预警:五月小心故障
预计768k日会在下个月内到来,这让人联想起AT&T、英国电信(BT)、康卡斯特、斯普林特和韦里逊全部中招瘫痪的512k日。
名为“768k日”的互联网里程碑事件越来越近,一些网络管理员惴惴不安,担心过时的网络设备导致宕机。
这种担心不无道理,许多公司已采取了预防措施以更新旧路由器,但仍预计会出现一些连锁故障。
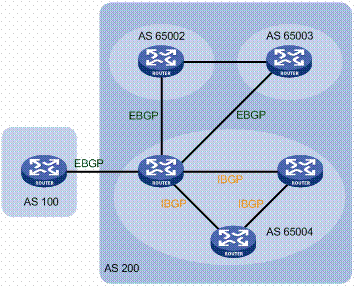
768k日是什么东东?
768K日这个术语来自所有互联网故障之母:512k日(512k Day)。
512k日发生在2014年8月12日,当时全球各地的数百家互联网服务提供商(ISP)瘫痪,由于互联网连接中断或数据包丢失,因交易错失和费用而导致数十亿美元的损失。
最初的512k日之所以会发生,是由于路由器用来存储全局BGP路由表的内存不足,BGP路由表是一个文件,包含所有连接至互联网的已知网络的IPv4地址。
当时,互联网的大部分系统通过分配TCAM(三元内容可寻址内存)的设备进行路由;TCAM足够大,存储最多512000条互联网路由。
但在2014年8月12日那天,韦里逊增加了15000条新的BGP路由,这导致全局BGP路由表在没有警告的情况下突然超过512000条。在旧路由器上,这表现为全局路由表文件从分配的内存中溢出,每次尝试读取或处理该文件都会使设备崩溃。微软、eBay、LastPass、BT、LiquidWeb、康卡斯特、AT&T、斯普林特和韦里逊等公司统统受到了影响。
许多老式路由器都收到了紧急固件补丁,让网络管理员得以为分配用于处理全局BGP路由表的内存大小设置更高的阈值。
大多数网络管理员都遵循当时提供的文档,将新的上限设置为768000,即768k。
全局BGP路由表在旧路由器上达到768000的限制
CIDR Report是跟踪全局BGP路由表的网站,它估计该文件的大小是773480个条目;然而,这个版本的表并非官方的表,含有一些重复条目。
一个名为BGP4-Table的Twitter机器人程序也一直在跟踪全局BGP路由表的大小,预料会出现768k日;它估计文件的实际大小为767392,离溢出仅一步之遥。
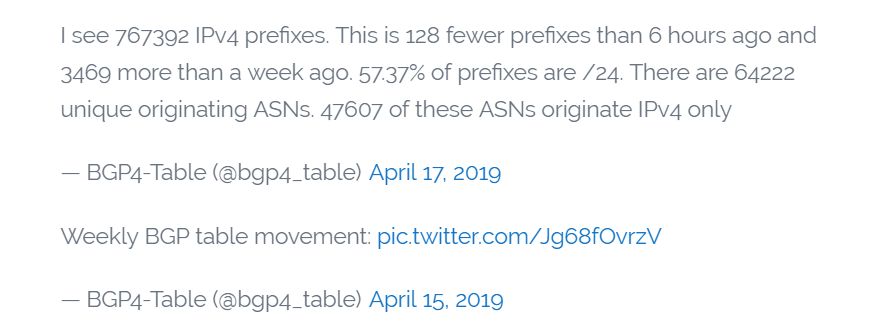
我看到767392个IPv4前缀。这比6小时前少了128个前缀,比一星期前多了3469个。57.37%的前缀是/ 24。有64222个独特的发起ASN(自治系统号)。这些ASN中有47607个仅发起IPv4。
预计768k日会在下一个月内出现
IT外媒ZDNet近日采访了AAGICo柏林的网络工程师Aaron A. Glenn和北新英格兰中立互联网交换中心(NNENIX)主任Jim Troutman。
他们俩都估计768k日会在下一个月内出现。
但与许多网络管理员不同的是,他们并不认为该事件会像2014年那样引起整个互联网的中断。然而Glenn和Troutman都预计,一些公司和较小的本地ISP会受到影响。
Glenn对ZDNet说:“如果出现任何大规模的中断或故障,我会感到有些意外。十年前,IP转接(IP transit)市场大得多。现在有几家大型运营商拥有基本上合适的设备。”
Troutman同意同仁的想法,说“我认为不会给互联网造成‘大规模破坏’。互联网具有的弹性和冗余性比大多数人想象的强得多。”
他补充道:“肯定有一些网络运营商和企业最终用户组织会遇到问题却浑然不觉。”
一些网络管理员已准备好
好消息是,网络管理员早就知道了768k日,许多人已作好了准备,要么把旧的路由器换成新的;要么调整固件,允许设备处理超过768000条路由的全局BGP路由表。
Troutman说:“是的,可以调整TCAM内存设置以帮助缓解问题,甚至在一些平台上超过768k条路由,如果你不运行IPv6,这招会管用。这些设置更改需要重启才能生效。”
“如果你接受所有路由,768k IPv4路由限制只是一个问题。如果你丢弃或不接受/24路由,这将整个BGP路由表的大小削减一半。”
Troutman补充道:“运行旧设备的组织应该已经知道这一点,应该已进行配置以限制已安装的前缀。这不难。”
他说:“我有个电信公司ILEC客户仍在旧的思科6509 SUP-720设备上顺畅地运行网络,我还很熟悉其他客户。”
据Troutman声称,诀窍是让ISP及其他网络运营商使用旧设备,将/24路由的所有出站流量指向上游转接提供商,这些提供商最有可能运行现代设备,并为客户转接流量。
目前,我们无法知道768k日那天会有多少路由器和网络受到影响,因为没有Shodan搜索查询可以告诉我们易受攻击的路由器的数量和位置。
但正如Glenn告诉ZDNet的那样,“长期以来,思科6500/7600产品系列在许多地方极其普遍,”所以如果一些网络因忘记768k Day、没有作好准备而断开,也不要大惊小怪。
相关阅读:
ISP 配置 BGP 错误导致谷歌云瘫痪,中国电信背了黑锅。。。
美国的大片地区又断网了:因技术人员配置失误,BGP路由泄露所致