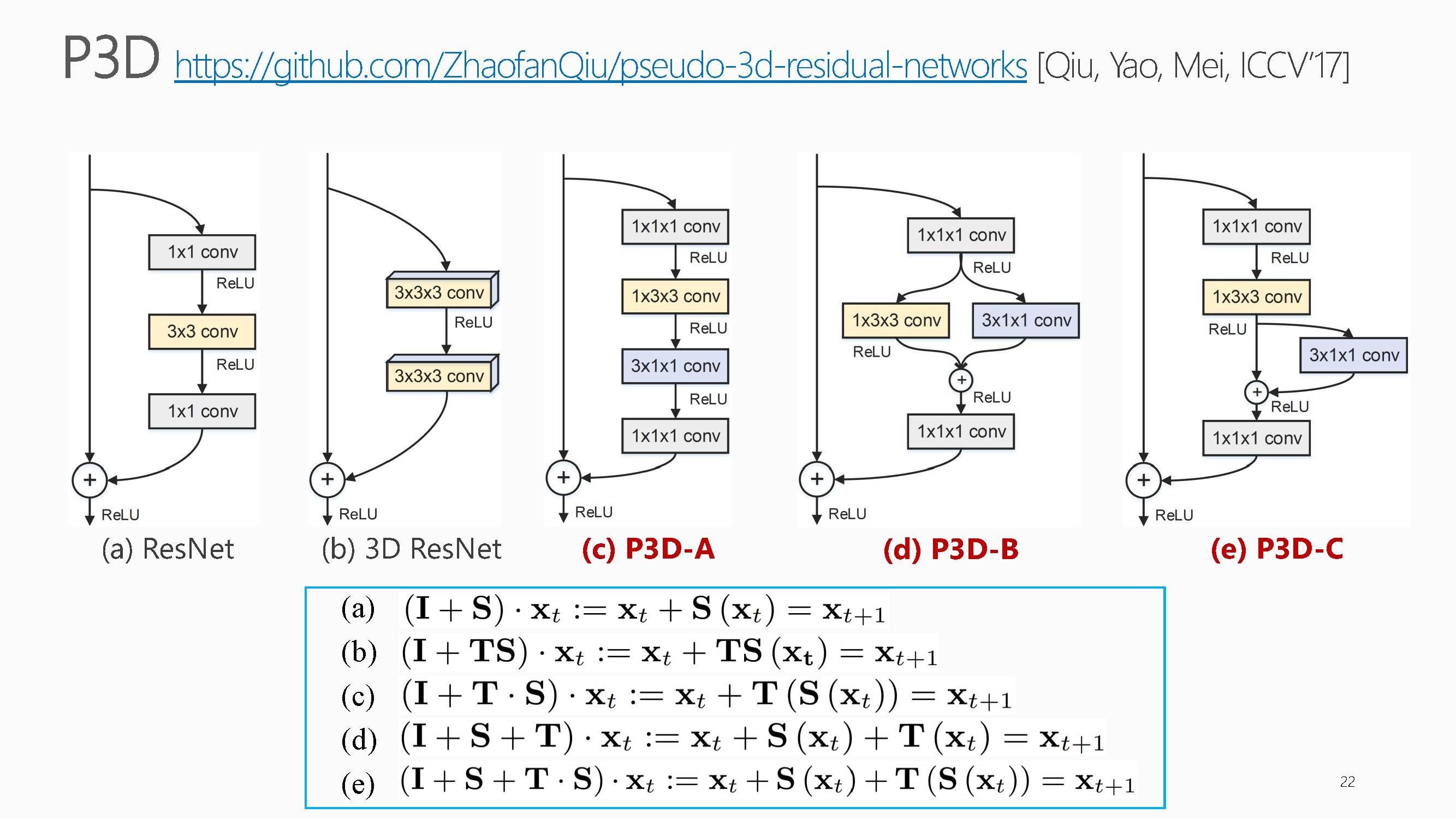
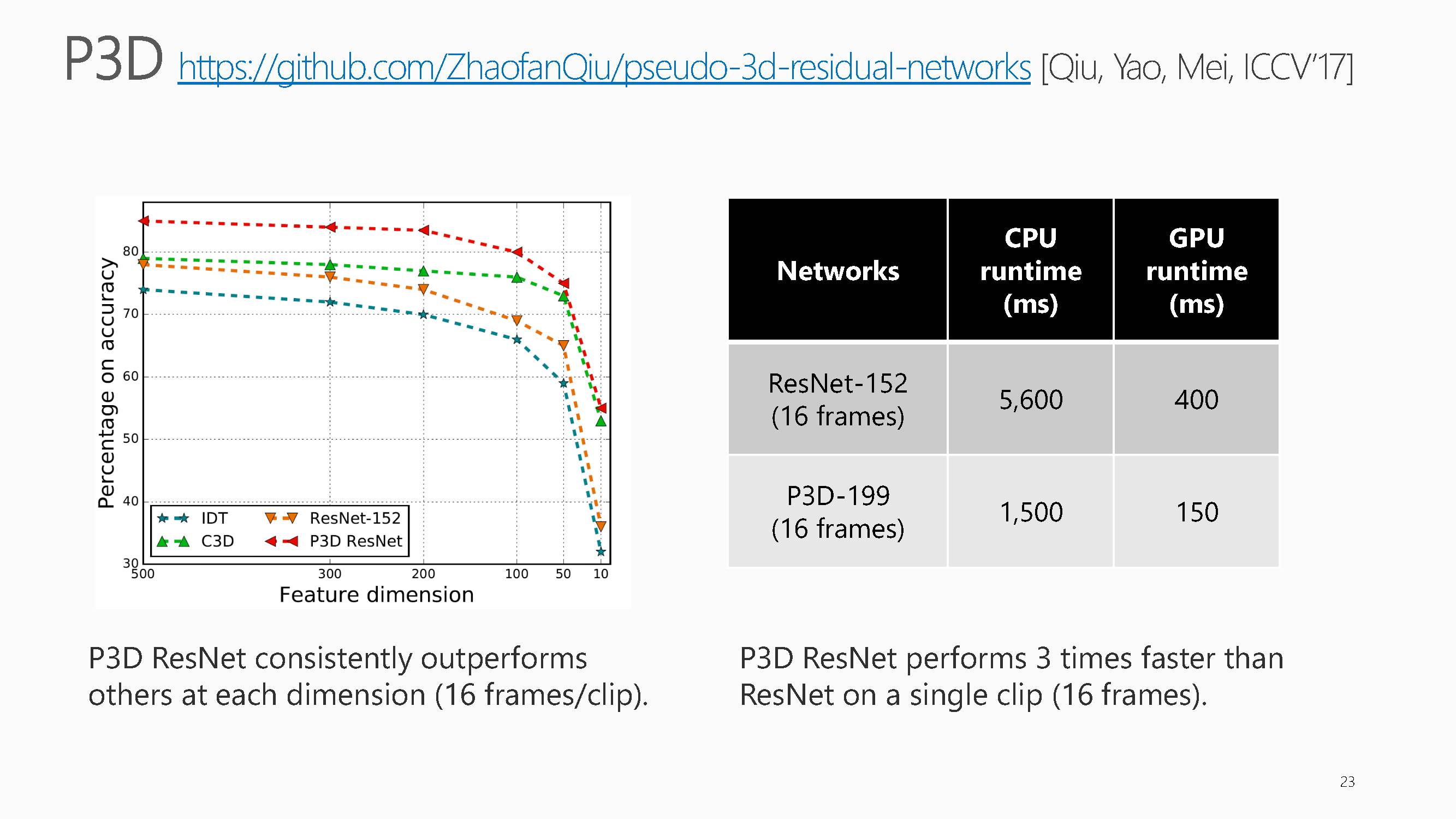
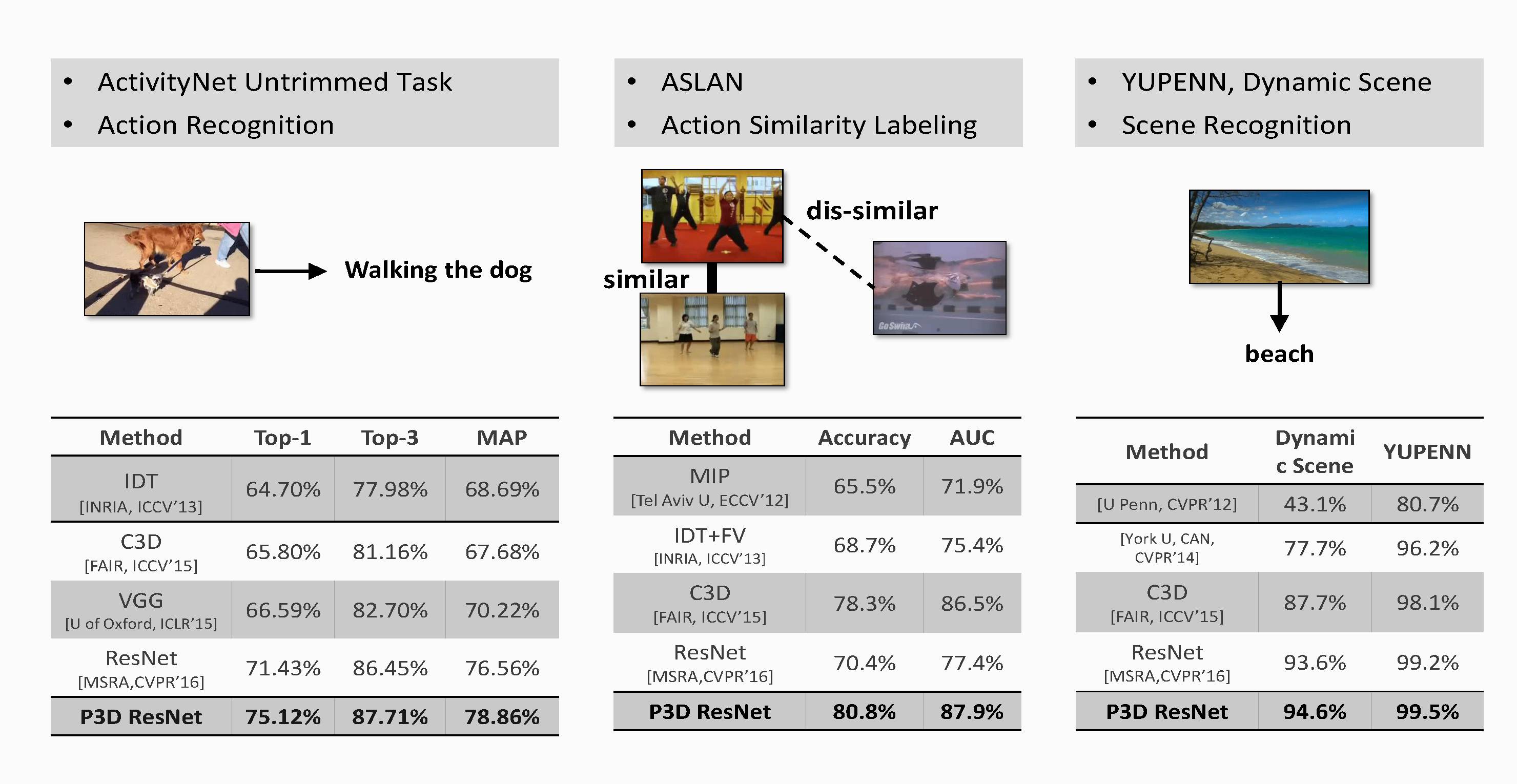
可以看出,其提出的方法在多个视频分类数据集上达到了目前最好。

下面开始介绍Video captioning(视频描述生成)和Semantic video segmentation语义视频分割。

近年来,视频文章描述的结果越来越精准化与细腻。但是VideoCaption 比 Image Caption 要难一些。
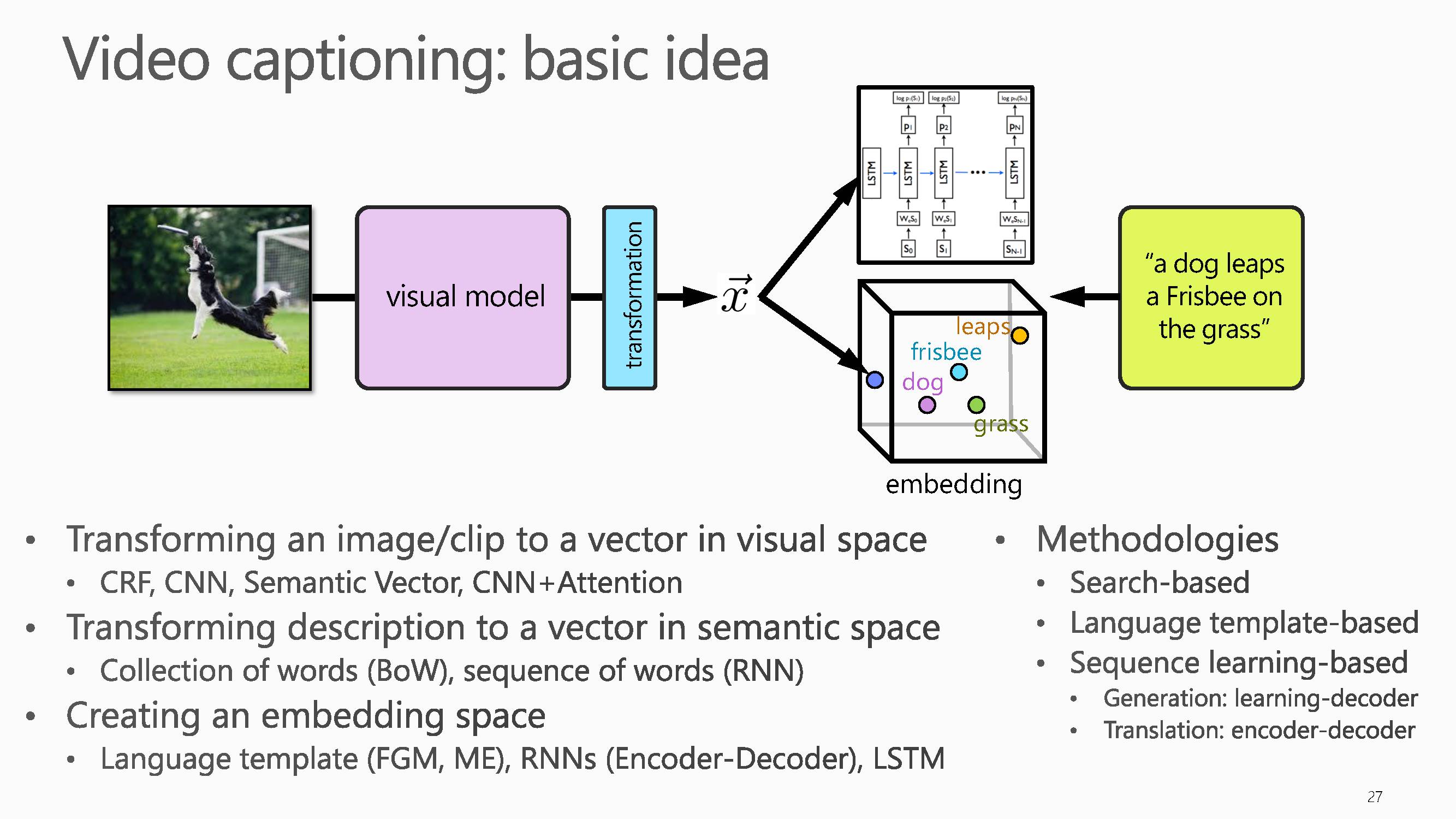
视频文字描述的基本思想是将视觉和文本映射到同一语义空间或者两者空间可以通过某种算法进行转换。研究的基本思路:一方面,不管是图像还是视频都是基于黑箱训练出一个网络模型,也可以引入注意力机制训练生成一个注意力模型。另一方面,引入语句向量。暂时不考虑语句的顺序,观察词汇的分布。也可以采用RNN训练出基于词汇序列的网络模型。下一步建立语义空间,在这个空间基础上生成imagecaption。

在视频描述生成中,Video Captioning 与 Image Caption都可以用语言模型来处理。首先在视频里边检测出来S-V-O主谓宾结构,一些物体以及一些动作。然后区分它是名词还是动词,最后拼接生成一个句子。
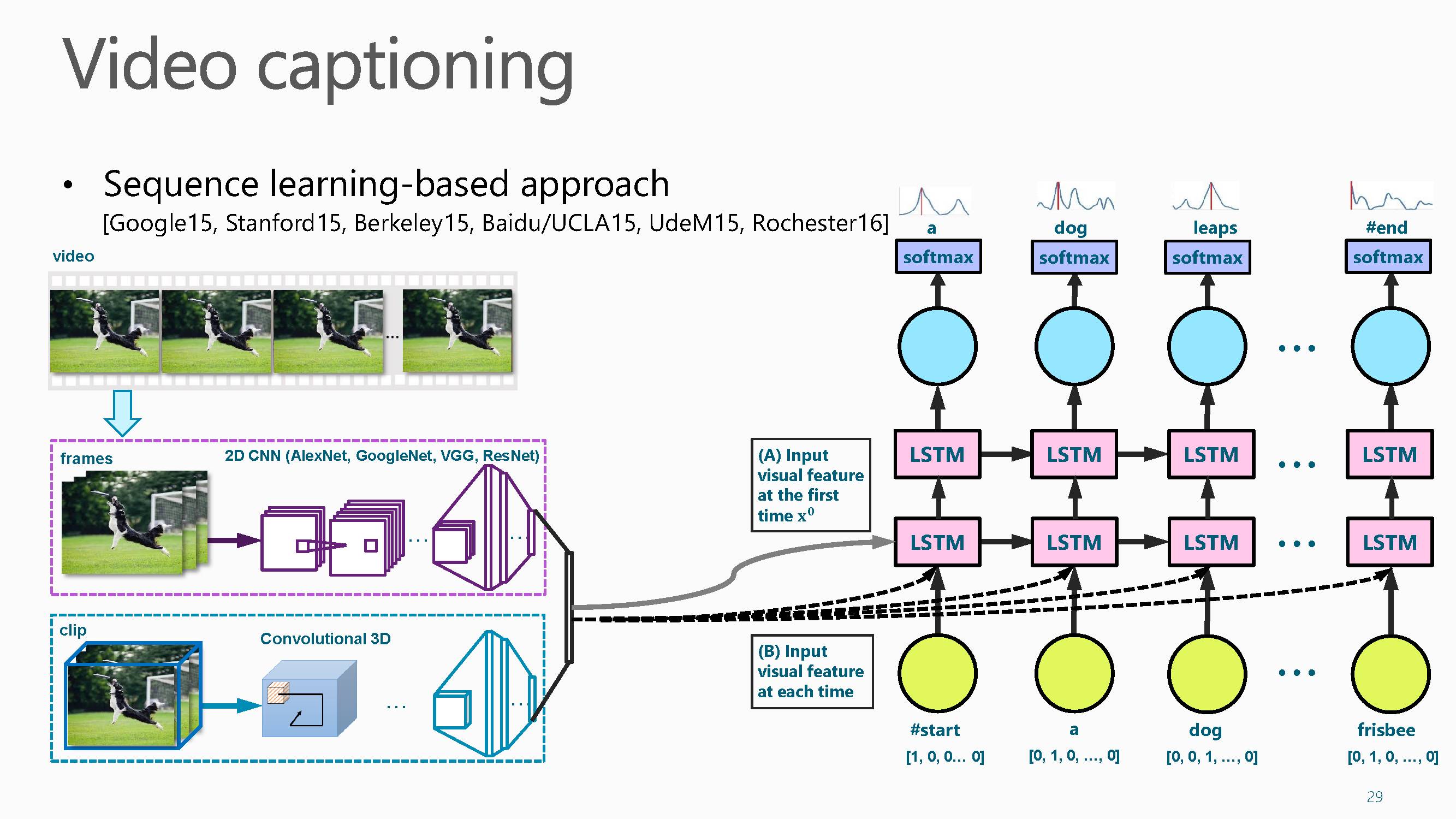
第二种做法和Image Caption一样用CNN学习特征,然后将特征输入循环做语言翻译。
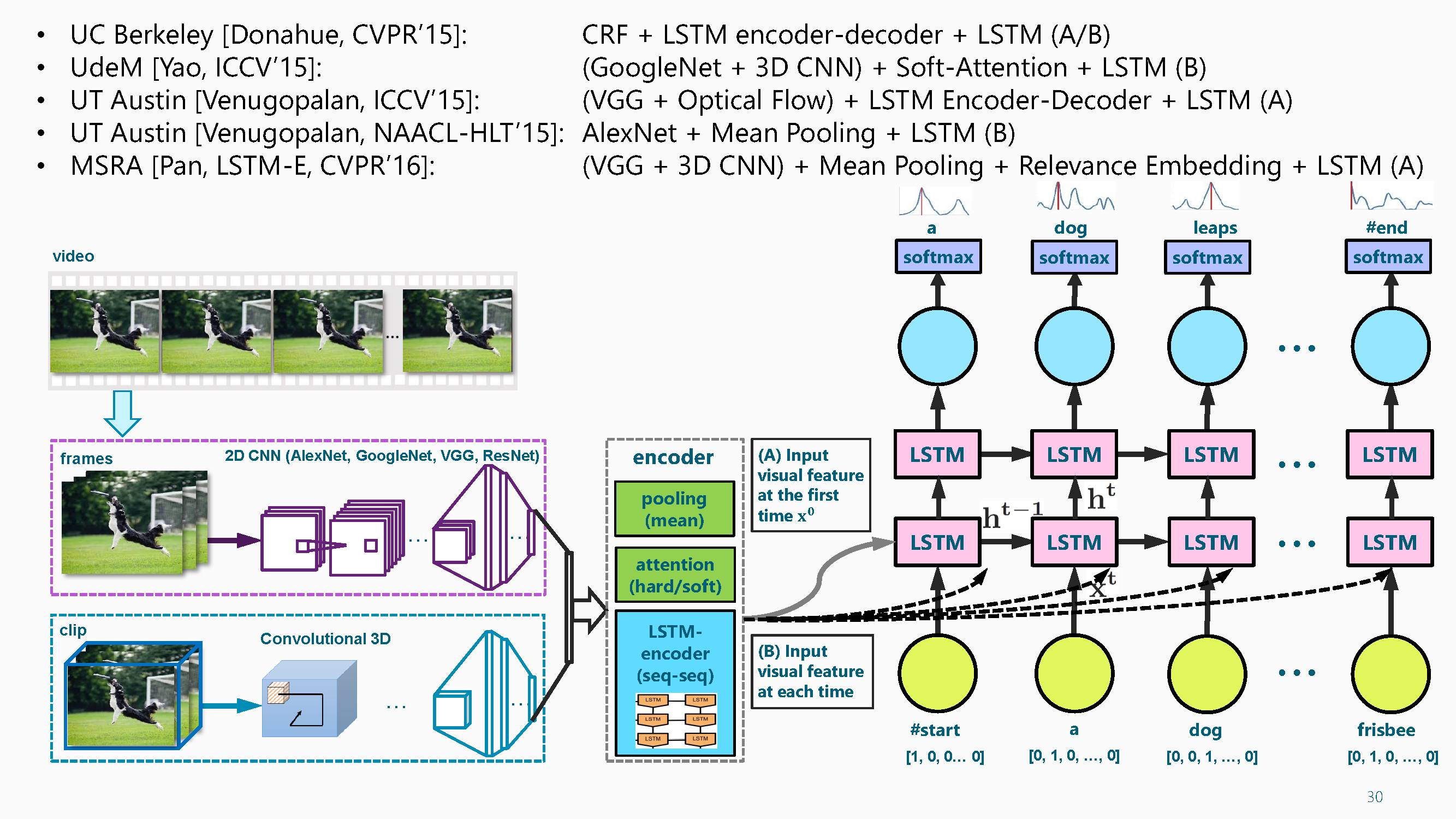
视觉文字描述生成算法经历了从语言模型到序列学习的研究历程。近几年,最早的一篇做图像语言描述的论文来自于ECCV 2010,此后随着深度学习在视觉任务中的普及,视觉和语言这一新兴领域越来越受到大家的关注,在 CVPR 2015和 CVPR 2016中分别收录了5篇和7篇相关论文。这个领域因为同时涉及了视觉和语言处理,所以CVPR/ICCV/ACL等视觉和语言处理会议中都收录了相关的高质量文章。
首先,在训练视频时不仅要学习视频帧的基础注意力机制,还要学习它的剪辑片段。学习视频片段时常用C3D网络。其次,把特征输入LSTM网络训练预测词语。在训练词的时候还有一些选择,视频是一个序列,每个帧在最后的文字描述时贡献是不一样的,因此可以给每帧加权重,称之为视频注意力机制,它是一个动态的视频注意力机制。此外,在做池化时可以给每帧加不同权重,这是动态池化,这是做视频的一个示例。

近年来,视频文字描述生成算法结合其他信息可以获得更好的结果,可以将这方面的研究进展概括为videocaptioning with X。例如:时间注意力模型,时空注意力模型,视觉属性,稠密物体信息。

若要获得更准确流畅的描述,最近的研究表明加入语义信息是有帮助的。关键在于文字的生成要满足两个指标:相关性 和一致性。相关性是指生成的文字内容对应的知识三元组《主、谓、宾》要和视频内容相关。一致性是指要符合语法规则。在研究video caption 方面,在2016年,组里发表了一篇文章研究联合学习LSTM-E。
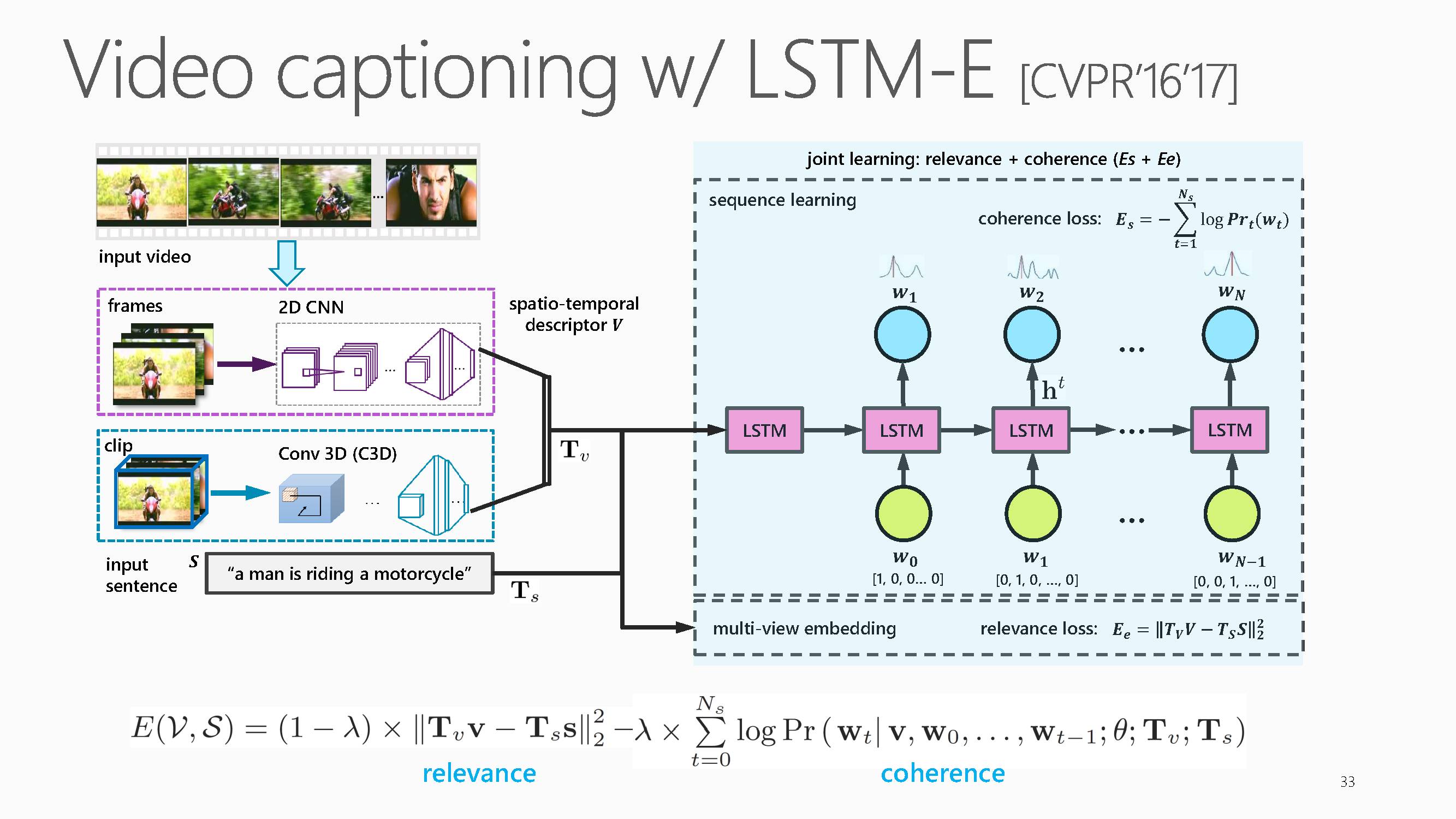
在研究video caption 的时候,发现训练数据集中频繁出现的词会常被作为识别结果,所以增加了一层物体相关性的函数。在训练时每次产生句子时都计算损失函数,计算视频和内容之间是否是最小损失。由此获得一个最小损失函数,使得每次训练时把这个频繁出现的词替换掉。
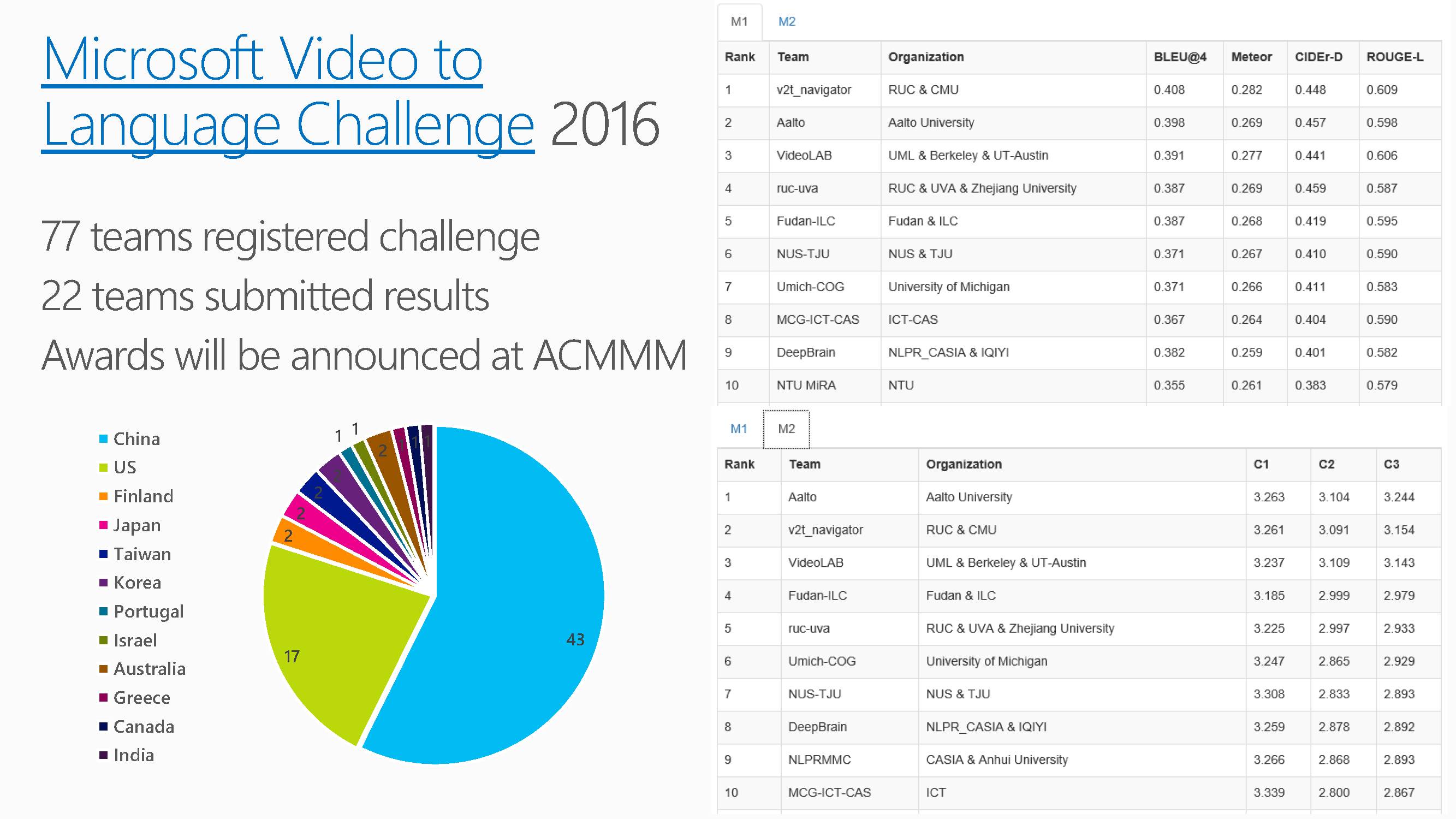
梅涛老师随后介绍了视频文字描述挑战赛MS-VTT 2016和 2017的比赛情况。这个是他们组里做的数据集。去年在ACMMM上组织了一次vision and language挑战赛,这个挑战赛标注了一万个视频片段,它是目前最大的一个数据集。今年的大赛会在四底到五月底举办。去年77个团队进行了注册,22个提交了结果。针对其有两个评价指标,客观的和主观的两个指标。
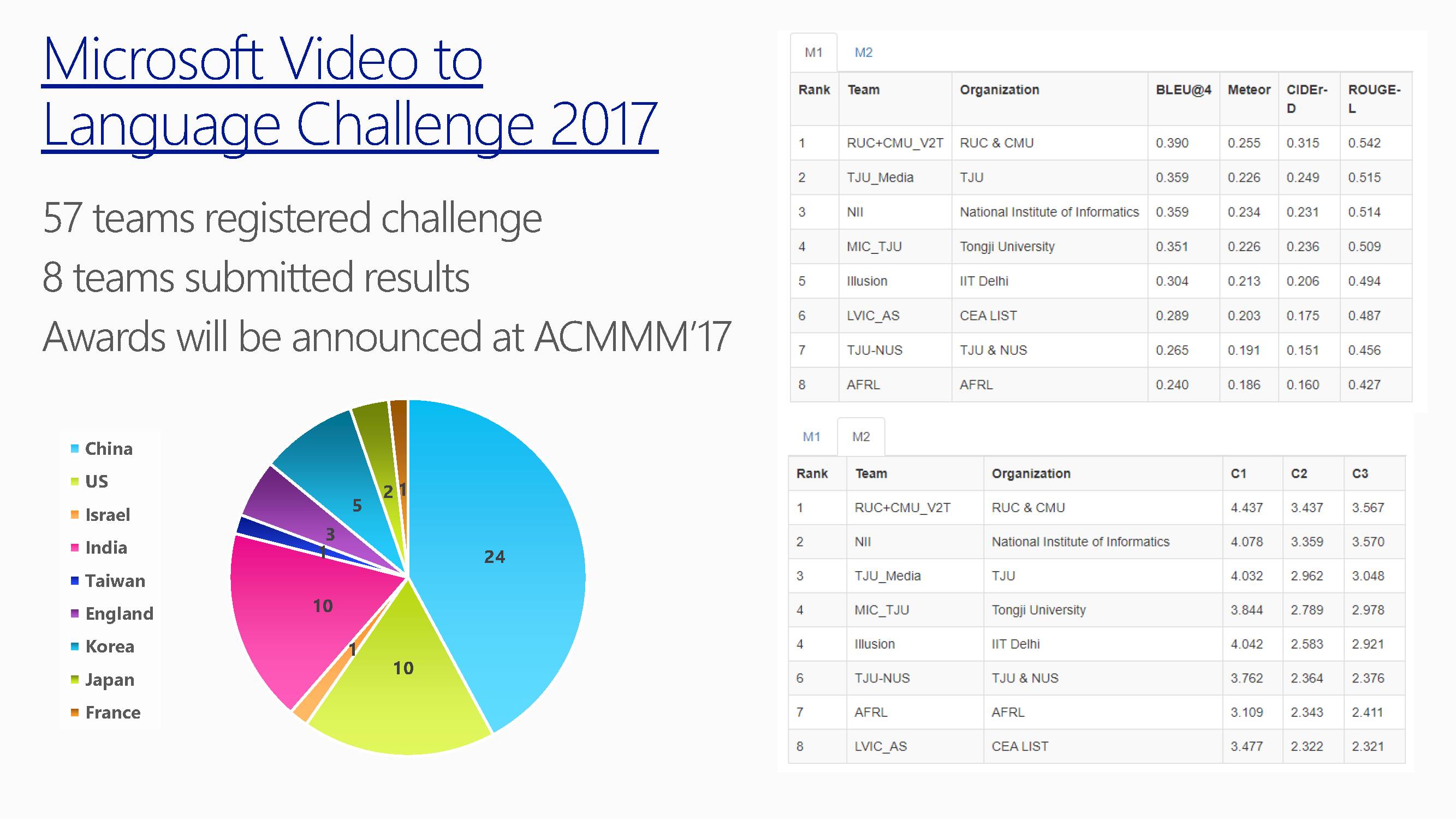
这是2017年的比赛情况。国内有天津大学,同济大学的团队上榜。

这是提出的方法对视频生成的字幕。微软小冰能够做auto-commenting(自动评论),不仅告诉你很美,还能告诉你美在什么地方。后面是一个小孩子,它说你的女儿很漂亮、很时尚。基本上它可以给自拍的视频做评论,给小孩的视频做评论,也可以给宠物视频做评论。

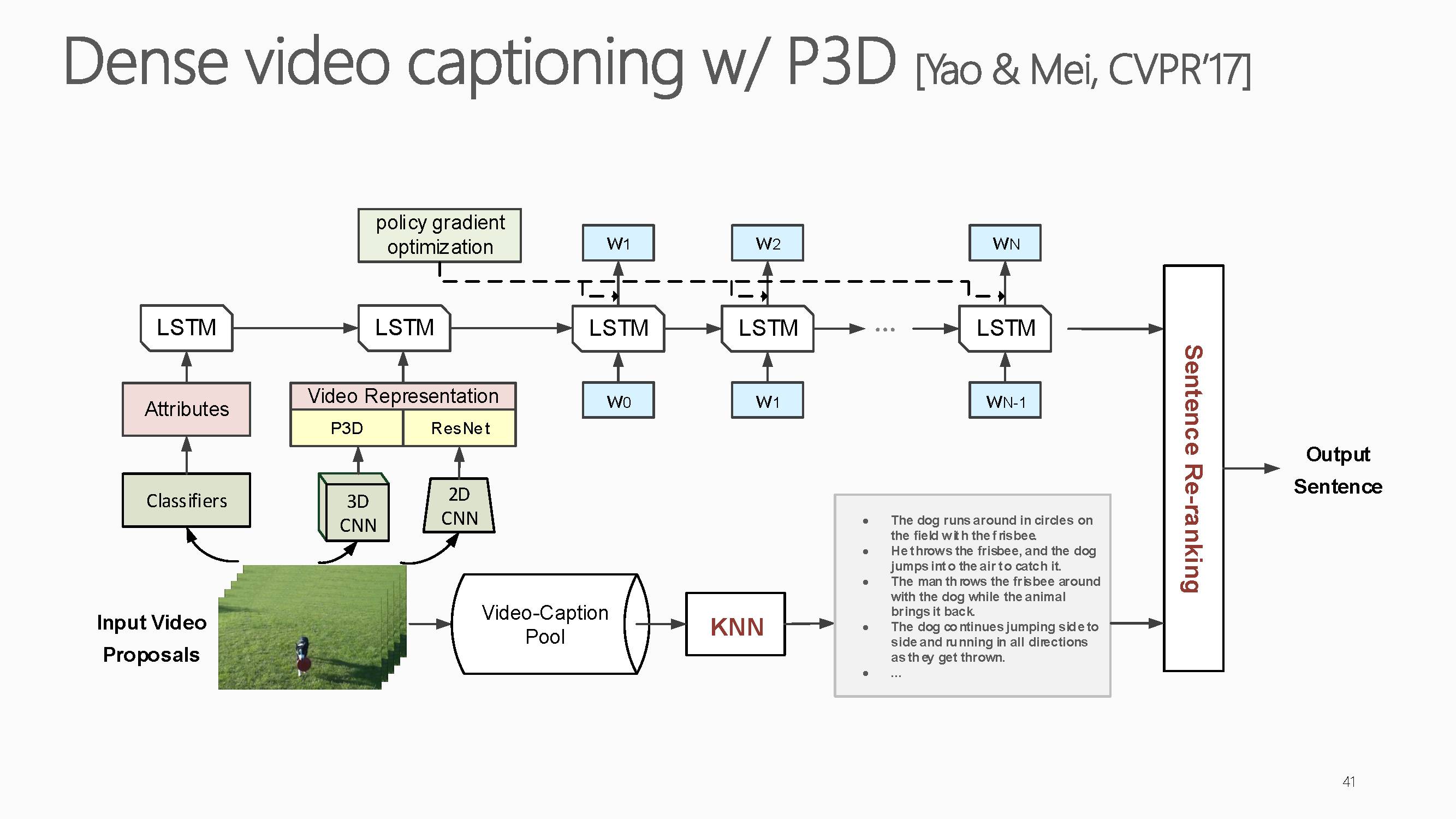
这是基于伪三维卷积(Pseudo-3D Convolution)的深度神经网络的视频事件文字描述结果。提出的方法在CVPR ActivityNet 2017challenge比赛Task5:Dense-Captioning Events in Videos中取得了第一的成绩。这项工作主要集中在如何利用大量视频数据来训练视频专用的深度三维卷积神经网络,它提出了一种基于伪三维卷积(Pseudo-3DConvolution)的深度神经网络的设计思路,并实现了迄今为止最深的199层三维卷积神经网络。通过该网络学习到的视频表达,在多个不同的视频理解任务上取得了稳定的性能提升。
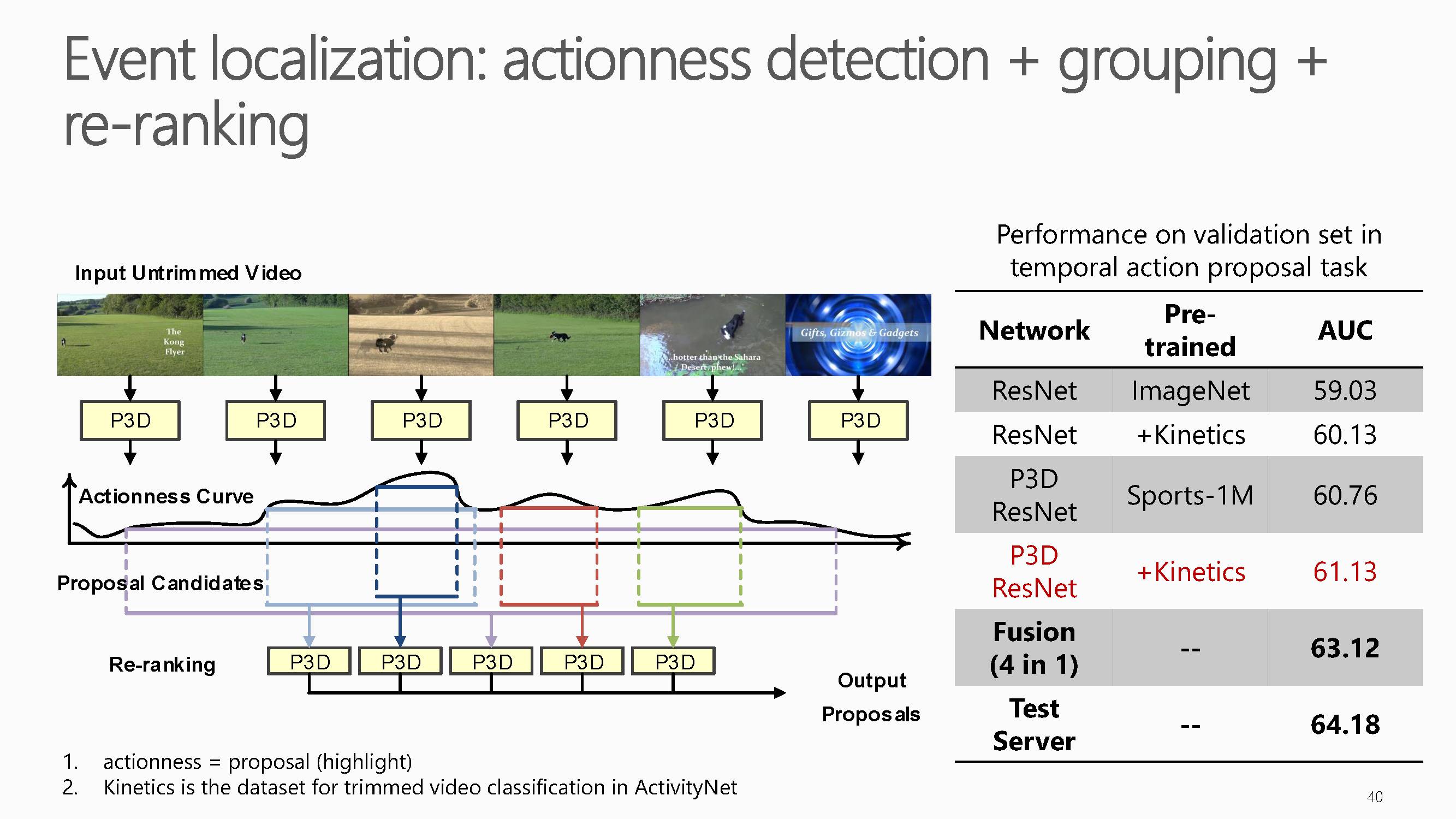
获奖实验分为三部分组成,分别是动作检测,分类和侯选区域
的重排序。
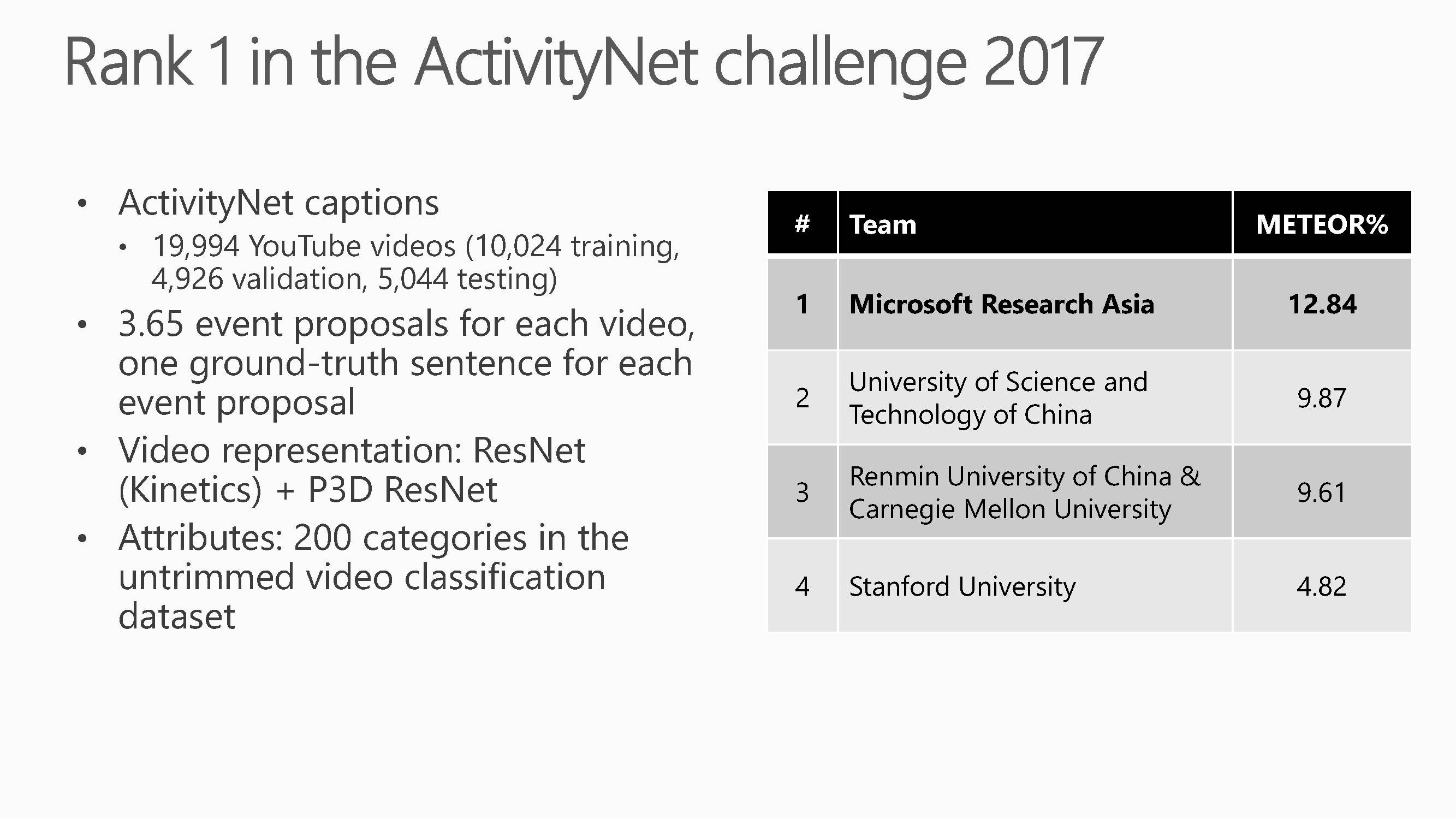
ActivityNet 听名字与ImageNet十分相似,是目前视频动作分析方向最大的数据集。目前的ActivityNet dataset版本为1.3,包括20000个Youtube视频(训练集包含约10000个视频,验证集和测试集各包含约5000个视频),共计约700小时的视频,平均每个视频上有1.5个动作标注(actioninstance)
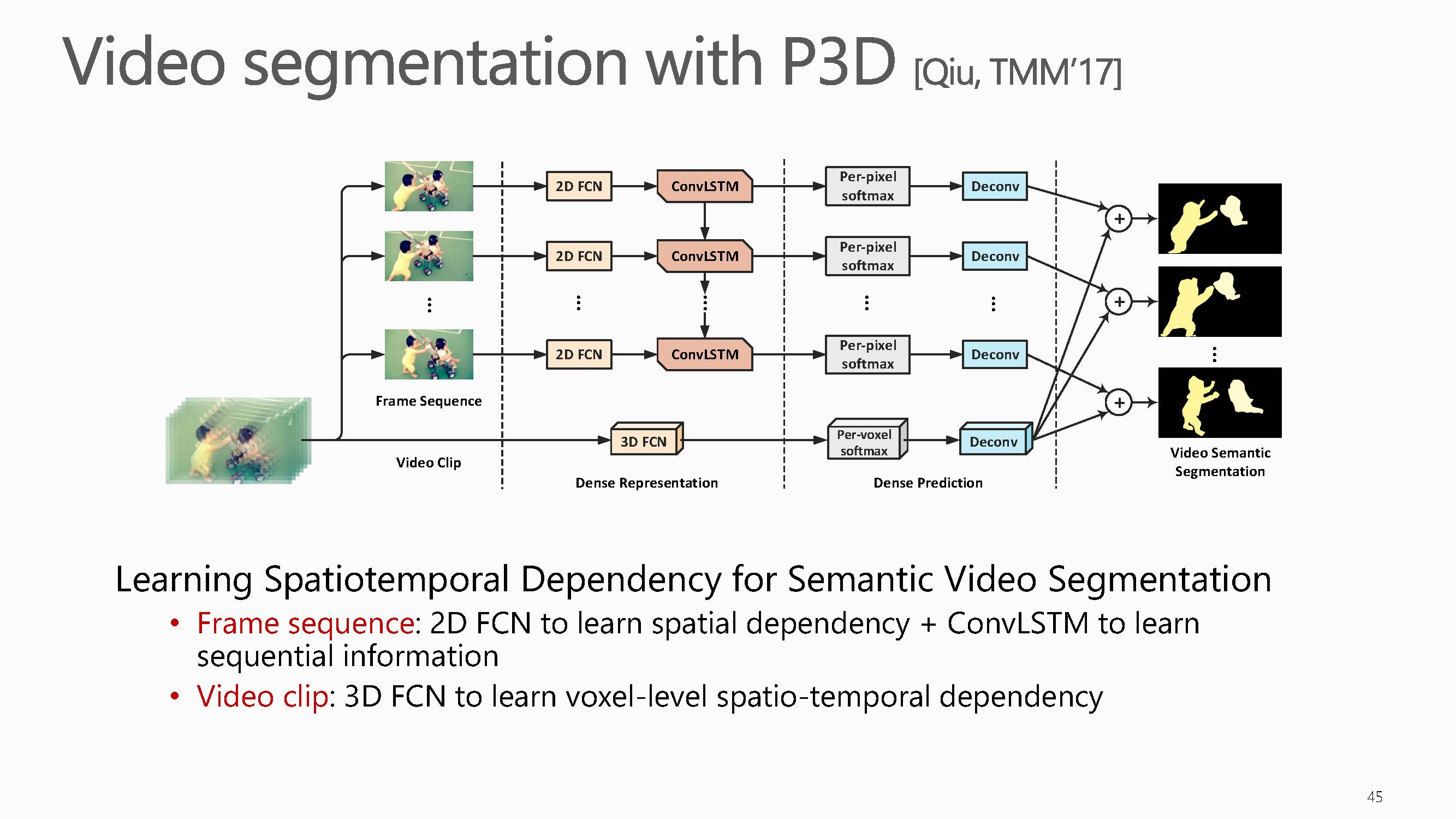
基于同样的P3D结构同样可以用在视频分割中。
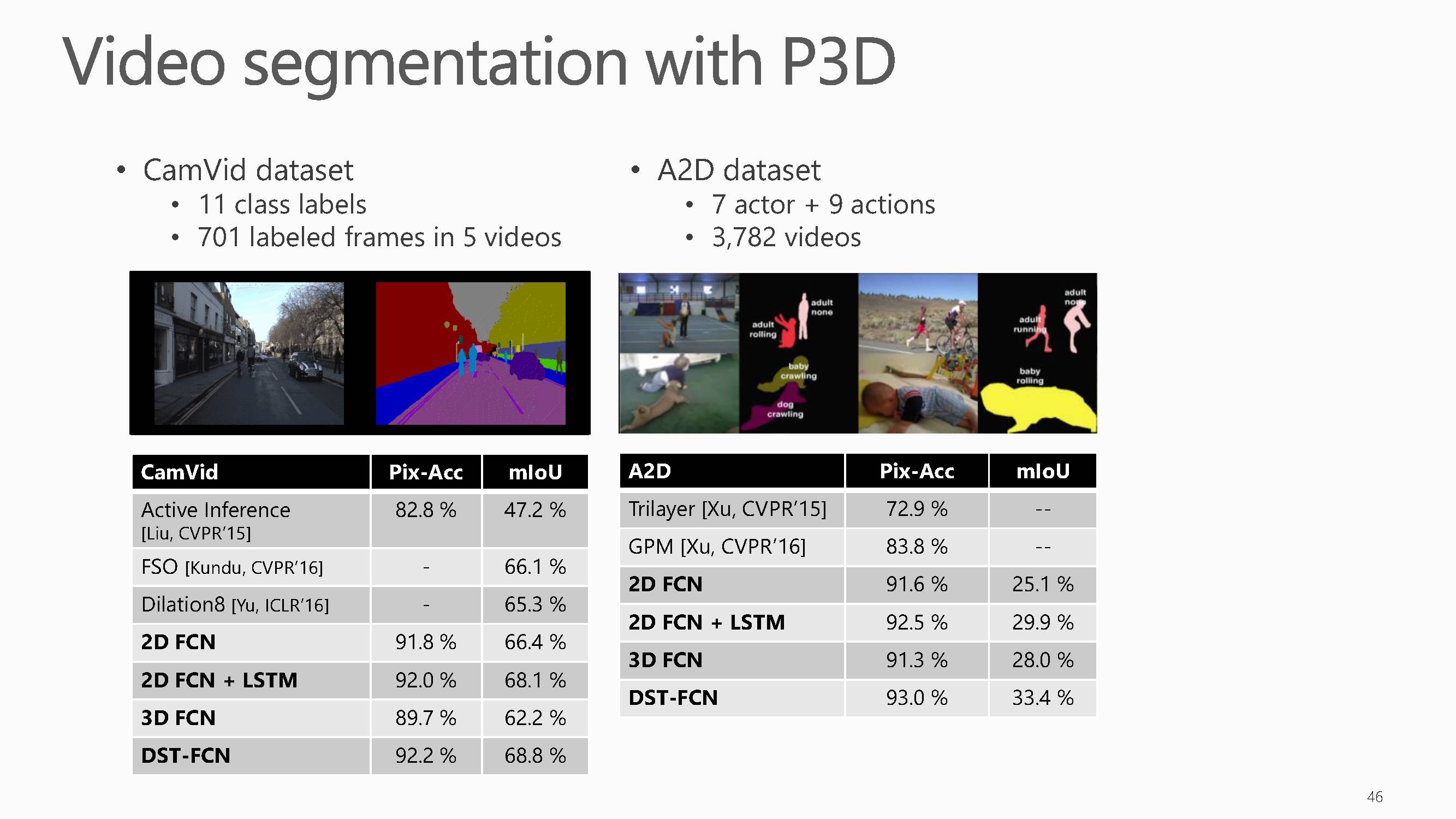

这些任务的结果证明了梅涛老师等人提出的P3D网络的强大表示能力,在其他方面应用,效果显著。

本次报告的参考文献。

提出的P3D的代码和一些网址链接。

最后,梅涛老师组里面招聘人手,机会难得,有兴趣的人请联系。
附:
上述有些内容引自:
梅涛:深度学习为视觉和语言之间搭建了一座桥梁
http://mp.weixin.qq.com/s/R6TUL7CSdK-A24MRmTn9QQ
梅涛:“看图说话”——人类走开,我AI来!|VALSE2017之十二
http://mp.weixin.qq.com/s/shBHKh2emSIL5uWV7po8cw
特别提示-梅涛博士报告下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“DL4IVA”就可以获取报告下载链接~~
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
获取更多机器学习人工智能知识,请PC登录 www.zhuanzhi.ai或者点击阅读原文,顶端搜索“ 深度学习” 主题,相关知识等资料!如下图所示~
请查看专知荟萃知识资料全集获取,请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
【专知荟萃07】自动文摘AS知识资料全集(入门/进阶/代码/数据/专家等)(附pdf下载)
【教程实战】Google DeepMind David Silver《深度强化学习》公开课教程学习笔记以及实战代码完整版
【GAN货】生成对抗网络知识资料全集(论文/代码/教程/视频/文章等)
【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



