寒武纪钱诚:将推性能更强的云端智能芯片|GTIC 2019
看点:钱诚指出,智能计算系统未来20年有10倍以上的增长空间。


3月15日,由智东西主办,AWE和极果联合主办的GTIC 2019全球AI芯片创新峰会在上海成功举办!本次峰会报名参会的观众覆盖了近4500家企业,到会观众极为专业,其中总监以上级别占比超过62%,现场实际到会人数超过1800位。
大会现场来自学术、投资、安防、芯片等多个领域的21位重磅嘉宾共聚一堂,系统的探讨了AI芯片在架构创新、生态构建、场景落地等方面的技术前景和产业趋势。

▲寒武纪副总裁 钱诚
寒武纪是中国最早发布神经网络处理器的AI芯片创业公司,去年5月发布了面向云端的机器学习处理器MLU。面对云端AI芯片市场巨头盘踞的局面,寒武纪将如何进行突围?在峰会现场,寒武纪副总裁钱诚带来了主题为《云端智能芯片的突围》的演讲。在演讲中,他指出智能计算系统未来20年有10倍以上的增长空间,同时他还重磅宣布正在研发性能更强的云端智能芯片。
在钱诚看来,目前的主流计算系统还远远谈不上智能,终端设备智能化浪潮,将带动未来20年智能计算系统在中国消费市场的增长达到10倍以上。这一增长背景下,有大量的AI训练需要在云端进行,但云端智能芯片遭遇了能效比与通用性的瓶颈。对此,寒武纪去年推出算力达到128Tops的MLU 100云端智能芯片,通过硬件神经元虚拟化、编写深度学习指令集等方式来解决芯片规模结构固定但算法规模扩大、算法快速变化等难题。
附寒武纪副总裁钱诚演讲实录
钱诚:尊敬的各位来宾,下午好!很高兴今天下午能在这里跟各位分享我对云端智能芯片的看法。
寒武纪公司是一家专门做智能芯片的公司,我们对智能芯片的定位是智能时代最核心的物质载体,这有点像在工业社会时候发动机是最重要的核心物质载体一样。这样的最核心物质载体市场是非常广阔的,据统计至少是千亿级别的市场。
智能时代会是什么样的?相信大家都有非常不一样的见解。在寒武纪看来,未来智能时代的计算系统至少要符合一下几点特征:
首先是端云一体,端和云、操作系统、指令级、核心加速模块、计算模型的迁移,都应该是完全畅通无阻的,可以很轻松地到达平台上。
计算系统组成中的人、计算机、设备之间的区别不会特别明确。比如说计算机和设备发挥的功能跟人相比不会差别太大,我们说智能计算系统一定是人机物三元融合的。比如说消防员救火的时候,现在需要问大楼的管理人员是否还有幸存者没有被救出来,以后只需要询问家具(电灯、电视机),它们就可以告诉你哪个角落还有幸存者。但现在的计算系统,特别是端和云还远远达不到这样的智能水平。
现在的消费类电子产品,大家用的比较多的是智能手机,智能手机在设计时人工智能的处理能力远远不如我们所预期的那么强大。比如说现在计算图像、识别图像一分钟是2000幅左右,这样折算成一秒钟就刚刚达到人类能够容忍的程度——30多桢。现在做的汽车、工业互联网也无法达到真正的自动驾驶,柔性生产线还无法像真正的人类一样自动安排生产。现在的互联网大数据中心还处于传统的往算力平台中加GPU进行加速的阶段,能否真正实现智能仍是未知数,可以说需求是非常广阔的。
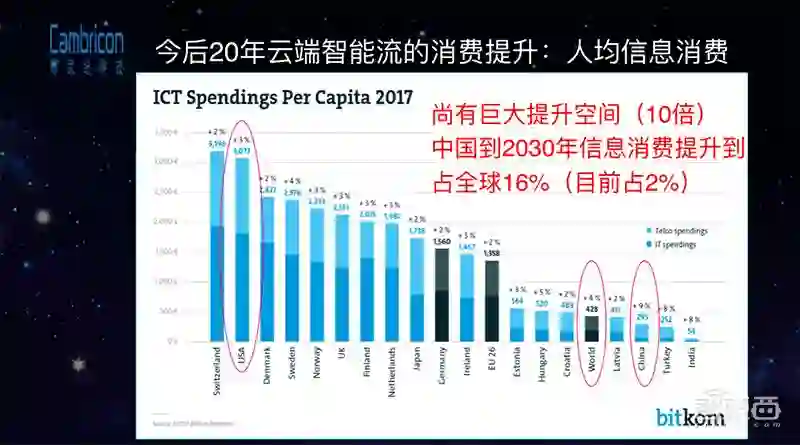
未来20年智能计算系统的需求,至少中国市场的消费提升潜力是非常巨大的,相比于现在至少有10倍以上的消费提升。未来计算系统上主要运行的不是现在这样的数据流,会是一种叫做计算流的处理过程。比如说现在我们渐渐用语音进行购物,只需要对着手机描述一下需要买哪个电视剧里主角婚礼上穿的礼服,系统就会自动给你推送一条产品店铺信息;在看短视频的时候,系统会告诉你哪部分是高潮剧情,你需要买什么样的产品,都是通过智能处理的过程把消费过程推送给你的。

云端智能流的消费提升空间是非常巨大的,但是现在的计算系统还无法支撑未来种种消费升级的需求。比如说现在有非常多的实时计算需求(比如短视频、短语音),但由于有各种各样处理的程序进行加工,现在大家已经完全不能相信互联网上视频、语音的真实性了。现在有非常大量的训练和推理需求都是在云端进行的,但是传统的计算系统(CPU、GPU)在做图像识别加速的时候,训练的性能非常有限。原来用英特尔至强的CPU做人工智能快速检测算法,可能几秒钟处理1桢,现在华为手机上搭载了寒武纪1A,可以将其加速到每秒几十帧的程度,但这远远不够。
支持如Google、百度大脑等巨型系统,图像处理速度至少要提升到一万倍以上的规模;把人类大脑这么大的神经网络处理规模变成可移动的系统设备,也需要1万倍以上的性能提升。而这需要不同方向的公司进行努力,比如说寒武纪会提供架构提升,诸多算法公司会提供优化的算法。

目前在云端智能处理方面要解决的问题最终可以归结为能效比的瓶颈问题。我们目前已有的芯片结构如ASIC、ASIP、FPGA、GPU、CPU,它们的能效大约集中在每秒100亿次到1万亿次的能效比区间,再往上提升是非常困难的。因为当芯片设计得越通用其能效越低,能效越高的话通用性就非常差。
能效比提升需要先解决三个方面的问题:
1.如摩尔定律等物理定律渐渐再也无法发挥像原来那么强的功效了。我们现在设计芯片在相同面积的情况下功耗是上升的,无法保持同样的功耗。导致现在芯片里有非常多的晶体管,在一定的功耗下是无法打开的,所以存在很多晶体管的浪费,所以单纯提高晶体管的数量等是无法提高性能的。
2.指令集并行、多核并行方面渐渐也出现了瓶颈。比如说现在做的超级系统,大概只有50%左右的并行效率。
3.应用场景也在发生变化,不像以前只在台式机平台下做计算就可以。现在出现了很多新的计算平台,如智能手机,未来汽车也将成为新的计算平台。现在云端的重要性也已变得越来越突出了。以前说到云端大家想到了超算,但现在一些商业化平台比如云计算已经非常普遍了。
这都要求新的芯片架构出现,新的芯片需要满足两个特征:1.性能功耗比非常高;2.通用性强。但要同时满足这两个条件其实是非常困难的。
那该怎么做呢?现在业界归结为的做法主要集中在领域专用的架构上,这种架构需要支持非常高的性能功耗比,里面采用非常多的电路都是领域专用的。但在通用性方面又要兼顾,不能做到像普通通用芯片如CPU一样对所有计算加速都非常强,而只能在某一领域里对某一大类的算法做非常好的加速效果,这就是现在的领域专用架构。这有点像做通用计算的CPU一样,可能是高速公路,非常高效也有序,但也有可能是非常低效无序的,现在领域专用架构想希望变成高速的高铁一样,让里面的信息都是有序的。

目前云端芯片市场上已有或者正在做研究的大概有三种主流路线:
1.生物方向做的比较多的,希望能模拟人脑产生的智能。比如说用生物的方程、描述神经元的方程进行简化,希望这些模型能用到芯片里,在芯片里跑起来,比如IBM的真北。而目前人的智能的产生还没有清楚地揭示,所以这种模型还无法达到预期的较高识别精度。但是研究界愿意投入更多的钱做研发,相信假以时日会有很棒的成果出来。
2.业内基于垄断地位的GPU产品。GPU产品在业界的垄断地位从做图形加速、科学计算等通用计算的GPU一脉相承过来的,其并行程度非常高,但目前也遇到瓶颈问题。因为GPU非常通用,所以功耗很难降下来。比如端芯片最新如V100这样的GPU功耗达300到400瓦,其功耗很难继续降低了。另外一方面其性能提升曲线也无法像以前那么陡峭了,比如做人工智能的处理,对稀疏化网络的加速,其效果远远比不上专用的加速芯片。
3.现在业界普遍做的是第三种,领域专用的深度学习处理器。可以说几乎所有要做智能芯片的公司大家研发的都是这个方向的芯片,而并非要投钱做新的GPU产品来支持深度学习。
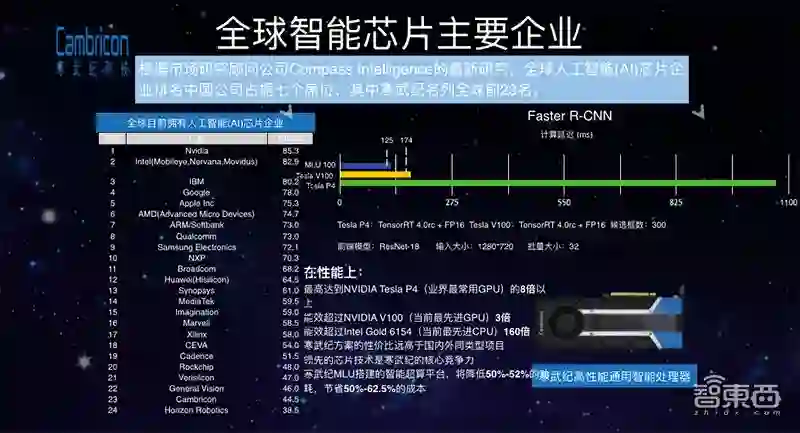
这是2018年上半年全球有志于推出智能芯片公司的综合排名。从中可以看出做服务器芯片、云端芯片的主要玩家有英伟达、IBM、Google、华为海思、寒武纪等。但市场上大规模应用的几个主要玩家和产品有:Google的TPU,其TPU二代拥有每秒80万亿次的计算能力;华为海思也在做自己的云端计算芯片,但要今年才出来,预计计算能力可能是每秒256万亿次;寒武纪去年5月份推出的MLU100,每秒128万亿次的计算能力。当然还有一些其他的公司,像英特尔收购了深度学习创企Nervana,从2016年开始一直进行研发,今年年初发布了产品,但具体的性能参数还没有完全给出。此外,其他的一些公司也推出看不是概念产品,但没摆到市场上进行销售。

很多软件互联网公司也在做芯片研发,比如百度的“昆仑”,还有很多其他公司也会推的相应的芯片。相信今年之内芯片相比于2018年会翻番甚至4倍的提升,同时会有大量深度学习的云端芯片出来。
云端芯片需要处理的人工智能应用主要集中哪些方面?原来主要是做识别,现在不仅做识别还要做理解。现在的人工智能还是属于计算智能,基于数学、统计学的原理,可以被欺骗也可以对抗。比如把识别猫的像素点变成游艇,或者自动驾驶中只用单一的方法就没有办法区别火车的反光和阳光下的白云。所以还需要对图片中的场景进行理解,比如说汽车需要对光学传感器数据、雷达图像、后台数据库,路况,语音输入内容等多方面数据进行识别和理解,最后做到多模态融合。

这就需要我们对所有类型的算法都得支持,包括现在的消费类产品。比如现在虚拟现实技术有很多内容,但互动仍非常差。怎么做到像电影《头号玩家》里那么强的互动呢?这需要芯片几乎要支持所有种类的深度学习算法和大部分的机器学习算法。而现在的终端芯片很难支持这么多算法。但云端的智能芯片必须要支持现在所有的算法,对像机器视觉、语音识别、自然语言理解都需要有非常好的加速比,这也是寒武纪目前一直在做的事情。
要做到这些,首先要解决三个最主要的问题:
1.芯片的规模数量有限,怎么支持神经网络越来越多、规模越来越大的算法呢?这需要算法在一个芯片上反复跑,神经网络运算、机器学习运算可以拆解成200多个加速计算形式,比如说乘加运算和一些简单函数等。
2.对结构已经固定的电路,芯片如何支持千变万换的算法呢?这需要指令集提供灵活的组合,比如支持CNN等基本网络的电路,我们通过修改指令级把最基本操作组合成记忆网络,通过这些方法对其进行加速使其可以支持更多的网络。但芯片做好以后功耗仍有限,现在人工智能应用的边际条件是不断变化的,需要我们随时提升计算精准性,保证识别效率。比如采用稀疏化算法,简化复杂电路,提升算法执行效率。
寒武纪对此的研究在国际上一直处于引领地位,从2012年开始寒武纪发布了很多深度学习处理器方面的里程碑架构论文,被很多企业追随。我们的目标是希望能够在云端做到端云一体。
现在很多端以后都会发展成多元具象的一些具体设备,像手机可以是浏览器、收音机、电视、摇控器,以后很多设备都会是多元具象的设备。这些设备显然是需要通用的智能处理能力的,同时要能够使云端训练好的模型和框架严丝合缝地移植到具体的终端设备上,但现在的很多设备做不到,希望未来的端云一体能做到。
在2018年上半年寒武纪曾提出一个想法,以后云端生态是不分高性能计算、超算和云计算的,会合而一体,里面通过加入非常多的支持人工智能的硬件和软件的框架,在商业化方面是完全开源、无缝对接的。
当时业界的发展还没有印证我们的想法,但是到2018年下半年很多大型的机器已经验证了我们的想法,比如美国阿冈实验室,他们做了很多的人工智能的科学计算,比如Google的云计算、美军的大型的智能云计算平台的招标以及世界排名第一的超算,采用4万块GPU V100做人工智能处理。那么未来云计算的平台肯定是通用的,里面会有非常多的人工智能的加速硬件。

现在头部的很多企业一年需要10000块加速卡,成本最便宜也要达1亿人民币,其需求量也处于井喷状态。寒武纪在2018年推出MLU100就是瞄准这个市场,目标是希望把占有率从0%提升到30%,所以目前我们和很多互联网头部企业做技术评测,希望能够很好的支持他们。今年寒武纪正在研发性能更高的支持训练的加速卡。
寒武纪的目标是通过加速卡赋能智能云端计算平台,云端智能计算平台把人工智能处理能力对互联网大数据的综合能力赋能给传统产业。比如说金融行业,可以对互联网消费需求进行信用评估,相比传统的信用来说成本很低1毛钱评估一次,用这样的方法促进传统产业进行升级。
今天我的分享到此结束,希望峰会越办越好,感谢!
本账号系网易新闻·网易号“各有态度”签约帐号
4月19日,作为上海车展官方合作媒体和会议合作伙伴,车东西将在上海车展同期举办GTIC 2019全球智能汽车供应链创新峰会。首批5位大咖已经确认参会,扫码报名。





