微软小冰三位首席科学家畅谈:这六篇论文见证微软小冰的2019成长之路
11月21日,微软小冰首席科学家宋睿华、首席NLP科学家武威、首席语音科学家栾剑在一场小型媒体交流会上介绍了微软小冰2019年年在自然语言处理、语音学研究、多模态生成等领域研究进展。

微软小冰首席 NLP 科学家武威、首席语音科学家栾剑、首席科学家宋睿华

第七代微软小冰已成为全球最大的跨领域人工智能系统之一。
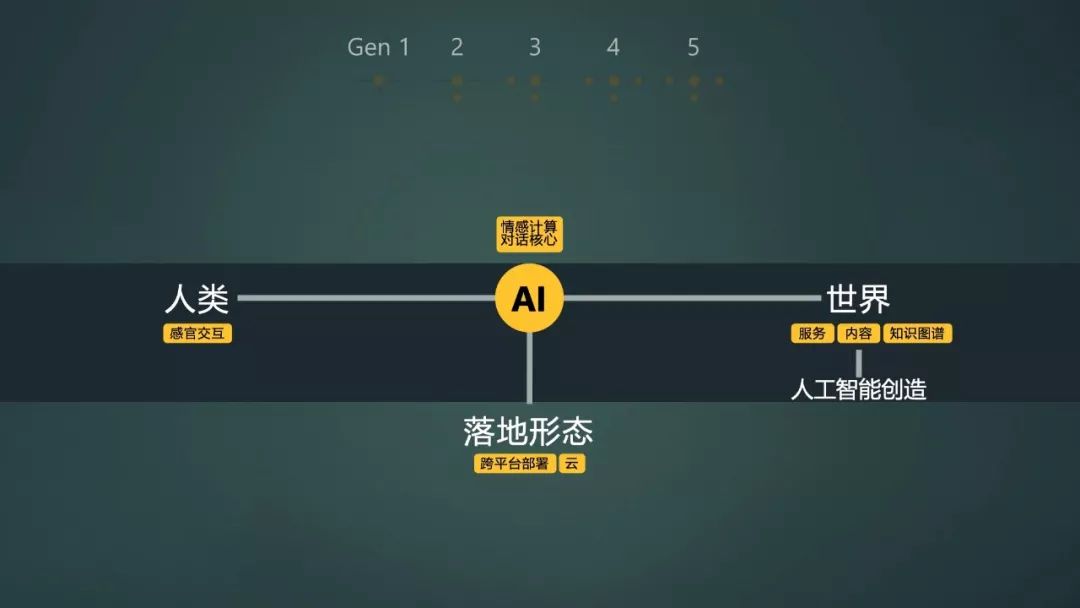
目前,微软小冰单一品牌在全球已覆盖 6.6 亿在线用户、4.5 亿台第三方智能设备和 9 亿内容观众,技术方面在交互场景大幅拓宽的情况下,微软小冰与用户的单次平均对话轮数(CPS)仍然能够达到 23 轮,显著高于其它聊天机器人,甚至也高于人类之间的对话。
微软小冰首席NLP科学家 武威 - “朝向自我完备的对话机器人”
Self-Complete(自我完备)是武威老师自己造的词,因为这个词能够很好的囊括微软小冰在近4年来在研究上、研发上的成果。
武威老师提出,一个能够自我完备的对话机器人应该拥有几项能力:
能力一:学习。学习分为两个层次,第一是能够从人类的对话中学习怎样去说话,第二是每个机器人可能发展到专注于某一个领域,拥有自己领域的知识和技能。就像人一样,每个人各有所长。
能力二:能够自主管理。初级的层次是能够知道在对话单轮的时候如何进行表达;更高级的形态是说单轮表达管理做好了之后,能够把控整个的对话流程。
能力三:连结。连结的意思是,对话机器人能够连结散落在世界上的多模态的知识。
武威老师提到的2019年三篇代表性论文:
1. 论文题目:
Learning a Matching Model with Co-teaching for Multi-turn Response Selection in Retrieval-based Dialogue Systems
论文接收会议:ACL 2019
随着深度学习技术的发展,对话匹配模型已经在多轮回复选择的标准数据集上表现得很好。然而,当这些模型应用于实际系统时,却和在标准数据上的表现有很大差距。究其原因,实际上是大规模无标注训练数据构造时的一些假设为深度学习模型拟合数据提供了“捷径”。本文考虑如何让对话模型通过“相互学习”得到“共同提高”,从而有效地克服大规模无标注数据中的噪音。
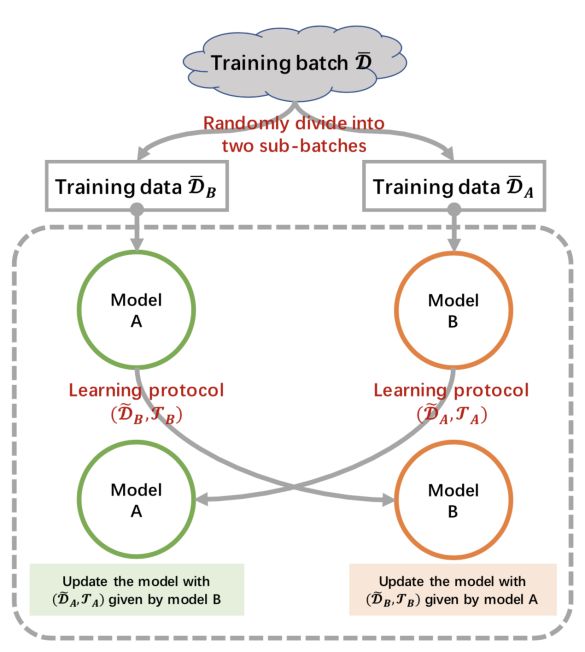
本文提出一个共同教学的学习框架。共同教学旨在让两个匹配模型“互相学习”从而“共同进步”。在这个过程中,一个模型既是老师也是学生,既去教另一个模型如何克服训练噪音,同时又从另一模型那里获得指导。在这个框架下,我们考虑了三种教学方案,包括动态间隔,动态样本赋权,以及动态数据课程。
论文地址:
https://www.zhuanzhi.ai/paper/b1a39a4bbb6f5d7d4121f28ed82b2a42
2. 代表论文:Low-Resource Response Generation with Template Prior
论文接收会议:EMNLP 2019
目前对话生成的研究工作往往假设具备大量符合要求的对话语料,然而在真实场景中特定类型的对话数据却未必容易获取。比如我们统计了5M微博语料后发现可以用来做问句回复生成的对话数据只有7.3%;而统计了2M Twitter对话数据后发现可以用来做(正向)情感回复生成的数据只占18%。因此,尽管一般的对话生成往往可以获得大量训练数据,生成具有某种具体特征(比如句型,情感,意图等)的对话回复却是一个低资源(low-resource)学习问题。另一方面,我们可以以低成本获取到大量的同类型单语语料,如表达疑问的文本和包含正向情感的文本。那么,可不可以利用这些“便宜”的单语语料和少量的对话语料来训练一个对话生成模型呢?
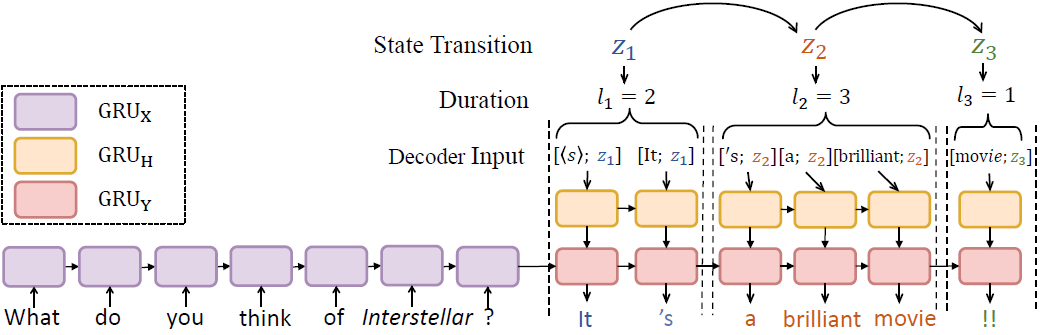
我们提出利用神经半隐马尔科夫模型 (NHSMM) 从大量的单语文本中无监督地学习“模板”,然后利用“模板”作为先验知识来指导对话回复的生成。为了充分利用“模板”知识并保证生成回复的上下文相关性,我们利用对抗学习的方法端到端地优化模型。
论文地址:
https://www.zhuanzhi.ai/paper/77e4c6af39ab2153feba3399db84dc48
3.
论文题目:Neural Response Generation with Meta-Words
论文接收会议:ACL 2019
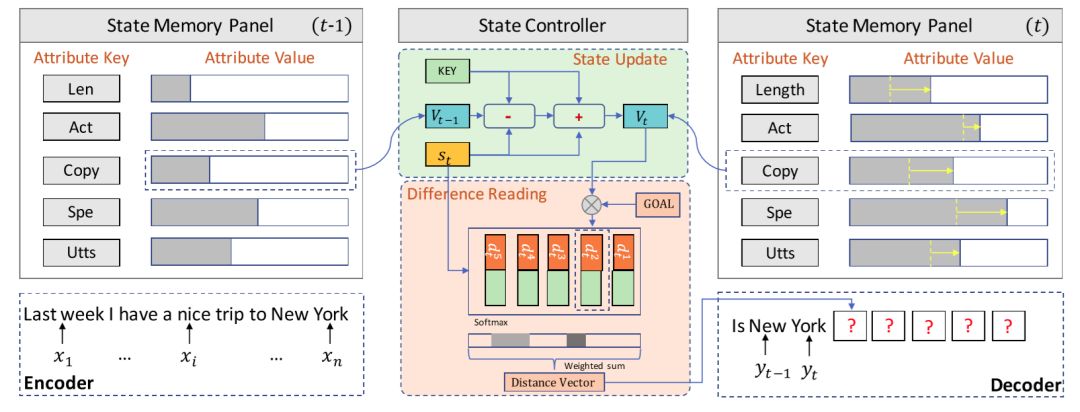
端到端开放域对话生成是人机对话领域近几年的一个研究热点。开放域对话生成中的一个基本问题是如何避免产生平凡回复 (safe response)。一般来讲,平凡回复的产生来源于开放域对话中存在的输入和回复间的 “一对多”关系。相对于已有工作“隐式”地对这些关系进行建模,我们考虑“显式”地表示输入和回复间的对应关系,从而使得对话生成的结果变得可解释。不仅如此,我们还希望生成模型可以允许开发者能够像“拼乐高玩具”一样通过控制一些属性定制对话生成的结果。
论文地址:
https://www.zhuanzhi.ai/paper/522513b797cc3851ebb36f49d2b63616
微软小冰首席语音科学家栾剑 “做唱歌更具有挑战”
微软小冰首席语音科学家栾剑分享了微软小冰在AI唱歌方面的进展。

栾剑说,微软小冰做唱歌技术的原因有三点:1、AI唱歌比AI说话的技术门槛更高;2、唱歌的情感表达更丰富、更激烈;3、唱歌是一个非常重要的娱乐方式。
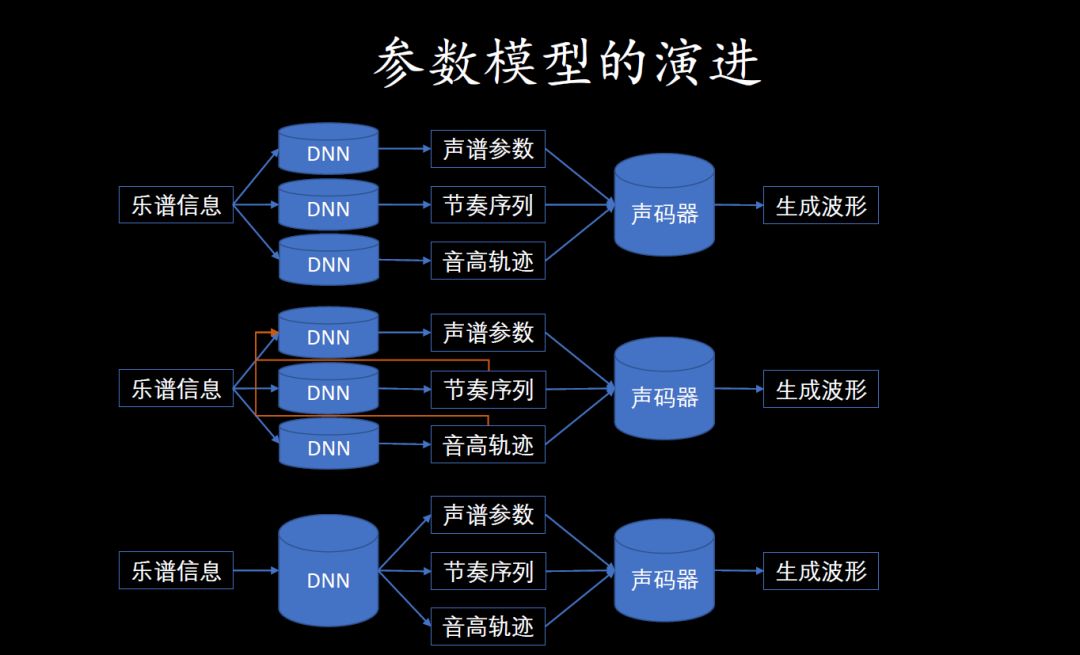
栾剑提到使用卷积残差网络从带伴奏的音乐中提取人声音高信息
众所周知,基频提取是音频信号处理的一项长期任务,尤其当伴奏存在时,从带伴奏的音乐中提取人声基频则更具挑战性。目前,多数基于深度学习的方法或使用频谱特征作为输入,或利用浅层网络直接对时域信号建模,然而前者丢失了相位信息,后者可能无法较好地处理被伴奏干扰的人声数据。本文提出深度卷积残差网络直接对时域信号建模。一方面保证音频信息的完整性,另一方面得益于卷积网络较强的捕捉局部信息的能力,该网络可以自主从时域信号中分析和提取有效信息。同时,残差连接的加入,提高了网络的学习能力,从而达到更好的建模效果。相比于基线系统,本文提出的方法在OA(整体准确率)和RPA(原始音高准确率)分别有5%和4%的提高。
宋睿华:“小冰可以创造比喻么?”
微软小冰首席科学家宋睿华老师分享了小冰在比喻、联想方面的进展,以及如何让小冰像人一样能将故事理解成画面。
微软小冰团队一直想让小冰更像人类,想让小冰更好的理解对话、更好的理解语言,那就需要模拟人类的能力,在短短的语言背后找到一些非常常识性,所没有说的暗含的意思。
宋老师提到的两篇论文:
“爱情像数学一样复杂”:用于社交聊天机器人的比喻生成系统
随着智能聊天机器人在人们日常生活中得到广泛采用,用户对聊天机器人系统的需求也从解决任务的基本对话,拓展到更加随意的朋友式交流。为了满足用户需求,同时与用户建立情感纽带,社交聊天机器人完全有必要吸纳更加人性化的高级语言功能。本文研究了一种人们常用的修辞手法——“比喻”在社交聊天机器人上的使用情况。我们的工作是首先设计一个比喻生成框架,该框架可以根据话题内容,生成新颖的比喻句。然后人工进行标注,验证所生成的比喻是否新颖合宜。更重要的是,我们评估了在人与聊天机器人对话中使用比喻的效果。试验表明,我们的系统能够有效激发用户与聊天机器人交流的兴趣,显著延长人与聊天机器人对话的时间。
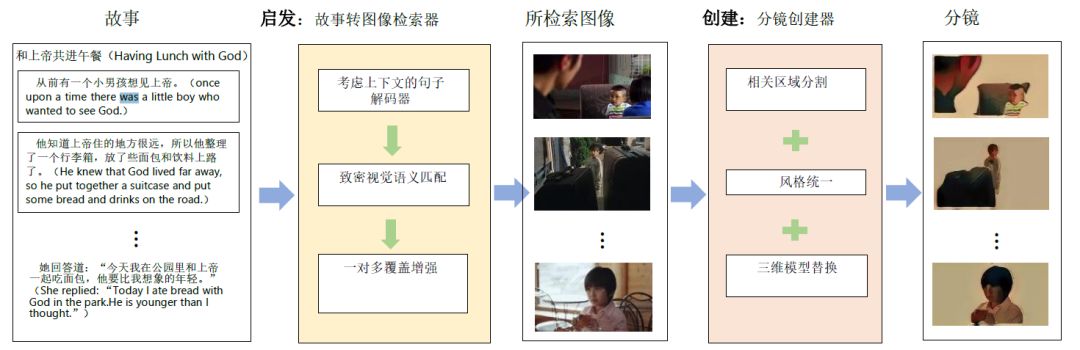
神经分镜艺术家:使用前后一致的图像序列直观呈现故事
分镜(也称“故事板”)是用来描述多语句故事的一系列图像,是创作各种故事的关键流程。本论文解决了一项有关自动创建分镜的全新多媒体任务,它推动了故事创作,赋予了人类分镜艺术家灵感。我们对语言的理解以过往的经验为基础。受此启发,我们提出了采用故事转图像检索器和分镜创建器的新式启发与创建框架;检索器选择电影图像获取灵感;创建器则进一步完善和渲染图像,提高图像的相关性和视觉一致性。我们提出的检索器运用多层注意力,动态利用故事中的上下文信息;同时应用致密视觉语义匹配,准确地检索和定位图像。然后,创建器采用三步渲染,提高所检索图像的灵活性,三步包括抹除不相关的区域,统一图像风格,替换一致的特性。我们对域内和域外视觉故事数据集进行了大量试验。创建分镜时,相比最先进的基线,拟议模型的定量性能优于最先进的基线。定量直观呈现和用户研究进一步证实,我们的方法即使在针对自然场景故事时,也能创作出高质量的分镜。
论文地址:https://dl.acm.org/citation.cfm?id=3350571
6篇论文便捷下载:请关注专知公众号(点击上方蓝色专知关注)
后台回复“xiaoice” 咨询获取六篇论文下载



展开全文



