上海大学建了一个“突发事件语料库”,包括地震、恐怖袭击等5大类

作者 | 阿司匹林
出品 | 人工智能头条(公众号ID:AI_Thinker)
本体最初是一个哲学上的概念,十多年前被引入计算机领域中作为知识表示的方法并被广泛使用。本体对于探索人的认知原理、发展自然语言理解技术和人机交互技术有重要意义。
要理解这些话语文本, 就必须知道这些事件类丰富的内容, 这些内容的绝大部分是不可能在话语文本中叙述的, 而是作为共同知识预先存在于每个交流者的头脑中。事件本体正是为计算机建造这样的共同知识。
研究本体,必然要先构建语料库。
几年前,上海大学语义智能实验室为了开展文本事件抽取和事件关系的抽取实验,创建了中文突发事件语料库(Chinese Emergency Corpus,CEC)。
GitHub 地址:
https://github.com/shijiebei2009/CEC-Corpus
根据国务院颁布的《国家突发公共事件总体应急预案》的分类体系,上海大学语义智能实验室从互联网上收集了 5 类(地震、火灾、交通事故、恐怖袭击和食物中毒)突发事件的新闻报道作为生语料,然后再对生语料进行文本预处理、文本分析、事件标注以及一致性检查等处理,最后将标注结果保存到语料库中,CEC 合计 332 篇。
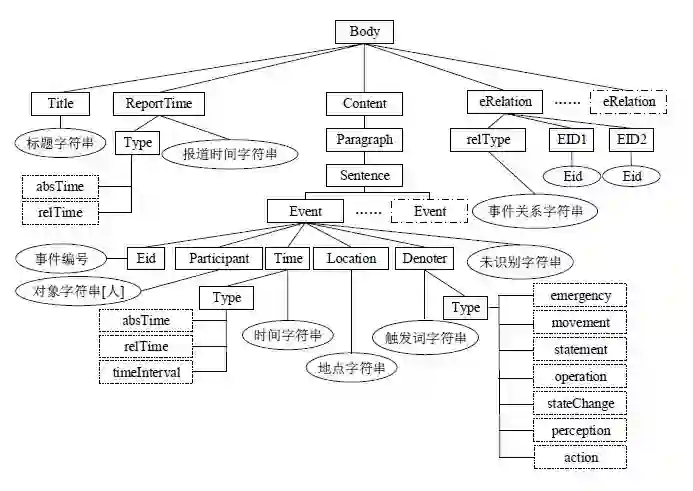
CEC 采用了 XML 语言作为标注格式,其中包含了六个最重要的数据结构(标记):Event、Denoter、Time、Location、Participant 和 Object。Event用于描述事件;Denoter、Time、Location、Participant 和 Object 用于描述事件的指示词和要素。此外,我们还为每一个标记定义了与之相关的属性。与 ACE 和 TimeBank 语料库相比,CEC 语料库的规模虽然偏小,但是对事件和事件要素的标注却最为全面。
据介绍,这个语料库是包括刘炜(上海大学计算机学院副研究员)、王旭(上海大学硕士研究生,已毕业)等在内的课题组师生,多年手工标注并不断打磨的成果。
不过,这个项目在 GitHub 上的最后更新时间是 2015 年。为了了解 CEC 的最新进展,营长联系上了项目组成员之一:上海大学计算机学院副研究员——刘炜。
1)CEC 项目目前有什么最新进展?
刘炜:近期没有更新,目前我们的工作主要在事件本体构建平台的开发,后面我们可能会针对事件本体构建的新需求以及我们这两年的工作积累再新增一些事件语料。
2)这个项目的出发点是什么?主要有什么用途?
刘炜:主要是用于之前我们开展的文本事件抽取和事件关系的抽取实验用。事件本体就是一个由事件类构成的用来描述事件知识的表示模型。事件类也叫事件概念,在事件本体中,事件类之间会存在一些语义关系。比如我们构建的地震事件本体,它会有地震、抢险、救援、医疗救助、灾害评估、赈灾等一系列事件类,同时这些事件类之间会存在因果、并发、顺序等语义关系。
另外,我们想用这些语料验证我们提出的事件六要素(人物,动作,地点,时间,状态,语言描述)表示模型,为一些研究人员研究文本事件处理算法提供实验数据。
3)能介绍下“事件本体构建平台”吗?
刘炜:事件本体构建平台就是一个建模工具,用来建立事件本体模型,这个模型有点像 UML 模型。我们做成了一个基于 Web 的,可支持协同建模的平台工具。它和语料库没有直接的关系,但都是我们研究事件本体的重要工作部分。
参考资料:
https://blog.csdn.net/shijiebei2009/article/details/44538257——王旭
题图来自上海大学官网
扫描二维码,关注「人工智能头条」
回复“技术路线图”获取 AI 技术人才成长路线图

☟☟☟点击查看 | 哈工大成立人工智能研究院 |



