![]()
过去几年,卷积神经网络(CNN)在视频中的动作识别问题上取得了巨大的进展。然而,这些方法往往会过于关注背景中的场景,而忽视了具体的动作本身。如图1所示,尽管人类的动作在图片中被屏蔽了,我们仍然能够通过场景来推断出最有可能的动作类型。对于卷积神经网络模型而言,通过识别场景来给出动作的类型就不可避免地带上了场景偏差。
图1. 尽管看不到人影,我们仍然能够通过场景来推断具体动作。
这种场景偏差在一些情况下会导致模型产生我们不希望看到的效果。如图2所示,左图中,由于棒球场的背景,唱歌的人会被错误地预测为在打棒球,而在右图中,即使我们把游泳的人完全挡住,模型也会由于对游泳池背景的识别,给出游泳的预测结果。
![]() 图2. 研究去偏差算法的动机。
图2. 研究去偏差算法的动机。
关于消除场景偏差的研究还比较少,下面这篇发表于NeurIPS 2019的论文提出了一种基于迁移学习的方案来减轻场景偏差。
![]()
论文链接:https://arxiv.org/pdf/1912.05534.pdf
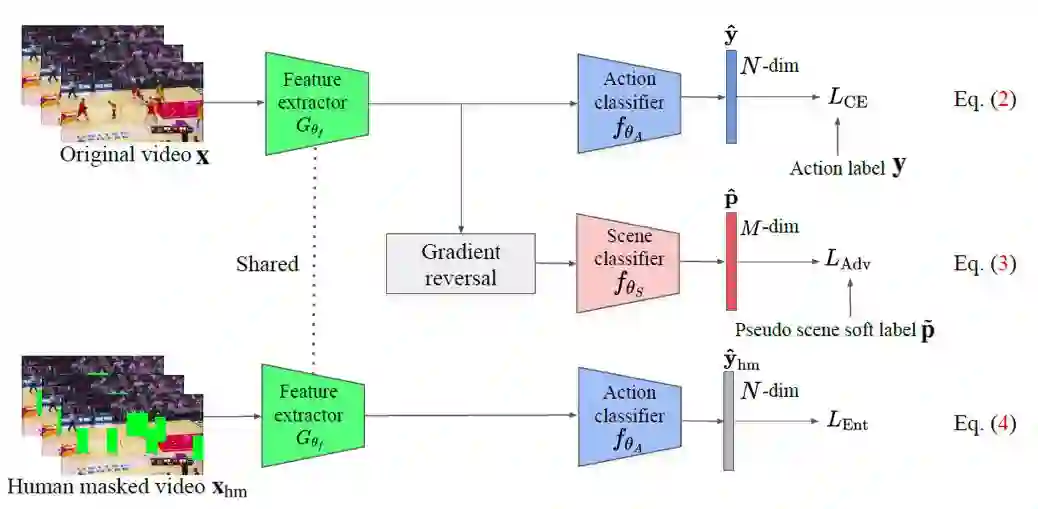
这篇论文的贡献在于提出了两种在预训练CNN模型时旨在减轻场景偏差的损失定义:
1)场景对抗损失(scene adversarial loss),鼓励模型学习场景不变的特征表示;
2)人体遮挡混淆损失(human mask confusion loss),来阻止模型在人体不可见的时候仍然给出动作预测。
为了验证所提方案的有效性,这篇论文在三种动作理解任务上进行了实验:动作分类,时序动作定位和时空动作识别。实验结果表明采用了偏差去除的迁移学习方案要比基准模型表现更好。
这个方案的目标是通过在一个大的视频分类任务上的预训练,学习特征提取器的参数 ![]() 。在这个过程中,作者们用到了三种损失函数。首先在Mini-Kinetics-200数据集[1]上,通过一个标准的交叉熵损失函数
使得从学习到的表征中无法推断出场景。最后,通过使用Mask R-CNN[2]检测出人体并加以遮挡,构造出一个被遮挡后的数据集,并应用人体遮挡混淆损失
。在这个过程中,作者们用到了三种损失函数。首先在Mini-Kinetics-200数据集[1]上,通过一个标准的交叉熵损失函数
使得从学习到的表征中无法推断出场景。最后,通过使用Mask R-CNN[2]检测出人体并加以遮挡,构造出一个被遮挡后的数据集,并应用人体遮挡混淆损失
这篇论文在三种动作理解任务上进行了实验:动作分类,时序动作定位和时空动作识别。用到的数据集如下:
1)预训练:Mini-Kinetics-200[1],包含了8万个训练视频和5千个验证视频。
2)动作分类:UCF-101[3], 包含了101中动作类别对应的13,320个视频;HMDB-51[4],包含了51个动作类别对应的6,766个视频;Diving48[5],包含了48种开车动作的1.8万个视频。对于前两个数据集,这篇论文采用了前人工作中的训练/测试集划分方案。
3)时序动作定位:THUMOS-14[6],包含了带有20种动作类别及时间戳。
4)时空动作识别:JHMDB[7],包含了21种动作的928个视频,每个要识别的动作都具有标注框。
这篇论文采用了一些前人的模型,并结合了所提出的场景偏差消除的方案。在预训练阶段,这篇论文使用的是3D-ResNet-18 [8]。对于时空动作识别,这篇论文采用的是基于VGG-16的模型[9]。
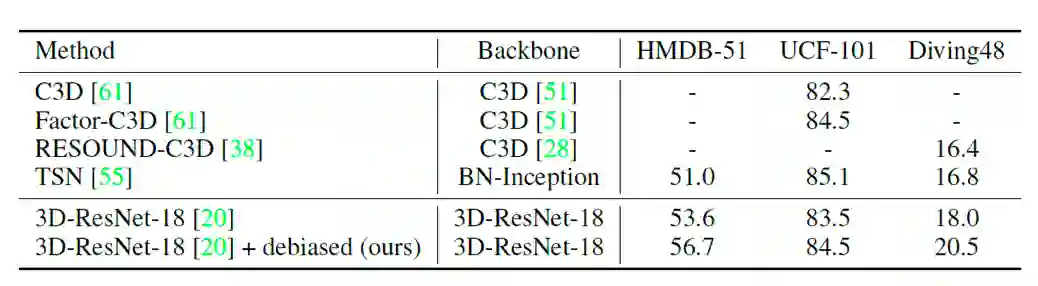
在动作分类任务上的实验结果如表1所示。通过增加去除场景偏差的操作,三个数据集上的表现都有所提高。
表1. 动作分类任务的准确率。UCF-101和HMDB-51给出的不同划分方式的平均结果。
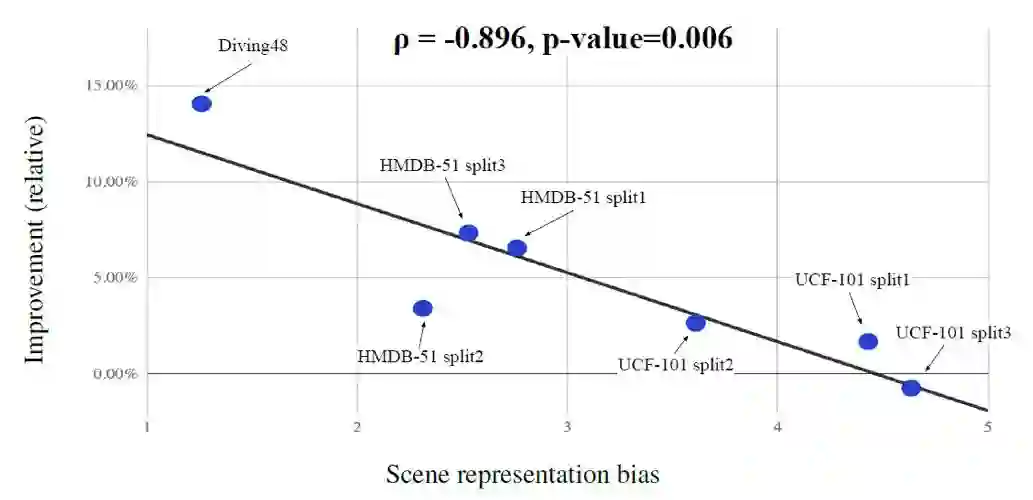
图4中也给出了相对的准确率提升与场景表征偏差之间的负相关。可以看到数据集中的场景偏差越大,去偏差算法带来的提升就越小。
图4. 相对的准确率提升与场景表征偏差之间的负相关。UCF-101和HMDB-51的不同划分方式会有不同的结果。
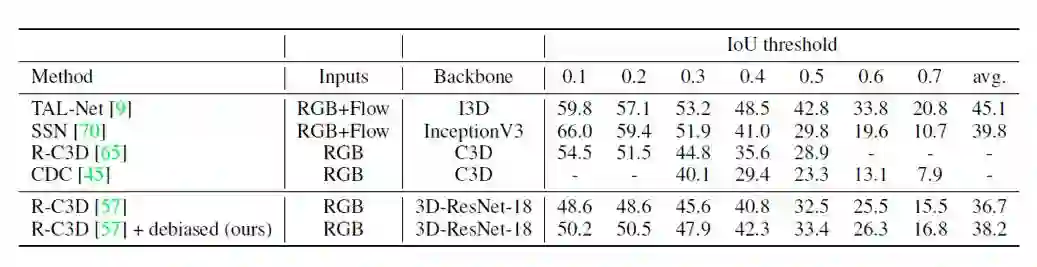
表2和表3分别给出了时序动作定位和时空动作识别任务上的实验结果。在这两个任务上,这篇论文提出的场景偏差去除的方案都能够提升基准模型的表现。
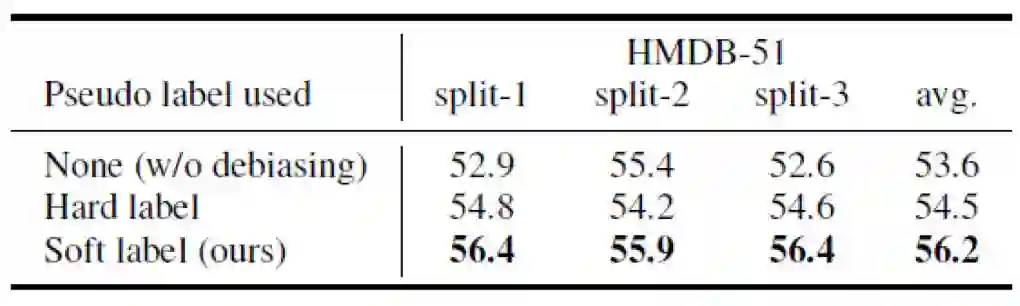
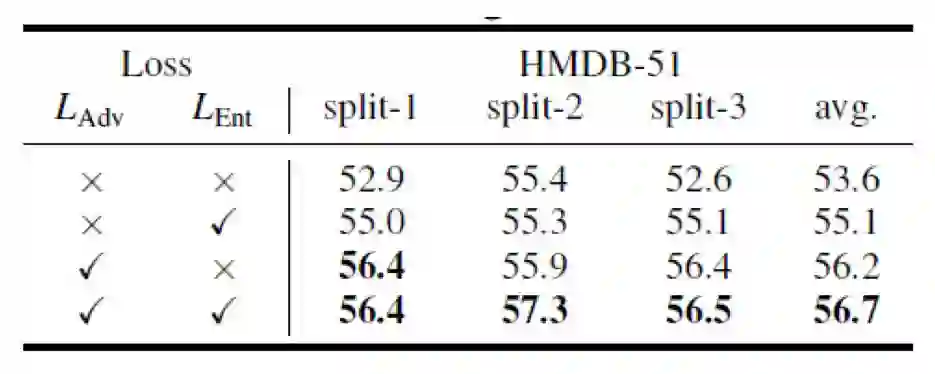
在HMDB-51数据集上,这篇论文进一步完善了伪场景标签和不同损失函数组合的情况。表4验证了使用软场景标签的方式能够更好地提升表现,而表5验证了同时使用场景对抗损失和人体遮挡混淆损失能带来最大的性能提升。
为了进一步验证所提场景偏差消除方案的有效性,这篇论文在HMDB-51和UCF-101两个数据集上进行了类激活映射的分析,如图5所示。结果表明,在不使用场景偏差消除时,模型会因为过于关注场景而非人体导致错误的分类;而在使用了场景偏差消除后,模型能够更加关注人体本身,从而给出正确的动作类别。
图5. HMDB-51和UCF-101两个数据集上的类激活映射举例。蓝色下划线字体表示正确的分类,而红色字体代表错误的分类。
这篇论文关注了一个之前研究较少涉及的问题,即动作识别中的背景偏差消除问题,并且提出了一种有效的方案,包含了两个新提出的损失定义,即场景对抗损失和人体遮挡混淆损失。在动作分类,时序动作定位和时空动作识别这三类不同任务上的大量实验表明了这篇论文所提方案的有效性。
[1] Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotemporal feature learning for video understanding. In ECCV, 2018.
[2] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN. In ICCV, 2017.
[3] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012.
[4] Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. HMDB: A large video database for human motion recognition. In ICCV, 2011.
[5] Yingwei Li, Yi Li, and Nuno Vasconcelos. Resound: Towards action recognition without representation bias. In ECCV, 2018.
[6] Y.-G. Jiang, J. Liu, A. Roshan Zamir, G. Toderici, I. Laptev, M. Shah, and R. Sukthankar. THUMOS challenge: Action recognition with a large number of classes. http://crcv.ucf.edu/THUMOS14/, 2014.
[7] Hueihan Jhuang, Juergen Gall, Silvia Zuffi, Cordelia Schmid, and Michael J Black. Towards understanding action recognition. In ICCV, 2013.
[8] Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In CVPR, 2018.
[9] Gurkirt Singh, Suman Saha, and Fabio Cuzzolin. Online real time multiple spatiotemporal action localization and prediction on a single platform. In ICCV, 2017.



 图2. 研究去偏差算法的动机。
图2. 研究去偏差算法的动机。