各种机器学习算法的应用场景分别是什么(比如朴素贝叶斯、决策树、K 近邻、SVM、逻辑回归最大熵模型)?


写在前边,其实这些算法在工作中实际使用的频率并不大,很多情况下都是几个算法联合起来,或者使用某一算法的改进版本。
19年才来单位的时候,当时的项目是基于电力负控数据寻找用电行为异常的用户,并根据行为异常的用户数据进行异常原因的分类。很显然,这一工作前提是找出异常,业务人员配合打上标签,然后进行多分类。(也尝试过无监督的分类,但是分类结果并不能直接反馈异常的原因。)
电力负控数据每天有96个点位,最终确定的判断异常的逻辑规则为(举个例子),当天异常点数超过80%则全天判定为异常。异常点的判断,同行业,每个季度会计算一条用电的标准曲线,根据甲方业务人员的经验值,会提供一个最大值和最小值的范围。超出范围则判定异常。(涉及保密,简单复述一下逻辑)。
当时我开发了整个异常判定的逻辑算法,目前来看,异常识别率在85%左右。
原因分析就好做了,用CNN抽了特征矩阵,加上某些特定的数据特征,放在random forest中,效果还算理想,80%左右。
所以在实际的工作中,单个的算法可能并不适合特定的工作场景,业务经验很重要,建模分析的经验也很重要。
正好前段时间看了一些基本机器学习算法的原理和机制。因为才做了分类,那就从分类器的角度说一下自己的理解吧。下图是监督学习的简单概述。
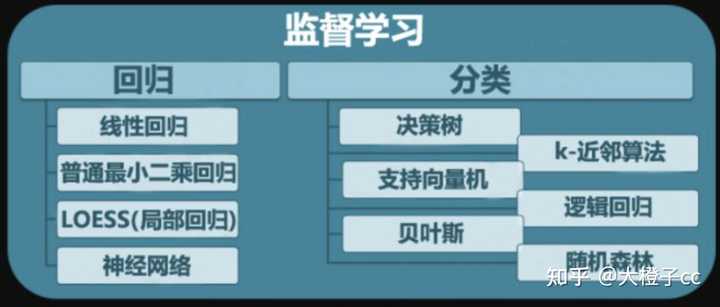

(一)朴素贝叶斯分类
朴素贝叶斯分类是基于贝叶斯定理与特征条件独立假设的分类方法,发源于古典数学理论,拥有稳定的数学基础和分类效率。
贝叶斯分类算法的实质就是计算条件概率的公式。在事件 B 发生的条件下,事件 A 发生的概率为 P(A | B)来表示。
1、优点
(1)算法的逻辑性十分简单,并且算法较为稳定
(2)数据集属性之间的关系相对比较独立时,朴素贝叶斯分类算法会有较好的效果。
2、缺点
(1)数据集独立性很难满足。
3、应用场景
文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等。
(二)支持向量机(SVM)
支持向量机是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
1、优点
(1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;
(2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心;
(3)支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。
2、缺点
(1) SVM算法对大规模训练样本难以实施;
(2) 用SVM解决多分类问题存在困难
3、应用场景
字符识别、面部识别、行人检测、文本分类等。
(三)随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。随机森林是一种灵活的、便于使用的机器学习算法,即使没有超参数调整,大多数情况下也会带来好的结果。
1、优点
(1)它能够处理很高维度(feature很多)的数据,并且不用做特征选择(因为特征子集是随机选择的);
(2)在训练完后,它能够给出哪些feature比较重要;
(2)训练速度快,容易做成并行化方法(训练时树与树之间是相互独立的);
(3)对于不平衡的数据集来说,它可以平衡误差,如果有很大一部分的特征遗失,仍可以维持准确度。
2、缺点
(1) 随机森林处理回归问题时表现欠佳;
(2) 对于小数据或者低维数据(特征较少的数据),可能不能产生很好的分类。
3、应用场景
文本分类、数据挖掘、信用监测等。
好啦。大致上先说这三个吧,等有时间再一一叙述主要原理,感兴趣可关注我后续文章或者回答~~~
怎么学呢?语言是基础,至少要学会合理使用sklearn或者tensorflow,学会调参。下边放3个机器学习简单的小项目供参考:
2、用电敏感客户分类
欢迎点赞收藏关注,让更多人看到。谢谢~~~