

粒子滤波
1. 粒子滤波理论
粒子滤波通过非参数化的蒙特卡洛(Monte Carlo)模拟方法来实现递推贝叶斯滤波,适用于任何能用状态空间模型描述的非线性系统,精度可以逼近最优估计。
1.1. 贝叶斯滤波
动态系统的目标跟踪问题可以通过下图的状态空间模型来描述。

在目标跟踪问题中,动态系统的状态空间模型可描述为
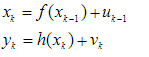
其中f()和h()分别为状态转移方程与观测方程,xk为系统状态,yk为观测值,uk为过程噪声,vk为观测噪声。为便于描述,
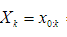
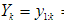
分别表示0到k时刻所有的状态与观测值。
在处理目标跟踪问题时,通常假设目标的状态转移过程服从一阶马尔可夫模型,即当前时刻的状态只与上一时刻的状态有关,另外一个假设为观测值相互独立,即观测值yk只与k时刻的状态xk有关。
贝叶斯滤波为非线性系统的状态估计问题提供了一种基于概率分布形式的解决方案。贝叶斯滤波将状态估计视为一个概率推理过程,即将目标状态的估计问题转换为利用贝叶斯公式求解后验概率密度或滤波概率密度,进而获得目标状态的最优估计。贝叶斯滤波包含预测和更新两个阶段,预测过程利用系统模型预测状态的先验概率密度,更新过程则利用最新的测量值对先验概率密度进行修正,得到后验概率密度。


贝叶斯滤波以递推的形式给出后验(或滤波)概率密度函数的最优解。目标状态的最优估计值可由后验(或滤波)概率密度函数进行计算。通常根据极大后验(MAP)准则或最小均方误差(MMSE)准则,将具有极大后验概率密度的状态或条件均值作为系统状态的估计值。
贝叶斯滤波需要进行积分运算,除了一些特殊的系统模型(如线性高斯系统,有限状态的离散系统)之外,对于一般的非线性、非高斯系统,贝叶斯滤波很难得到后验概率的封闭解析式。因此,现有的非线性滤波器多采用近似的计算方法解决积分问题,以此来获取估计的次优解。在系统的非线性模型可由在当前状态展开的线性模型有限近似的前提下,基于一阶或二阶Taylor级数展开的扩展Kalman滤波得到广泛应用。在一般情况下,逼近概率密度函数比逼近非线性函数容易实现。据此,Julier与Uhlmann提出一种Unscented Kalman滤波器,通过选定的sigma点来精确估计随机变量经非线性变换后的均值和方差,从而更好的近似状态的概率密度函数,其理论估计精度优于扩展Kalman滤波。获取次优解的另外一中方案便是基于蒙特卡洛模拟的粒子滤波器。
1.2. 粒子滤波
1.2.1. 贝叶斯重要性采样
蒙特卡洛模拟是一种利用随机数求解物理和数学问题的计算方法,又称为计算机随机模拟方法。该方法源于第一次世界大战期间美国研制原子弹的曼哈顿计划,著名数学家冯诺伊曼作为该计划的主持人之一,用驰名世界的赌城,摩纳哥的蒙特卡洛来命名这种方法。蒙特卡洛模拟方法利用所求状态空间中大量的样本点来近似逼近待估计变量的后验概率分布,从而将积分问题转换为有限样本点的求和问题。粒子滤波算法的核心思想便是利用一系列随机样本的加权和表示后验概率密度,通过求和来近似积分操作。
蒙特卡洛方法一般可以归纳为以下三个步骤:
(1)构造概率模型。对于本身具有随机性质的问题,主要工作是正确地描述和模拟这个概率过程。对于确定性问题,比如计算定积分、求解线性方程组、偏微分方程等问题,采用蒙特卡洛方法求解需要事先构造一个人为的概率过程,将它的某些参量视为问题的解。
(2)从指定概率分布中采样。产生服从己知概率分布的随机变量是实现蒙特卡洛方法模拟试验的关键步骤。
(3)建立各种估计量的估计。一般说来,构造出概率模型并能从中抽样后,便可进行现模拟试验。随后,就要确定一个随机变量,将其作为待求解问题的解进行估计。
在实际计算中,通常无法直接从后验概率分布中采样,如何得到服从后验概率分布的随机样本是蒙特卡洛方法中基本的问题之一。重要性采样法引入一个已知的、容易采样的重要性概率密度函数,从中生成采样粒子,利用这些随机样本的加权和来逼近后验滤波概率密度。
1.2.2序贯重要性采样算法
在基于重要性采样的蒙特卡洛模拟方法中,估计后验滤波概率需要利用所有的观测数据,每次新的观测数据来到都需要重新计算整个状态序列的重要性权值。序贯重要性采样作为粒子滤波的基础,它将统计学中的序贯分析方法应用到的蒙特卡洛方法中,从而实现后验滤波概率密度的递推估计。
(推导过程)
序贯重要性采样算法从重要性概率密度函数中生成采样粒子,并随着测量值的依次到来递推求得相应的权值,最终以粒子加权和的形式来描述后验滤波概率密度,进而得到状态估计。序贯重要性采样算法的流程可以用如下伪代码描述:

为了得到正确的状态估计,通常希望粒子权值的方差尽可能趋近于零。然而,序贯蒙特卡洛模拟方法一般都存在权值退化问题。在实际计算中,经过数次迭代,只有少数粒子的权值较大,其余粒子的权值可忽略不计。粒子权值的方差随着时间增大,状态空间中的有效粒子数较少。随着无效采样粒子数目的增加,使得大量的计算浪费在对估计后验滤波概率分布几乎不起作用的粒子更新上,使得估计性能下降。
克服序贯重要性采样算法权值退化现象最直接的方法是增加粒子数,而这会造成计算量的相应增加,影响计算的实时性。因此,一般采用以下两种途径:(1)选择合适的重要性概率密度函数;(2)在序贯重要性采样之后,采用重采样方法。
1.2.3. 重要密度函数的选择
重要性概率密度函数的选择对粒子滤波的性能有很大影响,在设计与实现粒子滤波器的过程中十分重要。在工程应用中,通常选取状态变量的转移概率密度函数作为重要性概率密度函数。转移概率的形式简单且易于实现,在观测精度不高的场合,将其作为重要性概率密度函数可以取得较好的滤波效果。然而,采用转移概率密度函数作为重要性概率密度函数没有考虑最新观测数据所提供的信息,从中抽取的样本与真实后验分布产生的样本存在一定的偏差,特别是当观测模型具有较高的精度或预测先验与似然函数之间重叠部分较少时,这种偏差尤为明显。
在实际情况中,构造最优重要性概率密度函数的困难程度与直接从后验概率分布中抽取样本的困难程度等同。从最优重要性概率密度函数的表达形式来看,产生下一个预测粒子依赖于已有的粒子和最新的观测数据,这对于设计重要性概率密度函数具有重要的指导作用,即应该有效利用最新的观测信息,在易于采样实现的基础上,将更多的粒子移动到似然函数值较高的区域。
1.2.4. 重采样方法
针对序贯重要性采样算法存在的权值退化现象,Gordon等提出了一种名为Bootstrap的粒子滤波算法。该算法在每步迭代过程中,根据粒子权值对离散粒子进行重采样,在一定程度上克服了这个问题。重采样方法舍弃权值较小的粒子,代之以权值较大的粒子。重采样策略包括固定时间间隔重采样与根据粒子权值进行的动态重采样。动态重采样通常根据当前的有效粒子数或最大与最小权值比来判断是否需要进行重采样。常用的重采样方法包括多项式(Multinomial resampling)重采样、残差重采样(Residual resampling)、分层重采样(Stratified resampling)与系统重采样(Systematic resampling)等。
残余重采样采用新的权值选择余下的粒子,残余重采样的主要过程为

重采样并没有从根本上解决权值退化问题。重采样后的粒子之间不再是统计独立关系,给估计结果带来额外的方差。重采样破坏了序贯重要性采样算法的并行性,不利于VLSI硬件实现。另外,频繁的重采样会降低对测量数据中野值的鲁棒性。由于重采样后的粒子集中包含了多个重复的粒子,重采样过程可能导致粒子多样性的丧失,此类问题在噪声较小的环境下更加严重。因此,一个好的重采样算法应该在增加粒子多样性和减少权值较小的粒子数目之间进行有效折衷。
标准化粒子滤波算法流程:


