初学者系列:Neural Factorization Machines 神经因子分解机详解
导读
在预测任务中,特征向量通常是稀疏且高维的。为了解决稀疏预测问题,有效的学习特征交互一直是学者们努力的方向。本文主要通过《Neural Factorization Machines for Sparse Predictive Analytics》一文介绍一种更有效的学习特征交互,解决稀疏预测问题的方法——NCF(Neural Factorization Machines)。
预测分析是推荐系统、搜索排名等信息检索(IR)和数据挖掘(DM)任务的最重要技术之一。预测变量大多是离散的和分类的。为了构建预测模型,通常使用one-hot编码将输入转化为二进制,但是经过转换的特征向量通常是高维且稀疏的。为了更有效的在稀疏数据中学习,更好地学习特征交互是必不可少的。但是之前学习特征交互的方法(例如:人工特征、FM以及DNN)都存在或多或少的局限。
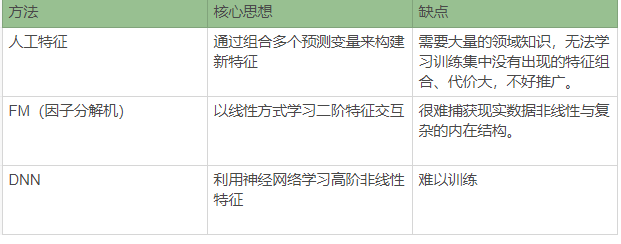
为了解决这些方法中的缺陷,更好地学习交互特征,作者提出了NFM(Neural Factorization Machine)模型用于稀疏数据下的预测,NFM结合了FM在建模二阶特征相互作用中的线性与神经网络(NN)在建模高阶特征相互作用中的非线性。并且NFM使用更浅的结构 在练习中更容易训练和调整。
NFM结合了FM在建模二阶特征相互作用中的线性与神经网络(NN)在建模高阶特征相互作用中的非线性,实现高阶交互+非线性特征交互。
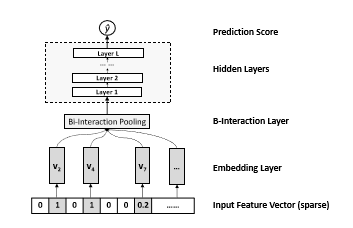
NCF是将FM中的二阶交叉特征项通过双线性交互层(BI-Interaction)进行池化操作实现,并将得到的交叉特征送入神经网络(NN)中提取高阶与非线性的特征交互。
对于FM的输出为:
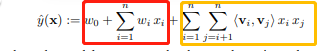
tips:请点击FM看FM算法详解
NCF的输出为:
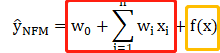
f(x)是NFM的核心组件,用于建模特征交互。
Embedding层
Embedding层是一个全连接层,是将稀疏输入映射为一个密集向量。可以将FM算法中的隐向量V看作该Embedding层的权重矩阵,经过Embedding后会获得一系列的嵌入向量( embedding vectors )V_x :
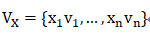
由于x为one-hot形式(输入x中只有一个位置不为0),故 V_x 在 x_i 不等于0时可以写为:
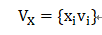
BI-Interaction层
BI-Interaction层是一个池化操作,将Embedding层得到的一系列嵌入向量集合V_x 转化为一个向量(相当于FM模型中的交叉项)。
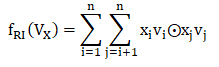
与FM中的交叉项一样,BI-Interaction层的输出 f_{RI}(V_x)可以化简为如下形式:

其中:
⊙ 表示向量的逐元素乘积
输出是k维向量,k是embedding的维度
隐藏层
隐藏层学习特征之间的高阶交互,各层的输出如下:
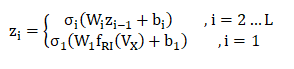
W_i表示第i层的感知机权重矩阵;
b_i表示第i层的感知机的偏置向量;
σ_i为第i层的激活函数。
因此,NCF的输出表示为:
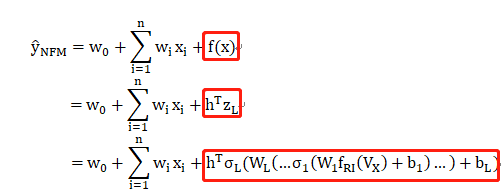
其中:
h为输出层神经元权重
Note:将隐藏层去掉直接连接输出层,NFM就变为了FM
优化
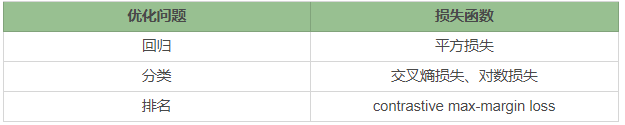
对于不同的优化问题(回归、分类、排名)可以选择不同的损失函数。
我们以回归问题为例,使用平方损失作为目标函数:
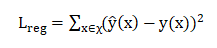
则参数更新可以表示为:
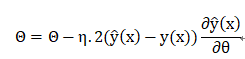
其中:
η为学习率
参数Θ 包括{w_0,{w_i,v_i},h,{W_l,b_l}}
为了更好地训练模型,作者还提出在训练过程中加入Dropout与Batch Normalization.
Dropout
论文中并没有在目标函数中加入L2正则化项,而是分别在Bi-Interaction层、隐藏层进行了Dropout,随机丢弃隐层向量,以防止过拟合。
Batch Normalization
为了避免出现随着网络深度加深,训练越来越困难,收敛越来越慢的问题,作者加入了Batch Normalization对输入进行处理(把每层神经网络任意神经元的输入值的分布强行拉回到均值为0方差为1的标准正态分布)。BN操作层,位于X=W_i *z_{i-1}+b_i激活值获得之后,非线性函数变换之前。
tips:出现网络收敛越来越慢的原因:深层神经网络在传入激活前的输入(W_i *z_{i-1}+b_i),在训练过程中分布会逐渐往非线性方向偏移,造成低层神经网络梯度消失。
源码地址:
https://github.com/hexiangnan/neural_factorization_machine
主要框架如下:
环境:
Python 2.7
Tensorflow
tips:可以将源码中的xrang改为range、sub改为subtract即可使用Python 3
数据
官方给出了经过处理的 MovieLens 1 Million (ml-1m) 和 frappe两个数据集,数据集示例如下:
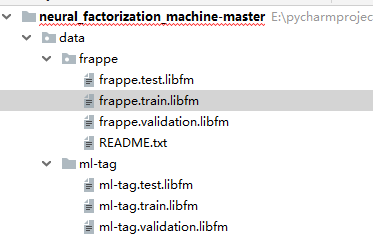
在所有的数据中,第一位代表标签(1或者-1),其余的都是特征。

构造数据集(LodaData.py)
在构造数据集时主要是通过如下两个函数实现,得到数据集中特征的索引值(并没有对输入数据直接进行one-hot处理)与标签,并存放在字典中,组成训练集、验证集、测试集。

构造得到的数据集形式如下:

主函数
源码中除了给出实现NFM的代码以外,还给出了实现FM的代码,下文主要介绍NFM的实现。
在主函数部分主要是通过调用LodaData()加载数据集、NeuralFM类获得定义的NFM模型以及训练函数train()训练模型。并且在训练的每一个epoch都会输出训练集、验证集、测试集的损失,并在最后输出效果最好的一次。

模型
NFM模型的实现主要通过NeuralFM类中的 _init_graph函数。模型主要包括Embedding层、BI层、隐藏层、输出层四部分。并且在 _init_graph()中定义了损失函数与优化器。
Embedding层:通过函数 tf.nn.embedding_
lookup()根据输入特征的索引号找到对应权重中的一行。(这也是在一开始不需要对数据进行one-hot转换的原因)
BI层:相当于FM中的二阶交叉项计算。
隐藏层:隐藏层通过for循环实现每一层的W_i * z_{i-1} + b_i。
输出层:
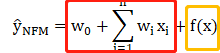
在这里对于FM中的一阶特征w_i * x_i的实现并不是直接相乘,而是通过一维的embedding实现的。

训练
在函数train()中在每个epoch中都随机的选择batch_size个数据进行训练,获得损失函数。
并且调用evaluate()函数对训练、验证、测试数据进行评价。

在evaluate()函数中分了两种情况,当损失函数是平方差损失时,计算了真实数据与预测数据的标准误差(RMSE);损失函数是对数损失时,计算对数损失。

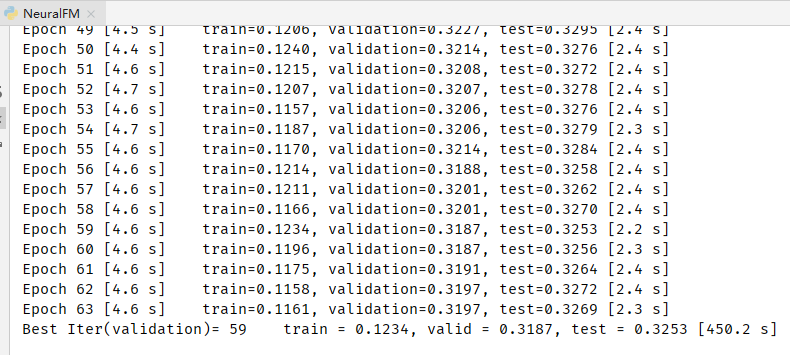
训练结果如下:
论文链接:
http://staff.ustc.edu.cn/~hexn/papers/sigir17-nfm.pdf
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



