国际机器学习会议 ICML(International Conference on Machine Learning),是全球范围内人工智能领域的顶级学术会议之一,由国际机器学习学会(IMLS)举办,与 NeurIPS、ICLR 并列为 AI 三大顶会。
ICML 2025 为第四十二届,于 7 月 13-19 日在加拿大温哥华举行。
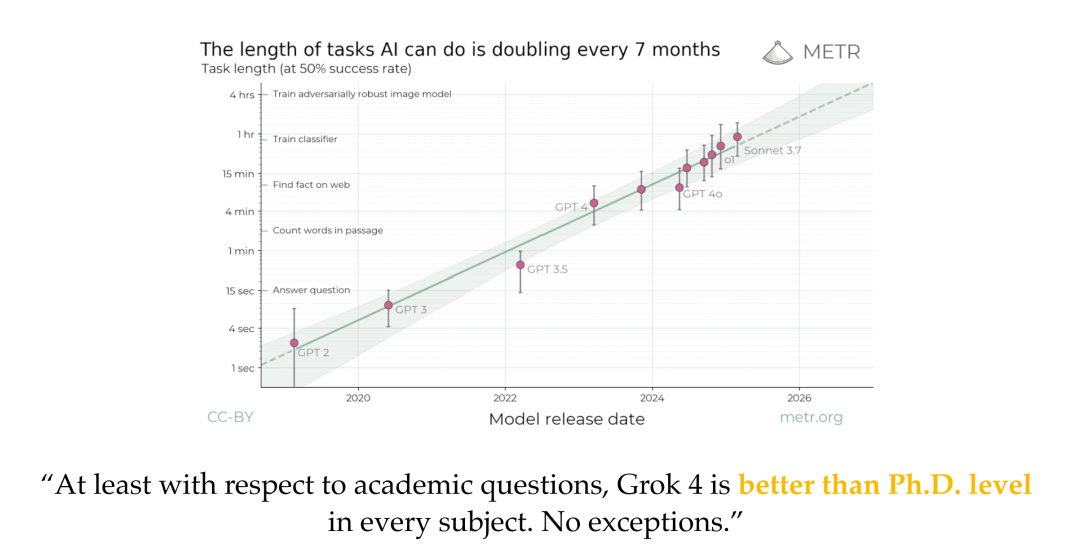
ICML 2025 共收到 12107 篇有效论文投稿,比去年(9653篇)大幅增长了 25.4%,最终有 3260 篇论文被接收,总体接收率为 26.9%。 今年获奖论文共计 8 篇,其中包括 6 篇杰出论文奖和 2 篇杰出立场论文奖。

自大语言模型(LLMs)问世以来,AI 安全领域便受到了广泛关注。相关研究致力于制定一系列最佳实践,包括评估协议、防御算法以及内容过滤器,旨在推动 LLM 及相关技术的伦理、安全与可靠部署。在 AI 安全中,一个核心议题是模型对齐(model alignment),即通过算法优化 LLM 的输出,使其符合人类价值观。然而,尽管已有大量研究努力,近期研究仍发现了多种失败模式——统称为“越狱(jailbreak)”——这些攻击手段可绕过模型对齐机制,诱导目标模型生成不安全内容。 最初的越狱攻击主要针对生成有害信息(如侵犯版权或违法内容),而当代攻击则更具针对性,聚焦于特定领域的风险,例如让数字智能体侵犯用户隐私,或操控由 LLM 控制的机器人在现实世界中执行危险行为。更严重的是,未来的攻击可能会瞄准模型的自我复制或权力寻求等高风险行为。越狱攻击的隐蔽性与破坏性构成了 LLM 广泛应用的重大障碍。因此,机器学习社区亟需深入研究这些失败模式,并设计出有效的防御策略加以应对。 在过去两年中,学术界与工业界不断推动越狱攻击与防御机制的双向演化:一方面开发新的攻击方法以测试模型安全性,另一方面强化模型的防护能力。这些持续努力在整体上提升了模型的安全性。例如,OpenAI 的 o 系列模型与 Anthropic 的 Claude3 系列在应对多种越狱攻击方面展现出显著的鲁棒性。然而,越狱与防御之间的“军备竞赛”仍在持续,这也表明当前的安全水平尚未达到最终理想状态。 为系统呈现该领域的最新进展,本文教程旨在对越狱研究的演化图景提供一个统一视角。我们的主要目标如下:
回顾越狱攻击的前沿进展,涵盖新兴的算法框架与数学基础,重点关注攻击方法、防御机制、评估技术及其在机器人与智能体系统中的应用; 1. 讨论该领域的未来方向,指出越狱攻击研究仍处于起步阶段,由其带来的新挑战、新机遇与研究方向值得关注; 1. 展示一系列开源 Python 实现,涵盖当前最先进算法的实际应用与演示。