手把手| 用Python代码建个数据实验室,顺利入坑比特币
作者:Patrick Triest
编译:Katherine Hou、林海、Shan LIU、高宁、Yawei
比特币市场到底是如何运作的?数字加密货币(cryptocurrency)跌宕起伏的原因是什么?不同的山寨币(altcoins)市场之间是紧密联系还是各自为营?我们该如何预测接下来将发生什么?
关于数字加密货币(如:比特币和以太坊)的文章铺天盖地,数百个自诩专家的作者各自发表着他们对比特币未来的猜想。而用来支持他们观点的这些分析中强有力的数据和统计学基础却乏善可陈。
这篇文章的目的是简单介绍“如何用Python来分析数字加密货币”。我们将用简单的Python代码来检索、分析和可视化不同的数字货币数据。在这个过程中,我们将揭示一个有趣的趋势:这些不稳定的市场是如何运作的,它们又是如何发展的。
这不是一篇解释数字加密货币是什么的科普贴(如果你需要,我推荐这篇很棒的概述),这也不是一篇讲哪个货币会升值、哪个会贬值的观点性文章。相反,在这篇教程中,我们所关心的只是获取原始数据,并揭示隐藏在数字中的故事。
步骤1 - 配置你的数据实验室
这篇教材适合在不同技能水平上的爱好者、工程师和数据科学家们。要求的技能只是对Python有基础的了解,以及知道如何用命令建立一个项目。
包含运行结果的notebook完整版本可以在这里下载。
步骤1.1 - 安装 Anaconda
安装这个项目所需的所有相关环境,最简单的办法就是用Anaconda。它是一个打包的Python数据科学生态系统和依赖管理器。
推荐使用下面的官方安装指南来安装Anaconda https://www.continuum.io/downloads
如果你是一个高阶用户,而你不需要使用Anaconda,那也完全没有问题。我会假设你在安装必须的依赖环境时不需要帮助,你可以直接跳到第二部分。
步骤1.2 - 建立一个Anaconda项目环境
当Anaconda安装完成后,我们需要创建一个新的环境来管理我们的依赖包。运行 conda create --name cryptocurrency-analysis python=3 来为我们的项目创建一个新的Anaconda环境。接下来,运行source activate cryptocurrency-analysis ( Linux/macOS 系统) 或者 activate cryptocurrency-analysis (windows 系统) 来激活这个环境。
最后,运行 conda install numpy pandas nb_conda jupyter plotly quandl 来为这个环境安装所需的依赖包。完成这些需要几分钟的时间。
为什么要用环境?如果你打算在你的电脑上运行很多Python项目,那么分开不同项目的依赖包(软件库和包)来避免冲突是很有帮助的。
Ananconda会为每一个项目的依赖包创建一个特殊的环境目录,使得所有包都能妥善地被管理和区分。
步骤1.3 - 启动一个交互的Jupyter Notebook
当环境和依赖包都安装好之后,运行 jupyter notebook 来启动 iPython 内核,然后用你的浏览器访问http://localhost:8888/ 。创建一个新的Python notebook,确保它使用的内核是Python [conda env:cryptocurrency-analysis]。

步骤1.4 – 导入依赖包
当你打开了一个空的Jupyter notebook,我们要做的第一件事就是导入所需的依赖包。
import os import numpy as np import pandas as pd import pickle import quandl from datetime import datetime我们还要导入Plotly来启用离线模式。
import plotly.offline as py import plotly.graph_objs as go import plotly.figure_factory as ff py.init_notebook_mode(connected=True)步骤2 - 获得比特币的价格数据
一切就绪,我们可以开始获取要分析的数据了。首先,我们要用Quandl的免费比特币接口来获得比特币的价格数据。
步骤2.1 - 编写Quandl帮助函数
为了方便数据获取,我们要编写一个函数来下载和同步来自Quandl(https://www.quandl.com/ 号称金融数据界的维基百科)的数据。
def get_quandl_data(quandl_id): '''Download and cache Quandl dataseries''' cache_path = '{}.pkl'.format(quandl_id).replace('/','-') try: f = open(cache_path, 'rb') df = pickle.load(f) print('Loaded {} from cache'.format(quandl_id)) except (OSError, IOError) as e: print('Downloading {} from Quandl'.format(quandl_id)) df = quandl.get(quandl_id, returns="pandas") df.to_pickle(cache_path) print('Cached {} at {}'.format(quandl_id, cache_path)) return df我们用pickle来序列化,把下载的数据存成文件,这样代码就不会在每次运行的时候重新下载同样的数据。这个函数将返回Pandas数据框(Dataframe)格式的数据。如果你对数据框不太熟悉,你可以把它想成是强大的电子表格。
步骤2.2 – 抓取Kraken交易所定价数据
我们首先来获取Kraken比特币交易所的历史比特币汇率。
# Pull Kraken BTC price exchange data btc_usd_price_kraken = get_quandl_data('BCHARTS/KRAKENUSD')我们可以用head()方法来查看数据框的前五行。
btc_usd_price_kraken.head()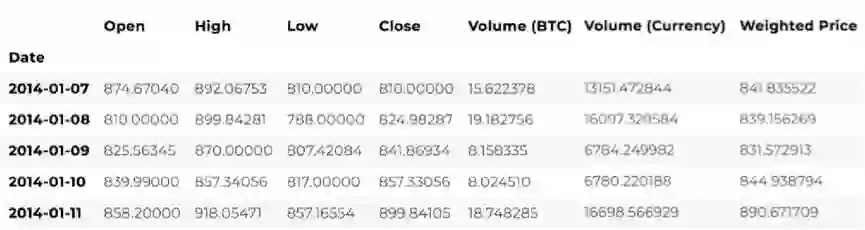
接下来,我们要做一个简单的图表,以此来快速地通过可视化的方法验证数据基本正确。
# Chart the BTC pricing data btc_trace = go.Scatter(x=btc_usd_price_kraken.index, y=btc_usd_price_kraken['Weighted Price']) py.iplot([btc_trace])

这里,我们用Plotly 来完成可视化部分。相对于使用一些更成熟的Python数据可视化库,例如Matplotlib ,用Plotly是一个不那么传统的选择,但我认为Plotly是一个不错的选择,因为它可以调用D3.js的充分交互式图表。这些图表有非常漂亮的默认设置,易于探索,而且非常方便嵌入到网页中。
我们可以将生成的图表与公开可用的比特币价格图表(如Coinbase上的图表)进行比较,作为一个快速的完整性检查,验证下载的数据是否合理。
步骤2.3 从更多的比特币交易所抓取价格数据
你可能已经注意到,上面的数据集中存在数据缺失现象--特别是在2014年末和2016年初。在Kraken交易所的数据集中,这种数据缺失情况尤为明显。我们当然不希望这些数据会影响到我们对价格的全面分析。
比特币交易所的特点是,供需关系决定比特币的价格。因而,没有哪个交易的价格所能够成为市场的“主流价格”。为了解决这个问题,以及刚刚提到的数据缺失问题(可能是由于技术性断电和数据的差错),我们将从三家主要的比特币交易所抓取数据,进而计算出平均的比特币价格指数。
首先,我们把各个交易所的数据下载到到由字典类型的数据框中。
# Pull pricing data for 3 more BTC exchanges exchanges=['COINBASE','BITSTAMP','ITBIT']exchange_data={}exchange_data['KRAKEN']=btc_usd_price_kraken for exchange in exchanges:exchange_code='BCHARTS/{}USD'.format(exchange)btc_exchange_df=get_quandl_data(exchange_code)exchange_data[exchange]=btc_exchange_df步骤2.4 将所有价格数据整合到单一数据框之中
接下来,我们将要定义一个简单的函数,把各个数据框中共有的列合并为一个新的组合数据框。
def merge_dfs_on_column(dataframes, labels, col):'''Merge a single column of each dataframe into a new combined dataframe'''series_dict={} for index in range(len(dataframes)):series_dict[labels[index]]=dataframes[index][col]return pd.DataFrame(series_dict)
现在,基于各个数据集的“加权价格”列,把所有的数据框整合到一起。
# Merge the BTC price dataseries' into a single dataframebtc_usd_datasets=merge_dfs_on_column(list(exchange_data.values()), list(exchange_data.keys()),'Weighted Price')最后,可以使用“tail()”方法,查看合并后数据的最后五行,以确保数据整合成功。
btc_usd_datasets.tail()
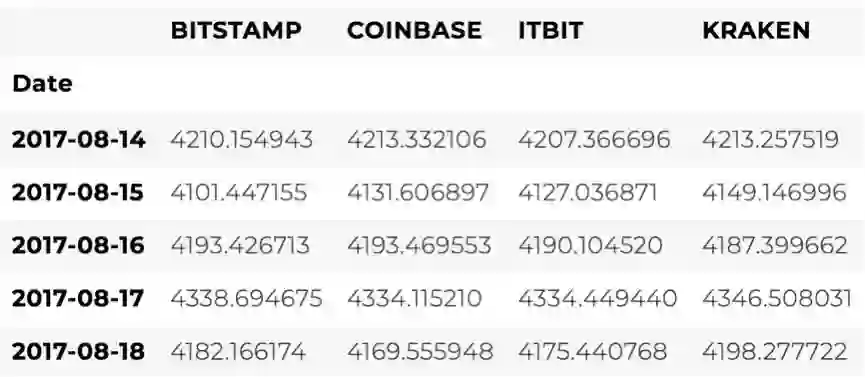
看起来,这些数据符合我们的预期:数据范围大致相同,只是基于各个交易所的供求关系而略有不同。
步骤2.5 价格数据的可视化
从逻辑上来说,下一步就是通过可视化,将这些数据进行比对。为此,我们需要先定义一个辅助函数,通过提供单行命令使用数据制作图表。
def df_scatter(df, title,seperate_y_axis=False,y_axis_label='', scale='linear',initial_hide=False):'''Generate a scatter plot of the entire dataframe'''label_arr= list(df)series_arr= list(map(lambda col:df[col],label_arr)) layout =go.Layout(title=title, legend=dict(orientation="h"), xaxis=dict(type='date'), yaxis=dict(title=y_axis_label, showticklabels=notseperate_y_axis, type=scale))y_axis_config=dict(overlaying='y', showticklabels=False, type=scale ) visibility ='visible'ifinitial_hide: visibility ='legendonly'# Form Trace For Each Seriestrace_arr=[]for index, series in enumerate(series_arr): trace =go.Scatter(x=series.index, y=series, name=label_arr[index], visible=visibility)# Add seperate axis for the seriesif seperate_y_axis: trace['yaxis']='y{}'.format(index +1) layout['yaxis{}'.format(index +1)]=y_axis_configtrace_arr.append(trace) fig =go.Figure(data=trace_arr, layout=layout)py.iplot(fig)为简便起见,我不会过多探讨这个辅助函数的工作原理。如果想了解更多,请查看Pandas 和 Plotly的说明文件。
现在,我们就可以轻松制作比特币价格数据的图形了!
# Plot all of the BTC exchange pricesdf_scatter(btc_usd_datasets,'Bitcoin Price (USD) By Exchange')
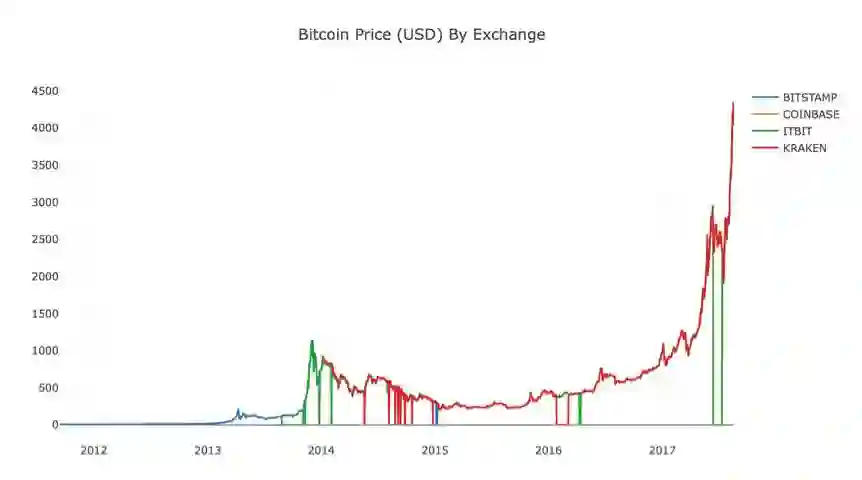
步骤2.6 清理并加总价格数据
从以上图形中可以看到,尽管这四个系列数据遵循大致相同的路径,但其中还是有一些不规则的变化,我们将设法清除这些异常变化。
在2012-2017年的时间段中,我们知道比特币的价格从来没有等于零的时候,所以我们先去除数据框中所有的零值。
# Remove "0" valuesbtc_usd_datasets.replace(0,np.nan,inplace=True)
在重新构建数据框之后,我们可以看到更加清晰的图形,没有缺失数据的情况了。
# Plot the revised dataframedf_scatter(btc_usd_datasets,'Bitcoin Price (USD) By Exchange')
我们现在可以计算一个新的列:所有交易所的比特币日平均价格。
# Calculate the average BTC price as a new columnbtc_usd_datasets['avg_btc_price_usd']=btc_usd_datasets.mean(axis=1)
新的一列就是比特币的价格指数!我们再把它画出来,以核对该数据看起来是否有问题。
# Plot the average BTC pricebtc_trace=go.Scatter(x=btc_usd_datasets.index, y=btc_usd_datasets['avg_btc_price_usd'])py.iplot([btc_trace])
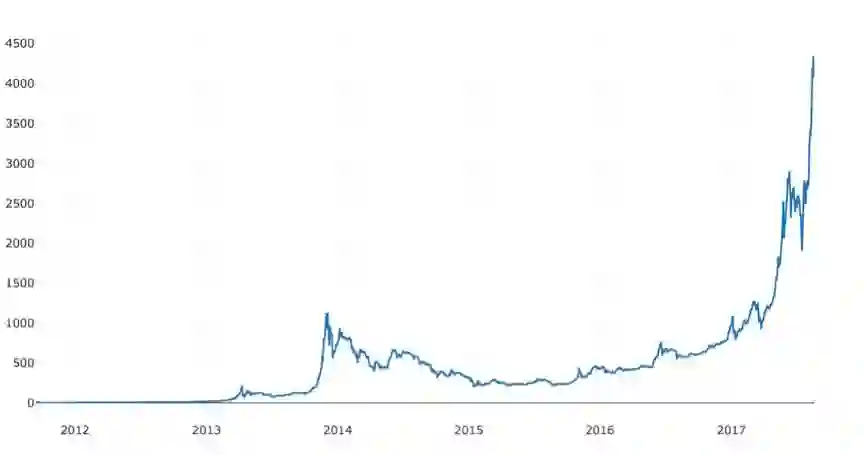
太好了,看起来确实没有问题。稍后,我们将继续使用这个加总的价格序列数据,以便能够确定其他数字货币与美元之间的兑换汇率。
步骤3 获取山寨币(Altcoins)价格
现在,我们已经有了比特币价格的时间序列数据了。接下来我们来看看非比特币的数字加密货币的一些数据,一般是指山寨币(Altcoins)。
步骤3.1 定义Poloniex交易所的API辅助函数
我们将使用Poloniex API来获取数字加密货币交易的数据信息。我们定义了两个辅助函数来获取山寨币的相关数据,这两个函数主要是通过这个API下载和缓存JSON数据。
首先,我们定义函数get_json_data,它将从给定的URL中下载和缓存JSON数据。
defget_json_data(json_url,cache_path):'''Download and cache JSON data, return as a dataframe.'''try: f = open(cache_path,'rb')df=pickle.load(f)print('Loaded {} from cache'.format(json_url))except(OSError,IOError) as e:print('Downloading {}'.format(json_url))df=pd.read_json(json_url)df.to_pickle(cache_path)print('Cached {} at {}'.format(json_url,cache_path))return df然后,我们定义一个新的函数,该函数将产生Poloniex API的HTTP请求,并调用刚刚定义的get_json_data函数,以保存调用的数据结果。
base_polo_url='https://poloniex.com/public?command=returnChartData¤cyPair={}&start={}&end={}&period={}'start_date=datetime.strptime('2015-01-01','%Y-%m-%d')# get data from the start of 2015end_date=datetime.now()# up until todaypediod=86400# pull daily data (86,400 seconds per day)def get_crypto_data(poloniex_pair):'''Retrieve cryptocurrency data from poloniex'''json_url=base_polo_url.format(poloniex_pair,start_date.timestamp(),end_date.timestamp(),pediod)data_df=get_json_data(json_url,poloniex_pair)data_df=data_df.set_index('date')return data_df上述函数将抽取加密货币配对字符代码(比如“BTC_ETH”),并返回包含两种货币历史兑换汇率的数据框。
步骤3.2 从Poloniex下载交易数据
绝大多数山寨币都无法使用美元直接购买,个人要想获取这些电子货币,通常都得先买比特币,再根据加密货币兑换汇率,兑换成山寨币。因而,我们就得下载每一种加密货币兑换比特币的兑换汇率,然后再使用现有比特币价格数据转换成美元。
我们会下载9种排名靠前的加密货币交易数据:Ethereum,Litecoin,Ripple,Ethereum Classic,Stellar,Dash,Siacoin,Monero,和NEM。
altcoins=['ETH','LTC','XRP','ETC','STR','DASH','SC','XMR','XEM']altcoin_data={} for altcoin in altcoins:coinpair='BTC_{}'.format(altcoin)crypto_price_df=get_crypto_data(coinpair)altcoin_data[altcoin]=crypto_price_df现在,我们有了包含9个数据框的字典,每种都包含山寨币与比特币之间的历史日平均价格数据。
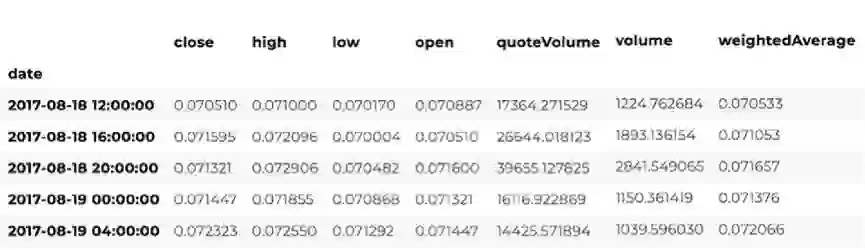
我们可以通过Ethereum价格表格的最后几行,来判定数据是否可用。
altcoin_data['ETH'].tail()
步骤3.3 – 统一货币单位:美元
现在,我们可以将BTC-山寨币汇率数据与我们的比特币价格指数结合,来直接计算每一个山寨币的历史价格(单位:美元)。
# Calculate USD Price as a new column in each altcoin dataframe for altcoin in altcoin_data.keys(): altcoin_data[altcoin]['price_usd'] = altcoin_data[altcoin]['weightedAverage'] * btc_usd_datasets['avg_btc_price_usd']此处,我们为每一个山寨币的数据框新增一列存储其相应的美元价格。
接着,我们可以重新使用之前定义的函数merge_dfs_on_column,来建立一个合并的数据框,整合每种电子货币的美元价格。
# Merge USD price of each altcoin into single dataframe combined_df = merge_dfs_on_column(list(altcoin_data.values()), list(altcoin_data.keys()), 'price_usd')就是如此简单!
现在让我们同时把比特币价格作为最后一栏添加到合并后的数据框中。
# Add BTC price to the dataframe combined_df['BTC'] = btc_usd_datasets['avg_btc_price_usd']现在我们有一个唯一的数据框,它包含了我们正在验证的十种电子货币的每日美元价格。
我们重新调用之前的函数df_scatter,以图表形式展现全部山寨币的相应价格。
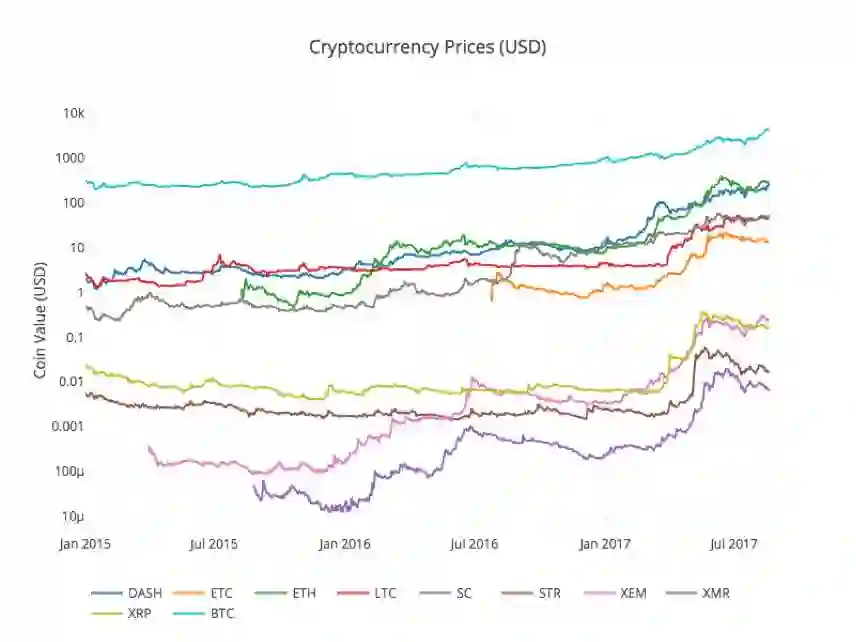
# Chart all of the altocoin prices df_scatter(combined_df, 'Cryptocurrency Prices (USD)', seperate_y_axis=False, y_axis_label='Coin Value (USD)', scale='log')
看起来不错!这张图为我们展现了每一种货币兑换汇率在过去几年的变化情况的一个全貌。
在这里我们使用了对数规格的y轴,在同一绘图上比较所有货币。你也可以尝试其他不同的参数值(例如scale='linear'),可以从不同视角理解数据。
步骤3.4- 执行相关性分析
你可能注意到电子货币的汇率看上去似乎是相关的,尽管他们的货币价值相差很大,而且波动性很高。尤其是从2017年4月的迅猛上涨开始,甚至很多的小波动似乎都与整个市场的波动同步出现。
当然,有数据支撑的结论比依据图像而产生的直觉更有说服力。
我们可以利用Pandas corr()函数来验证上述的相关性假设。该检验手段为数据框的每一栏计算了其对应另一栏的皮尔森相关系数。
8/22/2017修订说明-这部分的修改是为了在计算相关系数时使用每日回报率而不是价格的绝对值。
基于一个非稳态时间序列(例如原始的价格数据)直接计算可能会导致相关性系数的偏差。针对此问题,我们的解决方案是使用pct_change()方法,将数据框中的每一个的价格绝对值转化为相应的日回报率。
首先,我们来计算2016年的相关系数。
# Calculate the pearson correlation coefficients for cryptocurrencies in 2016 combined_df_2016 = combined_df[combined_df.index.year == 2016] combined_df_2016.pct_change().corr(method='pearson')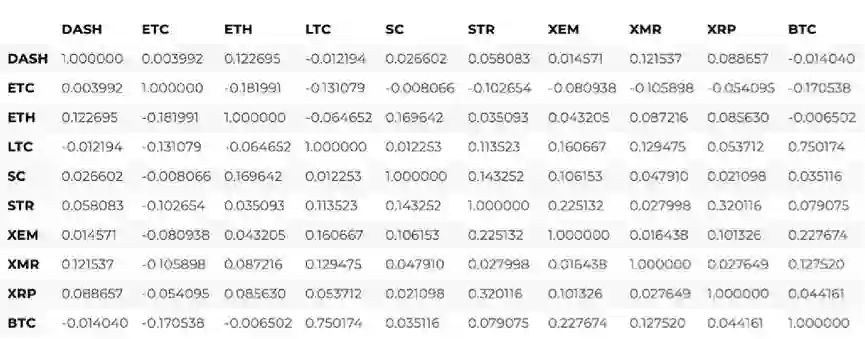
上面这张图显示的都是相关系数。系数接近1或-1,分别意味着这一序列是强正相关的,或逆相关的,相关系数趋近于0则说明相应对象并不相关,他们的波动是相互独立的。
为了更可视化的展示结果,我们创建了一个新的可视化的帮助函数。
def correlation_heatmap(df, title, absolute_bounds=True): '''Plot a correlation heatmap for the entire dataframe''' heatmap = go.Heatmap( z=df.corr(method='pearson').as_matrix(), x=df.columns, y=df.columns, colorbar=dict(title='Pearson Coefficient'), ) layout = go.Layout(title=title) if absolute_bounds: heatmap['zmax'] = 1.0 heatmap['zmin'] = -1.0 fig = go.Figure(data=[heatmap], layout=layout) py.iplot(fig) correlation_heatmap(combined_df_2016.pct_change(), "Cryptocurrency Correlations in 2016")

图示为2016年的电子货币相关系数
此处,深红色的数值代表强相关性(每一种货币显然是与其自身高度相关的),深蓝色的数值表示强逆相关性。所有介于中间的颜色-浅蓝/橙/灰/茶色-其数值代表不同程度的弱相关或不相关。
这张图表说明了什么呢?关键在于,它说明了不同的数字加密货币价格在2016年间的波动情况,几乎没有统计上的显著相关性。
现在,为了验证我们的假设-电子货币在近几个月的相关性增强,接下来,我们将使用从2017年开始的数据来重复同样的测试。
combined_df_2017 = combined_df[combined_df.index.year == 2017] combined_df_2017.pct_change().corr(method='pearson')
上图似乎显示了更强的相关性。但这些数据可以单独作为投资决策的依据吗?答案是否定的。
然而值得注意得是,在这张图上几乎所有的电子货币相互之间都变得相关性更强了。
correlation_heatmap(combined_df_2017.pct_change(), "Cryptocurrency Correlations in 2017")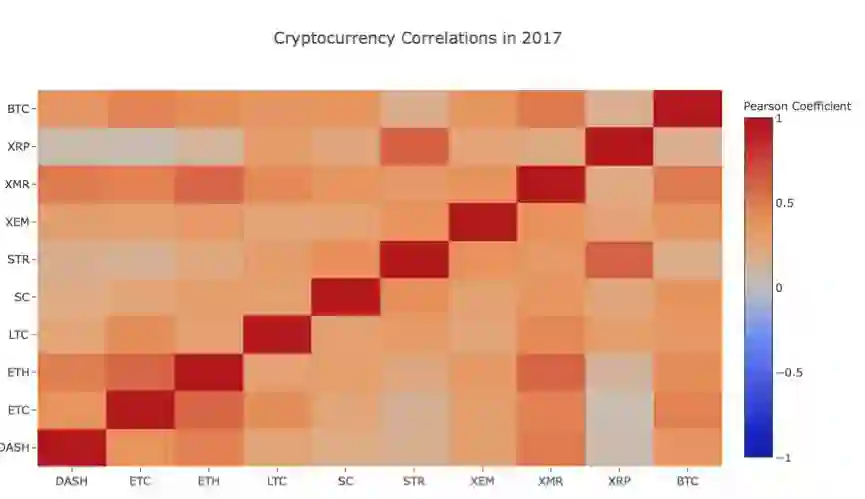
图:2017年的电子货币相关性
这是不是相当有趣呢!?
为什么?
好问题!其实,我也不是很确定。。。
我的第一反应是,对冲基金最近开始公开在电子货币市场交易[1][2]。这些基金持有远超于普通交易人的大量资本,当一支基金如果在多种加密货币间对冲自己的投入资本,然后根据独立变量(比如说,股票市场)对每一种货币使用相似的交易策略。如果从这个角度来看,出现这种越来越强的相关性趋势是合理的。
更深度的理解XRP和STR
例如,从上图中可以很明显看出XRP(Ripple的代币)是与其他电子货币相关性最低的。但这里有一个值得注意的例外是STR(Stellar的代币,官方名字是"Lumens"),与XRP有强相关关系(相关系数:0.62)。
有趣的是,Stellar和Ripple是非常相似的金融科技平台,他们都旨在减少银行间跨国转账时的繁琐步骤。
可想而知,考虑到区块链服务使用代币的相似性,一些大玩家以及对冲基金可能会对他们在Stellar和Ripple上的投资使用相似的交易战略。这可能就是为什么XRP相比其他电子货币,与STR有更强相关性的原因。
快讯-我是Chipper的合作人之一。Chipper是一家使用Stella的非常早期的初创企业,旨在颠覆非洲的小额汇款行业。
现在,到你了!
然而,这一解释在很大程度上是推测性的,可能你会做的更好。基于我们已经奠定的基础,你有成百上千条不同的方法可以继续探索数据中蕴藏的故事。
可以考虑从以下思路入手:
为整个分析添加更多加密货币的数据
调整相关性分析的时间范围和颗粒度,以得到优化的或粗粒度的趋势视图。
从交易量或区块链数据挖掘集中寻找趋势。相较于原始的价格数据,如果你想预测未来价格波动,你可以更需要买/卖量的比率数据。
在股票、商品、法定货币上加入价格数据来决定他们当中哪一项与电子货币具有相关性(但是,别忘了那句老话“相关不蕴含因果”)
使用Event Registry, GDELT,以及Google Trends来量化围绕着特定电子货币的“热词”数量。
利用数据训练一个预测性机器学习模型,来预测明日价格。如果你有更大的雄心壮志,你甚至可以考虑尝试用循环神经网络(RNN)进行上述训练。
利用你的分析来创建一个自动化的交易机器人,通过对应的应用编程接口(API),应用在例如“Poloniex”或“Coinbase”的交易网站上。请小心:一个性能欠佳的机器人可以轻易地让你的资产瞬间灰飞烟灭。
关于比特币,以及对于加密货币总体而言,最好的部分是它们的去中心化本质,这使得它比任何其他资产都自由、民主。可以将你的分析开源共享,参与到社区中,或者写一篇博客!
希望你现在已经掌握了自行分析所需的技能,以及在未来读到任何投机性的加密货币的文章时,进行辩证思考的能力,尤其是那些没有数据支撑的预测。
感谢你的阅读,关于这一教程,如果你有任何看法、建议或批评指正,请在下方留言。如果你发现代码如果有问题,也可以点在Github仓库中新建一个问题(issue)。
http://fortune.com/2017/07/26/bitcoin-cryptocurrency-hedge-fund-sequoia-andreessen-horowitz-metastable/
https://www.forbes.com/sites/laurashin/2017/07/12/crypto-boom-15-new-hedge-funds-want-in-on-84000-returns/#7946ab0d416a
原文链接:https://blog.patricktriest.com/analyzing-cryptocurrencies-python/

志愿者介绍
回复“志愿者”加入我们





往期精彩文章
点击图片阅读
强壮的男性 & 有想法的女性:分析34476个漫画角色,超级英雄中的性别透析






