

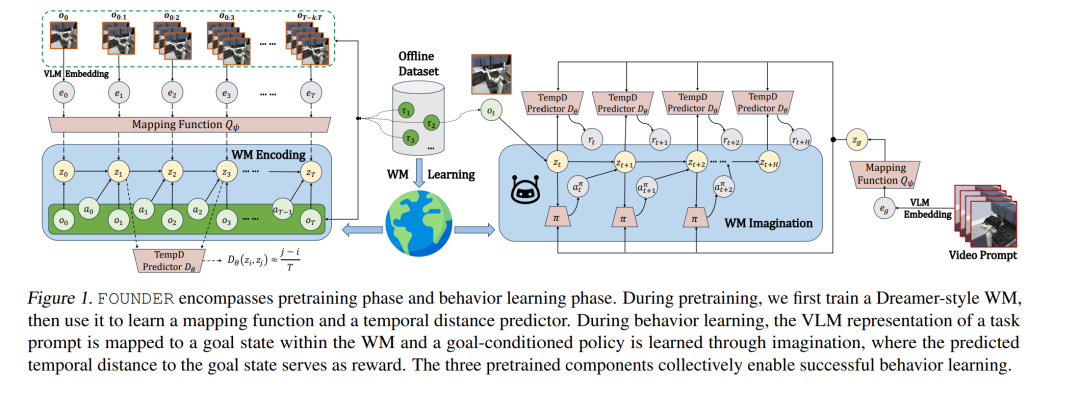
基础模型(Foundation Models, FMs)与世界模型(World Models, WMs)在任务泛化方面各具优势,分别作用于不同的抽象层级。在本文中,我们提出了一个新框架——FOUNDER,它融合了 FMs 所蕴含的可泛化知识与 WMs 的动态建模能力,从而在无奖励信号(reward-free)的具身环境中实现开放式任务求解。 我们的方法通过学习一个映射函数,将 FM 表征“对齐”到 WM 的状态空间,有效地根据外部观测推理出智能体在世界模拟器中的物理状态。通过该映射,系统可在行为学习阶段基于想象(imagination)训练出一个基于目标的策略(goal-conditioned policy),其中映射后的任务信息作为目标状态。 我们利用到目标状态的预测时间距离作为一种有信息量的奖励信号,辅助策略学习。在多个多任务的离线视觉控制基准测试中,FOUNDER 展现出优越的性能,尤其在任务由文本或视频指定、环境观测复杂或存在跨领域差异的情况下,显著优于现有方法,能够更准确地捕捉任务的深层语义。 我们还通过实证分析验证了 FOUNDER 学到的奖励函数与真实奖励之间的一致性。 项目主页:https://sites.google.com/view/founder-rl
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日
Arxiv
145+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日
Arxiv
145+阅读 · 2023年3月29日