
AlphaZero如何学习国际象棋的?

DeepMind 和 Google Brain 研究人员以及前世界国际象棋冠军Vladimir Kramnik通过概念探索、行为分析和对其激活的检查,探索了人类知识是如何获得的,以及国际象棋概念如何在 AlphaZero 神经网络中表示。
AlphaZero 在短短四个小时内掌握了所有国际象棋专业知识。 AlphaZero 不仅要颠覆国际象棋世界,还要颠覆整个世界 战略决策领域。 AlphaZero 胜利者代表了另一个重要方面的突破:这是一种可以推广到其他学习任务的算法。
众所周知,深度神经网络可以学习人类无法理解的不透明、无法解释的表示。 因此从科学和实践的角度来看,探索像AlphaZero这样自学成才的超人类神经网络代理实际上在学习什么以及如何学习,才是最重要的。
在新论文Acquisition of Chess Knowledge in AlphaZero中,DeepMind 和 Google Brain 研究人员以及前世界国际象棋冠军Vladimir Kramnik探索了 AlphaZero 如何以及在多大程度上获取人类知识,以及如何在其网络模型中表示国际象棋概念。 他们通过全面的概念探索、行为分析和对 AlphaZero 激活的检查来做到这一点。


像AlphaZero这样复杂的神经网络代理能学到什么?这个问题既有科学意义又有实践意义。如果强神经网络的表示与人类的概念没有相似之处,我们理解对其决策的解释的能力将受到限制,最终也会限制在神经网络可解释性方面的成就。在这项工作中,论文证明了AlphaZero神经网络在下棋时可以获得人类知识。通过探索广泛的人类国际象棋概念,论文展示了这些概念在如何在AlphaZero网络中表示。还提供专注于开局的行为分析,包括定性分析国际象棋大师Vladimir Kramnik。最后,对AlphaZero表示的底层细节进行了初步查看,并将结果的行为分析和表示分析放到网上。
研究人员的研究前提是:如果像 AlphaZero 这样的强神经网络的表示与人类概念没有相似之处,我们理解其决策的解释的能力将受到限制,最终限制了我们可以通过神经网络可解释性实现的目标。
该团队的研究旨在提高对以下方面的理解:
- 人类对于知识的编码
- 如何在训练中获取知识
- 通过编码国际象棋概念重新解释价值函数
- AlphaZero 的进化与人类历史的比较
- AlphaZero 的棋子下一步移动候选策略的演变
- 无监督概念发现和证明
该团队从大型输入数据集的网络激活中检测人类概念,在 AlphaZero 的国际象棋自我对弈训练过程中,在每个块和多个检查点上探测每个概念。 这使他们能够建立一张图片,了解在训练期间学习的内容以及计算网络的位置。


用于选择 Stockfish 8 和自定义概念的时间地点图。 下图,我们将一个 ResNet“块”算作一个层。
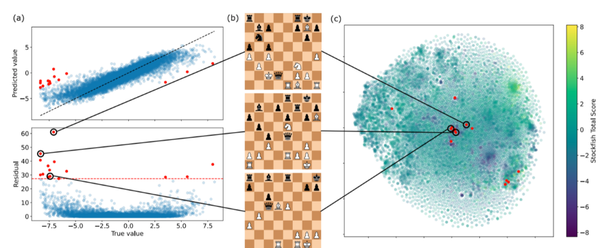

回归残差模式
该团队使用稀疏线性探测方法检查国际象棋知识是如何逐渐获取和表示的,这样可以确定 AlphaZero 如何表示广泛的人类国际象棋概念。 他们通过说明在训练时间学习什么概念以及在“什么时间什么地点”图中的网络来可视化这种概念知识的获取。
在研究内部表征是如何随着时间变化的之后,该团队接着研究了这些变化的表征是如何导致行为的变化的,方法是测量一组指定的棋位的移动概率的变化;通过将自我游戏训练中的进化与人类顶级游戏中移动选择的进化进行比较。


最后,考虑到已经建立的用于预测人类概念的AlphaZero的激活,通过使用非负矩阵分解(NMF)来直接查看这些激活,将AlphaZero的表示分解为多个因素,以获得AlphaZero网络正在计算的内容的补充视图。
下图确实是我们看到的,它将人类历史与AlphaZero在训练期间的历史偏好进行了比较。


如果训练不同版本的AlphaZero,得到的棋手可能会有不同的偏好。有趣的是,这意味着不存在“独一无二”的优秀棋手!下表显示了四种不同AlphaZero神经网络的偏好:
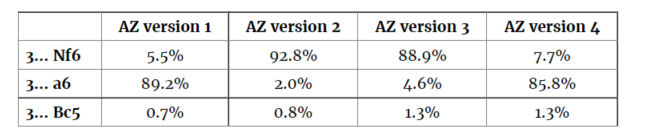

上表的先验是在 100 万次训练步骤后给出的。 有时 AlphaZero 收敛成为喜欢 3…a6 的玩家,有时 AlphaZero 收敛成为喜欢用 3…Nf6 的玩家。
但是AlphaZero到底是怎么想的呢?AlphaZero如何评估位置?AlphaZero的神经网络评估函数没有Stockfish的评估函数那样的结构层次:Stockfish将一个位置分解为一系列概念(例如king safety, mobility, and material),并将这些概念结合起来,以达到对位置的整体评估。而AlphaZero输出的值函数范围从-1(一定会失败)到+1(一定会胜利),没有明确的中间步骤。虽然神经网络评估函数在计算一些东西但并不清楚是什么。为了了解正在被计算的内容,DeepMind和谷歌Brain的研究人员使用Stockfish概念值来尝试预测AlphaZero的位置评估函数(类似于通过预测游戏结果获得棋子值的方式)。


这种方法允许研究人员估算AlphaZero在某个位置的值,以及这种评估是如何随着自训练的进展而发展的。如上图所示,material 在AlphaZero的评估中较早出现为重要因素,但在后期的训练中,随着king safety等更复杂的概念的重要性上升,material (子力)的重要性逐渐下降。这种进化与人类惊人地相似:在学习国际象棋的早期过程中,我们只是通过棋子子力来评估位置,然后随着我们了解的更多对位置的其他方面有了更丰富的理解。
该团队对 AlphaZero 神经网络从初始化到训练结束的进程的研究得出了以下见解:
1)在 AlphaZero 网络中可以找到许多人类概念;
2)通过“what-when-where plots”呈现训练过程中知识获取的详细画面;
3)概念的使用和相对概念价值随着时间的推移而演变,AlphaZero 最初主要关注子力,更复杂和微妙的概念在训练中才出现作为价值函数的重要预测指标;
4) 与历史人类游戏的比较表明,人类游戏的发展方式存在显着差异,但在 AlphaZero 的自我游戏策略的演变方面也有惊人的相似之处。
