
KDD2020|阿里团队最新的多元兴趣推荐模型---ComiRec

8.23
最近在Github上开源了一个项目:「Recommender System with TF2.0」,复现经典的论文,并且每个模型是独立的,可以单独进行验证。目前已有91个star,感兴趣的可以star一下,让我早点突破100!
8.16 更新
感谢各位点赞,不过发现胶囊网络确实没讲清楚,大家可以看一下这篇文章或者里面的四篇参考博客,写得非常好,发现知乎大多数介绍胶囊网络和动态路由算法都是参考这些的。
================================================================
前言
本次分享一篇2020年阿里团队发表在KDD的文章“Controllable Multi-Interest Framework for Recommendation”。本篇文章提出的模型ComiRec是基于推荐系统中匹配/召回的方法,且是一个序列化推荐的解决方案。由于是当前最新的序列化推荐匹配模型,因此会详细的介绍其背景、方法与实验。
微信:
1. 研究背景
1、对于工业界的推荐系统来说,一般由匹配/召回(matching)阶段和排序/精排(ranking)阶段组成。「匹配主要是检索出Top-K个候选物品」,而「精排则是通过更精确的分数来对候选物品进行排序」。本篇文章,主要「聚焦于匹配问题」,提高匹配的性能。
2、可以将推荐系统看作是一个「序列推荐问题」,即想要预测用户下一个可能交互的物品。
3、目前推荐系统的「准确性」并不是唯一的问题,人们更有可能被推荐一些新的或「多样化」的东西【长尾问题】。
本篇文章主要是基于上述三个研究背景进行展开。
2. 研究现状
1、传统的推荐方法主要是用协同过滤来预测分数。后来演变成用神经网络---对建立用户与物品的表示,并比传统方法的性能更为优越。但对于大规模的电子商务系统,很难直接使用神经网络给出用户对目标物品的CTR预估。现如今工业界使用快速KNN(如Faiss[1])来生成一个候选物品集,然后使用神经网络模型(如xDeepFM[2])来整合用户物品属性,以优化诸如CTR之类的业务指标。
2、当然最近也有使用「图嵌入」(Graph Embedding)来表示用户和物品。PinSage[3]建立在GraphSAGE[4]的基础上,将基于图卷积网络的方法应用于具有数十亿节点和边的数据。GATNE[5]考虑了不同的用户行为类型,并利用一种异构的图嵌入方法来学习用户和物品的表示。但是这些方法忽略了用户行为中的序列信息,无法捕捉相邻用户行为之间的相关性。【引入序列推荐】
3、推荐也可以看作一个序列化问题,通过用户的历史,来估计下一个用户感兴趣的物品。很多模型(DIN、DIEN)都从用户的行为序列给出一个整体的Embedding。但是,统一的用户Embedding不能反映用户在一段时间内的「多种兴趣」。如下图所示:


Emma对珠宝、包、化妆品感兴趣,她在这段时间内应该可能会点击三种类别的物品。
【注】本篇文章对推荐的分类:传统、基于神经网络(端到端、非端到端)、从基于神经网络的模型细化到基于图表示、再从用户历史行为中得到序列化推荐。基于图表示和序列化推荐是目前较为热门的研究方向。大家可以看一下文章的一些引用文献。
3. 创新与贡献
基于上述问题,作者提出一个新的序列化推荐模型:「controllable multi-interest framework,ComiREC」。模型分为「多元兴趣模块」(multi-interest module)和「聚合模块」(aggregation module)。多元兴趣模块从用户行为序列中捕捉多种兴趣,可以在大规模的物品池中检索候选的物品集。然后将这些物品输入到聚合模块以获得总体Top-K推荐。并且聚合模块利用「可控因素」(controllable factor)来「平衡推荐的准确性和多样性」。
4. 模型方法
4.1 问题定义
假设一个用户集合u \in \mathcal{U}和一个物品集合i \in\mathcal{I},对于每一个用户,定义用户序列(e_1^{(u)},e_2^{(u)},...,e_n^{(u)}),根据时间先后顺序排序。e_t^{(u)}记录了第t个物品与用户交互。文章所有的字母表示含义见下表:


4.2 多元兴趣模型整体框架
在工业推荐系统的物品池中经常有上百万或亿级别的物品,因此匹配阶段在推荐系统中扮演一个非常重要的角色。
对于「匹配阶段模型」:
- 首先通过用户历史行为序列计算出用户的「embedding」,然后基于embedding检索用户的候选物品集合。
- 然后利用快速K近邻(KNN)算法从大规模物品池中为每个用户生成最接近的物品集。
匹配阶段的决定性因素是根据用户历史行为计算出的「用户Embedding的质量」。对于部分序列模型只是建立一个单一的用户Embedding,但是其缺乏表达能力,因为现实世界的用户通常同时对几种类型的物品感兴趣,这些物品通常用于不同的用途,并且在类别上有很大的差异。因此作者提出了用于推荐系统的多元兴趣框架(「Multi-Interest Framework」),主要分为多元兴趣提取模块和聚合模块。


4.3 多元兴趣提取模块
本篇文章,作者主要使用两种方法:「动态路由法」[^6](dynamic routing method)和「自注意力机制法」(self-attentive method)来作为兴趣提取方法,分别对应的模型称为「ComiRec-DR」和「ComiRec-SA」。
Dynamic Routing Method
使用「动态路由方法」作为用户行为序列的多兴趣提取模块。将用户行为序列的物品embedding列表看作是「最初的胶囊(primary capsules)」,多元用户兴趣看作是「兴趣胶囊(interest capsules)」。
❝胶囊网络的概念是在2011年首先提出的,并在动态路由方法提出后广为人知。「胶囊是一组神经元」,其活动向量代表一个特定类型实体的实例化参数。胶囊的输出向量的长度表示由胶囊所表示的实体在当前输入中的概率。
❞
令\mathbf{e}_i表示最初层的胶囊i,可以给出基于最初胶囊的下一层的胶囊j的计算:
\hat{\mathbf{e}}_{j|i}=\mathbf{W}_{ij}\mathbf{e}_i \\
其中\mathbf{W}_{ij}表示一个转换矩阵,那么胶囊j的「总输入」是所有预测向量\hat{\mathbf{e}}_{j|i}的加权和:
\mathbf{s}_j=\sum_ic_{ij}\hat{\mathbf{e}}_{j|i} \\
其中c_{ij}为「耦合系数」(coupling coefficients),由迭代动态路由过程确定。胶囊i与下一层所有胶囊的耦合系数之和应为1。因此使用“「routing softmax」”来计算偶和系数:
c_{ij}=\frac{exp(b_{ij})}{\sum_kexp(b_{ik})} \\
其中b_{ij}表示i和j耦合的「对数先验概」率。
应用一个非线性的 「“压缩”(squashing)函数」,以确保短向量缩小到几乎零长度和长向量缩小到略低于1的长度。因此,胶囊j的「输出」向量表示为:
\mathbf{v}_j=squash(\mathbf{s}_j)=\frac{\|\mathbf{s}_j\|^2}{1+\|\mathbf{s}_j\|^2}\frac{\mathbf{s}_j}{\|\mathbf{s}_j\|} \\
\mathbf{s}_j是胶囊j的总输入,为了计算输出胶囊\mathbf{v}_j,我们需要计算基于\mathbf{v}_j和\mathbf{e}_i的内积的概率分布。\mathbf{v}_j的计算依赖于自身;为此,提出了一种「动态路由方法」来解决这一问题。其中用户u的输出兴趣胶囊为矩阵\mathbf{V}_u=[\mathbf{v}_1,...,\mathbf{v}_K]\in \mathbb{R}^{d\times K}。「K为兴趣胶囊的维度。」
具体算法如下所示:


Self-Attentive Method
给出用户行为序列的embeddding矩阵\mathbf{H}^{d\times n},n为用户行为序列的长度,d为用户/物品的embedding的维度。使用「自注意力机制」来获得权重向量\mathbf{a}\in \mathbb{R}^n:
\mathbf{a}=softmax(\mathbf{w}_2^Ttanh(\mathbf{W}_1\mathbf{H}))^T \\
其中\mathbf{w}_2 \in \mathbb{R}^{d_a}和\mathbf{W}_1 \in \mathbb{R}^{d_a \times d}是可训练化参数。
然后通过权重向量\mathbf{a}进行加权和得到向量v_u=\mathbf{Ha} \in \mathbb{R} ^d。对于自注意方法利用用户序列的顺序,作者在输入Embedding中添加了可训练的「位置嵌入」(positional embeddings)。位置embedding与物品embedding的维数d相同,二者可以直接相加。
因此将\mathbf{w}_2扩展为\mathbf{W}_2 \in \mathbb{R}^{d_a \times K},K为兴趣embedding的维度,attention向量\mathbf{a}变为\mathbf{A}:
\mathbf{A}=softmax(\mathbf{W}_2^Ttanh(\mathbf{W}_1\mathbf{H}))^T \\
用户最终的兴趣\mathbf{V}_u \in \mathbb{R}^{d \times K}:
\mathbf{V}_u=\mathbf{HA} \\
模型训练
在多元兴趣提取模块来计算兴趣embedding:
\mathbf{v}_u=\mathbf{V}_u[:,argmax(\mathbf{V}_u^T\mathbf{e}_i)] \\
其中\mathbf{e}_i表示目标向量i的embedding,\mathbf{V}_u表示用户兴趣embedding矩阵。
给出一个训练样本(u,i),用户embedding\mathbf{v}_u,和物品embedding\mathbf{e}_i,可以计算用户与物品交互的似然函数:
P_{\theta}(i|u)=\frac{exp(\mathbf{v}_u^T\mathbf{e}_i)}{\sum_{k\in\mathcal{I}}exp(\mathbf{v}_u^T\mathbf{e}_i))} \\
目标函数为最小化似然函数:
loss=-\sum_{u\in\mathcal{U}}\sum_{i\in \mathcal{I}_u}-logP_{\theta}(i|u) \\
「由于似然函数求和的计算复杂度大,因此使用采样的softmax技术来训练模型。」
在线服务
对于在线服务,使用「多兴趣提取模块」来计算每个用户的多元兴趣。用户的每个兴趣向量都可以通过「Faiss」等最近的近邻库从大规模项池中独立地检索top-N物品。多个兴趣检索到的物品被输入「聚合模块」,以确定总体候选物品。最后,排名较高的物品将被推荐给用户。
4.4 聚合模块(Aggregation Module)
如何将这些不同兴趣的物品聚合起来,得到总的前n个物品?一种基本而直接的方法是根据「物品与用户兴趣的内在相似性」来合并和过滤物品,可以将「相似性」公式化为:
f(u, i)=\max _{1 \leq k \leq K}\left(\mathbf{e}_{i}^{\top} \mathbf{v}_{u}^{(k)}\right) \\
其中\mathbf{v}_u^{(k)}是用户u的第k个兴趣embedding。这是聚合过程中实现推「荐精度最大化」的有效方法。然而,「目前推荐系统的准确性并不是唯一的问题。「人们更有可能被推荐一些」新的或多样化」的东西。
给定从用户u的K个兴趣中检索到一个集合\mathcal{M},有K·N个物品,找到一个输出集合\mathcal{S},有N个物品(Top-N),使预定义的「值函数最大化」。文章使用一个可控制的方法来解决这个问题。使用一个值函数Q(u, S)通过可控因子\lambda来「平衡推荐的准确性和多样性」:
Q(u, \mathcal{S})=\sum_{i \in S} f(u, i)+\lambda \sum_{i \in S} \sum_{j \in \mathcal{S}} g(i, j) \\
其中g(i,j)是一个多样性或差异性的函数:
g(i, j)=\delta(\operatorname{CATE}(i) \neq \operatorname{CATE}(j)) \\
其中CATE(i)表示物品i的类别,\delta(\cdot)是一个指示函数。
如果想要最大的准确率,那么可以令\lambda=0,如果想要最大的多样性,可以令\lambda=\infty。文章提出了一个「贪心推理算法」来近似最大化值函数Q(u,S):


4.5 模型对比
文章选取了最近的两个序列化推荐模型进行对比:MIMN[^8]和MIND[^9]。
- MIMN:是「推荐排序阶段」的一个代表性工作,它使用记忆网络从长序列的行为数据中捕获用户的兴趣。MIMN和本文模型都针对用户的多种兴趣。对于非常长的连续行为,基于记忆的体系结构也可能不足以捕获用户的长期兴趣。与MIMN相比,我们的模型利用多兴趣提取模块来利用用户的多个兴趣。
- MIND:是最近「推荐匹配阶段」的代表性工作,提出了一种Behavior-to-Interest (B2I)动态路由,用于自适应地将用户的行为聚合为兴趣表示向量。与MIND相比,ComiRec-DR采用CapsNet使用的原始动态路由方法,可以捕获用户行为的序列信息。
5. 实验
5.1 实验配置
本文实验配置设计的「很严格」,所以详细说一下:
评估所有方法在强泛化下的性能:「将所有用户」按8:1:1的比例分成训练/验证/测试集。使用训练用户的整个点击序列来训练模型。为了进行评估,从验证和测试用户中提取前80%的用户行为,从训练过的模型中推断用户Embedding,并通过预测剩余20%的用户行为来计算指标。这种设置比弱泛化更困难,弱泛化在训练和评价过程中都使用了用户的行为序列。
【注】:「在验证集和测试集中的用户是从未在训练集中出现过的」。
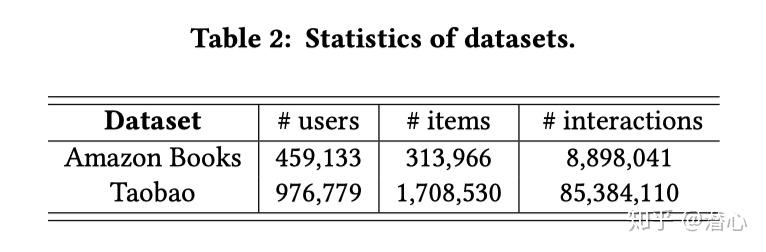
5.2 数据集
- Amazon:使用Amazon数据集中的Book,每个训练样本被「截断长度为20」。【并不算一个长序列】

5.3 方法比较
实验设置中,模型应该为验证集和测试集的未见用户提供预测。因此,基于因子矩阵分解的方法不适合此设置。
- MostPopular
- YouTube DNN【2016】
- GRU4Rec【2016】
- MIND【2019】
5.4 评估标准
- 「召回率(Recall)」:使用每个用户的平均来代替全局
\operatorname{Recall} @ \mathrm{N}=\frac{1}{|\mathcal{U}|} \sum_{u \in \mathcal{U}} \frac{\left|\hat{I}_{u, N} \cap \mathcal{I}_{u}\right|}{\left|\mathcal{I}_{u}\right|} \\其中\hat{I}_{u, N}表示用户u的Top-N个推荐,\mathcal{I}_u表示用户通过模型选出的测试集物品; - 「点击率(Hit Rate)」:
\mathrm{HR} @ \mathrm{N}=\frac{1}{|\mathcal{U}|} \sum_{u \in \mathcal{U}} \delta\left(\left|\hat{I}_{u, N} \cap I_{u}\right|>0\right) \\ - 「NDCG(Normalized Discounted Cumulative Gain)」:
\mathrm{NDCG} @ \mathrm{N}=\frac{1}{Z} \mathrm{DCG} @ \mathrm{N}=\frac{1}{Z} \frac{1}{|\mathcal{U}|} \sum_{u \in \mathcal{U}} \sum_{k=1}^{N} \frac{\delta\left(\hat{i}_{u, k} \in \mathcal{I}_{u}\right)}{\log _{2}(k+1)} \\该指标经常出现在信息检索中
5.5 实验结果
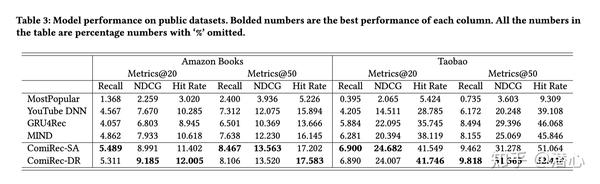

为了与其他模型进行公平比较,在聚合模块中设置了\lambda=0。详细说明了「如何检索框架的top-N物品」:
- 用户的每个兴趣都独立地检索top-N候选物品。因此,模型为每个用户总共检索K \cdot N物品。
- 根据物品Embedding和相应兴趣Embedding的「内积」对物品进行排序。排序后,K·N个物品中的top-N个物品被视为模型的最终候选物品。
如上图所示,ComiRec模型比所有的最先进的模型在所有的评估标准上有很大的差距。GRU4Rec比其他仅为每个用户输出单一Embedding的模型中获得了最好的性能。与MIND相比,由于「动态路由方法的不同」,ComiRec-DR获得了更好的性能。ComiRec-SA通过自我注意机制捕捉用户兴趣的能力较强,其结果与ComiRec-DR相当。
「参数敏感性」
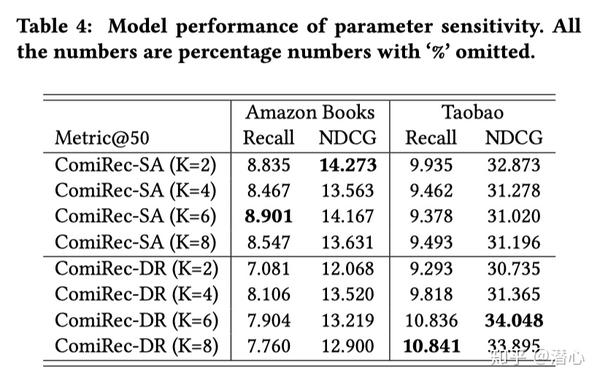

调节兴趣K的敏感性。两个模型显示了这个超参数的不同性质。
5.6 可控制的学习
为了获得每个用户最终的top-N候选物品,提出了一个新的模块来聚合根据每个用户的不同兴趣检索到的物品。除了对推荐达到较高的预测精度外,有研究认「为推荐需要多样化,以避免单调,提高客户体验」。
文章提出的聚合模块可以「控制推荐准确度和多样性的平衡」。使用以下基于物品类别的个体多样性定义:
\text { Diversity@N }=\frac{\sum_{j=1}^{N} \sum_{k=j+1}^{N} \delta\left(\operatorname{CATE}\left(\hat{i}_{u, j}\right) \neq \operatorname{CATE}\left(\hat{i}_{u, k}\right)\right)}{N \times(N-1) / 2} \\
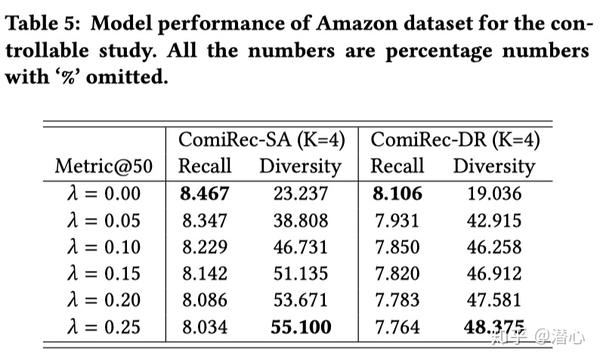

聚合模块可以通过选择一个合适的超参数,在准确性和多样性之间实现最优的平衡。
总结
本文对我的启发很大,不仅是模型,重要的是对整个目前序列化推荐发展的概述。所以想要清楚的了解自己的研究方向发展情况,除了综述,还可以从最新的文章中得到。
参考文献
[1]: Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2017. Billion-scale similarity search with GPUs. arXiv preprint arXiv:1702.08734 (2017).
[2]: Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xDeepFM: Combining explicit and implicit feature interactions for recommender systems. In KDD’18. ACM, 1754–1763.
[3]: Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. 2018. Graph convolutional neural networks for web-scale recommender systems. In KDD’18. ACM, 974–983.
[4]: Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In NIPS’17. 1024–1034.
[5]: Yukuo Cen, Xu Zou, Jianwei Zhang, Hongxia Yang, Jingren Zhou, and Jie Tang.2019. Representation learning for attributed multiplex heterogeneous network. In KDD’19. 1358–1368.
[6]: Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. 2017. Dynamic routing between capsules. In NIPS’17. 3856–3866.
[7]: Geoffrey E Hinton, Alex Krizhevsky, and Sida D Wang. 2011. Transforming auto-encoders. In ICANN’11. Springer, 44–51.
[8]: Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Practice on long sequential user behavior modeling for click-through rate prediction. In KDD’19. 2671–2679.
[9]: Chao Li, Zhiyuan Liu, Mengmeng Wu, Yuchi Xu, Pipei Huang, Huan Zhao, Guoliang Kang, Qiwei Chen, Wei Li, and Dik Lun Lee. 2019. Multi-Interest Network with Dynamic Routing for Recommendation at Tmall. arXiv preprint arXiv:1904.08030 (2019).
