【论文笔记】用于推荐的知识图注意力网络—KGAT
【导读】为了提供更加准确、多样化、和可解释的推荐,必须要在用户-项目交互基础上上,更多地考虑用户的辅助信息。而知识图和用户-项目图的混合结构可以得到项目之间的高阶关系,获得更多的辅助信息以提升推荐的性能。本文主要介绍来自KDD 2019 的用于推荐的知识图注意力网络—KGAT,它以端到端的方式显式建模知识图中的高阶连通性。

符号与名词解释
-
U和I分别表示用户和项目集, -
y_ui = 1表示用户u和项目i之间存在观察到的交互,否则yui = 0。
-
E'= E∪U -
R'= R∪{Interact}。 -
Interact为每一个用户与项目之间的交互 -
用户行为三元组表示为:(u,Interact,i)
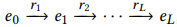
-
e_l∈E',r_l∈R' -
(e_{l-1},r_l,e_l)是第 l 个三元组,L是序列的长度
模型
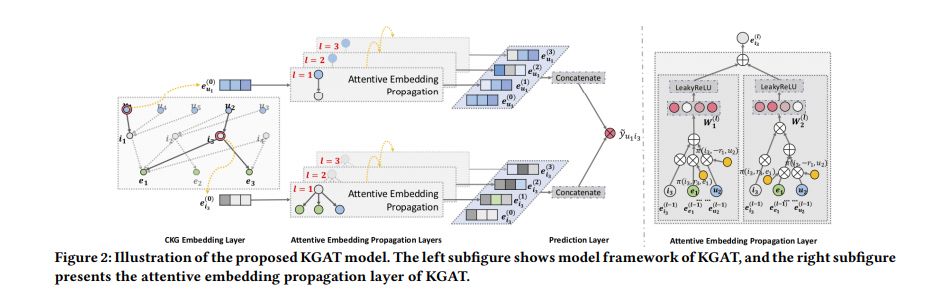
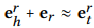
-
e_h,e_t∈R^ d分别是实体 h 和实体 t 的嵌入 -
e_r∈R^ k是r的嵌入 -
e ^ r_h,e ^ r_t是关系r空间中e_h和e_t的投影表示。
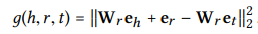
-
Wr∈R ^ {k×d}是关系r的变换矩阵,它将矩阵从d维实体空间投影到k维关系空间。 -
g(h,r,t)的值越低表明三元组更有可能是真实的,反之亦然。
-
-
(h,r,t')是通过随机替换有效三元组中的一个实体而构造的分解(broken)三元组 -
σ(·)为sigmod函数
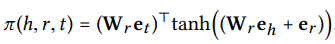
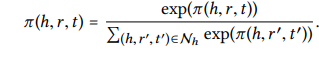
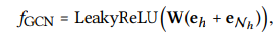
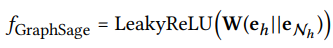
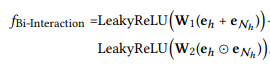
-
W1,W2∈R ^ d'×d是可训练的权重矩阵 -
⊙点乘(按元素相乘)
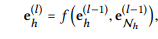
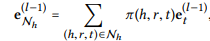
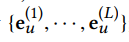
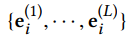
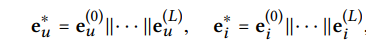
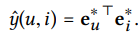
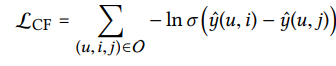
-
O = {(u,i, j)|(u,i) ∈ R+ , (u, j) ∈ R−}表示训练集 -
R +表示用户u和项目j之间观察到的(正)交互 -
R-表示未采样的(负)交互集 -
σ(·)是sigmod函数
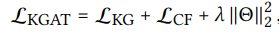
-
Θ = {E, Wr,∀l ∈ R, W (l) 1 , W (l) 2 ,∀l ∈ {1, · · · , L}} -
E是所有实体和关系的嵌入表; -
λ为L2正则化参数以防止过度拟合。
数据集
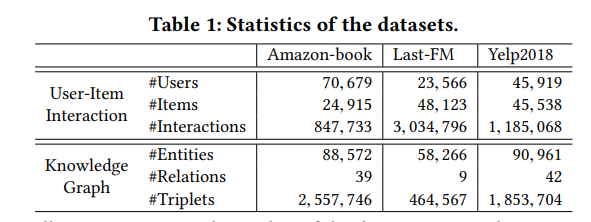
-
亚马逊book2:是从亚马逊评论中选择Amazon-book数据。并且为了确保数据集的质量,只保留至少10次互动的用户和商品。
-
Last-FM3: 是从Last.fm在线音乐系统收集的音乐收听数据, 频道被视为项目。 文中使用2015年1月至2015年6月的数据集的子集。 同样,只保留至少10次互动的用户和 频道。
-
Yelp20184: 此数据集是从2018年Yelp挑战赛采用的,将诸如餐馆和酒吧之类的当地企业视为商品。 同样,确保每个用户和每个项目至少有十次互动
-
Amazon-book和Last-FM,我们将通过标题匹配将项目映射到Freebase实体中。 -
Yelp2018,从本地业务信息网络中提取商品知识(例如类别,位置和属性)作为KG数据。 并且过滤不常见的实体(即两个数据集中的低于10的实体)并保留至少出现在50个三元组中的关系
参数设置
-
嵌入大小:64 -
batch size:1024 -
学习率:{0.05,0.01,0.005,0.001} -
L2归一化系数:{10−5,10−4,···,101,102}
实验结果
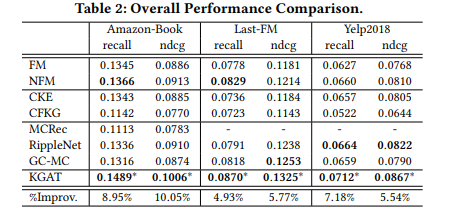
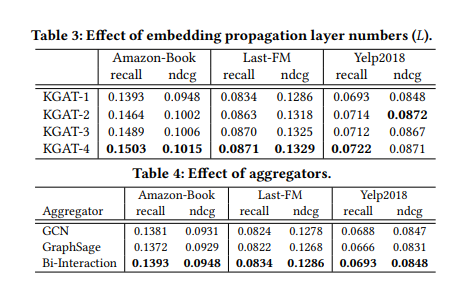
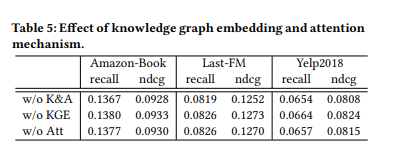
-
w / o KGE: 禁用了KGAT的TransR嵌入组件 -
w / o Att : 禁用注意力机制,并将π(h,r,t)设置为1 / | Nh | -
w / o K&A: 同时删除以上两个组件



展开全文



