让代码自动补全的全套流程
点击蓝字
关注我们

作者丨熊唯、黄飞
来源丨腾讯技术工程
AI 如果真的可以写代码了,程序员将何去何从?近几年,NLP 领域的生成式任务有明显的提升,那通过 AI 我们可以让代码自动完成后续补全吗?本文主要介绍了如何使用 GPT2 框架实现代码自动补全的功能。
数据
1、数据采集
2、数据清理
/* 注释文本*/
/**
注释段落
*/
// 注释文本
code //注释
3、数据编码
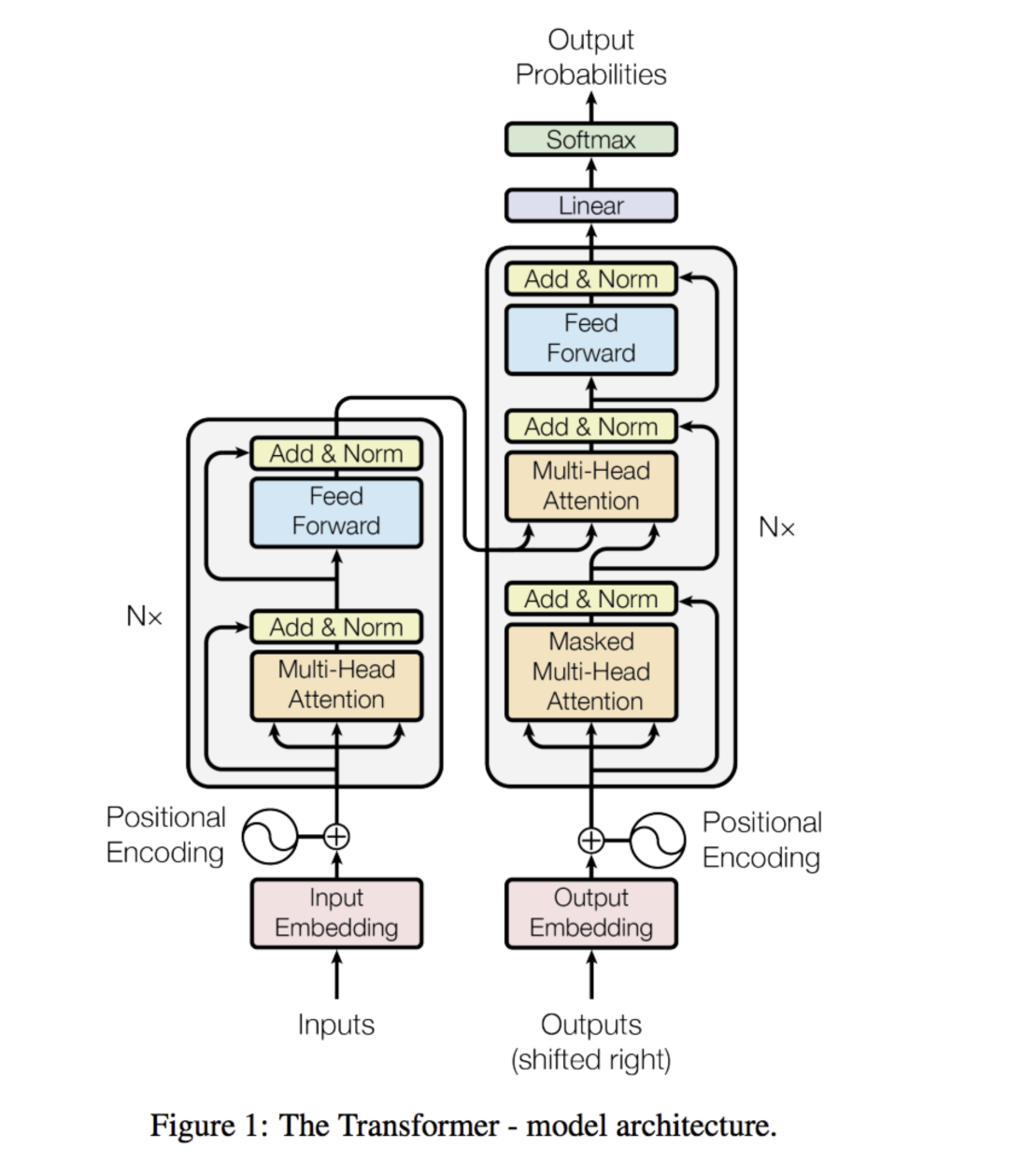
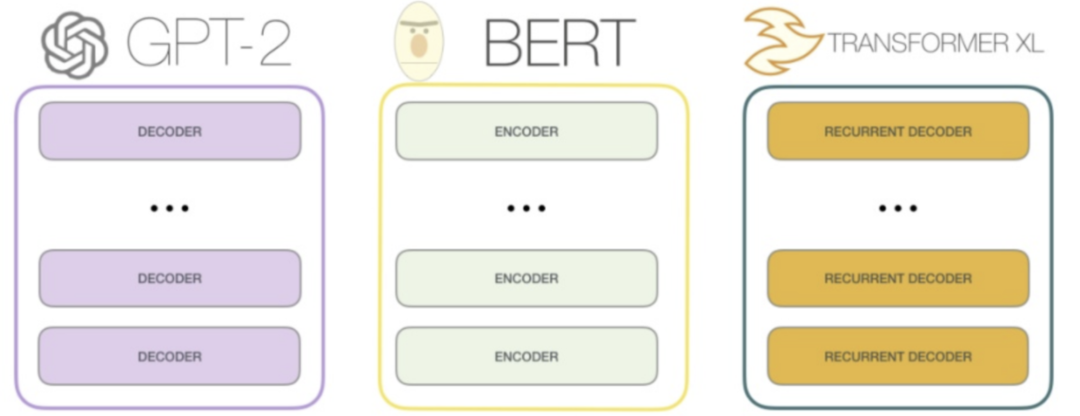
模型算法

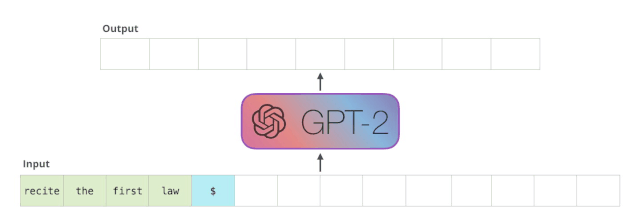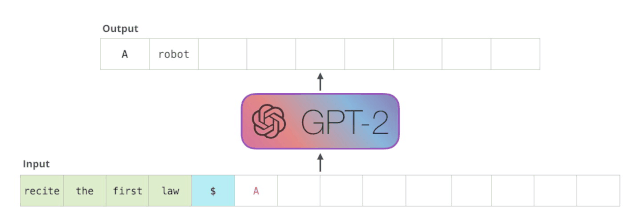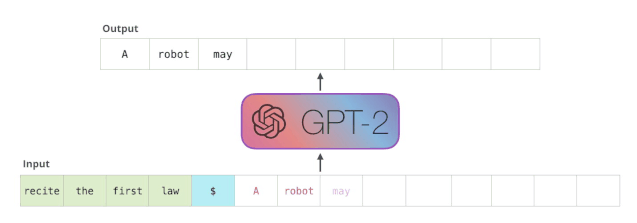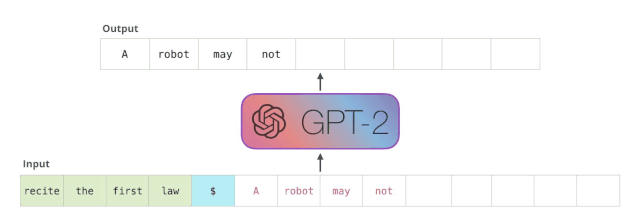
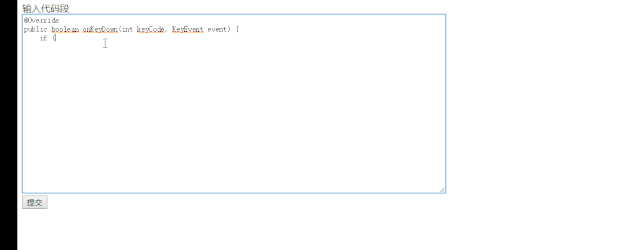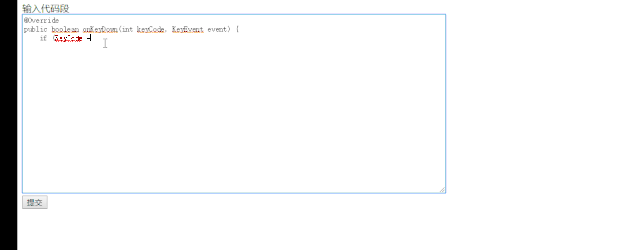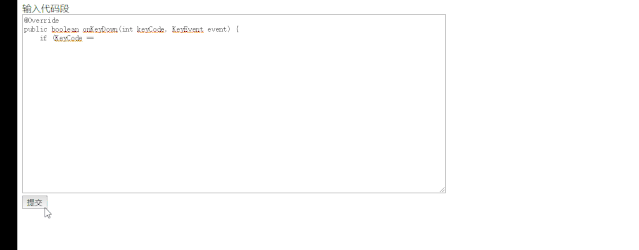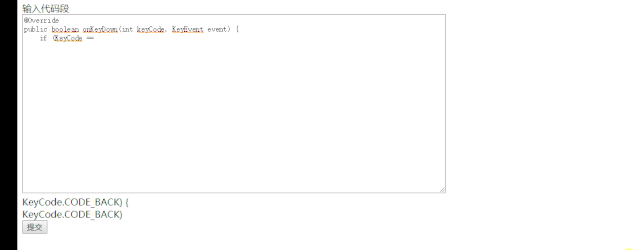
conda create -n flask python=3.6
source activate flask
pip install flask
from flask import Flask
from flask import request
app = Flask()
# route把一个函数绑定到对应的 url 上
@app.route("/plugin",methods=['GET',])
def send():
data = request.args.get('data')
# 模型预测逻辑
out = model_infer(data)
return out
if __name__ == '__main__':
app.run(host='0.0.0.0',port=8080, debug=False)

url = http://ip:8080/plugin?data="输入"
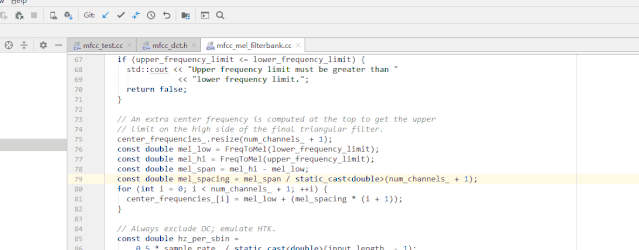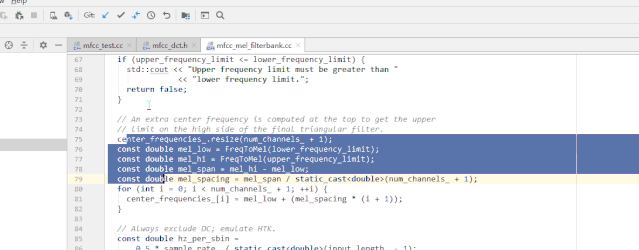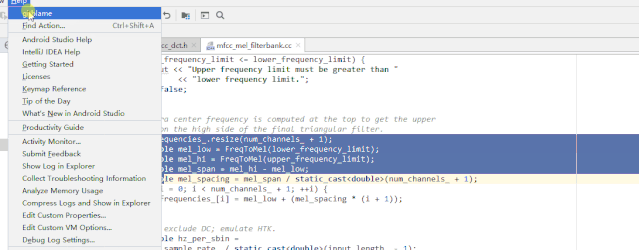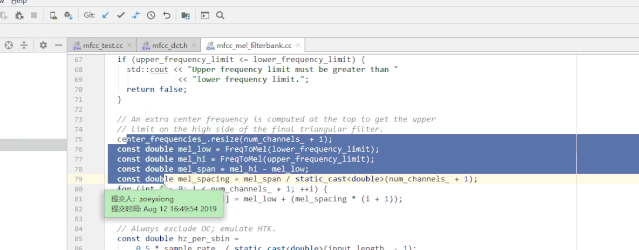
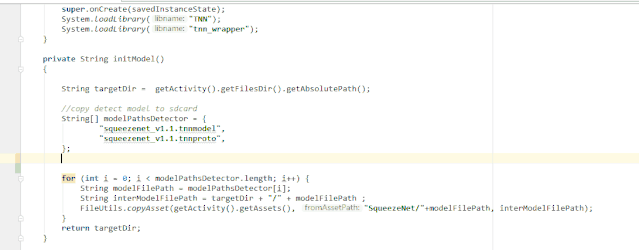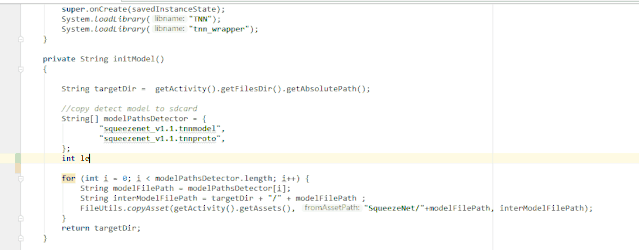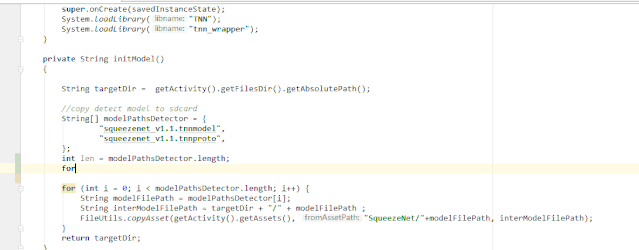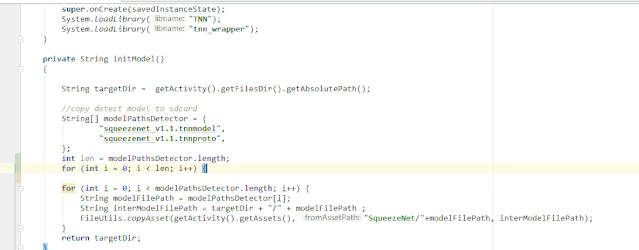
public class GitBlame extends AnAction {
private void showPopupBalloon(final Editor editor, final String result) {
ApplicationManager.getApplication().invokeLater(new Runnable() {
public void run() {
JBPopupFactory factory = JBPopupFactory.getInstance();
factory.createHtmlTextBalloonBuilder(result, null, new JBColor(new Color(186, 238, 186), new Color(73, 117, 73)), null)
.setFadeoutTime(5000)
.createBalloon()
.show(factory.guessBestPopupLocation(editor), Balloon.Position.below);
}
});
}
@Override
public void actionPerformed(AnActionEvent e) {
// TODO: insert action logic here
//获得当前本地代码根目录
String base_path = e.getProject().getBasePath();
String file_path = e.getProject().getProjectFilePath();
//获取编辑mEditor
final Editor mEditor = e.getData(PlatformDataKeys.EDITOR);
if (null == mEditor) {
return;
}
SelectionModel model = mEditor.getSelectionModel();
final String selectedText = model.getSelectedText();
if (TextUtils.isEmpty(selectedText)) {
return;
}
//获取当前编辑文档的目录
PsiFile mPsifile = e.getData(PlatformDataKeys.PSI_FILE);
VirtualFile file = mPsifile.getContainingFile().getOriginalFile().getVirtualFile();
if (file != null && file.isInLocalFileSystem()) {
file_path = file.getCanonicalPath();
}
//gitkit工具
JGitUtil gitKit = new JGitUtil();
String filename = file_path.replace(base_path+"/","");
//得到blame信息
int line_index = mEditor.getSelectionModel().getSelectionStartPosition().getLine();
String blame_log = gitKit.git_blame(base_path,filename,line_index);
//展示
if (!blame_log.isEmpty()){
showPopupBalloon(mEditor, blame_log);
}
}
}
// 请求url格式(和flask接口一致)
String baseUrl = "http://ip:8080/plugin?data=";
// 获取当前编辑位置文本
PsiFile str = position.getContainingFile();
// 根据模型上文限制获取代码端
String data = getContentCode();
String url = baseUrl+data;
// 发送请求
String result = HttpUtils.doGet(url);
// 后处理逻辑,在提示框显示预测结果
show()





登录查看更多
相关内容

Arxiv
7+阅读 · 2019年4月18日


相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月18日