
【强化学习应用11】对抗策略:深度强化学习攻击(1)

原文传送
特色
众所周知,深度强化学习(RL)策略容易受到其观察结果的对抗性干扰,类似于分类器的对抗性示例。但是,攻击者通常无法直接修改其他智能体的观察结果。这可能会让人产生疑问:是否可以通过选择在多代理环境中采取的对抗策略来攻击RL代理,从而创建具有对抗性的自然观察?我们证明了在模拟人类人形机器人与本体感受观察之间的零和游戏中,对抗性策略的存在,这种对抗性策略是针对通过自学训练对对手具有鲁棒性的最新受害者的。对抗性政策可靠地击败了受害者,但产生了看似随机和不协调的行为。我们发现,这些策略在高维环境中更为成功,并且与受害者与正常对手竞争时相比,在受害者策略网络中引起了实质上不同的激活。
1、简介
图像分类器对抗示例的发现为对抗攻击和防御的研究开辟了一个新领域(Szegedy等,2014)。 最近的工作表明,深入的RL策略也容易受到图像观察的对抗性干扰(Huang等人,2017年; Kos和Song,2017年)。 但是,现实世界中的RL代理人居住在由其他代理人(包括人类)组成的自然环境中,这些人只能通过自己的行动修改观察结果。 我们探索通过制定在共同环境中采取行动的对抗性政策,并诱发对受害者具有对抗性的自然观察,来攻击受害者的政策是否可行。
通过改变图像观察来攻击
Sandy H. Huang, Nicolas Papernot, Ian J. Goodfellow, Yan Duan, and Pieter Abbeel. Adversarial attacks on neural network policies. arXiv:1702.02284v1 [cs.LG], 2017.
Jernej Kos and Dawn Song. Delving into adversarial attacks on deep policies. arXiv:1705.06452v1 [stat.ML], 2017.
RL已应用于自动驾驶(Dosovitskiy等,2017),谈判(Lewis等,2017)和自动交易(Noonan,2017)等各种环境中。 在此类域中,攻击者通常无法直接修改受害者策略的输入。 例如,在自动驾驶中,行人和其他驾驶员可以在世界上采取行动来影响相机的图像,但只能以现实的方式进行。 它们不能给任意像素增加噪点或使建筑物消失。同样,在金融交易中,攻击者可以将订单发送到将出现在受害者的市场数据源中的交易所,但攻击者无法修改对第三方订单的观察。
作为概念的证明,我们通过本体感觉的观察证明了零和模拟机器人游戏中对抗策略的存在(Bansal等人,2018a)。 最先进的受害者策略通过自我扮演进行了训练,可以对付对手。 我们针对固定的黑匣子受害者使用无模型RL训练每种对抗策略。 我们发现对抗策略确实击败了受害者策略,尽管训练时间不到最初用于训练受害者策略的3%的时间。
至关重要的是,我们发现对手是通过创建具有对抗性的自然观察而获胜的,而不是通过成为普遍强壮的对手而获胜。 从质量上讲,对手处于扭曲位置,如图1所示,而不是像普通对手那样学习奔跑,踢球或阻挡。当受害者被“掩盖”并且看不到对手的位置时,该策略不起作用,这表明对手通过其行为来操纵受害者的观察而成功。
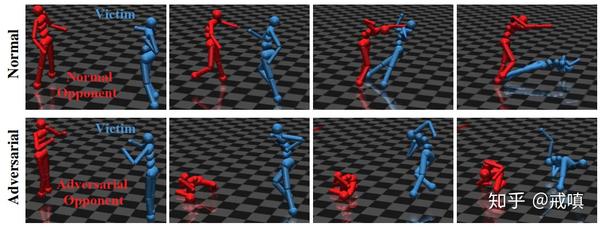

图1:受害者对普通和对抗对手(红色)的示意性快照(蓝色)。如果受害者越过终点线则获胜; 否则,对手获胜。 尽管从未站起来,但对抗对手还是赢得了86%的情节,远高于正常对手的47%胜率。
观察了这些结果之后,我们想了解攻击对攻击者可能影响的受害者观察结果维度的敏感性。 我们通过改变机器人主体(受攻击者影响的24个尺寸的人形机器人和具有15个尺寸的Ant的机器人)进行测试,同时保持高级任务不变。 我们发现,在较高维度的类人动物环境中,受害者策略比在Ant中更容易受到对抗策略的攻击。
为了深入了解对抗策略成功的原因,我们使用高斯混合模型和t-SNE分析了受害者策略网络的激活情况(Maaten和Hinton,2008年)。 我们发现,对抗性策略与正常对手相比,其诱因明显不同。 此外,对抗性激活通常在时间步长上比正常激活更广泛地分散。
我们的论文做出了三点贡献。
- 首先,我们针对RL中的对抗示例提出了一种新颖的,物理上真实的威胁模型(红色实体)。
- 其次,我们在几种模拟机器人游戏中证明了这种威胁模型中对抗策略的存在。 我们的对抗策略可靠地击败了受害者,尽管训练时间少于3%,并且产生了看似随机的行为。
- 第三,我们详细分析了对抗策略为何起作用。 我们证明了他们创造了对受害者不利的自然观察结果,并推动了受害者策略网络的启动分布不均。
- 此外,我们发现策略在高维环境中更容易受到攻击。
随着深层RL越来越多地部署在具有潜在对手的环境中,我们相信从业者必须意识到这种以前无法识别的威胁模型,这一点很重要。 此外,即使在良性环境中,我们也认为对抗策略可以成为发现意外策略失败模式的有用工具。 最后,我们对使用对抗性策略进行对抗性训练的潜力感到兴奋,这可以通过对付那些利用自我发挥过程中存在的类似对手分布所未发现的弱点的对手进行训练来提高相对于常规自我发挥的鲁棒性。
2、相关工作
大多数对抗性例子的研究都集中在对图像的小p范数扰动上,Szegedy等人(2014年)发现,即使变化在视觉上对人类来说是不可察觉的,也会导致各种模型自信地误判了该类。 Gilmer等人(2018a)认为,攻击者不仅限于小扰动,还可以构建新图像或搜索自然错误分类的图像。 类似地,Uesato等人(2018)认为,几乎无处不在的p模型只是对真正的最坏情况风险的便捷局部逼近。 我们遵循Goodfellow等人(2017)的观点更广泛地查看对抗性示例,将其作为“攻击者故意设计的机器学习模型的输入,导致模型出错。”
在RL中研究对抗性示例的很少的先验工作假设了“ p范式威胁模型”。 Huang等人(2017)以及Kos和Song(2017)表明,深度RL策略容易受到图像观测中的小扰动的影响。 Lin等人(2017)的最新工作产生了一系列扰动,将受害者引导到目标状态。 我们的工作与以前的方法不同,它使用了物理上真实的威胁模型(实体威胁模型,即红色agent),不允许直接修改受害者的观察结果。
Yen-Chen Lin, Zhang-Wei Hong, Yuan-Hong Liao, Meng-Li Shih, Ming-Yu Liu, and Min Sun. Tactics of adversarial attack on deep reinforcement learning agents. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), pages 3756–3762, 2017.

Lanctot等人(2017)确定了一种独特的失败模式,即特工可能与训练过的对手紧密耦合,对具有不同随机种子的对手进行失败。 像对抗性策略一样,这会导致显然强大的策略无法对抗新对手。 但是,我们所攻击的受害者策略可以成功抵御一系列反对者,因此并没有紧密地联系在一起。
具体来说,我们借鉴了多智能体强化学习中的悠久传统,将对手和受害者建模为马尔可夫博弈中的智能体人(Littman,1994年)。 竞争性多主体环境可作为具体威胁模型的来源(Lowe等人,2017; Bansal等人,2018a)。 但是,由于受害者策略是固定的,因此找到对抗策略是一个单一代理RL问题。
对抗训练是对抗示例的常见防御手段,可实现图像分类的最新鲁棒性(Xie等人,2019)。 先前的工作还应用了对抗训练来提高深层RL策略的鲁棒性,其中对手在受害者身上施加力矢量或改变诸如摩擦之类的动力学参数(Pinto等人,2017; Mandlekar等人,2017; Pattanaik等人) 等(2018) 我们希望在未来的工作中探索具有对抗性政策的对抗性训练。 与传统的自玩游戏相反,传统的自演仅在较小的策略空间区域内训练稳健性,与此相反,我们希望这会产生对对手不利的稳健性策略。
对手在受害者身上施加力矢量或改变诸如摩擦之类的动力学参数
Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta. Robust adversarial reinforcement learning. In Proceedings of the International Conference on Machine Learning (ICML), volume 70, pages 2817–2826, 2017.
Ajay Mandlekar, Yuke Zhu, Animesh Garg, Li Fei-Fei, and Silvio Savarese. Adversarially robust policy learning: Active construction of physically-plausible perturbations. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3932–3939, 2017.
Anay Pattanaik, Zhenyi Tang, Shuijing Liu, Gautham Bommannan, and Girish Chowdhary. Robust deep reinforcement learning with adversarial attacks. In Proceedings of the International Conference on Autonomous Agents and MultiAgent System (AAMAS), pages 2040–2042, 2018.
3框架
我们将受害者建模为在两人马尔可夫游戏中与对手对战(Shapley,1953)。我们的威胁模型假设攻击者可以控制对手,在这种情况下,我们称对手为对手。 我们分别用下标α和ν表示对手和受害者。
博弈M =(S,( A_{\alpha} , A_{\upsilon} ),T,( R_{\alpha} , R_{\upsilon} ))由
- 状态集S
- 动作集A_{\alpha}和A_{\upsilon}
- 联合状态转移函数T:S×A_{\alpha}×A_{\upsilon}→∆(S), 其中∆(S)是S上的概率分布
- 玩家i∈{α,ν}的奖励函数 R_{i} :S×A_{\alpha}×A_{\upsilon}×S→R取决于当前状态,下一状态和两个玩家的动作。 每个玩家都希望最大化其(折扣的)奖励金额。
- 允许攻击者无限制地黑盒访问从 \pi_{\upsilon} 采样的动作,但是不给对手任何白盒信息,例如权重或激活。
- 假设受害者遵循固定的随机策略\pi_{\upsilon},这对应于使用静态权重部署的预训练模型的常见情况。 对安全至关重要的系统特别可能使用固定的或不经常更新的系统由于实际测试的大量费用,因此无法使用该模型。
由于受害者策略 \pi_{\upsilon} 保持固定,因此两人马尔可夫游戏M降低为攻击者必须解决的单人MDP, M_{\alpha}=(S,A_{\alpha},T_{\alpha},R^{\prime}_{\alpha}) 。 攻击者的状态和行动空间与M中的相同,而转移和奖励功能中嵌入了受害者策略\pi_{\upsilon}:
T_{\alpha}(s,a_{\alpha}) = T(s,a_{\alpha},a_{\upsilon})
R^{\prime}_{\alpha}(s,a_{\alpha})=R_{\alpha}(s,a_{\alpha},a_{\upsilon})
受害者的行为是从随机策略 a_{\upsilon} \sim \pi_{\upsilon}(\cdot \mid s) 中抽样的。 攻击者的目标是找到一种对策 \pi_{\alpha} ,以使折价奖励的总和最大化:
\sum_{t=0}^{\infty}\gamma^{t}R_{\alpha}(s^{(t)},a_{\alpha}^{(t)},s^{(t+1)})
其中, s^{(t+1)} \sim T_{\alpha}(s^{(t)},a_{\alpha}^{(t)})
a_{\alpha} \sim \pi_{\alpha}(\cdot \mid s^{(t)})
请注意,即使Markov游戏的动态T是已知的,MDP的动态Tα也是未知的,因为受害者策略πν是一个黑匣子。 因此,攻击者必须解决RL问题。
4、寻找对抗策略
我们证明了零和模拟机器人游戏中对抗策略的存在。 首先,我们描述了受害者策略的训练方式以及它们所处的环境。随后,我们介绍了提供这些环境下我们的攻击方法的详细信息,并描述一些基准。 最后,我们提出了对抗策略和基线对手的定量和定性评估。
4.1环境和受害者策略
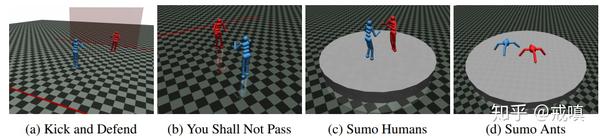
我们针对Bansal等人(2018a)创建的零和模拟机器人游戏的受害者策略进行攻击,如图2所示。受害者通过对自己的攻击者的随机旧版本进行自我游戏,成对训练了680至13.6亿时间步长。我们使用Bansal等人(2018b)的“代理商动物园”中发布的预先训练的策略权重。在对称环境中,动物园代理被标记为ZooN,其中N是随机种子。在非对称环境中,它们被标记为ZooVN和ZooON,代表受害人和对手代理。
Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, and Igor Mordatch. Emergent complexity via multi-agent competition. In Proceedings of the International Conference on Learning Representations (ICLR), 2018a.
Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, and Igor Mordatch. Source code and model weights for emergent complexity via multi-agent competition, 2018b. URL https: //http://github.com/openai/multiagent-competition.
在MuJoCo机器人模拟器中,所有环境都是两人游戏。两位特工都观察他们身体中关节的位置,速度和接触力,以及对手关节的位置。当触发获胜条件时或在一定时限之后,特工结束。我们在Bansal等人(2018a)的所有环境中进行评估,但“跑步至目标”除外,我们忽略了这一点,因为除获胜条件外,设置与“您不得通过”相同。我们在下面描述环境,并指定动物园代理的数量及其类型(MLP或LSTM):
踢和防守(3,LSTM)。两个类人机器人之间的足球点球大战。踢脚,守门员和球的位置是随机初始化的。如果球在球门柱之间移动,则踢球者获胜;否则,只要守门员保持在距目标3个单位之内,守门员就会获胜。
您不得通过(1,MLP)。两个Humanoid代理初始化为彼此面对。如果到达终点,则跑步者获胜。如果没有,则阻止者获胜。
相扑人类(3,LSTM)。两名类人生物特工在圆形竞技场上竞争。玩家的位置是随机初始化的。玩家在对手跌倒后仍保持站立状态获胜[Bansal等人(2018a)认为如果玩家在被对手碰到之前摔倒了,这一集将以平局结束。我们的获胜条件允许进行攻击,从而间接改变观察结果而无需实际操作联系。]。
相扑蚂蚁(4,LSTM)。与Sumo Humans相同的任务,但具有“蚂蚁”四足机器人身体。我们在5.2节中使用此任务来研究维数对这种攻击方法的重要性。
4.2评估方法
按照第3节中的RL公式,我们使用近端策略优化(PPO)训练对抗策略以最大化方程式1(Schulman et al。,2017)。
\sum_{t=0}^{\infty}\gamma^{t}R_{\alpha}(s^{(t)},a_{\alpha}^{(t)},s^{(t+1)})
其中, s^{(t+1)} \sim T_{\alpha}(s^{(t)},a_{\alpha}^{(t)})
a_{\alpha} \sim \pi_{\alpha}(\cdot \mid s^{(t)})
我们在情节结束时给予稀疏的奖励,当对手赢得游戏时给予积极的奖励,而当对手输掉游戏或平局时给予消极的奖励.Bansal等人(2018a)使用类似的奖励来训练受害者策略,并在开始时增加了一个密集的部分 训练。 我们使用稳定基准的PPO实施训练了2000万个时间步(Hill等人,2019)。 通过手动调整和随机搜索100个样本来选择超参数。 有关详细信息,请参见补充材料中的A节。 我们将我们的方法与三个基准进行比较:策略Rand采取随机行动; 实行零控制的无生命Zero策略; 以及来自Bansal等人(2018a)的所有经过预先培训的政策Zoo *。
