
自己动手写中文分词解析器完整教程,并对出现的问题进行探讨和解决(附完整c#代码和相关dll文件、txt文件下载)
中文分词插件很多,当然都有各自的优缺点,近日刚接触自然语言处理这方面的,初步体验中文分词。
首先感谢harry.guo楼主提供的学习资源,博文链接http://www.cnblogs.com/harryguo/archive/2007/09/26/906965.html,在此基础上进行深入学习和探讨。
接下来进入正文。。。大牛路过别喷,菜鸟有空练练手~~完整的项目源码下载在文章末尾~~
因为是在Lucene.Net下进行中文分词解析器编写的,新建项目Lucene.China,然后将Lucene.Net.dll添加到项目中。(附:资源Lucene.Net.rar)
与英文不同,中文词之间没有空格,于是对于中文分词就比英文复杂了些。
第一,构建树形词库,在所建项目目录下的bin/Debug文件下新建一个文件夹data(如果文件夹已经存在,则不用新建),然后在data文件夹中加入sDict.txt。
(附:资源sDict.rar,解压后得到是sDict.txt文档,放入指定文件夹中)
构建树形词库实现代码如下:


using System; using System.Collections.Generic; using System.Text; using System.Collections; using System.Text.RegularExpressions; using System.IO; namespace Lucene.China { /// <summary> /// 词库类,生成树形词库 /// </summary> public class WordTree { /// <summary> /// 字典文件的路径 /// </summary> //private static string DictPath = Application.StartupPath + "\\data\\sDict.txt"; private static string DictPath = Environment.CurrentDirectory + "\\data\\sDict.txt"; /// <summary> /// 缓存字典的对象 /// </summary> public static Hashtable chartable = new Hashtable(); /// <summary> /// 字典文件读取的状态 /// </summary> private static bool DictLoaded = false; /// <summary> /// 读取字典文件所用的时间 /// </summary> public static double DictLoad_Span = 0; /// <summary> /// 正则表达式 /// </summary> public string strChinese = "[\u4e00-\u9fa5]"; public string strNumber = "[0-9]"; public string strEnglish = "[a-zA-Z]"; /// <summary> /// 获取字符类型 /// </summary> /// <param name="Char"></param> /// <returns> /// 0: 中文,1:英文,2:数字 ///</returns> public int GetCharType(string Char) { if (new Regex(strChinese).IsMatch(Char)) return 0; if (new Regex(strEnglish).IsMatch(Char)) return 1; if (new Regex(strNumber).IsMatch(Char)) return 2; return -1; } /// <summary> /// 读取字典文件 /// </summary> public void LoadDict() { if (DictLoaded) return; BuidDictTree(); DictLoaded = true; return; } /// <summary> /// 建立树 /// </summary> private void BuidDictTree() { long dt_s = DateTime.Now.Ticks; string char_s; StreamReader reader = new StreamReader(DictPath, System.Text.Encoding.UTF8); string word = reader.ReadLine(); while (word != null && word.Trim() != "") { Hashtable t_chartable = chartable; for (int i = 0; i < word.Length; i++) { char_s = word.Substring(i, 1); if (!t_chartable.Contains(char_s)) { t_chartable.Add(char_s, new Hashtable()); } t_chartable = (Hashtable)t_chartable[char_s]; } word = reader.ReadLine(); } reader.Close(); DictLoad_Span = (double)(DateTime.Now.Ticks - dt_s) / (1000 * 10000); System.Console.Out.WriteLine("读取字典文件所用的时间: " + DictLoad_Span + "s"); } } }
第二,构建一个支持中文的分析器,
需要停用词表 :String[] CHINESE_ENGLISH_STOP_WORDS,下面代码只是构造了个简单的停用词表。 (附资源:相对完整的停用词表stopwords.rar)
具体实现代码如下:
using System; using System.Collections.Generic; using System.Text; using Lucene.Net.Analysis; using Lucene.Net.Analysis.Standard; namespace Lucene.China { /**//// <summary> /// /// </summary> public class ChineseAnalyzer:Analyzer { //private System.Collections.Hashtable stopSet; public static readonly System.String[] CHINESE_ENGLISH_STOP_WORDS = new System.String[] { "a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "s", "such", "t", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with", "我", "我们" }; /**//// <summary>Constructs a {@link StandardTokenizer} filtered by a {@link /// StandardFilter}, a {@link LowerCaseFilter} and a {@link StopFilter}. /// </summary> public override TokenStream TokenStream(System.String fieldName, System.IO.TextReader reader) { TokenStream result = new ChineseTokenizer(reader); result = new StandardFilter(result); result = new LowerCaseFilter(result); result = new StopFilter(result, CHINESE_ENGLISH_STOP_WORDS); return result; } } }
第三,进行文本切分,文本切分的基本方法:输入字符串,然后返回一个词序列,然后把词封装成Token对象。
当然,要判断将要进行切分的词是中文、英文、数字还是其他。
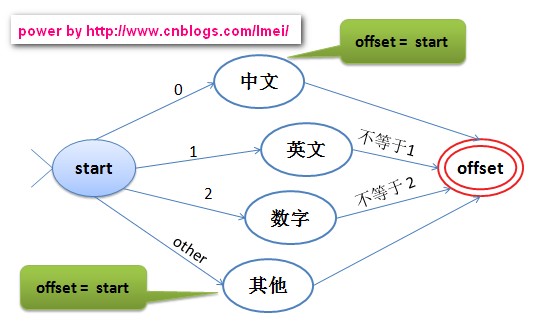
实现源码如下:
using System; using System.Collections.Generic; using System.Text; using Lucene.Net.Analysis; using System.Collections; using System.Text.RegularExpressions; using System.IO; namespace Lucene.China { class ChineseTokenizer : Tokenizer { private int offset = 0, bufferIndex = 0, dataLen = 0;//偏移量,当前字符的位置,字符长度 private int start;//开始位置 /// <summary> /// 存在字符内容 /// </summary> private string text; /// <summary> /// 切词所花费的时间 /// </summary> public double TextSeg_Span = 0; /// <summary>Constructs a tokenizer for this Reader. </summary> public ChineseTokenizer(System.IO.TextReader reader) { this.input = reader; text = input.ReadToEnd(); dataLen = text.Length; } /// <summary>进行切词,返回数据流中下一个token或者数据流为空时返回null /// </summary> /// public override Token Next() { Token token = null; WordTree tree = new WordTree(); //读取词库 tree.LoadDict(); //初始化词库,为树形 Hashtable t_chartable = WordTree.chartable; string ReWord = ""; string char_s; start = offset; bufferIndex = start; while (true) { //开始位置超过字符长度退出循环 if (start >= dataLen) { break; } //获取一个词 char_s = text.Substring(start, 1); if (string.IsNullOrEmpty(char_s.Trim())) { start++; continue; } //字符不在字典中 if (!t_chartable.Contains(char_s)) { if (ReWord == "") { int j = start + 1; switch (tree.GetCharType(char_s)) { case 0://中文单词 ReWord += char_s; break; case 1://英文单词 j = start + 1; while (j < dataLen) { if (tree.GetCharType(text.Substring(j, 1)) != 1) break; j++; } ReWord += text.Substring(start, j - offset); break; case 2://数字 j = start + 1; while (j < dataLen) { if (tree.GetCharType(text.Substring(j, 1)) != 2) break; j++; } ReWord += text.Substring(start, j - offset); break; default: ReWord += char_s;//其他字符单词 break; } offset = j;//设置取下一个词的开始位置 } else { offset = start;//设置取下一个词的开始位置 } //返回token对象 return new Token(ReWord, bufferIndex, bufferIndex + ReWord.Length - 1); } //字符在字典中 ReWord += char_s; //取得属于当前字符的词典树 t_chartable = (Hashtable)t_chartable[char_s]; //设置下一循环取下一个词的开始位置 start++; if (start == dataLen) { offset = dataLen; return new Token(ReWord, bufferIndex, bufferIndex + ReWord.Length - 1); } } return token; } } }
第四,编写测试demo的main函数,代码如下:
using System; using System.Collections.Generic; using System.Text; using System.Windows.Forms; using Analyzer = Lucene.Net.Analysis.Analyzer; using SimpleAnalyzer = Lucene.Net.Analysis.SimpleAnalyzer; using StandardAnalyzer = Lucene.Net.Analysis.Standard.StandardAnalyzer; using Token = Lucene.Net.Analysis.Token; using TokenStream = Lucene.Net.Analysis.TokenStream; namespace Lucene.China { class Program { [STAThread] public static void Main(System.String[] args) { try { // Test("中华人民共和国在1949年建立,从此开始了新中国的伟大篇章。长春市长春节致词", true); Test("hello world, a better day, never give up.", true); /*Test("一直在酝酿 new 一直在盼望 爸爸和妈妈唯一的理想 二月第一天 一九八一年 " + "我第一次对他们眨了眨眼 等待快点过去多少个明天" + "希望这个宝贝快快长大一点一点 身体要健康所有的事情都如所愿 Baby长大以后就是小轩" + "I will find my way I want a different way " + "I'll change the wind and rain There be a brand new day" + "小时候受伤有人心痛失落有人安慰 现在遇到困难自己就要学会面对", true); */ } catch (System.Exception e) { System.Console.Out.WriteLine(" caught a " + e.GetType() + "\n with message: " + e.Message + e.ToString()); } Application.EnableVisualStyles(); Application.SetCompatibleTextRenderingDefault(false); Application.Run(new Form1()); } internal static void Test(System.String text, bool verbose) { System.Console.Out.WriteLine(" Tokenizing string: " + text); Test(new System.IO.StringReader(text), verbose, text.Length); } internal static void Test(System.IO.TextReader reader, bool verbose, long bytes) { //Analyzer analyzer = new StandardAnalyzer(); Analyzer analyzer = new Lucene.China.ChineseAnalyzer(); TokenStream stream = analyzer.TokenStream(null, reader); System.DateTime start = System.DateTime.Now; int count = 0; for (Token t = stream.Next(); t != null; t = stream.Next()) { if (verbose) { System.Console.Out.WriteLine("Token=" + t.ToString()); } count++; } System.DateTime end = System.DateTime.Now; long time = end.Ticks - start.Ticks; System.Console.Out.WriteLine(time + " milliseconds to extract " + count + " tokens"); System.Console.Out.WriteLine((time * 1000.0) / count + " microseconds/token"); System.Console.Out.WriteLine((bytes * 1000.0 * 60.0 * 60.0) / (time * 1000000.0) + " megabytes/hour"); } } }
控制器输出显示:

可见被测试的文本为红色框里面所示。
测试结果:
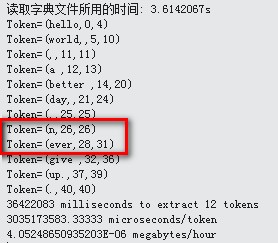
问题出现了,never被拆分成n,ever。于是测试多几次,发现只要是n开头的单词,n都会被拆开,如nnno,会变成n,n,n,o。
那么为什么会这样呢?
回想一下,之前我们构建了字典树。其实一般情况下我们会觉得说中文分析器所需要构建的字典树,当然就是纯文字,但是其实不是这样的。
打开sDict.txt文件,会发现下面这些词语:
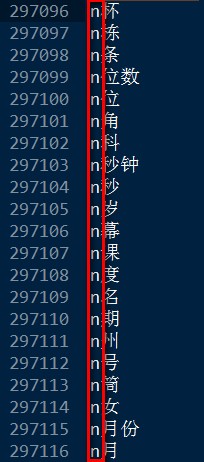
发现问题了吧!!!其实是包含字母的,所以英文单词的n总会被单独切分出来。
那么应该怎么解决呢??
解决方法,就是在sDict.txt文件中加入以n开头的单词表,这样就可以完美切分啦!!
测试一下吧!在文件中加入单词never,如下:
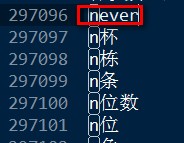
测试结果:
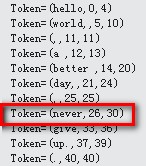
可见单词never已经完美切除。
接下来再来看另外一个在测试过程出现的问题,
测试文本如下:‘开’和‘始’中间有空格,且这段文本最后没有标点和空格。

测试结果如下:

依然完美切分,而且没有报错提示。
然后继续测试英文文本,如下:依然留空格,然后文本末尾没有空格跟标点。
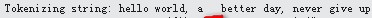
测试结果:出现异常

问题产生的原因是,英文是一个或多个单词相连的,如never,在判断第一个字母是属于英文的时候,会自动继续判断下一个,
当刚好这个单词是最后一个的时候,它依然会去查找下一个是否还是属于英文单词,这样文本要是以英文结束,且后面没有空格跟标点的话,
它就会出现超出索引的错误。
出现问题的代码是下面这句:在ChineseTokenizer.cs中
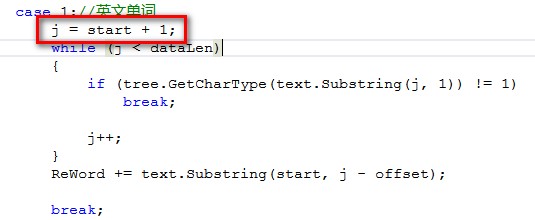
注:由于数字的切分和英文的切分采用的方法相同,所以也会出现同样问题
解决方法:就是在测试的文档的最后加上一个空格。因为空格不会影响到切分,所以只要把要切分的文本都进行事先处理,在文本末尾加多个空格给它,这样就不会出现上面异常。
懒人大礼包^_^
如果你不想进行上面那些多步骤,也是可以的。
第一,还是要把sDict.txt文件放到项目目录/bin/Debug/data文件夾中;
第二,下载Lucene.Fanswo.rar和Lucene.Net.rar,然后将Lucene.Fanswo.dll和Lucene.Net.dll添加到项目中;
注:Lucene.Fanswo.dll实现的功能跟上面写的一样,直接调用就行。
第三,编写Programs.cs测试代码
关键语句:
using Lucene.Fanswo;
创建支持中文的分析器,
Analyzer analyzer = new Lucene.Fanswo.ChineseAnalyzer();
完整代码如下:
using System; using System.Collections.Generic; using System.Text; using System.Windows.Forms; using Lucene.Fanswo; using Analyzer = Lucene.Net.Analysis.Analyzer; using SimpleAnalyzer = Lucene.Net.Analysis.SimpleAnalyzer; using StandardAnalyzer = Lucene.Net.Analysis.Standard.StandardAnalyzer; using Token = Lucene.Net.Analysis.Token; using TokenStream = Lucene.Net.Analysis.TokenStream; namespace Lucene.China { class Program { [STAThread] public static void Main(System.String[] args) { try { //Test("中华人民共和国在1949年建立,从此开 始了新中国的伟大篇章。长春市长春节致词", true); Test("hello world, a better day, never give up", true); /*Test("一直在酝酿 new 一直在盼望 爸爸和妈妈唯一的理想 二月第一天 一九八一年 " + "我第一次对他们眨了眨眼 等待快点过去多少个明天" + "希望这个宝贝快快长大一点一点 身体要健康所有的事情都如所愿 Baby长大以后就是小轩" + "I will find my way I want a different way " + "I'll change the wind and rain There be a brand new day" + "小时候受伤有人心痛失落有人安慰 现在遇到困难自己就要学会面对", true); */ } catch (System.Exception e) { System.Console.Out.WriteLine(" caught a " + e.GetType() + "\n with message: " + e.Message + e.ToString()); } Application.EnableVisualStyles(); Application.SetCompatibleTextRenderingDefault(false); Application.Run(new Form1()); } internal static void Test(System.String text, bool verbose) { System.Console.Out.WriteLine(" Tokenizing string: " + text); Test(new System.IO.StringReader(text), verbose, text.Length); } internal static void Test(System.IO.TextReader reader, bool verbose, long bytes) { //Analyzer analyzer = new StandardAnalyzer(); Analyzer analyzer = new Lucene.Fanswo.ChineseAnalyzer(); TokenStream stream = analyzer.TokenStream(null, reader); System.DateTime start = System.DateTime.Now; int count = 0; for (Token t = stream.Next(); t != null; t = stream.Next()) { if (verbose) { System.Console.Out.WriteLine("Token=" + t.ToString()); } count++; } System.DateTime end = System.DateTime.Now; long time = end.Ticks - start.Ticks; System.Console.Out.WriteLine(time + " milliseconds to extract " + count + " tokens"); System.Console.Out.WriteLine((time * 1000.0) / count + " microseconds/token"); System.Console.Out.WriteLine((bytes * 1000.0 * 60.0 * 60.0) / (time * 1000000.0) + " megabytes/hour"); } } }
测试过程中会发现如上问题,解决方法也是按上面的方式解决。
最后,附上完整测试demo项目源码下载,Lucene.China.rar
注:如果是下载项目源码,运行后发现有个空白窗体弹出,不要理它,关注控制台的输出。
@_@|| 终于写完了!!! ~_~zzZ
声明:转载请注明出处:http://www.cnblogs.com/lmei/p/3519242.html

