

近年来人工智能(AI)模型的成功伴随着其内部机制的不透明性,尤其是由于深度神经网络的广泛使用。为了理解这些内部机制并解释 AI 模型的输出,研究者提出了一系列方法,统称为可解释人工智能(XAI)。本文聚焦于 XAI 的一个子领域——可解释强化学习(XRL),该方向旨在解释通过强化学习获得策略的智能体所采取的行为。 我们提出了一种直观的分类方法,基于两个核心问题:“解释什么(What)”与“如何解释(How)”。第一个问题关注解释方法所针对的目标,第二个问题则涉及解释的呈现方式。我们基于这一分类体系,对超过 250 篇相关文献进行了系统综述。 此外,我们还介绍了一些与 XRL 密切相关的研究领域,并指出这些方向应受到社区更多关注。最后,本文总结了当前 XRL 领域面临的一些关键需求与挑战。
1 引言
本文对可解释性与透明性的强化学习(Explainable and Transparent Reinforcement Learning)进行了最新综述,汇集了一系列近年来提出的新方法,这些方法既包括专门针对强化学习(RL)设计的技术,也包括从可解释人工智能(XAI)领域迁移而来的方法,例如最初用于分类模型解释的 LIME【285】和 SHAP【234】。 强化学习是一种机器学习范式,其中智能体(agent)在环境中通过序列决策进行学习。给定当前状态(state)所提供的信息,智能体在每个时间步选择一个动作(action),进入新的状态并获得由环境动态(包括状态转移函数和奖励函数)决定的奖励。智能体的目标是通过学习一个最优策略,最大化其累积奖励(也称为“回报”)。一个强化学习问题通常建模为马尔可夫决策过程(Markov Decision Process, MDP),表示为四元组 ⟨S, A, R, p⟩,其中 S 和 A 分别表示状态空间和动作空间,R: S × A → ℝ 是奖励函数,p: S × A → Pr(S) 是状态转移函数。 除介绍可解释强化学习(XRL)方法外,我们还简要介绍一些与之密切相关的 RL 子领域,这些领域虽然以提升策略性能与泛化能力为主要目标,但同样有助于解释或增强智能体行为的可透明性。例如,关系型强化学习(Relational RL, RRL)【97】让智能体基于对象及其关系进行推理,而非直接处理原始数据,这些关系本身即可用于解释智能体的行为。 本综述基于 12 篇已有的代表性综述文献【204, 153, 247, 125, 121, 381, 155, 369, 78, 402, 279, 8】以及一些补充性论文。其中,文献【125】专注于强化学习的可解释性,文献【121】聚焦于反事实解释(counterfactual explanations),而其他综述则并未限定于某一特定解释类型。反事实解释用于确定输入(例如 RL 中的状态)需做出哪些修改,才能改变模型的输出(例如智能体的策略)。值得注意的是,这类方法在当前的 XRL 研究中仍显不足【121】。 本文的主要目标如下: * 综述用于解释或增强强化学习智能体可透明性的各类方法; * 介绍一部分使用模型无关(model-agnostic)解释方法的工作; * 简要描述与 XRL 密切相关、值得研究者关注的研究领域; * 总结当前 XRL 领域存在的研究需求。
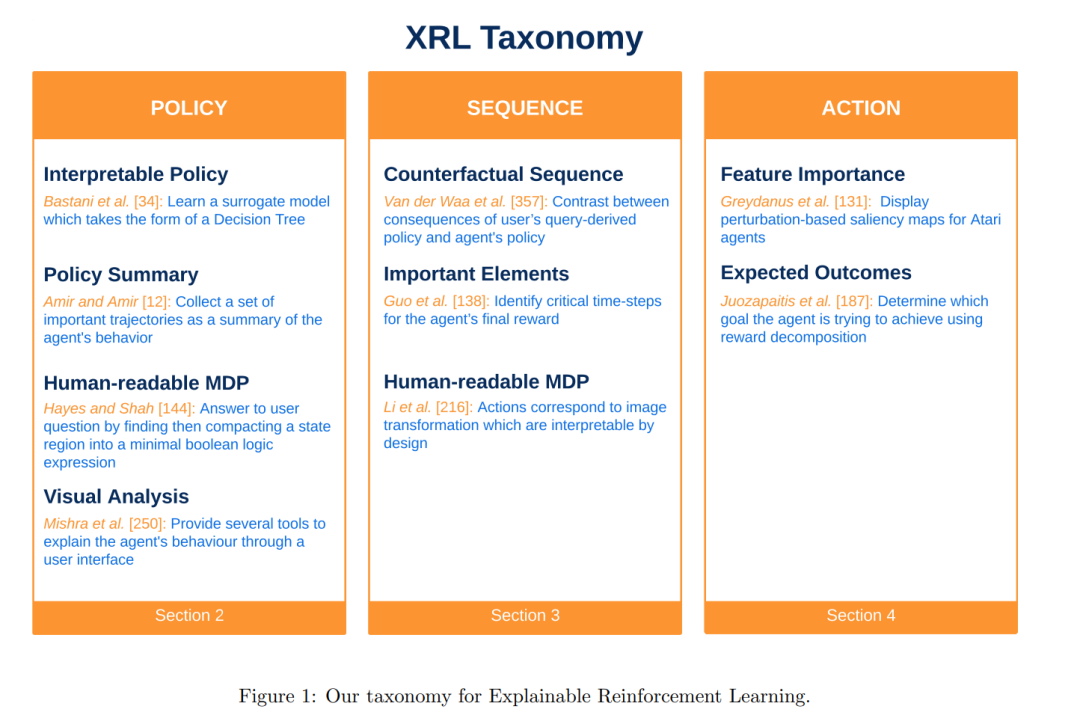
在本综述中,我们既涵盖了面向解释的技术方法,也包括那些通过设计本身实现行为可透明性的策略。我们认为覆盖这两类方法对于全面理解如何让智能体行为对用户“可理解”至关重要。在文中,我们将这两类方法统称为“解释”或 XRL,尽管从严格意义上讲它们略有不同。 当前 XRL 研究中尚未形成一致的分类体系。例如,Puiutta 与 Veith【279】借用了用于分类模型解释的分类法,按照解释的范围(scope)与解释的时机(timing)进行区分。就范围而言,**局部解释(local explanation)关注某一具体动作选择,而全局解释(global explanation)**则描述智能体整体策略;就时机而言,内在解释(intrinsic explanation)指模型本身可被直接解释,而事后解释(post-hoc explanation)则是在模型学习完成后给出解释。Milani 等人【247】则提出一种更贴合强化学习特点的分类方法,将工作分为三类:特征重要性(识别影响决策的状态特征)、学习过程与 MDP(揭示导致当前策略的学习轨迹与环境组成)、策略层级(解释智能体的长期行为)。Dazeley 等人【78】则提出了一个基于因果解释框架(Causal Explanation Framework)【46】的概念模型,即因果 XRL 框架(Causal XRL Framework),并据此将方法分为两类:感知类(perception)和动作类(action)。前者侧重于智能体的感知如何影响其行为与结果,后者则关注动作选择及其结果影响。 由于尚无统一分类标准,本文提出一个基于两个核心问题的简明分类法:“What”与“How”。具体而言: * “What”用于界定解释方法的目标,即“该方法试图解释什么?希望使哪方面变得透明?”我们识别出三个主要对象:
智能体的策略(policy); 1. 智能体与环境之间的某一交互序列; 1. 智能体在特定情境下的某一动作选择。 * “How”用于细化分类,考察具体的解释方式,即“如何进行解释?”。本文根据上述三个“解释对象”,系统整理了各类解释方法,并在图1中展示了该分类体系的概要及其对应的代表性研究工作。
我们相信,这一分类体系可帮助读者快速识别与其研究问题相关的方法类别,并了解不同方法所采用的解释方式。本综述也揭示了当前研究的热点趋势,无论是在解释目标还是技术路径方面。 本文余下内容结构如下: * 第2节:介绍用于解释智能体策略的方法; * 第3节:描述用于解释智能体在一段交互序列中的行为的方法; * 第4节:阐述用于解释智能体在特定状态下动作选择的方法; * 第5节:简要介绍与 XRL 相关的重要研究领域; * 第6节:根据已有综述文献,总结 XRL 领域的研究需求。