强化学习专题系列:第一讲 联合模型和无模型的强化学习算法

前言:
已经有一个多月没更新知乎的帖子了。本人在过去的一个多月干了很多“杂事”。其中包括在北京上了两天的线下强化学习课程,完稿了一本关于强化学习的书籍,题目暂定为《深入浅出强化学习》(电子工业出版社),估计十月份就能在市面上看到等等,总之一直在“瞎忙活”……。这周才有时间静下心来继续看论文和“搞研究”。
在过去的一个月,强化学习领域似乎也格外地热闹。先是谷歌deepmind于2017.7.7号连发3篇论文,向世人展示了强化学习可以教机器人完成像跑酷这样复杂的运动,既阿法狗之后,令世人再次惊呼。其所用的方法正是OpenAI的科学家在2016NIPS中发布的PPO算法。OpenAI的科学家们不甘落后,于是在2017年7月20号发表了它们的PPO论文,展示了更加复杂和智能的demo( https://blog.openai.com/openai-baselines-ppo/
), 前段时间,谷歌DeepMind与暴雪联合又开源了星际争霸2,提供了强化学习算法测试和研发的新平台……
强化学习研究领域不断有新的战场被开辟出来,各路高手纷纷入局。可以说这是一个还未封神的新世界,一块没有巨头垄断的新大陆,一个可以崭露头角,独霸一方的新位面……
可是,想要建功立业,不能光靠一腔热血,还得冬练三九,夏练三伏,踏踏实实地把内功练好,本专栏就是“练功秘籍”,想杀出一条血路的同学可参考练习。
从本节开始,本专栏开设强化学习的专题系列。每讲一个专题,每个专题会涉及几篇有代表性的论文。初步拟定的专题包括:
第一个专题:联合无模型和模型的强化学习算法。
第二个专题:多智能体强化学习
第三个专题:分层强化学习
第四个专题:迁移强化学习
第五个专题:元强化学习
第六个专题:强化学习的神经生物学原理。
针对这几个专题,欢迎知友向本专栏投稿。也欢迎大家留言自己想了解的专题。通过互联网,大家可互通有无。在吸收别人知识的同时贡献自己的知识,这样大家才能一起壮大起来。所以,欢迎大家向本专栏投稿,等专栏的帖子积累到一定程度,可考虑联合形成书籍,这样大家都是书的作者了……
好了,前言就到这里。
现在正式进入本系列的第一个专题,联合无模型和模型的强化学习算法。
首先,大家肯定会问的一个问题是:为什么要联合无模型的强化学习算法和基于模型的强化学习算法?
答案是:基于模型的强化学习算法和无模型的强化学习算法各有优缺点,将两种算法联合使用可以吸取两者的优点,从而让强化学习算法更实用。
那么,大家肯定会问了,这两种方法各有什么优缺点?如何联合?
这就是本讲要回答的两个问题。
第一个问题,基于模型的强化学习算法和无模型的强化学习算法各有什么优缺点?
首先看基于模型的强化学习算法
基于模型的强化学习算法是智能体通过与环境交互获得数据,根据数据学习和拟合模型,智能体根据模型利用强化学习算法优化自身的行为。
基于模型的强化学习算法的优点:由于智能体利用数据进行模型的拟合,因此智能体将数据进行了充分的利用,因为模型一旦拟合出来,那么智能体就可以根据模型来推断智能体从未访问过的区域。因为数据得到了最高的利用效率。智能体与环境之间的交互次数会急剧减少。基于模型的典型的代表是PILCO算法( https://zhuanlan.zhihu.com/p/27537744 )。用一个词来概括基于模型的强化学习算法就是 Data efficiency.
从基于模型的强化学习算法的过程我们也可以很容易看到它的缺点:拟合的模型存在偏差,因此基于模型的强化学习算法一般不能保证最优解渐近收敛。
我们再看无模型的强化学习算法
无模型的强化学习算法是指智能体从环境中获得的数据并不拟合环境模型,而是直接拿过来优化智能体的动作。
由于没有拟合环境模型,所以智能体对环境的感知和认知只能通过与环境之间不断的交互。因此需要大量地交互。这个交互量多大呢?比如倒立摆模型,要想稳定肯定,无模型的方法需要几万次的交互,对于雅达利游戏,则需要甚至百万次的交互。如此多的交互次数使得无模型的强化学习算法效率很低,而且难以应用到实际物理世界中。
然而,跟基于模型的强化学习算法相比,无模型的强化学习算法有一个很好的性质,该性质是渐近收敛。也就是说,无模型的强化学习算法经过无数次与环境的交互可以保证智能体得到最优解。
由于基于模型的强化学习算法和无模型的强化学习算法“半斤八两”,它们各自有优点也有缺点。一个很自然的想法是将两者的优点联合起来。
如何联合呢?
强化学习的先锋Sutton教授在1991年的时候就提出了联合两者的一个框架,即Dyna框架。
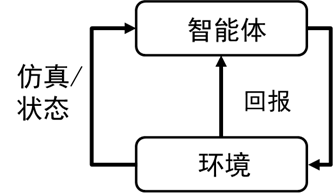
图1.1 Dyna框架
如图1.1为Dyna框架,跟一般的强化学习框架相比,Dyna框架多了仿真这一步。其实这一步就是拟合模型,并根据模型进行模拟。
Dyna结构不是一个具体的算法,而是一个组合模型和无模型算法的框架,其伪代码如图1.2所示。
从伪代码我们可以看到,Dyna的组成包括以下三个方面:
1. 运动模型的结构和学习方法的选择
2. 选择假想状态和动作的方法
3. 强化学习方法的选择
这三个方面,每个方面都有很多种方法,因此基于Dyna的结构可以有很多种算法。

图1.2 Dyna算法伪代码
伪代码中3和5.3都利用强化学习算法对值函数进行评估。因此,Dyna算法的本质可用图1.3所示。

图1.3 Dyna算法
从1.3中我们看到,基于模型的强化学习算法和无模型的强化学习算法是通过同时对值函数评估实现联合的。也就是说,智能体通过动作与环境进行交互得到真实的经验,该真实的经验一方面用来进行强化学习评估值函数,令一方面将该经验拿来拟合运动模型。当运动模型拟合后,利用拟合的运动模型进行模拟,智能体利用模拟的经验继续改进值函数。
Dyna框架的优势:
用来进行值函数训练的数据不仅仅来自于智能体与环境交互的真实经验,而且来自于模型模拟的数据,因此智能体进行强化学习所需要的数据来源多了,这样与环境之间的交互就不需要那么多了。
2008年,Silver和Sutton在Dyna的基础上发展出Dyna-2 . Dyna的想法是实际的经验和模拟的经验对同一个值函数进行估计。Dyna-2则进行了细分。即将实际经验估计的值函数用 \hat{q}_{mf} 表示,由模型模拟得到的经验估计的值函数用 \hat{q}_{mb} 表示,在实际应用中(即动作的选择)则使用两种方法得到的值函数估计的和。


图1.4 Dyna和Dyna-2比较
..............................................................................................................
Dyna-2的基本思想:
Dyna-2将记忆分为永久性记忆(permanent memory)和瞬时记忆(transient memory), 其中永久性记忆利用实际的经验来更新,瞬时记忆利用模型模拟经验来更新。真实的经验数据所服从的分布称为学习分布;模拟经验数据所服从的分布称为搜索分布。
Dyna-2的基本思想是在选择实际的执行动作前,智能体先执行一遍从当前状态开始的基于模型的模拟,该模拟将仿真完整的轨迹,以便评估当前的动作值函数。智能体会根据模拟得到的动作值函数加上实际经验得到的值函数共同选择实际要执行的动作。


图1.5 Dyna-2伪代码
如图1.5为Dyna-2的伪代码,我们对该伪代码进行详细地解释。
[1] 开始学习过程
[2] 初始化运动模型和回报函数
[3] 清除永久性记忆。这里所谓的永久性记忆是实际经验估计的值函数所对应的参数
[4] 进入学习的循环
[5] 从初始状态开始一次尝试
[6] 每个episode都需要清除一次瞬时记忆,因为瞬时记忆只在一个episode内有效。
[7] 清除资格迹
[8] 对于每个episode的初始状态,执行一次模拟(即从初始状态开始利用当前的模型执行模拟。其目的是更新值函数。)
[9]基于模拟更新的值函数和要评估的策略选择一个动作
[10] 如果当前状态不是终止状态,则进入如下循环
[11] 执行动作,并从环境中观测执行动作后环境实际返回的回报和后继状态
[12] 利用后继状态,动作和回报更新模型和回报,该步涉及到模型的拟合。
[13] 利用新拟合的模型从后继状态开始进行模拟,更新值函数
[14] 利用更新的值函数和策略选择下一步实际要执行的动作。
[15] 利用实际经验计算永久记忆所对应的值函数的TD偏差
[16] 利用TD偏差更新永久记忆所对应的值函数的参数
[17] 更新资格迹
[18] 智能体转移到后继状态
[19] 结束一次episode
[20] 结束循环学习
[21] 结束程序
利用想象轨迹加速学习
如果用一句话来概括Dyna及Dyna-2的基本思想就是这句话:利用想象轨迹加速无模型的学习,这里的想象轨迹是模型模拟出来的。Gu等于2016年发表论文《Continuous
Deep Q-learning with Model-based Acceleration》对Dyna框架进行了新的发展。
Dyna框架在提出来时就提出了很多开放性问题,其中最关键的开放性问题是如何利用拟合的模型产生样本,以及产生什么样的样本。
Dyna和Dyna-2利用模型所产生的样本都是相同策略的样本。一个更广泛的空间是利用模型产生异策略的样本。比如,基于模型我们利用规划方法或轨迹最优方法如iLQG可以产生最优的轨迹。这些轨迹都是在模型下最好的数据。利用这些数据可以引导智能体进行高效地探索。
然而,这个想法虽然好。可是,若将这些好的轨迹数据和要评估和改善的策略所产生的轨迹放在一起利用Q-learning的方法对智能体进行训练时,算法并不稳定,而且策略改善的效果很小。
这个现象背后的原因是基于iLQG所产生的好的数据的策略与要改善的策略太不相同了。Q-learning要想成功本质上需要带噪音的同策略动作。
对于机器人和自动驾驶,该方法是不可行的。因为Q-learning方法要想成功需要具备两个条件:
(1) 除了好的异策略样本,也需要大量的同策略经验。
(2) 智能体需要亲自犯错,而有些动作极具损坏性,现实中不可能实现。
既然在现实世界中不可能实现,那么完全可以利用学到的模型去模拟。因此,Gu等人提出“imagination rollouts”也就是假想轨迹。将真实轨迹和模拟的iLQG轨迹和模拟的策略轨迹混合起来然后利用Q-learning的方法进行训练。从这个意义上来说,Gu的方法是传统Dyna方法的变种。
当拟合的模型不精确时,想象的轨迹会产生严重的偏差。Gu等发现利用迭代重拟合时变线性动力学的方法可以起到很好的效果。作者发现,基于模型的方法优势只在学习过程的早期阶段可以体现出来,而随着迭代次数的增加,无模型的强化学习算法性能比基于模型的方法要好,所以作者提出在一定数目的迭代后,关掉想象轨迹,而只用无模型的强化学习算法。


图1.6 利用模型加速学习伪代码
如图1.6为利用模型进行加速学习的伪代码。需要注意的是产生轨迹的策略为同策略和异策略iLQG。
利用基于模型的强化学习算法来初始化无模型的强化学习算法
就像Gu在它的工作中观察的那样,基于模型的强化学习算法只是在最初的迭代步的表现强于无模型的强化学习算法。其实,这也容易理解。因为随着迭代次数的增加,基于模型的强化学习算法,模型偏差可能越来越大,而无模型的强化学习则具有渐近最优的特性,也就是说迭代步数越多,无模型的强化学习算法对环境的探索越成熟,因此性能会更好。
一个很自然的联合方式是将基于模型的强化学习算法初始化无模型的强化学习算法。如Gu的论文中,基于Dyna的结构是一种方法,但绝不是唯一的一种方法。Nagabandi等在2017年8月份发出一篇论文《Neural Network Dynamics for Model-Based Deep Reinforcement Learning
with Model-free Fine-Tuning》中则并未采样Dyna的结构,而是利用监督学习训练无模型的策略网络。
该论文最大的贡献在于提出一种新的基于模型的强化学习算法,并将该算法初始化无模型强化学习的策略网络。
下面我们对该论文的主要核心内容做简单的介绍。
1. 利用神经网络拟合动力学模型
基于模型的强化学习方法是利用数据拟合模型,在Dyna的框架中,模型的拟合也是其不可缺少的一环,而且是算法效果好坏的关键。Gu在他的工作中也阐述了这一点,他们使用的模型拟合方式是迭代重拟合的方法,该方法是局部线性拟合;基于模型的强化学习中效率最高的是PILCO,在PILCO中模型拟合方法是高斯回归过程,但是该方法难以应用到高维系统中。作者提出,利用神经网络来拟合动力学模型。但作者并非直接拟合后继状态与当前状态及动作的非线性关系,而是拟合状态变化与当前状态和动作的非线性关系。即:
\hat{s}_{t+1}=s_t+\hat{f}_{\theta}\left(s_t,a_t\right)
2. 设置优化目标,对神经网络动力学模型进行训练
在第一步,我们已经将动力学模型进行参数化了(参数化的是状态差),第二步就需要设置损失函数,从而利用随机梯度下降法求得最优参数。
给定智能体的轨迹数据 \tau =\left(s_0,a_0,\cdots ,s_{T-2},a_{T-2},s_{T-1}\right) ,损失函数为:
\[ \mathcal{E}\left(\theta\right)=\frac{1}{\left|\mathcal{D}\right|}\sum_{\left(s_t,a_t,s_{t+1}\right)}{\frac{1}{2}\lVert\left(s_{t+1}-s_t\right)-\hat{f}_{\theta}\left(s_t,a_t\right)\rVert^2} \]
尽管该损失函数提供了估计我们学到的动力学函数在预测下一个状态多好。但是,我们实际上想要知道的是我们的模型能多好地预测将来,而不是下一个状态。
因为我们将主要利用该模型预测长期的控制。对于每个真实动作序列 \left(a_t,\cdots ,a_{t+H-1}\right) ,我们比较相应的状态序列 \left(s_{t+1},\cdots ,s_{t+H}\right) 和动力学模型的多步状态预测 \left(\hat{s}_{t+1},\cdots ,\hat{s}_{t+H}\right) 的差别,所以需要构建如下的损失函数:
\[ \mathcal{E}_{val}^{\left(H\right)}=\frac{1}{\mathcal{D}_{val}}\sum_{\mathcal{D}_{val}}{\frac{1}{H}\sum_{h=1}^H{\frac{1}{2}\lVert s_{t+h}-\hat{s}_{t+h}\rVert^2}}; \\ \hat{s}_{t+h}=\left\{\begin{array}{c} s_t, h=0\\ \hat{f}_{\theta}\left(\hat{s}_{t+h-1},a_{t+h-1}\right)\ h>0\\ \end{array}\right. \]
3. 基于MPC的最优控制
有了模型,我们便可以利用模型得到最优策略了。问题形式化为:
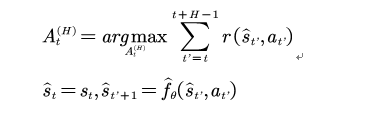
由于我们采用的模型是神经网络模型,该问题没有解析解。一种可行的方法是采用shooting的方法。所谓shooting的方法中文翻译为打靶的方法,就是迭代数值尝试:
具体的方法为:
随机产生K个候选动作序列,然后将这些动作序列作用于环境,利用学到的神经网络动力学模型预测相应的状态序列和回报。那些拥有最高期望累积回报的序列被选择。这些被选择的动作序列并非都被执行,而是只执行一步 a_t ,然后在环境中观察在此动作下新状态信息 s_{t+1} ,然后利用该方法(shooting方法)重复得到下一步的动作序列。
4. 利用强化学习改善基于模型的控制
第1到第3步,我们先完成了模型训练,然后基于模型得到了最优控制率。这种顺序执行的方法有一个问题:第2步模型的拟合所用的数据集跟我们优化轨迹的数据集并非一个数据集,因此导致了拟合的模型具有偏差。一种解决的方法是模型拟合的数据集应该包含优化时所用的数据集。


图1.7 基于模型强化学习方法伪代码
如图1.7所示为基于模型强化学习方法的伪代码,需要注意的是模型拟合所用的数据集包括随机轨迹数据集合最优轨迹数据集。
得到最优策略后便可以利用监督学习对无模型的强化学习策略网络进行监督学习,最后得到的网络参数作为无模型强化学习策略网络的初始化参数。之后利用TRPO等方法进行无模型强化学习。
参考文献
[1] Sutton R S. Dyna, an integrated architecture for
learning, planning, and reacting[J]. Acm Sigart Bulletin, 1991, 2(4):160-163.
[2] Silver D, Sutton R S, Müller M. Sample-based learning and
search with permanent and transient memories[C]// International Conference on
Machine Learning. ACM, 2008:968-975.
[3] Gu S,
Lillicrap T, Sutskever I, et al. Continuous Deep Q-Learning with Model-based
Acceleration[J]. 2016:2829-2838.
[4] Nagabandi A, Kahn G, Fearing S R, Levine S.
Neural Network Dynamics for Model-Based Deep Reinforcement Learning with
Model-free Fine-Tuning arXiv:1708.02596
2017.8.17更新
如果对你有帮助请赞赏
未完待续......
