
多目标跟踪算法——SORT
1 前言
跟踪是很多视觉系统中的一个核心模块,有很多算法都需要使用到跟踪的信息。比如在基于视频的行为识别,我们就需要获得视频中每个个体的行为片段。在我们项目的pipeline中,跟踪采用的是DeepSORT算法,而DeepSORT的基础是SORT算法,所以本文主要先介绍SORT算法,后面另开一篇介绍DeepSORT算法。
2 SORT
2.1 SORT是什么
SORT是论文《Simple Online and Realtime Tracking》的缩写,它是一个解决多目标跟踪(Multiple Object Tracking: MOT)问题的算法,该算法基于“tracking-by-detection”框架,且是一个在线跟踪器(Online Tracker)。而所谓Online Tracker,就是跟踪器只能利用当前和之前帧的检测结果去实现跟踪算法。
SORT算法在设计时的建模有以下特点:
- 不考虑遮挡,无论是短时的还是长时的
- 未使用外观特征(appearance feature),在运动估计和数据关联时只利用了检测框的位置(postiion)和大小(size)
- 没有过多考虑跟踪中的一些corner case以及检测错误,因此算法对detection error的鲁棒性可能不是那么好,或者说跟踪效果的好坏很大程度上受到检测的影响
2.2 SORT原理
SORT算法主要包括4个模块:1)检测模块;2)运动估计模块;3)数据关联模块;4)被跟踪物体的建立与销毁模块。
检测模块
其中检测模块采用的是Faster RCNN,这个在实际项目中可以被其它检测算法替换,比如我们项目中使用的就是YOLO算法。
运动估计模块
每个物体的状态定义为\(\mathbf{x}=[u, v, s, r, \dot{u}, \dot{v}, \dot{s}]^{T}\)。假如当前帧检测出3个物体,运动估计模块利用Kalman Filter,得到下一帧(或下几帧)这3个物体的状态。预测过程使用的是匀速模型,如果下一帧的某个检测结果和其中某个物体关联起来了,那么用检测结果作为观测值来更新该物体的状态。
数据关联模块
数据关联就是回答当前检测得到的物体是现有的哪个物体(assigning detections to existing targets)。假设上一帧检测出3个物体,当前帧检测出4个物体,那么我们可以得到一个\(3 \times 4\)的矩阵,矩阵中每个元素表示预测的bbox和当前检测的bbox的IoU距离(Intersection-over-union distance)。基于这个矩阵,为了使总的IoU距离最小,可以利用匈牙利算法进行匹配/指配,从而完成数据关联。
被跟踪物体的建立与销毁模块
- 如果某个检测得到的物体和所有现有的trakcer的IoU都很小(\(< IoU_{min}\)),那么会基于它建立一个新的trakcer,这个物体的速度初始化为0,速度相关的协方差分量会初始化为一个很大的值;
- 如果一个被跟踪的物体(tracker)如果在\(T_{Lost}\)帧未被检测关联上,那么该tracker会被销毁。
为了跟细致地理解运动估计模块和数据关联模块,下面简单介绍一下卡尔曼滤波算法和匈牙利算法。
2.2.1 卡尔曼滤波(Kalman Filter)算法
卡尔曼滤波是一种最优估计算法,它是融合/结合各种带有不确定信息的一种有力工具。卡尔曼滤波算法对内存的占用很少,因为它只需要存储上一个状态的信息,同时它的实时性非常好,这使得卡尔曼滤波成为一种得到广泛应用的算法,1969年的阿波罗登月计划中就使用到了该算法。
下面以运动估计为例,大致看一下Kalman Filter,详细的卡尔曼滤波及其推导会另开一篇文章说明。
参考《How a Kalman filter works, in pictures》。
假设我们关注的状态为一个物体的位置和速度:\(\vec{x}=\left[\begin{array}{l} \vec{p} \\ \vec{v} \end{array}\right]\),且它们间的协方差矩阵(co-variance matrix)为\(\mathbf{P}_{k}=\left[\begin{array}{ll} \Sigma_{p p} & \Sigma_{p v} \\ \Sigma_{v p} & \Sigma_{v v} \end{array}\right]\)。
-
预测
根据运动模型(比如在很短的一小段时间\(\Delta t\)内,可以把物体视作匀速运动),可以得到下一状态的预测值: \(\begin{aligned} \hat{\mathbf{x}}_{k} &=\left[\begin{array}{cc} 1 & \Delta t \\ 0 & 1 \end{array}\right] \hat{\mathbf{x}}_{k-1} \\ &=\mathbf{F}_{k} \hat{\mathbf{x}}_{k-1} \end{aligned}\)。
上面的预测是基于一个非常理想的模型,但在实际场景中,我们还需要考虑一些已知的外部影响以及环境中的一些额外的不确定性。综合考虑,可以得到下一时刻的预测:
\(\begin{aligned} \hat{\mathbf{x}}_{k} &=\mathbf{F}_{k} \hat{\mathbf{x}}_{k-1}+\mathbf{B}_{k} \overrightarrow{\mathbf{u}_{k}} \\ \mathbf{P}_{k} &=\mathbf{F}_{\mathbf{k}} \mathbf{P}_{k-1} \mathbf{F}_{k}^{T}+\mathbf{Q}_{k} \end{aligned}\)
其中\(\mathbf{B}_{k}\)表示已知的外部影响,\(\mathbf{Q}_{k}\)表示环境中额外的不确定性。 -
测量更新
通过传感器,我们可以获得对状态的一组观测值。如果要获得一组靠谱的预测值,需要调和通过运动模型得到的预测值和实际测量的观测值。如果上述两个值分别用一个多维高斯分布进行表示,那么更好的预测应该是这两个多维高斯分布的乘积。
在预测阶段,我们以运动模型为基础,给定\(k-1\)时刻的状态,预测了\(k\)时刻的状态,但是我们的测量结果并不在状态空间,通过\(H_k\)矩阵,可以将状态空间转换到测量空间:
\(\begin{aligned} &\vec{\mu}_{\text {expected }}=\mathbf{H}_{k} \hat{\mathbf{x}}_{k} \\ &\mathbf{\Sigma}_{\text {expected }}=\mathbf{H}_{k} \mathbf{P}_{k} \mathbf{H}_{k}^{T} \end{aligned}\) -
两正太分布相乘仍为正态分布
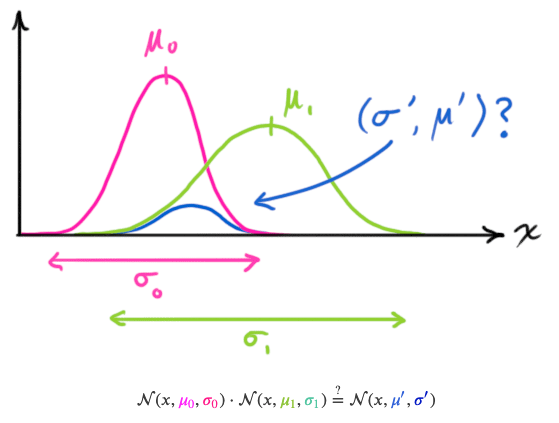
这里直接给出公式,其中\(K\)矩阵称为卡尔曼增益:
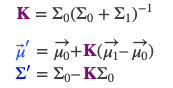
- 完整的Kalman FIlter

结合上面对卡尔曼滤波的简单介绍,可以看看源码对它的实现:
def convert_x_to_bbox(x,score=None):
"""
Takes a bounding box in the centre form [x,y,s,r] and returns it in the form
[x1,y1,x2,y2] where x1,y1 is the top left and x2,y2 is the bottom right
"""
w = np.sqrt(x[2] * x[3])
h = x[2] / w
if(score==None):
return np.array([x[0]-w/2.,x[1]-h/2.,x[0]+w/2.,x[1]+h/2.]).reshape((1,4))
else:
return np.array([x[0]-w/2.,x[1]-h/2.,x[0]+w/2.,x[1]+h/2.,score]).reshape((1,5))
class KalmanBoxTracker(object):
"""
This class represents the internal state of individual tracked objects observed as bbox.
"""
count = 0
def __init__(self,bbox):
"""
Initialises a tracker using initial bounding box.
"""
#define constant velocity model
# dim_x: 状态值是一个7维向量[u, v, s, r, u', v', s']
# dim_z: 测量值是一个4维向量[u, v, s, r]
# 代码中的F、H、R、P、Q都可以和上面的公式对应
self.kf = KalmanFilter(dim_x=7, dim_z=4)
self.kf.F = np.array([[1,0,0,0,1,0,0],[0,1,0,0,0,1,0],[0,0,1,0,0,0,1],[0,0,0,1,0,0,0], [0,0,0,0,1,0,0],[0,0,0,0,0,1,0],[0,0,0,0,0,0,1]])
self.kf.H = np.array([[1,0,0,0,0,0,0],[0,1,0,0,0,0,0],[0,0,1,0,0,0,0],[0,0,0,1,0,0,0]])
# F和H基于模型进行设置,但是R、P、Q的设置好像是根据经验进行设置?
self.kf.R[2:,2:] *= 10.
self.kf.P[4:,4:] *= 1000. #give high uncertainty to the unobservable initial velocities
self.kf.P *= 10.
self.kf.Q[-1,-1] *= 0.01
self.kf.Q[4:,4:] *= 0.01
self.kf.x[:4] = convert_bbox_to_z(bbox)
self.time_since_update = 0
self.id = KalmanBoxTracker.count
KalmanBoxTracker.count += 1
self.history = []
self.hits = 0
self.hit_streak = 0
self.age = 0
def update(self,bbox):
"""
Updates the state vector with observed bbox.
"""
self.time_since_update = 0
self.history = []
self.hits += 1
self.hit_streak += 1
self.kf.update(convert_bbox_to_z(bbox))
def predict(self):
"""
Advances the state vector and returns the predicted bounding box estimate.
"""
if((self.kf.x[6]+self.kf.x[2])<=0):
self.kf.x[6] *= 0.0
self.kf.predict()
self.age += 1
if(self.time_since_update>0):
self.hit_streak = 0
self.time_since_update += 1
self.history.append(convert_x_to_bbox(self.kf.x))
return self.history[-1]
def get_state(self):
"""
Returns the current bounding box estimate.
"""
return convert_x_to_bbox(self.kf.x)
2.2.2 匈牙利(Hungarian)算法
匈牙利算法在有些资料中也称作KM算法。SORT利用匈牙利算法解决了二分图中的最小权重匹配问题,我们可以用以下例子来理解这个问题。假设二分图的第一部分有N个节点,表示N个工人,第二部分有M个节点,表示M件工作。矩阵C中的元素\(C[i, j]\)表示将地j个工作分配给第i个工人需要的花费。试问如何分配工作,才能使得花费最小?
SORT中数据关联的源码如下,其中linear_sum_assignment()函数是sklearn中匈牙利算法的实现。
def linear_assignment(cost_matrix):
try:
import lap
_, x, y = lap.lapjv(cost_matrix, extend_cost=True)
return np.array([[y[i],i] for i in x if i >= 0]) #
except ImportError:
from scipy.optimize import linear_sum_assignment
# 调用匈牙利算法进行匹配
x, y = linear_sum_assignment(cost_matrix)
return np.array(list(zip(x, y)))
def iou_batch(bb_test, bb_gt):
"""
From SORT: Computes IOU between two bboxes in the form [x1,y1,x2,y2]
"""
bb_gt = np.expand_dims(bb_gt, 0)
bb_test = np.expand_dims(bb_test, 1)
# 求两个bbox的iou,横轴表示x,右为正,纵轴表示y,下为正
# (x1, y1)表示左上角点,(x2, y2)表示右下角点
# (xx1, yy1)和(xx2, yy2)分别表示两个bbox交集的左上角点和右下角点
xx1 = np.maximum(bb_test[..., 0], bb_gt[..., 0])
yy1 = np.maximum(bb_test[..., 1], bb_gt[..., 1])
xx2 = np.minimum(bb_test[..., 2], bb_gt[..., 2])
yy2 = np.minimum(bb_test[..., 3], bb_gt[..., 3])
w = np.maximum(0., xx2 - xx1)
h = np.maximum(0., yy2 - yy1)
wh = w * h
o = wh / ((bb_test[..., 2] - bb_test[..., 0]) * (bb_test[..., 3] - bb_test[..., 1])
+ (bb_gt[..., 2] - bb_gt[..., 0]) * (bb_gt[..., 3] - bb_gt[..., 1]) - wh)
return(o)
def associate_detections_to_trackers(detections,trackers,iou_threshold = 0.3):
"""
Assigns detections to tracked object (both represented as bounding boxes)
Returns 3 lists of matches, unmatched_detections and unmatched_trackers
"""
if(len(trackers)==0):
return np.empty((0,2),dtype=int), np.arange(len(detections)), np.empty((0,5),dtype=int)
iou_matrix = iou_batch(detections, trackers)
if min(iou_matrix.shape) > 0:
a = (iou_matrix > iou_threshold).astype(np.int32)
if a.sum(1).max() == 1 and a.sum(0).max() == 1:
matched_indices = np.stack(np.where(a), axis=1)
else:
# 使用匈牙利算法求解
matched_indices = linear_assignment(-iou_matrix)
else:
matched_indices = np.empty(shape=(0,2))
# 没有匹配到现有tracker的检测物体
unmatched_detections = []
for d, det in enumerate(detections):
if(d not in matched_indices[:,0]):
unmatched_detections.append(d)
# 没有匹配到检测物体的tracker
unmatched_trackers = []
for t, trk in enumerate(trackers):
if(t not in matched_indices[:,1]):
unmatched_trackers.append(t)
#filter out matched with low IOU
matches = []
for m in matched_indices:
if(iou_matrix[m[0], m[1]]<iou_threshold):
unmatched_detections.append(m[0])
unmatched_trackers.append(m[1])
else:
matches.append(m.reshape(1,2))
if(len(matches)==0):
matches = np.empty((0,2),dtype=int)
else:
matches = np.concatenate(matches,axis=0)
return matches, np.array(unmatched_detections), np.array(unmatched_trackers)

