

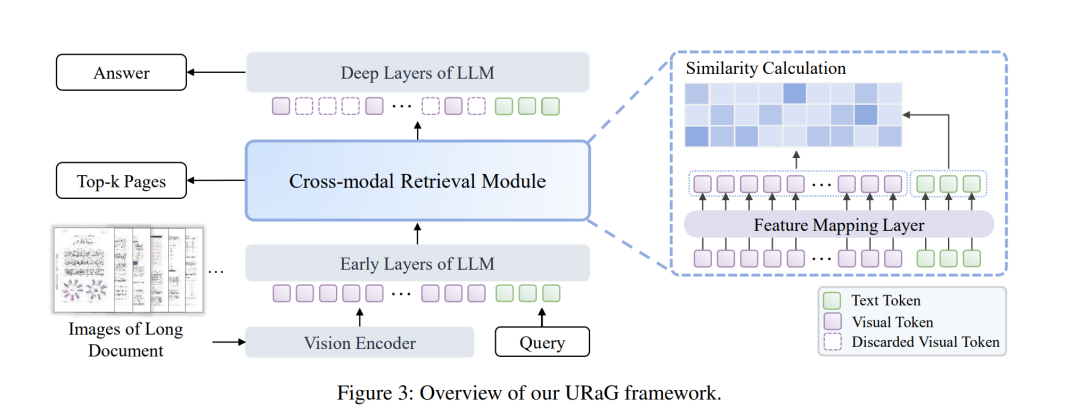
当前的多模态大语言模型在处理长文档理解任务时,仍面临两大根本性挑战:海量无关内容造成的信息干扰,以及基于Transformer架构的二次计算复杂度。现有方法主要分为两类:通过令牌压缩牺牲细节粒度的方法,以及引入外部检索器导致系统复杂性增加且无法端到端优化的方案。 为突破这些限制,我们通过深入分析发现:MLLMs呈现出类人的从粗到细推理模式——早期Transformer层广泛关注文档整体内容,而深层网络则聚焦于相关证据页面。基于这一发现,我们提出可以显式利用MLLMs固有的证据定位能力,在推理过程中执行检索操作,从而实现高效的长文档理解。 为此,我们提出了URaG——一个简单而有效的统一检索生成框架。该框架通过引入轻量级跨模态检索模块,将早期Transformer层转换为高效证据选择器,能够精准识别并保留最相关页面,同时过滤无关内容。这种设计使得深层网络可以集中计算资源处理关键信息,在提升准确性的同时优化计算效率。大量实验表明,URaG在实现最优性能的同时,显著降低了44%-56%的计算开销。 代码已开源:https://github.com/shi-yx/URaG
成为VIP会员查看完整内容
相关内容
Arxiv
222+阅读 · 2023年4月7日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
222+阅读 · 2023年4月7日