文本嵌入的经典模型与最新进展(下载PDF)
来自 | AI研习社 作者 | WBLUE
词嵌入和句子嵌入已成为所有基于深度学习的自然语言处理(NLP)系统的重要组成部分。它们在定长的密集向量中编码单词和句子,以大幅度提高文本数据的处理性能。
下载方式
方式一
点击阅读原文
方式二
对话框回复“20180624”
对通用嵌入的追求是一大趋势:在大型语料库上预训练好的嵌入,可以插入各种下游任务模型(情感分析、分类、翻译等),通过融合一些在更大的数据集中学习得到的常用词句表示,自动提高它们的性能。
这是一种迁移学习。最近,迁移学习被证明可以大幅度提高 NLP 模型在重要任务(如文本分类)上的性能。Jeremy Howard 和 Sebastian Ruder (ULMFiT) 的工作就是一个最好的例子。(http://nlp.fast.ai/classification/2018/05/15/introducting-ulmfit.html)
虽然句子的无监督表示学习已经成为很长一段时间的规范,但最近几个月,随着 2017年末、 2018 年初提出了一些非常有趣的提议,无监督学习已经有转向有监督和多任务学习方案的趋势。
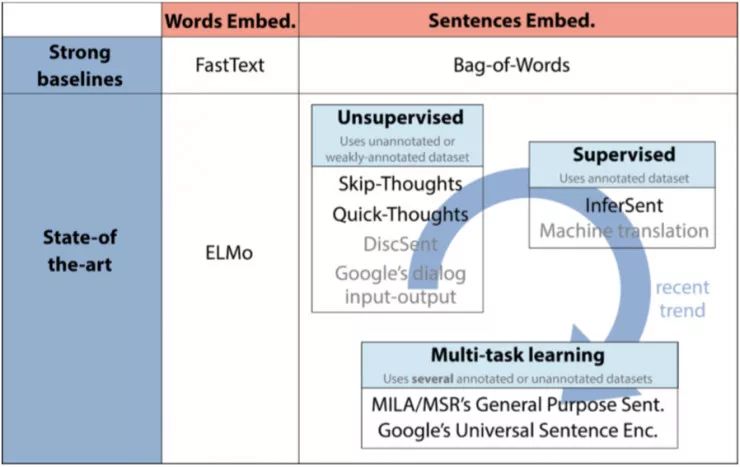
通用词/句子嵌入的最新趋势。 在这篇文章中,我们描述了用上图中黑体字的模型。
因此,这篇文章简要介绍了通用词和句子嵌入的最新技术:
强/快的基线模型:FastText,Bag-of-Words(词袋)
最先进的模型:ELMo,Skip-Thoughts,Quick-Thoughts,InferSent,MILA/ MSR 的通用句子表示和 Google 的通用句子编码器。
我们先从词嵌入开始。如果你想对 2017 年之前发生的事情有一些背景知识,我推荐你去看 Sebastian 去年写过的关于词嵌入的一篇很好的文章(http://ruder.io/word-embeddings-2017/)和入门介绍帖(http://ruder.io/word-embeddings-1/)。
词嵌入的最新发展
在过去的五年里,人们已经提出了大量可能的词嵌入方法。最常用的模型是 word2vec 和 GloVe,它们都是基于分布假设的无监督学习方法(在相同上下文中的单词往往具有相似的含义)。
虽然有些人通过结合语义或句法知识的有监督来增强这些无监督的方法,但纯粹的无监督方法在 2017-2018 中发展非常有趣,最著名的是 FastText(word2vec的扩展)和 ELMo(最先进的上下文词向量)。
FastText (https://github.com/facebookresearch/fastText)是 2013 年提出了 word2vec 框架的 Tomas Mikolov 团队开发的,这引发了关于通用词嵌入研究的爆炸式增长。FastText 对原始 word2vec 向量的主要改进是包含了字符 n-gram,它允许为没有出现在训练数据中的单词计算单词表示。
FastText 向量训练速度超快,可在 157 种语言的 Wikipedia 和 Crawl 训练中使用。这是一个很好的基线模型。
深度语境化的单词表示 (ELMo,http://allennlp.org/elmo) 最近大幅提高了词嵌入的顶级水平。它由 Allen 研究所开发,将于 6 月初在 NAACL 2018 会议上发布。

ELMo对上下文语境了解很多
在ELMo 中,每个单词被赋予一个表示,它是它们所属的整个语料库句子的函数。所述的嵌入来自于计算一个两层双向语言模型(LM)的内部状态,因此得名「ELMo」:Embeddings from Language Models。
ELMo的 特点:
ELMo 的输入是字母而不是单词。因此,他们可以利用子字词单元来计算有意义的表示,即使对于词典外的词(如 FastText 这个词)也是如此。
ELMo 是 biLMs 几层激活的串联。语言模型的不同层对单词上的不同类型的信息进行编码(如在双向LSTM神经网络中,词性标注在较低层编码好,而词义消歧义用上层编码更好)。连接所有层可以自由组合各种文字表示,以提高下游任务的性能。
现在,让我们谈谈通用句子嵌入。
通用句子嵌入的兴起

目前有很多有竞争力的学习句子嵌入的方案。尽管像平均词嵌入这样的简单基线始终效果不错,但一些新颖的无监督和监督方法以及多任务学习方案已于 2017 年末至 2018 年初出现,并且引起了有趣的改进。
让我们快速浏览目前研究的四种方法:从简单的词向量平均基线到无监督/监督方法和多任务学习方案。
在这一领域有一个普遍的共识,即直接平均一个句子的词向量(即所谓的「词袋」方法)的简单方法为许多下游任务提供了一个强大的基线。
Arora 等人的工作详细介绍了计算这种基线的一个很好的算法。去年在 ICLR 上发表了一个简单但有效的句子嵌入基线 https://openreview.net/forum?id=SyK00v5xx:使用你选择的热门词嵌入,在线性加权组合中对一个句子进行编码,并执行一个通用组件移除(移除它们的第一主成分上的向量)。这种通用的方法具有更深入而强大的理论动机,它依赖于一个使用语篇向量上的生成模型的随机游走来生成文本。(在这里我们不讨论理论细节)
最近一个强大的 Bag-of-Word 基线(甚至比 Arora 的基线更强)的实现是来自达姆施塔特大学的串联 p-mean 嵌入,它的地址是 https://github.com/UKPLab/arxiv2018-xling-sentence-embeddings。

HuggingFace 的对话框袋的字。 Bag-of-Words 接近宽松的单词排序,但保留了惊人数量的语义和句法内容。
来源:Conneau 有趣的 ACL 2018 论文 http://arxiv.org/abs/1805.01070。
除了简单的平均,第一个主要的建议是使用无监督的训练目标,从 Jamie Kiros 和他的同事在 2015 年提出的 Skip-thoughts 向量开始。
无监督方案将句子嵌入学习作为学习的副产品,以预测句子内连贯的句子顺序或句子中连贯的连续从句。这些方法可以(理论上)使用任何文本数据集,只要它包含以连贯方式并列的句子/子句。
Skip-thoughts 向量(https://arxiv.org/abs/1506.06726)是学习无监督句子嵌入的典型例子。它可以作为为词嵌入而开发的 skip-gram 模型的句子等价物:我们试着预测一个句子的周围句子,而不是预测单词周围的单词。该模型由基于 RNN 的编码器 – 解码器组成,该解码器被训练用于重构当前句子周围的句子。
Skip-Thought 论文中有一个有趣的见解是词汇扩展方案:Kiros 等人在训练过程中,通过在 RNN 词嵌入空间和一个更大的词嵌入(如word2vec)之间进行线性变换,来处理未见过的单词。
Quick-thoughts 向量(https://openreview.net/forum?id=rJvJXZb0W)是今年在 ICLR 上发布的 Skip-thoughts 向量的最新发展。在这项工作中,预测下一句话的任务被重新定义为一个分类任务:解码器被一个分类器所取代,该分类器必须在一组候选者中选择下一句。它可以被解释为对生成问题的一种判别近似。
该模型的一个优势是其训练速度(与 Skip-thoughts 模型相比有数量级的提升)使其成为开发大量数据集的有竞争力的解决方案。
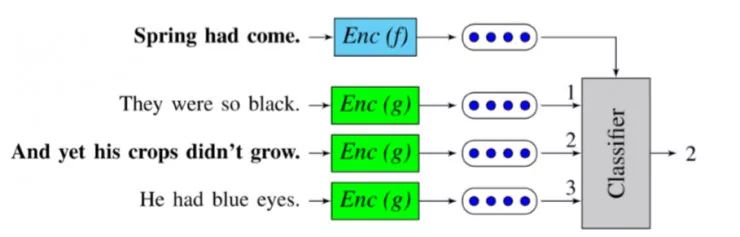
Quick-thoughts分类任务, 分类器必须从一组句子嵌入中选择以下句子
来源:Logeswaran等人的「学习语句表达的有效框架」
在很长一段时间里,监督学习句子嵌入被认为是比无监督的方法提供更低质量的嵌入,但是这个假设最近被推翻,部分是在推论结果的发布之后。
与之前详述的无监督方法不同,监督学习需要标注数据集来标注某些任务,如自然语言推理(如一对限定句)或机器翻译(如一对译句),构成特定的任务选择的问题和相关问题的数据集的大小需要质量好的嵌入。在讨论这个问题之前,让我们看看 2017 年发布的突破 InferSent 的背后是什么。
因其简单的体系结构,InferSent (https://arxiv.org/abs/1705.02364)是一个有趣的方法。它使用句子自然语言推理数据集(一组 570k 句子对标有3个类别:中性,矛盾和隐含)来在句子编码器之上训练分类器。两个句子都使用相同的编码器进行编码,而分类器则是根据两个句子嵌入构建的一对表示进行训练。Conneau 等人采用双向 LSTM 完成最大池化的操作器作为句子编码器。
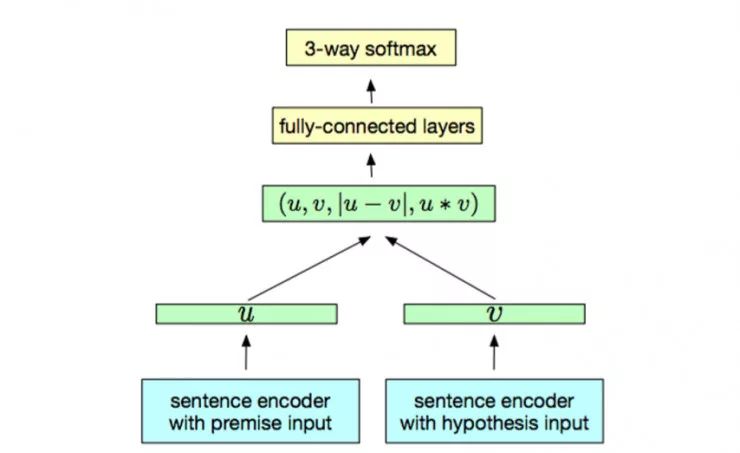
从NLI数据集中学习的监督句子嵌入模型(InferSent)
资料来源:A. Conneau等人的「自然语言推理数据中通用句子表示的监督学习」
除了通常的寻找最佳神经网络模型的探索之外,InferSent 的成功还提出了以下问题:
什么样的监督训练任务能获得更好泛化到下游任务中的句子嵌入?
多任务学习 可以看作是 Skip-Thoughts,InferSent 和相关的无监督/监督学习方案的泛化,它通过试图在训练方案中结合几个训练目标来回答这个问题。
最近几个关于多任务学习的提议于2018年初发布。让我们简要的看一下 MILA / MSR 的通用句子表示和Google 的通用句子编码器。
在 MILA 和 Microsoft Montreal 的 ICLR 2018 论文(Learning General Purpose Distributed Sentence Representation via Large Scale Multi-Task Learning,https://arxiv.org/abs/1804.00079)中,Subramanian 等人观察到,为了能够泛化到各种不同的任务中,对同一句子的多个方面进行编码是必要的。
因此,作者利用一对多的多任务学习框架,通过在多个任务之间切换来学习通用句子嵌入。选择的 6 个任务(Skip-thoughts 模型预测上下文、神经网络机器翻译、句法分析和自然语言推理)共享了由双向 GRU 获得的相同的句子嵌入。实验表明,当添加多语言神经机器翻译任务时,可以更好地学习语法属性,通过解析任务学习长度和词序并且训练自然语言推断编码语法信息。
Google 的通用句子编码器(https://arxiv.org/abs/1803.11175),于2018年初发布,采用相同的方法。他们的编码器使用一个转换网络,该网络经过各种数据源和各种任务的训练,目的是动态地适应各种自然语言理解任务。他们也给 TensorFlow 提供了一个预训练的版本 https://www.tensorflow.org/hub/modules/google/universal-sentence-encoder/1。
总结
以上就是我们对于通用词嵌入和句子嵌入现状的简短总结。



