
大型神经语言模型的对抗性训练

原文:Adversarial Training for Large Neural Language Models
作者: Xiaodong Liu , Hao Cheng
源码:https://github.com/namisan/mt-dnn

一、简介
二、预备知识
---- 2.1 输入表示法
---- 2.2 模型结构
---- 2.3 自监督
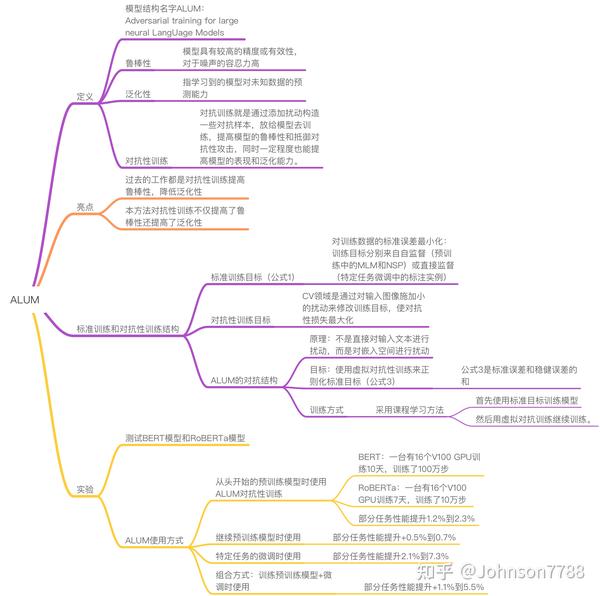
三、ALUM(大型神经LangUage模型的对抗性训练)
---- 3.1 标准训练目标
---- 3.2 对抗性训练
---- 3.3 ALUM算法
---- 3.4 泛化性与鲁棒性
四、实验
---- 4.1 数据集
---- 4.2 实施细节
---- 4.3 提高泛化性
---- 4.4 提高鲁棒性
---- 4.5 结合对抗性预训练和微调
五、总结
参考文献
一、简介
泛化性和鲁棒性都是设计机器学习方法的关键要求。对抗性训练可以提高鲁棒性,但过去的工作经常发现它损害了泛化性。在自然语言处理(NLP)中,预训练的大型神经语言模型,如BERT,在各种任务中表现出令人印象深刻的泛化增益,并通过对抗性微调进一步改善。然而,这些模型仍然容易受到对抗性攻击。在本文中,我们表明,对抗性预训练可以提高泛化性和鲁棒性。我们提出了一种通用的算法ALUM(大型神经LangUage模型的对抗性训练),它通过在嵌入空间中应用扰动来规范训练目标,使对抗性损失最大化。我们首次全面研究了对抗性训练的各个阶段,包括从头开始的预训练、在训练好的模型上持续的预训练以及特定任务的微调。在广泛的NLP任务中,ALUM比BERT在常规和对抗性场景中都获得了巨大的收益。即使是那些在极其庞大的文本语料库中训练过的模型,如RoBERTa,ALUM仍然可以从持续的预训练中产生巨大的收益,而传统的非对抗性方法则不能。ALUM可以进一步与特定任务的微调相结合,以达到额外的收益。ALUM的代码可在https://github.com/namisan/mt-dnn。
泛化性和鲁棒性是评估机器学习方法的两个基本考虑。理想情况下,一个学习的模型应该在未见过的测试实例上表现良好,并能抵御对抗性攻击。在自然语言处理(NLP)中,在未标注的文本上预训练神经语言模型已被证明对提高各种下游任务的泛化性能非常有效,BERT(Devlin等人,2018)和其他基于transformer的模型(Liu等人,2019c;Radford等人,2018;Clark等人,2020;Dong等人,2019;Bao等人,2020)就是例子。然而,这些模型在对抗性场景中仍然可能遭受灾难性的失败(Nie等人,2019;Hsieh等人,2019)。例如,Jin等人(2019)表明,在Yelp数据集上,BERT模型的分类精度从标准测试的95.6%下降到鲁棒测试的6.8%。
对抗性训练(Madry等人,2017;Goodfellow等人,2014)在计算机视觉中得到了很好的研究,但过去的工作表明,它往往会伤害到泛化(Raghunathan等人,2019;Min等人,2020)。在NLP中,人们对对抗性训练的兴趣越来越大,但现有的工作通常侧重于评估对泛化的影响(Zhu等人,2019;Jiang等人,2019;Cheng等人,2019;Wang等人,2019)。此外,对抗性训练一般仅限于特定任务的微调。见Minaee等人(2020a)的最新调查。
在本文中,我们提出了第一个关于对抗性预训练的全面研究,并表明它可以提高广泛的NLP任务的泛化性和鲁棒性。我们提出了一个统一的算法ALUM(Adversarial training for large neural LangUage Models),它通过在嵌入空间中应用扰动来增加标准训练目标,使对抗性损失最大化。ALUM一般适用于预训练和微调,在任何基于transformer的语言模型之上。
我们对多个基准数据集的各种NLP任务进行了综合评估,包括GLUE、SQuAD v1.1/v2.0、SNLI、SciTail,以评估模型的泛化;ANLI、HELLSWAG、SWAG、Adversarial SQuAD,以评估模型的鲁棒性。实验结果表明,通过进行对抗性的预训练,ALUM获得了明显的改进,往往比以前的技术水平要好得多。即使是训练过的RoBERTa模型也是如此,在没有对抗性训练的情况下,持续的预训练未能获得任何收益。
值得注意的是,除了提高泛化能力外,我们发现对抗性预训练也大幅提高了鲁棒性,例如在对抗性数据集(如ANLI、Adversarial-SQuAD、HELLASWAG)中产生的巨大收益,这大大减少了BERT和RoBERTa等流行模型的标准误差和鲁棒误差之间的差距。这表明,在无标签数据上进行对抗性训练可以提供一个有希望的方向,以调和先前工作中观察到的泛化和鲁棒性之间的明显冲突(Raghunathan等人,2019;Min等人,2020)。我们还表明,对抗性预训练可以与对抗性微调相结合,从而产生额外的收益。
我们的贡献总结如下。
- 我们提出了ALUM,一种结合对抗性训练的通用算法,用于对大型神经语言模型进行预训练和微调。
- 我们对广泛的NLP任务进行了综合评估,并评估了对抗性训练在从头开始的预训练、继续的预训练、特定任务的微调及其组合中的影响。
- 与之前的技术水平相比,我们在泛化和鲁棒性方面都获得了明显的改进,包括像RoBERTa这样训练过的模型。
- 为了促进研究,我们将发布我们的代码和预训练的模型。
二、预备知识
在这一节中,我们以BERT(Devlin等人,2018)作为基于transformer的神经语言模型的运行实例,对语言模型的预训练进行了简单的概述。
2.1 输入表示法
我们假设输入由文本跨度(通常是句子)组成,由一个特殊的token[SEP]分开。为了解决未登录词的问题,token被分为子词单元,使用字节对编码(BPE)(Sennrich等人,2015)或其变体(Kudo和Richardson,2018),产生一个固定大小的子词单词表,以紧凑地表示训练文本语料中的单词。
2.2 模型结构
按照最近的预训练方法(Devlin等人,2018;Liu等人,2019c),我们使用基于transformer的模型(Vaswani等人,2017)来利用多头注意力机制,与LSTM(Hochreiter和Schmidhuber,1997)等循环神经网络相比,这种机制在并行计算和建模长距离依赖方面表现出优势。输入首先被传递到一个词汇编码器,它通过元素相加将token嵌入、(token)位置嵌入和片段嵌入(即该token属于哪个文本跨度)结合起来。然后,嵌入层被传递给多层transformer模块,以生成上下文表述(Vaswani等人,2017)。
2.3 自监督
BERT(Devlin等人,2018)的一个关键创新是使用mask语言模型(MLM)进行自监督的预训练。MLM不是像传统的生成语言模型那样根据前面的token预测下一个token,而是用一个特殊的token(例如[MASK])随机替换一个token子集,并要求模型预测它们。本质上,它是一个cloze任务(Taylor, 1953),训练目标是原始token和预测token之间的交叉熵损失。在BERT和RoBERTa中,选择了15%的输入token,其中80%被随机替换为[MASK],10%保持不变,10%被随机替换为单词表中的一个token。在我们的实验中,我们没有使用固定的15%的mask率,而是将其从5%逐渐增加到25%,每20%的训练epoch增加5%,因为我们发现这使得预训练更加稳定。
此外,BERT还使用了下一句话预测(NSP),这是一个二分类任务,对于给定的句子对,确定一个句子是否在原文中紧跟另一个。对于NSP的帮助有多大,人们有争论(Liu等人,2019c)。但我们将其纳入我们的实验中,以便与BERT进行公平的比较。
三、ALUM(大型神经LangUage模型的对抗性训练)。
在本节中,我们首先介绍了标准训练目标和先前的对抗性训练方法的统一观点。然后,我们提出了ALUM,它是一种适用于预训练和微调的通用对抗性训练算法,在任何基于transformer的神经语言模型之上。
3.1 标准训练目标
预训练和微调都可以被看作是对训练数据的标准误差最小化,训练目标分别来自自监督(预训练中的MLM和NSP)或直接监督(特定任务微调中的标注实例)。
具体来说,训练算法试图学习→一个函数 f(x;θ): x \rightarrow C ,以θ为参数。在MLM中,C是单词表,f(x;θ)试图预测被mask的token y。给定输入-输出对(x,y)的训练数据集D和损失函数l(., .)(如交叉熵),f (x; θ)被训练为最小化经验风险。
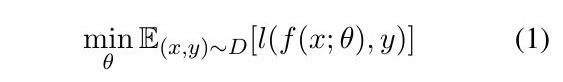

3.2 对抗性训练
事实证明,预训练大型神经语言模型,如BERT,可以有效地提高特定任务微调的泛化性能(Devlin等人,2018)。然而,这样的模型在对抗性场景中仍然会遭受灾难性的损失(Nie等人,2019;Hsieh等人,2019;Madry等人,2017;Jin等人,2019),攻击方式简单到在输入句子中替换几个词,同时保留语义。
为了提高模型的鲁棒性和抵御对抗性攻击,对抗性训练已经被广泛提出和研究,主要是在计算机视觉文献中(Goodfellow等人,2014;Madry等人,2017)。其关键思想是通过对输入图像施加小的扰动来修改训练目标,使对抗性损失最大化。
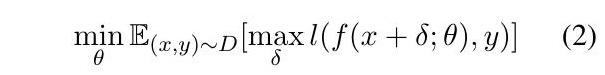

其中内部最大化可以通过运行一些投影梯度下降步来解决(Madry等人,2017)。
虽然对抗性训练在缓解对抗性攻击方面取得了成功,但过去的工作经常遇到泛化和鲁棒性之间的明显冲突(Raghunathan等人,2019,2020;Min等人,2020),因为对抗性训练可能伤害泛化性能。
3.3 ALUM算法
在NLP中,应用对抗性训练并不简单,因为输入是离散的元素(token或子词序列),但最近有一些成功案例(Zhu等人,2019;Jiang等人,2019;Cheng等人,2019;Wang等人,2019;Minaee等人,2020b)。然而,除了Wang等人(2019),之前还没有任何关于对抗性预训练的工作,Wang等人(2019)只将对抗性训练应用于使用LSTM的生成性语言模型。
ALUM同时适用于预训练和微调。它建立在几个关键的想法上,这些想法在之前的工作中已经被证明是有用的。首先,我们不是直接对输入文本进行扰动,而是对嵌入空间进行扰动。也就是说,x是f(x;θ)中的子词嵌入(Jiang等人,2019;Zhu等人,2019)。
其次,我们没有像Zhu等人(2019)和其他大多数方法那样采用公式2的对抗性训练目标,而是跟随Jiang等人(2019)使用虚拟对抗性训练(Miyato等人,2018)来正则化标准目标。
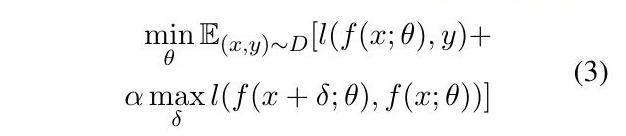

实际上,对抗项有利于嵌入邻域的标签平滑性,而α是一个超参数,控制标准误差和稳健误差之间的权衡。
我们发现,虚拟对抗训练优于传统的对抗训练,尤其是在标签可能有噪声的情况下。例如,BERT预训练使用被masked的词作为自监督的标签,但在许多情况下,它们可以被其他词取代,形成完全合法的文本。从经验上看,我们验证了这种情况确实存在,因为预训练从较大的α中受益。我们在所有的实验中都将α=10用于预训练,α=1用于微调。
与标准训练相比,由于内部最大化,对抗性训练的成本相当高。Zhu等人(2019)采用了Shafahi等人(2019)的自由对抗训练思想进行加速,通过重用梯度计算的反向传递来同时进行内上升步和外下降步。受ERNIE(Sun等人,2019)和其他持续预训练方法的启发,我们转而采用课程学习方法:首先使用标准目标(1)训练模型;然后用虚拟对抗训练(3)继续训练。
Jiang等人(2019)还使用Bregman近似点方法纳入了一个动量项,这在训练时间上会有相当大的代价。我们发现,我们的课程学习方法在很大程度上使之成为不必要的,并且简化了我们的算法,没有使用这个术语。


算法1显示了ALUM的细节。第4-6行运行K个投影梯度步,以找到使对抗性损失(违反局部平稳性)最大化的扰动δ。请注意,更大的K会导致更好的近似(Madry等人,2017;Qin等人,2019),但它更昂贵。为了在速度和性能之间达到良好的权衡,我们在所有的实验中都设定K=1。
3.4 泛化性与鲁棒性
从经验上看,我们发现,通过使用ALUM进行对抗性预训练,我们能够改善广泛的NLP任务的泛化和鲁棒性,如第4节所示。这是非常有趣的,因为之前的工作经常发现对抗性训练会损害泛化,即使有理论依据(Raghunathan等人,2019,2020;Min等人,2020)。
我们假设对抗性预训练可能是调和这种明显不一致的关键,因为之前关于泛化和鲁棒性之间的冲突的工作通常集中在有监督的学习环境中。有趣的是,一些调和这两者的新生成果也利用了无标签数据,如self-training(Raghunathan等人,2020)。此外,我们假设,通过扰动嵌入空间而不是输入空间,NLP中的对抗性训练可能会无意中偏向于流扰动而不是常规扰动,这有助于泛化(Stutz等人,2019)。我们将所有这些联系的理论分析留给未来的工作。
四、实验
在本节中,我们介绍了对大型神经语言模型的对抗性训练的全面研究。我们表明,在广泛的NLP任务中,对于标准的BERT模型和训练过的RoBERTa模型,ALUM都大幅提高了泛化性和鲁棒性。我们还表明,ALUM同样可以应用于对抗性预训练和微调,并通过将两者结合起来获得进一步的收益。
4.1 数据集
预训练:对于BERT的预训练,我们使用维基百科(英文维基百科dump2;13GB)。对于RoBERTa的持续预训练,我们使用维基百科(13GB),OPENWEBTEXT(公共Reddit内容(Gokaslan和Cohen);38GB),STORIES(CommonCrawl的一个子集(Trinh和Le,2018);31GB)。
NLP应用基准:为了评估对抗性训练对泛化的影响,我们使用标准基准,如GLUE(Wang等人,2018)和SQuAD(v1.1和v2.0)(Rajpurkar等人,2016,2018),以及生物医学领域的三个命名实体识别(NER)任务。为了评估对抗性训练对鲁棒性的影响,我们使用ANLI(Nie等人,2019)、对抗性SQuAD(Jia和Liang,2017)和HELLASWAG(Hampel,1974)。为了评估对抗性预训练和微调的结合,我们跟随Jiang等人(2019),使用MNLI(Williams等人,2018)(来自GLUE)、ANLI、SWAG(Zellers等人,2018)、SNLI(Bowman等人,2015)、SciTail(Khot等人,2018)。这些基准涵盖了广泛的NLP任务,如命名实体识别、文本蕴含和机器阅读理解,横跨分类、排名和回归。详情请见附录A。
4.2 实施细节
我们在实验中进行了三种类型的对抗性训练:从头开始的预训练,在训练好的模型上持续的预训练,以及特定任务的微调。
我们使用维基百科从头开始预训练BERT模型。训练代码基于Megatron,在PyTorch(Shoeybi等人,2019)中实现。我们使用ADAM(Kingma和Ba,2014)作为优化器,其标准学习率,计划在前百分之一的步中从零线性增加到 1 \times 10^{-4} 的峰值学习率,然后在其余99%的步中线性衰减到零。按照Devlin等人(2018)的做法,训练了100万步,批次大小为256。我们设定扰动大小 ε=1 \times 10^{-5} ,步大小 η=1 \times 10^{-5} ,初始化扰动的方差 σ=1 \times 10^{-5} 。在虚拟对抗训练中,我们设置α=10以提高正则化程度,并设置K=1以提高训练效率(即一个投影梯度步)。训练在一台有16个V100 GPU的DGX-2机器上需要10天。
对于RoBERTa(Liu等人,2019c)的持续预训练,我们使用RoBERTa的默认训练参数,除了较小的学习率( 4 \times 10^{-5} ),并在Wikipedia、OPENWEBTEXT和STORIES(总大小为82GB)的联盟上运行100K训练步,批次大小为256。代码是基于FairSeq5的。训练在两台DGX-2机器上进行,需要7天时间。
对于有无对抗性训练的微调,我们使用MT-DNN开源工具包(Liu等人,2020,2015)6。我们跟随Jiang等人(2019)进行头对头比较,使用ADAM(Kingma和Ba,2014)和RADAM(Liu等人,2019a)作为我们的优化器,峰值学习率为{5×10-6,8×10-6,1×10-5,2×10-5},批次大小为16、32或64,取决于任务。
除了MNLI的0.3和CoLA的0.05之外,所有特定任务层的dropout rate都设置为0.1。为了避免梯度爆炸,梯度被剪掉,以保持范式在1以内。所有的文本都使用WordPiece进行tokenized,并切成512个tokens。我们进行10个 epochs微调,并使用dev set挑选出最佳模型。
4.3 提高泛化性
在本小节中,我们通过比较预训练模型在各种下游应用中的表现,研究对抗性预训练对泛化的影响。首先,我们通过比较三个BERT模型来研究从头开始预训练的情况。
- BERTBASE是标准的BERT基础模型,使用与Devlin等人(2018)相同的设置进行训练(即1M步,批次大小为256)。
- BERT+BASE与BERT相似,除了是用1.6M步训练的,这与对抗性预训练的时间大致相同(见下面的ALUMBERT-BASE)。
- ALUMBERT-BASE是一个使用与BERTBASE相同的设置训练的BERT模型,只是在最后的500K步中使用了ALUM。每个对抗性训练步比标准训练中的一个步大约长1.5倍7。
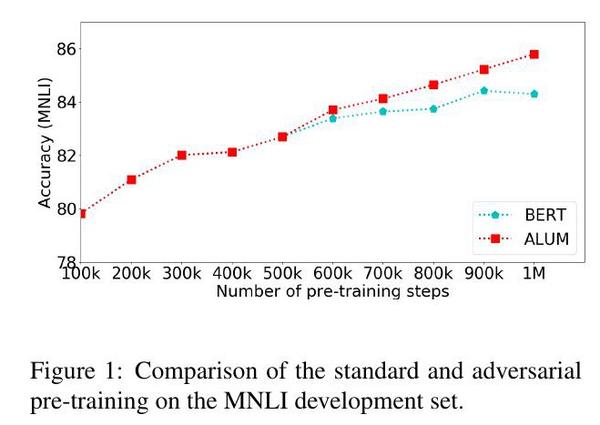
表1在三个标准基准(SQuAD v1.1(Rajpurkar等人,2016)和v2.0(Rajpurkar等人,2018),以及GLUE(Wang等人,2018)的MNLI)上比较了这些预训练的模型,使用相同的标准微调设置(没有对抗性训练)。只使用维基百科数据训练的标准BERT模型获得了与Devlin等人(2018)类似的结果,因此提供了一个良好的比较基线。ALUMBERT-BASE在所有数据集上的表现一直优于标准BERT模型,即使调整了稍长的训练时间。例如,在SQuAD v1.1上,ALUMBERT-BASE在F1中比BERTBASE提高了2.3%,比BERT+BASE提高了1.2%。图1显示了ALUM在MNLI的开发集上的工作。一旦在中间应用对抗性训练(在前50万步之后),ALUM就开始超过BERT,而且差距越来越大。

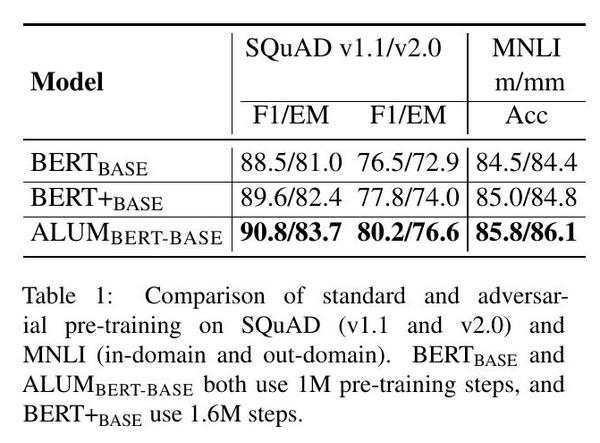

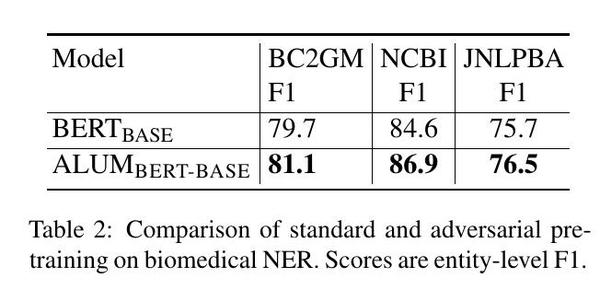
我们还评估了生物医学领域中对抗性预训练的影响,这与预训练中使用的维基百科语料库有很大不同。表2显示了标准生物医学名称实体识别(NER)数据集的结果。BC2GM(Smith等人,2008),NCBI(Dogan等人,2014),JNLPBA(Collier和Kim,2004)。有趣的是,ALUM在所有三个任务上的表现仍然优于标准的BERT模型,尽管应用领域与预训练的领域有很大的不同。

接下来,我们评估了对抗性训练在继续预训练环境中的影响。我们使用我们的预训练数据集(Wikipedia, OPENWEBTEXT, STORIES; 82GB)8,并在我们所有的持续预训练实验中运行100K步。我们选择RoBERTa模型作为基线,它使用与BERT相同的神经模型,但在一个数量级的文本上进行了预训练(160GB对13GB)。它们是最先进的预训练语言模型,在许多NLP任务中的表现超过了标准的BERT模型。
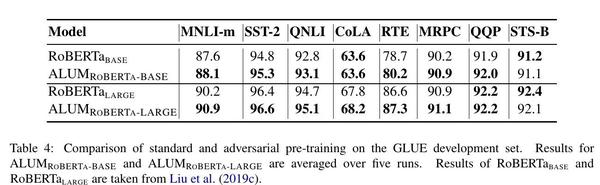
RoBERTa模型的训练效果非常好。标准的持续预训练未能在下游应用中获得任何收益,如MNLI(Williams等人,2018)和GLUE(Wang等人,2018)的SST(Socher等人,2013),如表3所示。另一方面,ALUM能够从RoBERTa的持续预训练中获得进一步的收益,如表4所示。例如,ALUM ROBERTA-BASE优于RoBERTaBASE +0.5%,ALUM ROBERTA-LARGE在MNLI开发集上优于RoBERTa LARGE +0.7%。这是相当了不起的,因为相比之下,标准的持续预训练无法达到任何收益。


4.4 提高鲁棒性
在本小节中,我们使用三个标准的对抗性NLP基准,评估对抗性预训练对模型对对抗性攻击的鲁棒性的影响。ANLI(Nie等人,2019)、HELLASWAG(Zellers等人,2019)和对抗性SQuAD(Jia和Liang,2017)。在ANLI上,我们遵循Nie等人(2019)的实验设置,以实现头对头的比较,它结合了四个数据集(ANLI、MNLI、SNLI和FEVER(Thorne等人,2018))来进行微调。
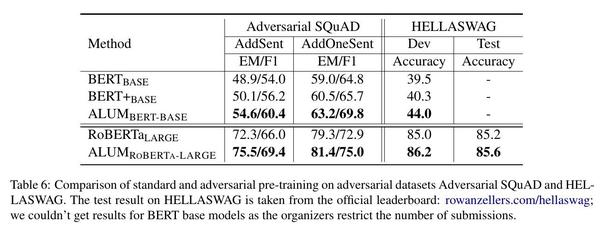
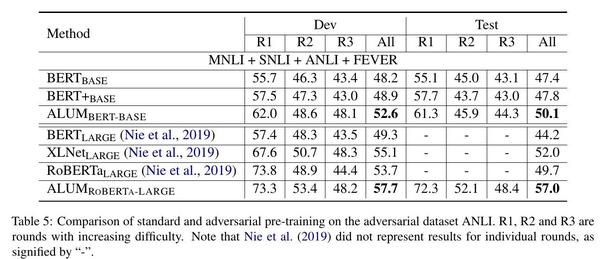
如表5和表6所示,对抗性预训练大大提高了模型的鲁棒性。在所有三个对抗性数据集中,ALUM的表现一直优于标准的预训练,对于BERT和RoBERTa都是如此。例如,在ANLI上,ALUM ROBERTA-LARGE的测试准确率比RoBERTa LARGE提高了7.3%点,比XLNet(Yang等人,2019)高出5.0%点,创造了一个新的最先进的结果。对Adversarial SQuAD和HELLASWAG的收益同样显著。例如,对于Adversarial SQuAD,ALUMBERT-BASE在AddSent设置中优于BERTBASE的+6.4% F1,在AddOneSent设置中优于+5.0% F1。针对RoBERTa,ALUM LARGE ROBERTA-LARGE在AddSent中获得+3.4%的F1,在AddOneSent中获得+2.1%的F1。



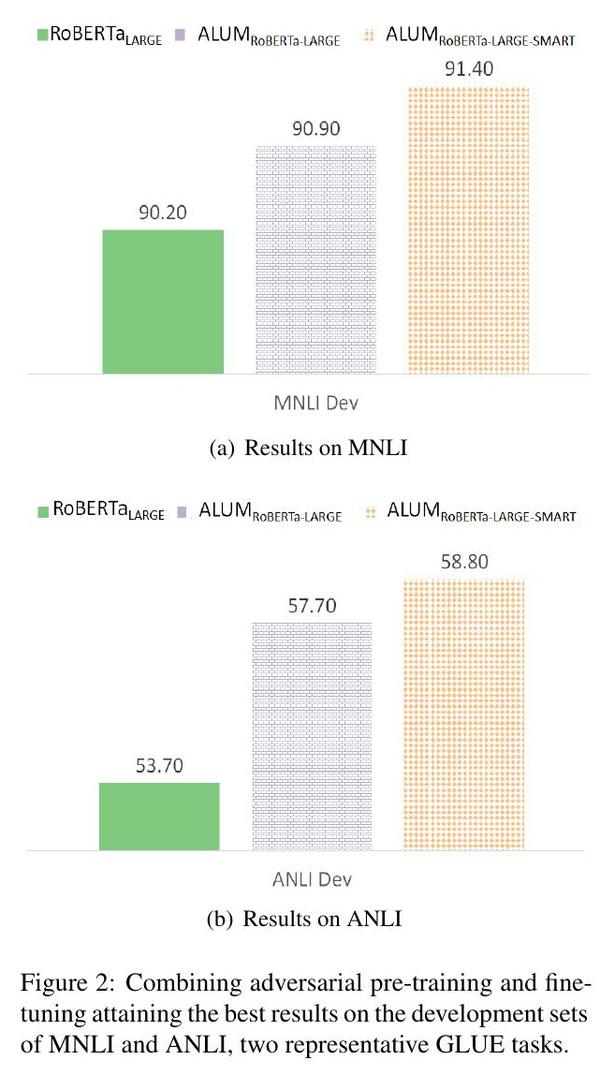
4.5 结合对抗性预训练和微调
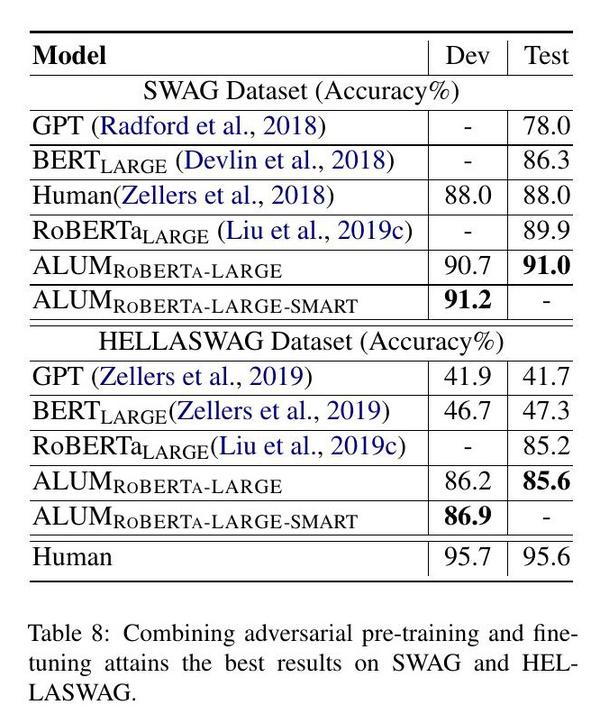
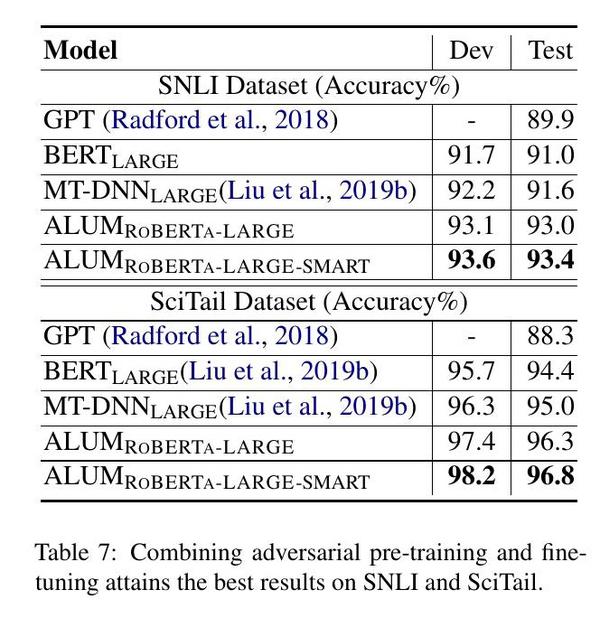
在特定任务的微调中,对抗性训练已被证明是有效的(Jiang等人,2019;Zhu等人,2019)。在本小节中,我们探索将对抗性预训练与对抗性微调相结合。具体来说,我们使用RoBERTa作为基础模型,并将其与ALUM(使用对抗性ROBERTA-LARGE ial持续预训练但标准微调)和ALUM(在持续预训练和微调中使用adRoBERTA-LARGE-SMART versarial训练)进行比较。图2显示了在MNLI和ANLI这两个有代表性的GLUE任务的开发集上的结果。结合对抗性的预训练和微调达到了最好的结果,并大大超过了RoBERTa LARGE。例如,在ANLI上,ALUM RoBERTa-SMART的准确率比ALUM ROBERTA-LARGE高出+1.1%,比RoBERTa LARGE高出+5.1%。在SNLI、SciTail、SWAG和HELLASWAG上,我们通过结合对抗性预训练和微调观察到类似的收益,在这些任务上达到了新的最先进的结果。见表7和表8。



五、总结
我们提出了ALUM,一种通用的对抗性训练算法,并提出了对大型神经语言模型中对抗性训练的首次全面研究。我们表明,对抗性预训练可以显著提高泛化性和鲁棒性,这为调和先前工作中观察到的它们的冲突提供了一个有希望的方向。在广泛的NLP任务中,ALUM极大地提高了BERT和RoBERTa的准确性,并且可以与对抗性微调相结合以获得进一步的收益。
未来的方向包括:进一步研究对抗性预训练在提高泛化和鲁棒性方面的作用;加快对抗性训练的速度;将ALUM应用于其他领域。
参考文献
A NLP应用基准
- GLUE。通用语言理解评估(GLUE)基准是九个自然语言理解(NLU)任务的集合。如表9所示,它包括问答(Rajpurkar等人,2016)、语言接受性(Warstadt等人,2018)、情感分析(Socher等人,2013)、文本相似性(Cer等人。2017),转述检测(Dolan和Brockett,2005),以及自然语言推理(NLI)(Dagan等人,2006;Bar-Haim等人,2006;Giampiccolo等人,2007;Bentivogli等人,2009;Levesque等人,2012;William等人,2018)。任务的多样性使得GLUE非常适用于评估NLU模型的泛化和鲁棒性。


- SNLI。斯坦福大学自然语言推理(SNLI)数据集包含570k个人工标注的句子对,其中的前提来自Flickr30语料库的标题,假设则是人工标注的(Bowman等人,2015)。这是NLI SciTail最广泛使用的entailment数据集。
- SciTail 这是一个源自科学问答(SciQ)数据集的文本蕴含据集(Khot等人,2018)。该任务涉及评估一个给定的前提是否包含一个给定的假设。与前面提到的其他尾蕴含据集不同,SciTail中的假设是由科学问题创建的,而相应的答案候选者和前提来自于从大型语料库中检索的相关网络句子。因此,这些句子在语言上具有挑战性,前提和假设的词汇相似度往往很高,因此使SciTail变得特别困难。
- ANLI。对抗性自然语言推理(ANLI,Nie等人(2019))是一个新的大规模NLI基准数据集,通过一个迭代的、对抗性的人类和模型的循环程序收集。具体来说,这些实例被选为对最先进的模型(如BERT和RoBERTa)来说是困难的。
- SWAG。它是一个大规模的对抗性数据集,用于基于常识的推理任务,它统一了自然语言推理和物理基础推理(Zellers等人,2018)。SWAG由113k个关于接地情况的多项选择题组成。
- HELLASWAG。它与SWAG类似,但更具挑战性(Zellers等人,2019)。对于HELLASWAG中的每个查询,它也有4个选择,目标是找到其中的最佳选择。
- SQuAD v1.1/v2.0。斯坦福问答数据集(SQuAD)v1.1和v2.0(Rajpurkar等人,2016,2018)是流行的机器阅读理解基准。它们的段落来自大约500篇维基百科文章,问题和答案是通过众包获得的。SQuAD v2.0数据集包括关于相同段落的无法回答的问题。
- BC2GM。Biocreative II研讨会上的基因提及任务(Smith等人,2008)为基因名称实体识别提供了一个标注的数据集。- NCBI。NCBI疾病语料库(Dogan等人,2014)包含来自PubMed摘要集的疾病提及标注。
- JNLPBA。JNLBA是一个生物医学实体识别共享任务(Collier和Kim,2004)。它是最大的数据集之一,涵盖了分子生物学中主要分类法的很大一部分。
