
原创作者:郑欢洋 牛天昊 方恒杰 董轩 指导老师:车万翔 朱庆福 转载须标注出处:哈工大SCIR 在调研总结过程中,本文参考了 A Survey on Vision-Language-Action Models: An Action Tokenization Perspective[1]中的“动作标记化”分类体系,对作者团队深表感谢。
1. 简介
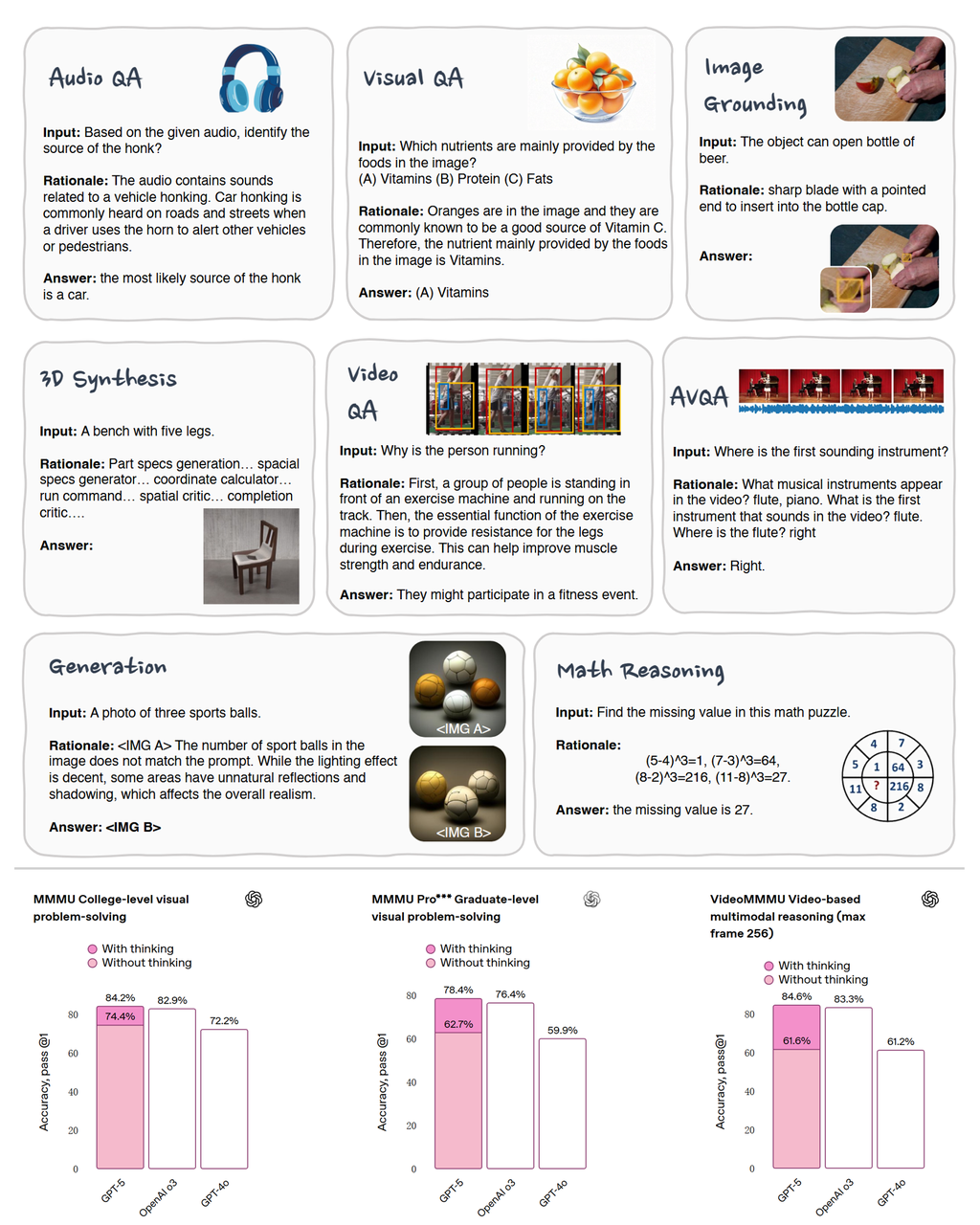
图1: 思维链(CoT)在各领域的应用及其效果示例[38][39] 思维链(Chain-of-Thought, CoT)是一种在推理过程中不直接输出最终结果,而是显式生成中间推理步骤的推理范式。该推理过程可以采取多种形式,包括但不限于纯文本、图像以及隐藏表示等。CoT推理在下游任务上的显著成功推动了其在学术界和工业界的广泛研究与应用。OpenAI o1/o3、Deepseek R1等前沿系统的进展更是引起了对思维链技术的热烈关注与讨论。在多模态测试基准上的测试结果也说明思维链在多模态领域中有较强潜力(如图1下所示)。 图2: 思维链在具身任务中的应用示例[2]依照CCF术语的标准定义,具身智能是指一种基于物理身体进行感知和行动的智能系统,其通过智能体与环境的交互获取信息、理解问题、做出决策并实现行动,从而产生智能行为和适应性。本文将上述定义中与环境进行交互的智能体称为具身智能体。直观上,具身智能体同样可以从显式推理过程中获益。例如,当人类接收到指令 “Pick up a carrot” 并感知到当前环境时,通常会在脑海中先“想象”完成指令后的目标场景,再据此执行动作。如图2所示,CoT-VLA工作[2]利用这一特性,利用视觉-语言-动作模型(VLA)作为具身智能体的"大脑",在得到指令和观测后,先想象出抓取胡萝卜后的目标状态,然后再输出具体动作并控制机械臂完成目标操作,实验证明这种方法能极大提升任务成功率。基于上述结论,越来越多的研究开始将CoT应用于具身智能领域。本文对该方向的研究进行了系统性的调研与综述。本文总结的具身CoT方法为:在执行推理过程中不直接输出最终结果,而是至少显式推理生成一种中间表征,再据此推导并输出最终结果的方法。涉及的工作涵盖具身智能的多个研究领域,包括具身规划、具身问答、视觉语言导航(VLN)和视觉-语言-动作模型(VLA)等。
图3: 具身CoT笔记架构图 如图3所示,本文从推理中间表征设计层面、训练层面与推理过程优化层面三个维度,对近期具身CoT相关研究进行了梳理与分析。除此之外,本文对现有具身CoT相关资源进行了系统整理。 对于推理中间表征设计层面,本文对当前具身CoT研究中采用的不同中间表征形式进行了分类。对于每一种中间表征,首先介绍相关研究工作(包括单独使用该表征的研究以及与其他表征联合使用的研究),随后总结该表征所依赖的数据资源及其构建方式,并进一步分析该表征的优缺点。在整理过程中,我们参考了A Survey on Vision-Language-Action Models: An Action Tokenization Perspective [1]中的“动作标记化”分类体系,对作者团队在具身智能研究整理与体系构建上的启发深表感谢。 对于训练层面,本文重点介绍了当前提升具身CoT性能的两类主流算法——模仿学习与强化学习。我们从训练目标与训练策略两个方面对两种算法进行系统总结,并分析其优缺点。 对推理优化层面,本文重点关注除从推理中间表征设计之外,如何进一步优化具身CoT的推理过程以提升推理效率与最终性能表现。 本文希望通过对具身CoT工作的系统梳理,提供一个全面的总结,帮助研究者更高效地理解具身CoT的近期研究进展。
2. 从推理中间表征设计层面提升
具身智能中的CoT具有不同的表征形式,他们具有各自的独特优势。本节本文借鉴 A Survey on Vision-Language-Action Models: An Action Tokenization Perspective 中的“动作标记化”分类体系,从不同中间表示层面对具身CoT工作展开总结。 2.1 纯自然语言(Natural Language) 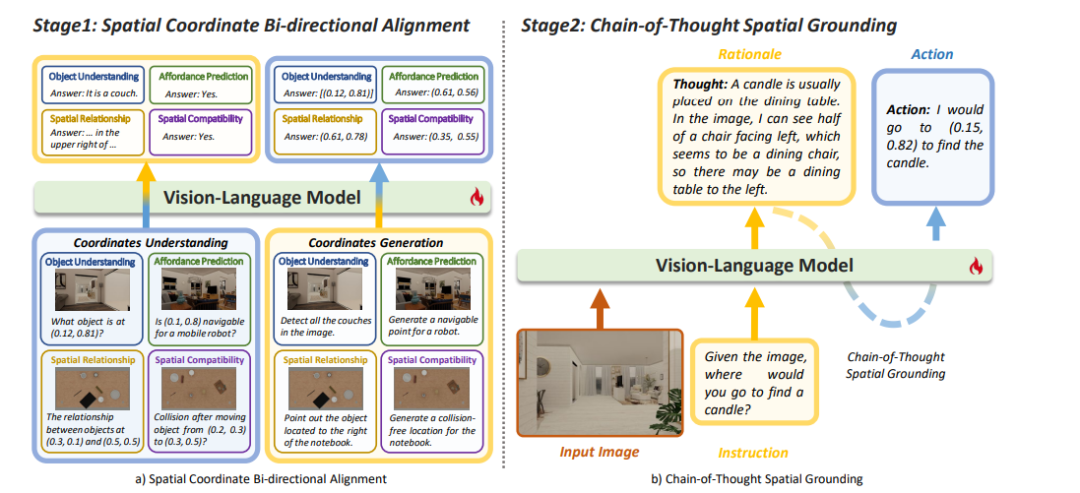
**自由文本长链 CoT:**以可读的自然语言“推理链”串联观察、因果与计划,强调第一人称视角与时序连贯性;其目标是在执行前先把“看到了什么、为什么、接下来做什么”写清楚,从而获得可解释、可编辑、可交互的高层决策依据。EgoThinker[4]用第一人称、时空绑定的长链文字推理,链条通常包含“我当前看到什么→关键物体/手部交互→时间因果→下一步意图”,并在链中显式提及观察到的证据(如手的出现、物体运动),最后给出决策/答案。其核心是让叙述天然地站在“我”的视角,明确时间线与因果线。Robix[5]把 CoT 写成可对话、可中断的计划叙事:先用短句总结场景要点与目标,再列出可选方案与取舍理由,必要时插入澄清/询问语句,随后给出当前执行子计划;一旦环境或人类干预改变,CoT 会插入重规划说明并继续推进。核心是把“推理—交流—执行”的状态转换都体现在文字链里。**综上所述,**该类方法共同以长链文本承载高层推理与交互,具有强可解释、易审阅、易编辑性质,在面向长时规划与动态人机协同时尤为有效。自由文本CoT的实际落地可与结构化模板或坐标/潜在表示结合,以平衡可解释性与执行效率。 * **结构化 CoT模板: **用受约束的模板或槽位把“想法→动作”写成短、稳、可机检的文字链(如
数据
相关数据集介绍:这类数据以纯自然语言作为中间表示,共同范式是:用感知(自我视角 RGB/RGB-D/历史)与指令作为输入,先有文本化的 CoT/高层计划(可结构化为“地标+方向”或
优缺点
优点
**可解释、可编辑、易合成:**因为中间表示是自然语言,便于人工审阅与修改,且可用模板/LLM大规模自动生成标注与过程链。 * **跨任务迁移强(语言层抽象):**因为不绑定特定坐标系或传感器格式,规则与模板可在导航、操控、问答等任务间复用。 * **推理速度快(文本生成):**因为只需生成短句模板,无需额外渲染/仿真或扩散/流匹配解码,计算链更短。
缺点
物理落地弱于坐标/latent、易冗长与幻觉:因为纯文字不显式编码动力学/可达性约束,易生成“说得通但做不到”的步骤,且语言模型有填充冗词倾向。 * **纯感知型任务上过度 CoT 可能降效降准:**因为多余的语言步骤占用计算与上下文预算,弱化了直接判别/回归模型在检测与定位上的天然优势。
2.2 代码/结构化思维(Code/Structured Thinking)
图5:使用代码或结构化思维中间表示的代表性工作UML-CoT[10] * **介绍:**在具身CoT中,“代码/结构化思维”(Code/Structured Thinking)指以形式化语言或结构化符号(而非自由自然语言)来表示中间推理过程的方式。其核心思想是:让模型在思考链中输出可解析、可执行的结构(如代码或领域特定语言),从而减少歧义、增强可验证性。与自由文本式推理相比,这种形式化中间表示可将抽象推理转化为机器可读逻辑结构,使得推理链既能被人理解,又能被程序检验或直接执行。 * **方法:**为提升推理的准确性与可解释性,近期工作探索了多种结构化推理。此外,亦有工作探索将其与其他思维方式融合。
**仅使用代码/结构化数据为中间表征:**不同研究探索了不同的结构化和形式化表达方式。**第一类工作是代码或伪代码推理,**这类工作采用类似编程的结构(如循环、条件语句和函数调用等), 通过模拟任务的执行过程,来进行推理。HyCodePolicy[11]通过生成可执行的符号化程序代码实现具身任务的结构化推理,并利用多模态监控与迭代式代码修复机制动态修正执行错误。**第二类工作是形式语言推理:**NaviWM[12]引入了基于Gentzen自然演绎树的演绎推理链,将社会导航任务建模为多步逻辑推理过程,通过层次化的逻辑命题(如活动感知、距离感知、碰撞避免、时间约束)来引导LLM生成可验证的导航决策。这种方法将复杂的多变量优化问题转化为结构化的逻辑步骤,显著提升了推理的严谨性与可解释性。SafePlan[13]的不变式CoT推理器利用线性时序逻辑(LTL)形式化安全属性,通过状态转换模型系统验证任务执行过程中的不变式,并结合逻辑框架与同义词处理机制,确保任务规划的语义与逻辑一致性,从而在代码生成与执行前拦截不安全任务。除此之外,UML-CoT[13]通过使用统一建模语言(UML)表示推理过程(图4: 以 UML code 为载体的CoT)。SCoT[3]为了解决解决传统CoT在3D场景中“语言合理但场景无依据”的幻觉问题,提出了在CoT生成过程中,强制模型在每一步推理中显式标记引用的场景信息(如物体属性、空间关系、布局等)。**综上所述,**这些结构化的CoT表达方式通过引入代码结构、逻辑符号与建模语言,使得语言模型的推理过程从自由文本走向可验证的结构化逻辑推理,显著增强了模型的可控性与可解释性 * **与其他中间表征结合:**除了基于结构化思维的形式化推理外,一些研究还将其他类型的思维方式与结构化思维结合,以扩展推理的表现力和应用范围。例如,心灵宫殿探索(Mind Palace Exploration)[14]方法,除了使用结构化图形表示和自然语言推理外,还将空间化的记忆检索和时空推理结合在一起。这种方法在结构化思维的基础上引入了长期记忆的管理与探索过程,使得机器人能够在处理长期任务时,不仅依赖即时的环境感知,还能够利用历史经验进行有效的推理和决策。通过这种方式,结构化思维不仅限于符号化的推理,还融合了对环境的动态感知和时间演变的考虑,从而增强了推理过程的灵活性和适应性。 * 数据
**相关数据集介绍:**使用代码作为中间表征比较有代表性的4个数据集是SCoT、IntentGrasp[15]、MRoom-30k[10]和SafePlan Benchmark[13]。SCoT作为百万规模的3D推理数据集,其输入包含3D场景图、鸟瞰图和多视角图像,输出则根据不同任务层级分为:空间感知任务直接输出属性答案,空间分析与规划任务输出带有场景引用标签
优缺点
优点
精确度高:通过形式化语言减少歧义,如NaviWM使用逻辑约束、GraspCoT分层推理。 * **可验证性强:**结构化输出支持自动验证,如SafePlan使用不变式推理器多次验证代码安全性。
缺点
训练复杂:需大量标注与多阶段训练,如SafePlan依赖复杂逻辑设计。 * 灵活性差:固定模板难以适应新场景,如GraspCoT对未知物体指令响应有限。 * 理解门槛高:结构化输出(如图表、代码)对非专业用户不够直观,如NaviWM逻辑树难以理解。
2.3 可供性(Affordance)
**
边界框(Bounding Box,图6左1):边界框是最经典的Affordance表达方式,代表性工作如ECoT[16]。通过预测物体在视野中的边界框位置,模型能辅助具身智能体完成“视觉接地”,明确可操作目标,从而推理出合理的后续动作。 * 关键点(Keypoint,图6左2):关键点以“点”而非“区域”描述可操作位置。以KITE[17]为代表的模型,会在完成视觉感知后定位一组语义关键点(如“把手中心”“旋钮边缘”),据此指导精准抓取或旋转。这类方法尤其适用于高精度操作任务,如插拔、按钮、对准等。 * 极坐标(Polar Coordinate,图6左3):TrackVLA++[18] 引入极坐标系,将周围环境划分为扇区网格,并用角度与距离唯一标定空间位置。这种方式在多相机场景中优势突出,能够保持跨视角空间一致性,避免边界框方法易出现的歧义问题。 * 分割掩码(Segmentation Mask,图6左4):分割掩码通过不同颜色的像素来精确划分特定物体或区域。代表性工作如 ROCKET-1[19],利用分割掩码区分物体的功能区(如“可抓取面”“可切割边缘”)与非功能区,从而显著增强模型对柔性体与复杂表面的理解。适用于擦拭、折叠、液体倒入等动态操作任务。 * 可供性图(Affordance Map,图6左5):以VoxPoser[20]为代表的工作使用可供性图来采样动作。可供性图为图像中的每个像素分配一个得分,用以衡量该位置对特定动作的适应度。与分割掩码不同,Affordance Map不仅提供“能/不能”的二值判断,还能表示“可操作性强度”。它在视觉输入与动作推理之间建立密集映射,既保留空间连续性,又能与语言指令融合。 * **与其他中间表征结合:**在实际应用中,Affordance经常与其他中间表示共同使用,为需要进行空间感知与决策的广泛智能体提供空间推理指引。最常见的结合形式是与Language Plan与Trajectory结合使用,作为子任务——动作两个层级的中间表示,为模型的进一步推理动作提供视觉接地。例如MolmoAct[21]、VLA-R1[22]等工作均在生成NL格式的子任务后分别预测可供性与轨迹标签,之后根据标签提供的空间指引来解码动作;无需操作机械臂的PhysVLM-AVR[23]则仅使用了Language Plan和Affordance作为思维链表示,来推理应该在下一步选择的环境交互动作;在重视指令跟随的VLN任务中,VAMOS[24]选择了Affordance和Trajectory作为思维链表示,来为智能体规划连续、可执行的路径。 * 数据
**相关数据集介绍:**Affordance中比较典型的数据集包括YCB-Affordance[25]、AVR-152K[23]、VLA-CoT-13K[22]、EVT-Bench Training Set[26]等。Affordanc数据集的格式通常较简单,包括视频/图像以及对应的结构化注释(注释包括关键点、边界框、坐标系)等等。部分数据集(例如VLA-CoT-13K)除了上述的场景与标注之外,还包含思维链以反映推理出Affordance标签的过程。 * **数据构建方案:**按照数据构建方案,**其一是模型自动标注,**专用模型(如DINO)或大型视觉语言模型(如Qwen2.5-VL)能够为可供性任务提供自动化标注支持。ECoT、VLA-R1、PhysVLM-AVR等工作从现有机器人演示数据集中使用上述模型自动标注可供性标签,将其转变为可供性数据集,形成了AVR-152K、VLA-CoT-13K这样的数据集。这是标注Affordance数据集的最常见方法。**其二是手动标注,**即对复杂场景选择手动数据集注释。例如YCB-Affordance对于“手部抓握”这一场景,人工注释了手部位置、手部姿势和抓握类型。由于现有人工智能体判断手部姿势的能力弱,这样的专家标注具有显著价值。**其三是基于仿真环境自动标注:**仿真平台(如 Habitat 3.0)及其衍生基准(如 TrackVLA++ 所使用的 EVT-Bench)对其管理的虚拟环境具有完全访问权限,通常能够生成精确的可供性标签(例如物体相对智能体的极坐标系)。对于来自仿真环境的数据集,使用仿真环境标注可供性标签也是常见选项。
优缺点
优点
空间显式性强: 输出为可视化区域或密集场,具有良好的可解释性; * 跨平台迁移性好: 抽象掉控制细节,仅保留功能语义,对不同机械臂或视角具鲁棒性; * 语义与物理统一: 模型同时学习形状与功能属性(可抓、可推、可倒),具备任务泛化能力。
缺点
三维感知不足: 多数方法仍基于2D预测,难以处理遮挡与深度的关系; * 缺乏时间动态: 忽略任务中可供性的时序变化,如“盖子打开后才能倒液体”; * 对噪声敏感: 光照、遮挡、材质变化等因素易导致预测漂移。
2.4 轨迹(Trajectory)
** **图7: 不同Trajectory的表征 (点轨迹 视觉轨迹 光流场)[1] * **介绍:**Trajectory形式的思维链以“动作轨迹”作为中间表示,在时序空间中显式生成一段连续路径,用以刻画从当前状态到目标状态的动态演化过程。与语言式或代码式CoT不同,这种形式在推理过程中引入了时间与空间维度,使智能体能够以“可视化运动”的方式进行思考与规划,从而在复杂任务中获得更强的物理可解释性与过程连续性。 * **方法:**Trajectory类方法整体上体现了信息从稀疏到稠密、从显式几何到隐式动态的渐进式演化趋势。总体而言,这类方法可分为三种主要形式:点轨迹、视觉轨迹与光流场。
点轨迹(图7左1):以 VLA-R1[22]为代表,该方法使用关键点位姿序列表示末端执行器在时空中的运动轨迹。点轨迹常作为具身“大脑”模型(规划层)与“小脑”模型(执行层)之间的中间表征,为后者解码出底层动作提供直接而精确的空间指引。 * 视觉轨迹(图7左2):以 MolmoAct[21]为代表,视觉轨迹将点轨迹渲染至图像或视频域,使模型能够在视觉空间中直观“看到”动作路径。由于感知视觉轨迹需要更强大的模型,此类方法通常作为端到端VLA模型的中间推理阶段。 * 光流场(图7左3):光流场描述了像素级在帧间的动态变化,用于捕捉场景整体运动而非单一轨迹。虽然其表示较为复杂、难以解析,但能隐式建模多物体交互与连续运动模式。目前光流更多用于具身感知输入,而较少被直接作为CoT的中间表示,但仍具潜在研究价值。 * **与其他中间表征结合:**Trajectory与其余中间表征结合的工作常见于需求连续动作的工作,例如机械臂控制与视觉语言导航。在执行机械臂控制的VLA中,Trajectory经常与纯自然语言联合使用,作为指令与动作的中间表示。VLA-R1等工作选择先用NL推理出当前子动作,再绘制子动作对应的Trajectory以指导后续的动作生成;而GigaBrain-0[27]则选择先绘制操作的轨迹,再解释当前操作对应的子动作,最后解码出最终动作。我们认为探索Trajectory的粒度以及它与NL思维链的前后位置也是一个潜在的研究方向。 * 数据
相关数据集介绍:代表性的Trajectory数据集包括ShareRobot、BridgeData v2[8]、Open X-Embodiment[28]、EgoRe-5M[4]等。对于点轨迹数据集,数据集中每条轨迹均保存了每个采样点的视觉、语言、执行器动作;对于视觉轨迹数据集,每条轨迹通常保存一副场景图以及对应的数个2D坐标串联形成的轨迹。 * 数据构建方案:按照数据构建方案,可分为两类。其一是直接采样于仿真环境或现实机器人,并以机器人运行轨迹的格式储存(例如ShareRobot、Bridge Data v2)。此类数据可直接用作点轨迹训练样本,亦可通过图像处理(例如在观察中连续标注夹持器位置并串联)转化为视觉轨迹或光流场形式。RT-Trajectory、VLA-R1等工作在训练中均使用了此类数据集。其二是**基于无标注视频使用工具自动化抽取,**例如EgoThinker、ThinkAct等工作注意到从海量的人类视频中提出轨迹的可能:Ego4D、Something-Something V2等等数据集包含丰富的操作示例,可通过 CoTracker、TAPIR 等关键点跟踪器或光流算法自动提取轨迹标签,从无标注视频中构建可学习的轨迹数据。这种方式展现了从互联网级视频中挖掘可供学习信号的潜力,但对数据清洗与标注一致性要求较高。
优缺点
优点
时空连续与可解释性强:Trajectory显式展示了从感知到执行的动态链条,便于可视化与调试; * 物理一致性高:轨迹直接对应真实动作序列,有助于模型学习运动学与动力学规律; * 数据来源广泛:便于从无标注视频中提取轨迹信息,数据获取成本相对较低。
缺点
语义层缺失:轨迹仅描述“怎么动”,缺乏对“为何而动”的抽象,需与语言或目标状态结合; * 计算负担重:轨迹数据连续且高维,训练与推理成本高; * 三维泛化不足:当前多局限于2D轨迹,难以充分表达三维操作空间中的复杂动态。
2.5 目标状态(Goal State)
图8:以EO-1为载体的CoT[29] * **介绍:**Goal-State作为CoT的一种中间表示,把“观测→行为”的中间环节显式化成可感知的目标状态(常见为目标图像/下一帧图像/子目标图像序列,也可为显式状态向量)。模型先生成目标/子目标状态,再把“当前观测 + 目标状态(或其潜在表达)”一起喂给模型,产出动作。这样做把抽象语言推理落到可验证、可执行的感知空间,更容易与扩散/流匹配等世界模型结合,并能在运行时做一致性校验。 * **方法:**这一类把“目标状态”显式化为思维链的核心桥梁:先“想出目标”(目标帧/子目标帧/目标图像+原始动作的交错证据),再据此驱动控制。可分为单步目标、多步子目标、与交错模态三种范式。
**单步目标图像→动作:**CoT-VLA[2]先用“指令+当前帧”预测目标帧,再以“指令+当前帧+目标帧”生成动作,充分利用无动作视频学“目标长什么样”,再用少量动作数据对齐“目标图像→动作”; * **多步子目标图像序列→动作:**CoTDiffusion把“子任务描述”替换为子目标图像序列,先学帧间差异/关注区域,再在 将对齐模块嵌入扩散模型预测下一帧/下一子目标,并据此逐步执行,形成更可验证的逐步规划; * **与其他中间表征结合:**交错模态式 CoT 把“思考与执行”拆成文本推理流与/视觉目标流两条并行信号,再在统一框架中交替对齐,以此把语言计划落到可验证的感知与控制上。例如EO-1[29]将视觉—文本—动作统一到同一解码器的交错序列中:文本段写计划与推理,动作段用流匹配生成连续控制;为防止动作去噪对后续条件造成污染,引入交错纠正抽样,确保后续模态始终“看见干净动作”,从而维持“想 ↔ 做”的因果一致;SEAL运行时并行采样多条动作序列,同时生成目标图像作为视觉证据,对“计划—执行”进行一致性验证并甄选最优;以raw action + 目标图像的双证据形态,构成一种交替校验的图像/动作—文本协同思维范式。 * 数据
相关数据集介绍:在多源轨迹数据中,统一将“目标状态”作为中间表示来连接高层理解与低层控制:对人类演示视频(如 Ego4D[30]、Something-Something V2[31]),先从单或多视角的 RGB(可含音频、字幕)提取关键点轨迹与光流等像素级运动线索,再归纳为目标位置、接触点或目标区域等目标状态,用于指导后续的动作规划;对真实机器人数据(如 RT-1、BridgeData、RoboPoint[32]),多模态记录的视觉、末端位姿与控制信号可直接生成路点序列或三维姿态等目标状态,作为对策略的监督与参考。无论来源如何,流程都可表述为:依据指令与当前观测先预测目标状态或目标路点,再由低层控制去跟踪与实现,从而解耦语义理解与执行细节,便于多来源对齐与跨语言、跨场景迁移。 * 数据构建方案:数据构建上,主要可分为两类。其一是无标注人类视频挖掘:对 Ego4D/SSv2 等先做片段筛选(手部/交互显著性、运动强度),再运行 CoTracker/TAPIR 等关键点跟踪器或光流生成轨迹;随后做时序拼接与平滑、轨迹去噪/去漂移、异常剔除与轨迹规范化(像素→归一化/相机坐标),必要时结合标题/字幕生成弱语义描述,形成 (视频片段,轨迹) 的可学习对。其二是基于真实机器人采集与对齐:通过遥操作或脚本演示逐时刻采集观测 o_t(RGB/RGB-D/点云等)、状态 s_t(关节/末端位姿/力矩等)与语言指令 x,并同步记录执行器动作/路点;完成时间对齐与标定(相机内外参、基座与末端坐标系)后,将原始控制信号统一为 2D/3D 点轨迹或关键路点,最终形成标准监督样本对:序列 (o1…T, s1…T, x) → (轨迹/动作)。在此基础上,可将空间轨迹投影为视觉轨迹或光流场,对人/机轨迹进行重采样、插值与时间伸缩以统一长度与频率,并执行去重、跨传感器一致性检查与基于运动先验的异常过滤;同时叠加视角、光照、背景等数据增强,以提升标注稳定性与跨域鲁棒性。
优缺点
优点
强落地性与可验证性:目标/子目标在像素或显式状态空间,可用感知器/执行器直接校验“是否达到”。 * 抽象规划具体化:解耦“目标生成”与“控制轨迹”,便于与扩散/流匹配等世界模型对接;对语言幻觉更鲁棒。 * 可扩展性强:可大量用无动作视频学“目标外观/过渡”,再少量动作对齐,降标注成本、易迁移。
缺点
视角/相机依赖:目标图像对相机位姿/光照敏感,跨场景复用需做多视角一致性对齐 * 成本高:相比于文本CoT,多子目标图像生成会拉长推理时延;
2.6 潜在表征(Latent Representation)
图9:以DreamVLA为载体的CoT[33] * 介绍:潜在表征(Latent representation)作为CoT的一种中间表示,用“潜在世界/潜在动作”作为中间表示:不是直接输出目标图像或显式文字链,而是在编码后的隐空间里先形成世界嵌入或动作嵌入,再据此解码为动作序列。这样既保留了语言推理的抽象力,又把决策锚定到可学习、可压缩、可泛化的表征上,便于接入扩散/流匹配/离散VQ等生成器与世界模型。 * 方法:这一类方法把“思考”收拢到不可见但可学习的潜在空间:先得出潜在世界嵌入或潜在动作表示,再把它解码成可执行控制。优点是压缩与泛化强、便于与扩散/流匹配协同,也能大量吸纳弱标注/生成数据来“塑形”隐空间。
**连续潜在向量:**即先在连续隐空间里形成“世界/动作”表示,再将其解码为多步控制;优点是表征紧凑、可泛化,且易与扩散/流匹配等生成式解码器耦合。例如如图8,DreamVLA[33]冻结文本视频编码器与可学习状态编码器,把多模态输入与可学习的 dream queries 送入 LLM 得到世界嵌入,再用 action query 引出潜在动作嵌入,最后以该潜在向量条件化 denoising-diffusion transformer,把噪声去噪为 n 步动作;训练时用运动区域/深度/语义等多头显式监督,迫使隐空间学到“物理+常识”知识;GigaBrain-0[27] 在“Embodied CoT”里显式产出连续的操控轨迹:将末端执行器路径投影到图像平面,并用10 个关键点表示,模型引入10 个可学习的 trajectory tokens与全局视觉特征双向交互,随后经轻量 GRU 回归出 2D 像素坐标;同时,动作端由 Diffusion Transformer(DiT)+ flow matching 预测连续的 action chunks,与轨迹回归一同作为连续表征流优化(统一目标联合训练)。两者相辅相成——DreamVLA 在模型端建立“潜在世界→潜在动作→扩散解码”链路,GigaBrain-0 在数据端用世界模型做分布共形与结构补强;合起来既提升隐空间可用性,又增强跨域鲁棒与落地控制性能。 * **离散运动token:**离散运动 token思路先把“帧间运动”量化为有限词表的离散符号,在隐空间完成“语言→运动表示”的推理,再把该表示解码为动作。它把连续控制离散化,便于学习、约束与复用,且可与连续潜在/扩散解码和世界模型扩域互补。Moto(离散桥接的核心范式)先用 VQ-VAE 将帧间运动量化成latent motion tokens;预训练仅用 LM loss 学“观测+指令→latent 序列”,微调再联学动作回归;推理先生成 latent 序列,再解码成最终动作,等价于“语言 ↔ 运动 token ↔ 动作”的三段桥接,带来更高的样本效率与可控性。除连续流外,GigaBrain-0 还在 CoT 中生成离散表征:生成离散动作 tokens,两者均按自回归下一词预测训练,其中离散动作 tokens 用于加速后续 DiT 的连续动作块学习与收敛,构成“离散推理(语言/动作 token)→ 连续控制”的桥接层。 * **结合离散运动token和潜在向量:**实践上离散运动token和潜在向量可组合使用:先用世界模型把数据分布“做宽”,再选用 离散 token 桥接(Moto)或连续潜在+扩散(DreamVLA)“做稳”落地控制;当任务强调可控性/样本效率时偏向离散 token,当强调长视界/物理一致性时偏向连续潜在+扩散,两者在统一隐空间框架下可互补增益 * **与其他中间表征结合:**在实际应用中,中间表示常采用 language plan 与 Trajectory 的融合式设计。以 GigaBrain-0 为例,它利用 World Model 构建贴近真实分布的数据体系:对人类演示进行视角、背景、光照与颜色等风格增强与重整,并执行 sim-to-real 的域迁移;同时并行生成并对齐自然语言计划与轨迹式推理链。该联合表征在保持可执行性的同时,显著提升中间表示的可解释性、语义覆盖度与跨域稳健性。 * 数据
**相关数据集介绍:**统一以潜在表示作为中间层贯通三类数据:仿真(如 CALVIN、LIBERO)用状态与多视角观测结合指令,学习映射到潜在目标/潜在动作;真实演示(如 DROID)用真实轨迹与控制序列把同一潜在空间对齐到可执行分布;世界模型增强数据在视频上叠加结构与推理通道,提升潜在表征的可迁移性。最终,高层先预测潜在目标/潜在动作,低层据此解码为多步控制。 * 数据构建方案:数据构建统一围绕把多源样本规约为潜在表示:在仿真与世界模型生成路线上(如 DreamVLA、GigaBrain-0、Moto[34]),先用深度/语义/运动区域等结构信号或视频运动量化器(VQ-VAE)将观测与指令压缩为潜在目标/潜在动作(如连续潜在向量或离散 latent motion tokens),再以该潜在表示去条件化生成多步控制或与下游控制逐层对齐;在真实演示路线上(如 DROID、GigaBrain-0 的人/机演示),同样先为视频叠加结构与推理通道(深度、语义、CoT 注释),把可执行的轨迹与控制映射进同一潜在空间,使“观测/指令 → 潜在表示 → 控制”的中间层在不同数据域与风格下保持一致,从而既保留世界知识,又稳定支撑动作解码。
优缺点
优点
压缩与泛化好:使用潜在表示作为CoT,可以去除了由图片或者文本CoT导致的外观噪声(光照/背景/视角),对跨域更稳; * 可与生成器无缝耦合:扩散/流匹配/自回归在 latent 上更易优化,支持长视界与多步规划; * 可扩展性强:可大量用无动作视频/世界模型合成学习 tokenizer 或世界嵌入,再用少量动作对齐;
缺点
可解释性弱:latent 难以人类直观核查,需要额外可视化或验证器; * 对 tokenizer/世界模型依赖强:量化误差或生成偏移会传染到动作; * 训练链路复杂:需多阶段(tokenizer→潜在建模→解码器/扩散→联合微调),超参与稳定性要求高;
3. 从训练层面提升
为了激发具身智能体的思维链(CoT)能力,现有研究存在两种主要的训练范式:基于模仿学习的方法和基于强化学习的方法。两种范式优势互补。本节将对此展开详细讨论。 3.1 基于模仿学习 (Imitation Learning) 
**训练策略:**在具身CoT的模仿学习训练中,大规模预训练提供了跨模态理解与空间推理的基础,而使用CoT数据的微调则让模型具备具体场景中的思维链生成与决策能力。pi0.5等工作的消融实验已经证明,在预训练数据中加入互联网视觉语言数据、域外机器人数据、具身推理数据能够增强目标任务上的性能。Robix等研究证明了特定领域微调能将预训练VLM迁移为具身CoT模型。通过在Qwen2.5-VL上继续预训练具身任务、并使用带有推理链和人类交互标注的数据进行微调,Robix[5]将通用VLM转变成了具有主动对话、实时中断处理等新功能的具身推理模型。而ECoT[16]同样通过带有CoT的标注数据微调,将Prismatic VLM转变为具有CoT能力的VLA。总体来看,大规模视觉语言预训练、具身领域继续预训练、特定领域微调“三步走”是激发具身CoT的主流模仿学习范式。
优缺点
优点
简单易用:相比强化学习需要设计复杂奖励函数(特别是思维链部分质量难以评估、具身场景下奖励信号稀疏),模仿学习不依赖外部奖励函数,直接从专家演示中学习最优或近似最优策略,在数据数量充足、分布均匀时开发周期短,效果良好。 * 收敛速度快:由于采用监督式优化,训练过程稳定、收敛更快,不依赖大量探索,能够迅速培养模型的基本推理能力。
缺点
泛化性不足:受限于专家数据分布,模型在未见过的新场景或任务上表现不佳。 * 策略退化与复合误差累积:缺乏长期反馈,模型容易在多步推理中容易偏离目标轨迹,导致策略逐渐退化、难以完成复杂、长视野的具身智能任务。 * 成本较高:高质量的具身演示(尤其是思维链注释)难以大规模获取,数据标注成本高。
3.2 基于强化学习 (Reinforcement Learning)
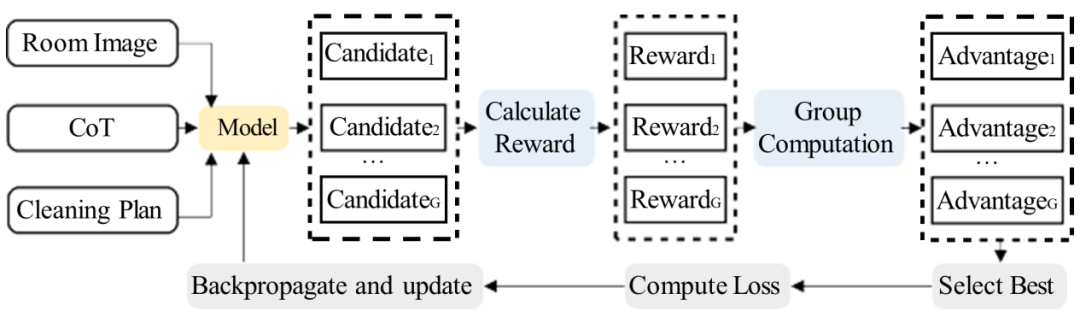
图11: 使用RL训练模型CoT能力[10] * **简介:**近期工作探索了超越纯模仿学习的训练范式。它们普遍采用多阶段训练流程,以强化学习阶段为微调的最终阶段,并旨在通过精心设计的、可验证的奖励函数来耦合高层推理与底层控制/定位。尽管在具体目标、策略和侧重点上存在差异,但这些方法共同展示了RL在提升模型泛化性、鲁棒性以及减少对精细专家标注依赖方面的巨大潜力。 * 训练目标:近期具身CoT工作均采用可验证奖励作为训练目标,且同时考虑CoT的过程与结果。例如ThinkAct[36]的RL阶段的目标是让推理MLLM生成的具身CoT和视觉轨迹规划在物理上准确可行。奖励函数专门为此设计,结合了视觉奖励保轨迹起点/终点准确和整体形状像专家的目标奖励与轨迹奖励)和格式奖励,以驱动CoT与真实世界动力学对齐。VLA-R1的RL阶段的目标是联合提升推理质量和动作执行精度。奖励函数最为综合,包含轨迹一致性奖励(使用ALAF,即一种综合考虑轨迹点顺序、切向角度和段长比例的增强Fréchet距离)、区域对齐奖励(GIoU)和格式奖励,以实现多目标优化。二者均通过精细化设计的物理约束奖励,提高底层控制的准确性 * **训练策略:**现有采用RL的具身CoT工作呈现出“模仿学习—强化优化”的通用路径。具体而言,近期工作首先通过模仿学习建立基础能力,再借助RL实现性能跃升。例如,EgoThinker和VLA-R1均采用两阶段流程,先进行SFT,再分别通过GRPO算法(图11: Group Relative Policy Optimization (GRPO))优化定位或推理-动作能力;而ThinkAct与UML-CoT则进一步引入第三阶段,分别用于动作模型适应或答案导向的强化优化。尽管阶段数量和具体目标有所差异,这些方法的共同核心在于:模仿学习负责能力构建,RL则聚焦于能力的精准对齐与优化,体现出当前技术发展中“先学后精”的普遍思路。
优缺点
优点
提升推理-动作一致性:通过可验证的奖励信号(如轨迹)强制CoT与物理世界对齐,解决了模仿学习中“推理合理但动作错误”的脱节问题。 * 激发任务导向的推理能力:奖励驱动模型探索更有效的推理路径,能涌现出模仿学习难以获得的自反思与自纠正等高级认知行为。 * 减少对专家CoT标注的依赖:无需人工逐步标注思维链,能利用大量仅含最终结果(如成功轨迹、检测框)的数据进行学习,降低了数据成本。
缺点
奖励设计复杂且敏感:性能高度依赖为特定任务手工设计的奖励函数,需要领域知识,且设计不当易导致模型行为偏差。 * 训练开销与实现复杂度较高
3.3 总结 现有具身CoT工作通常采用两种主流的训练范式来优化系统性能:基于模仿学习的方法和基于强化学习的方法。模仿学习通过优化不同中间表征设计特定的损失函数,快速构建基础能力,然而,模仿学习的泛化性往往受到专家数据分布的限制。而强化学习则通过依据不同中间表征的特性精细化的奖励函数,在无需大量标注的前提下能够提升模型的推理与执行精度。通过结合这两种方法,具身CoT的性能得以显著提升。 4. 从推理过程优化层面提升
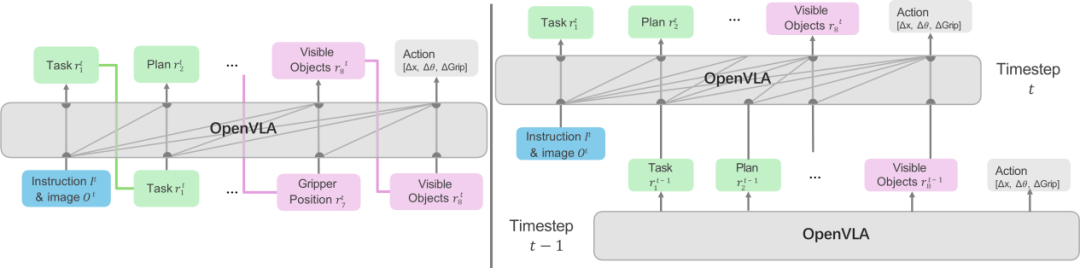
图12: 重用CoT以提升推理效率[37] 具身CoT的推理过程优化主要包含两个层面:一是通过优化推理过程以提升CoT的生成效率;二是优化推理过程以提升模型最终性能。
**优化推理过程以提升模型性能:**ECoT 的研究发现,思维链中的错误与最终动作的失败存在显著关联。 这一现象提示,若能够在推理过程中识别并纠正 CoT 中的潜在错误,则有可能提前规避错误动作的执行,减少具身交互中的损失;SEAL框架通过三层验证机制强化这一过程:在假设阶段并行生成多个候选CoT;通过仿真环境预执行动作序列的结果;在验证阶段利用视觉语言模型评估CoT与动作结果的一致性,实现早期错误检测与修正;VAMOS [24]通过学习每个载体的Affordance 函数,判断当前CoT在该载体上的可行性,从而在推理阶段动态筛选或调整规划结果。这种基于可行性判断的机制,使具身CoT能够自动考虑载体的物理约束,在迁移到新载体时仍保持较好的执行一致性。 * **优化推理过程以提升生成效率:**高效产生CoT是提升具身系统推理效率的核心,关键在于优化推理过程以减少计算延迟。现有工作可分为如下几个层面。
**重用和缓存CoT:**具身任务的规划通常从宏观到微观逐层展开,高层任务规划在相邻推理间往往保持稳定。例如,在执行“拿起香蕉并放到盘子里”的任务中,高层规划(如“让香蕉在盘子上”)基本不变,而中间层的子任务(移动、抓取、放置)相对稳定。基于此,Fast ECoT[37](图12: 重用CoT) 提出缓存和重用高层思维链的策略,将上次推理的高层规划(即 token 序列的前缀)作为下一次推理输入,从而实现从自回归解码到并行解码的转变,提高推理速度。在此基础上,研究者还探索了异步推理机制,以进一步提升性能。 * **使用双系统协同架构:**高层规划的更新频率通常远低于底层控制。基于这一特性,Nav-R1[6] 和 ThinkAct 将系统设计为由“慢系统”和“快系统”协同工作的结构:前者负责长时语义推理与高层任务规划,后者则专注于低延迟的动作执行与实时反应。快系统在循环控制过程中持续采用慢系统最近生成的规划结果,而无需等待新的输出,从而实现异步协同运行。这种设计既保证了高层规划的连贯性,又显著提升了系统对动态环境的响应速度。 * 推理阶段的模块简化:DreamVLA 在训练阶段加入多个轻量化模块,用于将 LLM 输出映射为运动区域、深度、语义,通过监督学习提升模型对物理世界的理解。但在推理阶段移除运动区域、深度、语义的轻量化模块,保留核心推理与控制结构,从而减少计算量,提高推理帧率。 * 通用推理优化策略:除 CoT 机制本身的优化外,Action Chunk 等通用的具身智能推理优化算法也能提高推理帧率,使 CoT 在具身场景中实现更高效的实时反应。
总体而言,具身CoT的推理优化通过在生成效率与性能增强两方面的系统性设计,实现了从快速思维链生成到智能化推理控制的完整优化闭环,为具身智能的发展提供了坚实的推理基础。 尽管上述推理优化方法在提升效率与性能方面取得了显著成效,但我们仍需清醒地认识到其固有的局限性。例如Fast ECoT、 Nav-R1 和 ThinkAct虽然更高效地产生CoT,但是部署系统的复杂度也增加了。Fast ECoT所依赖的高层规划稳定性前提,在任务目标频繁切换的动态场景中难以成立,其近似处理会因前提失效而产生显著误差。VAMOS和SEAL等框架中引入的可行性判断与多层验证机制,也增加了系统的复杂性与计算开销。 5. 总结 本文全面回顾了近期具身CoT方法。近期研究主要围绕推理中间数据表征设计,训练以及推理优化展开。 **从推理中间表征设计层面,**近期工作采用多种中间表示形式引导推理。这些表示形式帮助模型生成更为清晰和可操作的推理链条,提升了模型对复杂任务的理解和决策能力。 **从训练层面,**近期研究主要集中于通过模仿学习和强化学习等策略提升模型的推理与决策能力。模仿学习通过专家示范数据来初始化模型的推理能力,而强化学习则通过精细设计的奖励函数,使得模型能够在动态环境中进行更为精准的推理与行动决策。此外,模型的训练方法也逐渐向多阶段、模块化训练演进,以提高训练效率和推理能力。 **从推理优化层面,**近期工作通过缓存、模块化与协同架构等策略,有效提升了系统的效率;通过加强推理中验证与提前预判错误并及时修正,有效提升了推理性能。 尽管现有具身CoT方法在性能上取得了一定进展,但仍面临跨任务和场景泛化能力不足,训练与推理代价高昂等挑战。未来的研究应聚焦于提升跨任务和场景的适应性,优化推理效率,更多地探索不同推理中间表征的有效整合以及处理处理更多的模态信息(如语音模态,触觉模态等),以推动具身智能系统的实际应用。
6. 参考文献
[1] Zhong Y, Bai F, Cai S, et al. 2025. A Survey on Vision-Language-Action Models: An Action Tokenization Perspective[A/OL]. arXiv preprint arXiv:2507.01925.[2] Zhao Q, Lu Y, Kim M J, et al. 2025. CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models[J].[3] Liu Y, Chi D, Wu S, et al. 2025. SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning[J].[4] Pei B, Huang Y, Xu J, et al. 2025. EgoThinker: Unveiling Egocentric Reasoning with Spatio-Temporal CoT[J].[5] Fang H, Zhang M, Dong H, et al. 2025. Robix: A Unified Model for Robot Interaction, Reasoning and Planning[A/OL]. arXiv preprint arXiv:2509.01106.[6] Liu Q, Huang T, Zhang Z, et al. 2025. Nav-R1: Reasoning and Navigation in Embodied Scenes[A/OL]. arXiv preprint arXiv:2509.10884.[7] Lin B, Nie Y, Zai K L, et al. 2025. EvolveNav: Empowering LLM-Based Vision-Language Navigation via Self-Improving Embodied Reasoning[A/OL]. arXiv preprint arXiv:2506.01551.[8] Walke H, Black K, Lee A, et al. 2024. BridgeData V2: A Dataset for Robot Learning at Scale[J].[9] Sermanet P, Ding T, Zhao J, et al. 2023. RoboVQA: Multimodal Long-Horizon Reasoning for Robotics[A/OL]. arXiv preprint arXiv:2311.00899.[10] Chen H, Wang G. 2025. UML-CoT: Structured Reasoning and Planning with Unified Modeling Language for Robotic Room Cleaning[A/OL]. arXiv preprint arXiv:2509.22628.[11] Liu Y, Liang Z, Chen Z, et al. 2025. HyCodePolicy: Hybrid Language Controllers for Multimodal Monitoring and Decision in Embodied Agents[A/OL]. arXiv preprint arXiv:2508.02629.[12] Wang W, Ike O, Choi S, et al. 2025. Deductive Chain-of-Thought Augmented Socially-aware Robot Navigation World Model[A/OL]. arXiv preprint arXiv:2510.23509.[13] Obi I, Venkatesh V L N, Wang W, et al. 2025. SafePlan: Leveraging Formal Logic and Chain-of-Thought Reasoning for Enhanced Safety in LLM-based Robotic Task Planning[A/OL]. arXiv preprint arXiv:2503.06892.[14] Ginting M F, Kim D K, Meng X, et al. 2025. Enter the Mind Palace: Reasoning and Planning for Long-term Active Embodied Question Answering[A/OL]. arXiv preprint arXiv:2507.12846.[15] Chu X, Deng J, You G, et al. 2025. GraspCoT: Integrating Physical Property Reasoning for 6-DoF Grasping under Flexible Language Instructions[A/OL]. arXiv preprint arXiv:2503.16013.[16] Zawalski M, Chen W, Pertsch K, et al. 2024. Robotic Control via Embodied Chain-of-Thought Reasoning[A/OL]. arXiv preprint arXiv:2407.08693.[17] Sundaresan P, Belkhale S, Sadigh D, et al. 2023. KITE: Keypoint-Conditioned Policies for Semantic Manipulation[A/OL]. arXiv preprint arXiv:2306.16605.[18] Liu J, Qi Y, Zhang J, et al. 2025. TrackVLA++: Unleashing Reasoning and Memory Capabilities in VLA Models for Embodied Visual Tracking[A/OL]. arXiv preprint arXiv:2510.07134.[19] Cai S, Wang Z, Lian K, et al. 2024. ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting[A/OL]. arXiv preprint arXiv:2410.17856.[20] Huang W, Wang C, Zhang R, et al. 2023. VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models[A/OL]. arXiv preprint arXiv:2307.05973.[21] Lee J, Duan J, Fang H, et al. 2025. MolmoAct: Action Reasoning Models that can Reason in Space[A/OL]. arXiv preprint arXiv:2508.07917.[22] Ye A, Zhang Z, Wang B, et al. 2025. VLA-R1: Enhancing Reasoning in Vision-Language-Action Models[A/OL]. arXiv preprint arXiv:2510.01623.[23] Zhou W, Xiong X, Peng Y, et al. 2025. PhysVLM-AVR: Active Visual Reasoning for Multimodal Large Language Models in Physical Environments[A/OL]. arXiv preprint arXiv:2510.21111.[24] Wang S, Zhao Q, Do M Q, et al. 2023. Vamos: Versatile Action Models for Video Understanding[A/OL]. arXiv preprint arXiv:2311.13627.[25] Corona E, Pumarola A, Alenya G, et al. 2020. GanHand: Predicting Human Grasp Affordances in Multi-Object Scenes[C]. CVPR 2020: 5030–5040.[26] Wang S, Zhang J, Li M, et al. 2025. TrackVLA: Embodied Visual Tracking in the Wild[A/OL]. arXiv preprint arXiv:2505.23189.[27] G Team, Ye A, Wang B, et al. 2025. GigaBrain-0: A World Model-Powered Vision-Language-Action Model[A/OL]. arXiv preprint arXiv:2510.19430.[28] O X E Collaboration, O’Neill A, Rehman A, et al. 2023. Open X-Embodiment: Robotic Learning Datasets and RT-X Models[A/OL]. arXiv preprint arXiv:2310.08864.[29] Qu D, Song H, Chen Q, et al. 2025. EO-1: Interleaved Vision-Text-Action Pretraining for General Robot Control[A/OL]. arXiv preprint arXiv:2508.21112.[30] Grauman K, Westbury A, Byrne E, et al. 2021. Ego4D: Around the World in 3,000 Hours of Egocentric Video[A/OL]. arXiv preprint arXiv:2110.07058.[31] Goyal R, Kahou S E, Michalski V, et al. 2017. The “Something-Something” Video Database for Learning and Evaluating Visual Common Sense[A/OL]. arXiv preprint arXiv:1706.04261.[32] Yuan W, Duan J, Blukis V, et al. 2024. RoboPoint: A Vision-Language Model for Spatial Affordance Prediction for Robotics[A/OL]. arXiv preprint arXiv:2406.10721.[33] Zhang W, Liu H, Qi Z, et al. 2025. DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge[A/OL]. arXiv preprint arXiv:2507.04447.[34] Chen Y, Ge Y, Tang W, et al. 2024. Moto: Latent Motion Token as the Bridging Language for Learning Robot Manipulation from Videos[A/OL]. arXiv preprint arXiv:2412.04445.[35] Intelligence P, Black K, Brown N, et al. 2025. π₀.₅: A Vision-Language-Action Model with Open-World Generalization[A/OL]. arXiv preprint arXiv:2504.16054.[36] Huang C P, Wu Y H, Chen M H, et al. 2025. ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning[A/OL]. arXiv preprint arXiv:2507.16815.[37] Duan Z, Zhang Y, Geng S, et al. 2025. Fast ECoT: Efficient Embodied Chain-of-Thought via Thoughts Reuse[A/OL]. arXiv preprint arXiv:2506.07639.[38] Wang Y, Wu S, Zhang Y, et al. 2025. Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey. arXiv preprint arXiv:2503.12605.[39] https://openai.com/zh-Hans-CN/index/introducing-gpt-5/
编辑:欧阳扬鸥初审:张 羽复审:冯骁骋终审:单既阳
哈尔滨工业大学社会计算与交互机器人研究中心
理解语言,认知社会 以中文技术,助民族复兴
