
协同作战飞机被设想用于在竞争环境中执行自主的情报、监视与侦察任务,在这种环境中对手可能采取战略性行动进行欺骗或规避探测。由于模型的不确定性和对安全、实时决策的需求,这些任务带来了挑战。鲁棒马尔可夫决策过程提供了最坏情况下的性能保证,但受限于静态模糊集,这些模糊集捕捉了初始不确定性却无法适应新的观察结果。本文提出了一种为协同作战飞机执行情报监视侦察任务量身定制的自适应鲁棒马尔可夫决策过程框架。我们引入了一个针对任务的建模方式,其中飞机在移动状态和传感状态之间交替。对手战术被建模为一组有限的转移核,每个核都捕捉了关于对手传感或环境条件如何影响奖励的假设。我们的方法通过消除不一致的威胁模型来逐步优化策略,使智能体能够在保持鲁棒性的同时从保守行为转向激进行为。我们提供了理论保证,表明自适应规划器在可信集收缩至真实威胁时会收敛,并在不确定性下保持安全性。在不同网络拓扑结构下对高斯和非高斯威胁模型进行的实验表明,与标称规划器和静态鲁棒规划器相比,该方法获得了更高的任务奖励和更少的暴露事件。
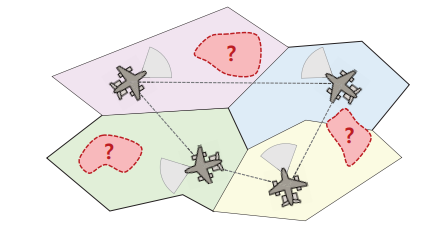
图1 采用协同作战飞机执行分散式ISR任务的任务层面概念示意图。每架飞机在局部威胁不确定性下,在指定区域内执行监视。彩色多边形表示示例性区域划分,红色虚线区域标注不确定威胁位置,带有传感弧段的飞机图标示意传感覆盖范围。
协同作战飞机已被广泛提议作为未来空战和监视行动的关键赋能因素,尤其是在竞争性或通信受阻的环境中。这些平台有望自主或半自主运行,与其他资产协同执行复杂任务,如电子战、精确打击和广域情报监视侦察。这一愿景已在美国空军的“下一代制空权”计划中得到实现,该计划将协同作战飞机定位为无人“力量倍增器”,能够在动态的对抗环境中执行分布式、高风险的任务。
在这些角色中,情报监视侦察因其在有限的集中协调下实现分布式传感和持久态势感知的潜力而受到越来越多的关注。然而,对自主情报监视侦察的这种乐观看法往往低估了现实环境中及其内部的对抗性和欺骗性。对抗性威胁行为者可能部署机动地对空导弹系统、间歇性启动雷达传感器或发射虚假信号,以掩盖其真实位置和能力。这些行为挑战了自主规划中常见且关键的假设:准确模型和稳定动态的可用性。在此类环境中,情报监视侦察平台在部分可观测性以及对对手行为和环境转移的认知不确定性下运行。
从本质上看,这一挑战代表了模型不确定性下的序贯决策问题。强化学习作为一种解决方案已被广泛探索,它提供了适应性和通过数据驱动策略进行泛化的能力。在航空航天应用中使用强化学习的兴趣日益增长,例如自主导航、飞行控制和多智能体任务规划。然而,强化学习方法通常需要大量探索且缺乏安全性保证,这使其不适用于安全关键任务。作为另一种选择,鲁棒马尔可夫决策过程通过在一组预定义的转移模型模糊集上进行优化,提供了最坏情况下的性能保证。尽管如此,传统的鲁棒马尔可夫决策过程方法依赖于静态模糊集,并且不纳入任务执行期间收集的新信息,这限制了其在动态或对抗环境中的效率。在实践中,执行情报监视侦察任务时,随着智能体观察威胁如何感知、反应或暴露自身,其对底层对抗模型的理解也在不断演变。减少这种不确定性需要可能增加暴露的探索性行动,而采取保守行动又会限制改进威胁模型的能力。
这种动态张力自然地引出了情报监视侦察任务特有的探索-利用困境,智能体必须在提高对对抗行为的理解与保持安全和任务效能之间取得平衡。最近关于在危险或不确定领域中自主车辆协调的研究,已经证明了通过不确定性感知和自适应决策框架明确处理这种权衡的好处。尽管先前的工作为处理探索和风险提供了实用策略,但它们并未在适用于情报监视侦察任务的鲁棒序贯决策框架内明确形式化这种权衡。受此差距启发,我们提出一个为情报监视侦察任务量身定制的自适应鲁棒马尔可夫决策过程框架,该框架建立在已有文献中的在线鲁棒规划形式化之上,并通过不确定性感知的策略适应自然地平衡探索与利用。在此过程中,智能体对结构化的对抗行为进行推理,并动态调整其策略,以在竞争环境中保持安全性和覆盖范围。
本稿件的其余部分组织如下。第二部分提供文献综述,第三部分介绍相关背景。第五部分详细描述了任务场景和自适应情报监视侦察任务策略。第六部分介绍了自适应鲁棒规划框架,包括图鲁棒马尔可夫决策过程、贝叶斯信念更新和模糊集收缩。关于收敛性、安全性和渐近最优性的理论保证在第六部分C中给出。第七部分展示了不同威胁模型和图结构下的仿真结果。第八部分总结了研究发现并概述了未来工作方向。

