
原创作者:陈则睿
指导老师:刘铭
转载须标注出处:哈工大SCIR
1 简介
大型语言模型性能强大,但仍面临“事实幻觉”的挑战。知识图谱作为结构化知识能有效缓解此问题,但不同KG间常因独立构建而存在“信息孤岛”。实体对齐旨在连接不同KG中的等价实体,是实现多源知识融合的关键。传统EA方法(如基于TransE或GNN的方法)常在捕捉深层语义和可扩展性上受限,而语言模型的兴起为此带来了颠覆性的新策略。
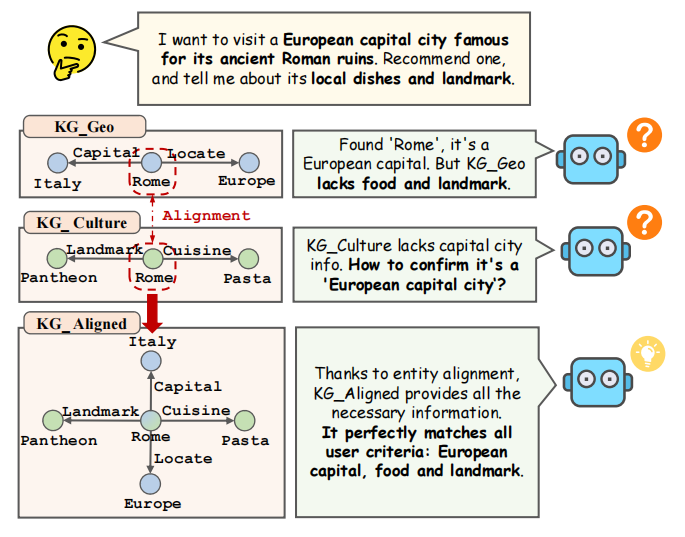
正如 图1 所示,实体对齐能显著增强LLM应对复杂查询的能力。当面对一个需要结合地理位置(首都)、文化(美食、地标)信息的查询时,若知识库是碎片化的,LLM将难以整合出完整答案。而经过实体对齐后,一个统一的知识库能提供所有必要信息,使LLM能够完美、准确地回应用户。为此,哈工大SCIR实验室知识计算组的陈则睿、范会明、王乾宇、何涛在刘铭教授与秦兵教授的指导下,共同撰写了这篇综述,该工作已被自然语言处理顶级会议EMNLP 2025录用为主会论文。本文创新性地提出了一个统一的技术框架,将整个LM驱动的实体对齐流程解构为三个逻辑清晰的核心阶段:数据准备、特征嵌入和对齐决策。通过这个框架,不仅对每个阶段的关键技术和代表性工作进行了细致剖析,还深入探讨了当前的核心挑战与未来发展路径。本文作者期望这篇综述能为初学者快速构建起对该领域的系统性认知,并为资深研究者提供富有洞见的参考与灵感。
2 LM-Driven EA分类
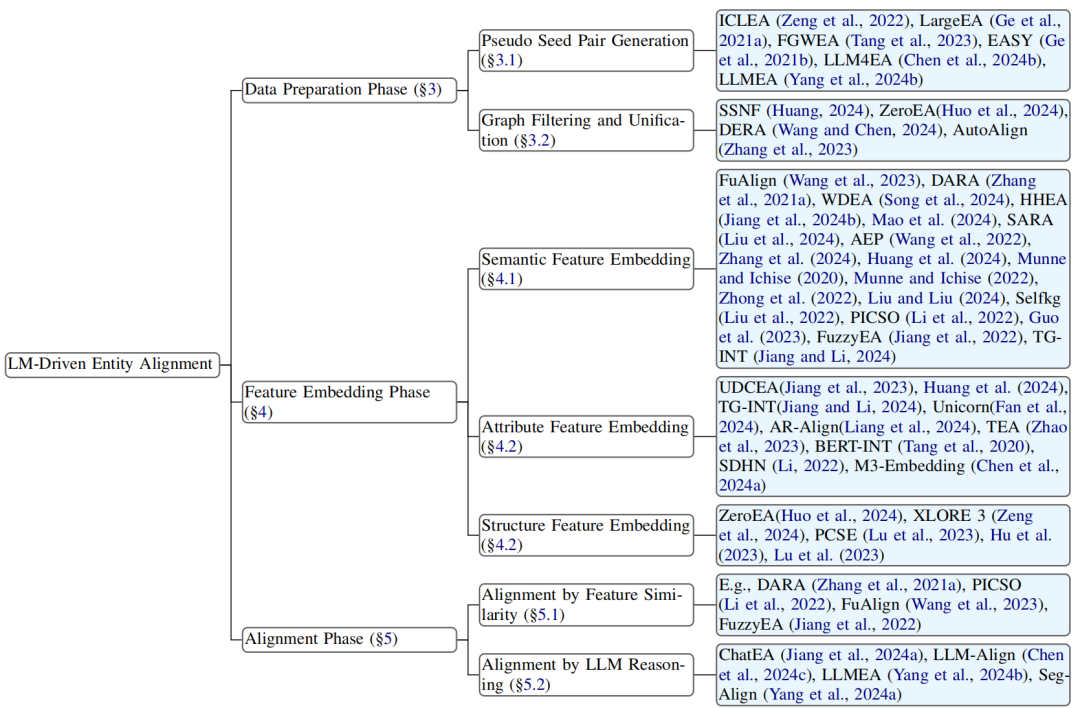
图2:基于语言模型的实体对齐模型的分类和代表性工作
3 三阶段实体对齐
为系统化梳理现有工作,我们提出了一个分类法,将LM驱动的EA方法按其在流程中的核心作用,划分为三个关键阶段。数据准备阶段:关注LMs如何用于预处理、增强或筛选对齐所需的数据。具体包括伪种子对生成和图谱过滤与统一。特征嵌入阶段:阐述LMs如何为实体生成富含上下文的向量表示。这进一步细分为语义特征嵌入、属性特征嵌入和结构特征嵌入。对齐阶段:涵盖如何利用LM衍生的特征或其内在的推理能力来做出最终的匹配决策。这包括基于特征相似性的对齐和基于LLM推理的对齐。
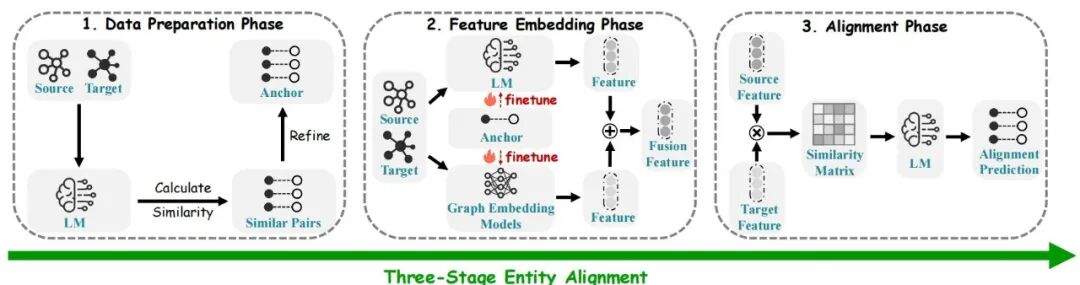
图3:LM驱动的实体对齐方法的三个阶段
3.1 数据准备 在此初始阶段,LMs被用作强大的数据预处理器,旨在解决训练数据稀疏或质量不高的问题。LMs通过计算源实体和目标实体间的相似度来生成或精炼锚点对。这具体表现为两大策略: 3.1.1 基于编码能力的伪种子对生成 利用LMs强大的文本编码能力来识别潜在的对齐实体。例如,ICLEA 分别编码实体名称和描述来创建伪对齐对;FGWEA 则采用LaBSE或SimCSE等先进句子编码器,并结合Sinkhorn算法来确定高置信度的锚点。 3.1.2 基于生成能力的交互式增强 LLMs的生成和指令跟随能力也被用于更智能的数据增强。LLM4EA 采用主动学习策略识别“最有价值”的实体,并引导LLM为其生成伪标签;而 LLMEA 则通过精心设计的提示来指导LLM筛选实体。此外,LMs的零样本能力也被用于图谱过滤与结构统一,例如 ZeroEA 的 Graph2Prompt 模块将图的拓扑结构转化为文本,供LM理解和处理。 3.2 特征嵌入这是LMs的核心应用阶段,其目标是为每个实体生成能够全面反映其特性的向量表示。经过微调的LMs和图嵌入模型共同为源实体和目标实体生成特征,这些特征随后被融合以产生更全面的表示。根据信息的来源和处理方式,这包括了多种精细化的策略。 3.2.1 语义与结构融合 除了实体名称和描述,其丰富的属性也是对齐的关键线索。UDCEA 和 Unicorn 等方法专门利用LMs直接对实体的属性三元组进行编码。TEA 和 BERT-INT 等工作则通过设计特定的训练任务来微调LM,使其能更好地理解和表示属性信息。3.2.2 属性信息深度编码
一种更前沿的范式是,不将结构信息视为独立的模态进行融合,而是直接将其“翻译”成自然语言,让LM在一个统一的文本空间中进行处理。例如,XLORE 3 建立结构化模板,PCSE 则利用上下文消息传递来生成描述性文本,从而将隐式的结构关系显式化。 3.3 对齐决策最终的对齐阶段展现了从计算到推理的明显范式演进。 3.3.1 基于特征相似性的对齐 这是较为传统但高效的范式。它利用第二阶段生成的实体嵌入向量,通过计算相似度矩阵,并采用近邻搜索等算法来预测对齐关系。例如,DARA 在其融合后的特征空间中寻找最近邻,BERT-INT 则在其微调后的统一嵌入上执行直接的相似度搜索。**
**
3.3.2 基于LLM推理的对齐
这是更前沿、更智能的范式。它超越了单纯的向量相似度计算,直接将实体信息、候选对乃至相似度矩阵作为上下文输入给一个大型语言模型,通过精心设计的提示技术(如Zero-shot, Few-shot, Chain-of-Thought),让LLM直接作为推理引擎进行最终的对齐预测。代表工作 ChatEA 将对齐任务转化为对话形式,LLM-Align 采用多轮投票机制进行精炼,而 Seg-Align 则利用零样本提示来处理复杂的跨语言对齐样本,充分发挥了LLM在复杂逻辑判断上的优势。 4 评估、挑战与未来方向 4.1 评估与分析 在DBP15K和SRPRS等基准数据集上,LM驱动的方法已展现出卓越性能,例如FGWEA在ZH-EN任务上Hits@1达到0.987,甚至出现了“基准饱和”的趋势。这证明了LMs作为EA基础技术的强大,同时也促使我们必须将目光投向更具挑战性的真实世界问题。 4.2 现有挑战与未来方向 4.2.1 超越文本:向多模态实体对齐发展 当前的实体对齐研究绝大多数局限于文本和结构化数据。然而,现实世界的实体(如人物、地点、商品)通常由包含图像、音频、视频在内的多种模态共同描述。因此,一个至关重要的未来方向是多模态实体对齐,其目标是综合利用这些异构来源的信息来识别等价实体。未来的研究需要攻克一系列核心挑战,包括:如何有效融合异构的多模态表示;如何处理现实场景中常见的模态数据缺失或噪声问题;以及如何利用新兴的大型多模态模型的强大能力,以在这些信息丰富的实体间实现更全面、更精确的对齐。 4.2.2 深化推理:利用LLM推理解决复杂对齐 为了进一步提升实体对齐的准确性,特别是在处理复杂或模棱两可的案例时,未来的工作必须超越简单的嵌入相似度或直接提示,转而利用大型语言模型更复杂的推理能力。这包括采用如思维链等先进的提示技术,引导模型进行逐步推理,以更准确地辨别实体间的细微差异。然而,这些高级推理方法会显著增加计算开销。因此,其实际应用必须与效率提升并行。关键策略包括:通过模型压缩或知识蒸馏等技术开发更紧凑的EA专用模型;以及设计高效的推理方法,例如只对最具挑战性的实体对选择性地应用高强度的推理,从而在推理深度与计算可行性之间取得平衡,实现稳健且可扩展的LLM驱动EA。 4.2.3 新基准:构建更真实、更具挑战性的评估基准
当前主流基准上观察到的“饱和”现象——即多种模型取得近乎完美的分数——凸显了对新评估标准的迫切需求。未来的工作必须优先创建和管理更具挑战性的新基准,以真实地测试模型的鲁棒性和可扩展性。这些新基准应具备以下关键特征:1)更高的噪声与稀疏性,以模拟真实世界知识图谱中普遍存在的信息不完整和不一致问题;2)更大的规模与异构性,涵盖更大规模的知识图谱以及更多样的结构、语义甚至跨模态特征;3)更复杂的对齐场景,例如包含大量模糊实体、复杂的n-to-m映射关系(而非简单的1-to-1映射),以及来自高度专业化领域的知识图谱,在这些场景中,简单的表层特征往往无效。构建此类基准对于驱动领域创新、摆脱对现有指标的增量改进至关重要。 5 总结 本文对语言模型驱动的实体对齐进行了全面的综述,深入探讨了这一新兴领域的核心进展。具体而言,我们将EA的工作流系统性地划分为数据准备、特征嵌入和对齐决策三个关键阶段,并提供了一个创新的分类法,深入分析了LMs在每个阶段中的独特贡献。通过总结关键的基准、评估指标,我们归纳了当前面临的挑战并指明了未来的发展方向。本文旨在填补现有综述的空白,首次系统性地聚焦于语言模型如何从根本上重塑实体对齐领域,希望为该交叉领域的研究人员和实践者提供一份宝贵的参考,推动语言模型与知识图谱集成的持续探索与创新。
6 参考文献
[1] Artetxe M, Schwenk H. 2019. Massively multilingual sentence embeddings for zero-shot cross-lingual transfer and beyond[J]. Transactions of the Association for Computational Linguistics, 7: 597–610. [2] Auer S, Bizer C, Kobilarov G, et al. 2007. Dbpedia: A nucleus for a web of open data[C]//international semantic web conference. Springer: 722–735. [3] Bordes A, Usunier N, Garcia-Duran A, et al. 2013a. Translating embeddings for modeling multi-relational data[C]//Advances in neural information processing systems. 26. [4] Bordes A, Usunier N, García-Durán A, et al. 2013b. Translating embeddings for modeling multi-relational data[C]//Neural Information Processing Systems. [5] Chaurasiya D, Surisetty A, Kumar N, et al. 2022. Entity alignment for knowledge graphs: Progress, challenges, and empirical studies[J]. arXiv preprint arXiv:2205.08777. [6] Chen J, Xiao S, Zhang P, et al. 2024a. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation[J]. arXiv preprint arXiv:2402.03216. [7] Chen Q, Qin L, Liu J, et al. 2025. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models[J]. arXiv preprint arXiv:2503.09567. [8] Chen S, Zhang Q, Dong J, et al. 2024b. Entity alignment with noisy annotations from large language models[J]. arXiv preprint arXiv:2405.16806. [9] Chen X, Lu T, Wang Z. 2024c. Llm-align: Utilizing large language models for entity alignment in knowledge graphs[J]. Preprint, arXiv:2412.04690. [10] Chen Z, Guo L, Fang Y, et al. 2023. Rethinking uncertainly missing and ambiguous visual modality in multi-modal entity alignment[C]//International Semantic Web Conference. Springer: 121–139. [11] Church K W. 2017. Word2vec[J]. Natural Language Engineering, 23(1): 155–162. [12] Cuturi M. 2013. Sinkhorn distances: Lightspeed computation of optimal transport[C]//Advances in neural information processing systems. 26. [13] Devlin J, Chang M W, Lee K, et al. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186. [14] Fan J, Tu J, Li G, et al. 2024. Unicorn: A unified multi-tasking matching model[J]. ACM SIGMOD Record, 53(1): 44–53. [15] Fanourakis N, Efthymiou V, Kotzinos D, et al. 2023. Knowledge graph embedding methods for entity alignment: experimental review[J]. Data Mining and Knowledge Discovery, 37(5): 2070–2137. [16] Feng F, Yang Y, Cer D, et al. 2022. Language-agnostic bert sentence embedding[J]. Preprint, arXiv:2007.01852. [17] Frantar E, Ashkboos S, Hoefler T, et al. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers[J]. arXiv preprint arXiv:2210.17323. [18] Gao T, Yao X, Chen D. 2022. Simcse: Simple contrastive learning of sentence embeddings[J]. Preprint, arXiv:2104.08821. [19] Ge C, Liu X, Chen L, et al. 2021a. Largeea: aligning entities for large-scale knowledge graphs[J]. Proceedings of the VLDB Endowment, 15(2): 237–245.

