请问FAIR的最新论文,用CNN建立语言模型为什么效果极佳?有哪些其它可能的应用?

Language Modelling - 语言模型
1. 【Language Modelling】Language Models are Unsupervised Multitask Learners
【语言模型】语言模型是无监督的多任务学习者
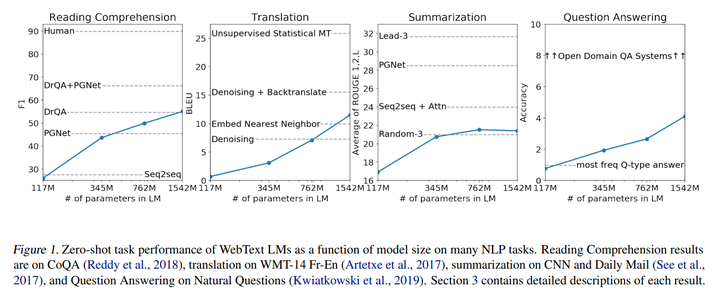

作者:Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever
链接:
https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
代码:
https://github.com/openai/gpt-2
英文摘要:
Natural language processing tasks, such as question answering, machine translation, reading comprehension, and summarization, are typically approached with supervised learning on taskspecific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText. When conditioned on a document plus questions, the answers generated by the language model reach 55 F1 on the CoQA dataset - matching or exceeding the performance of 3 out of 4 baseline systems without using the 127,000+ training examples. The capacity of the language model is essential to the success of zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks. Our largest model, GPT-2, is a 1.5B parameter Transformer that achieves state of the art results on 7 out of 8 tested language modeling datasets in a zero-shot setting but still underfits WebText. Samples from the model reflect these improvements and contain coherent paragraphs of text. These findings suggest a promising path towards building language processing systems which learn to perform tasks from their naturally occurring demonstrations.
中文摘要:
自然语言处理任务,例如问答、机器翻译、阅读理解和摘要,通常通过对特定任务数据集的监督学习来处理。我们证明,当在一个名为WebText的包含数百万个网页的新数据集上进行训练时,语言模型开始在没有任何明确监督的情况下学习这些任务。当以文档和问题为条件时,语言模型生成的答案在CoQA数据集上达到55F1-在不使用127,000多个训练示例的情况下,匹配或超过4个基准系统中的3个的性能。语言模型的容量对于零样本任务转移的成功至关重要,并且增加它以对数线性方式跨任务提高性能。我们最大的模型GPT-2是一个1.5B参数的Transformer,它在8个测试语言建模数据集中的7个在零样本设置中实现了最先进的结果,但仍然不适合WebText。模型中的样本反映了这些改进并包含连贯的文本段落。这些发现为构建语言处理系统提供了一条有希望的途径,该系统从自然发生的演示中学习执行任务。
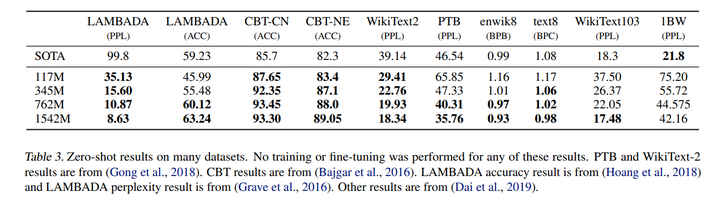

2. 【Language Modelling】Jasper: An End-to-End Convolutional Neural Acoustic Model
【语言模型】Jasper:端到端卷积神经声学模型
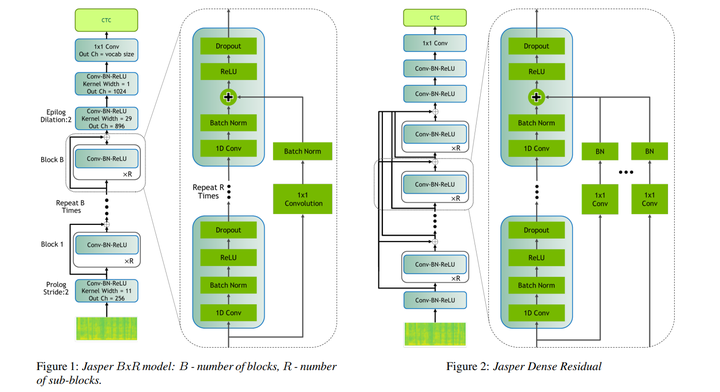

作者:Jason Li, Vitaly Lavrukhin, Boris Ginsburg, Ryan Leary, Oleksii Kuchaiev, Jonathan M. Cohen, Huyen Nguyen, Ravi Teja Gadde
链接:
https://arxiv.org/abs/1904.03288v3
代码:
https://github.com/NVIDIA/OpenSeq2Seq
英文摘要:
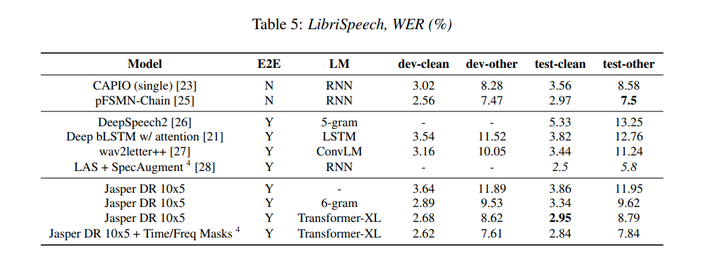
In this paper, we report state-of-the-art results on LibriSpeech among end-to-end speech recognition models without any external training data. Our model, Jasper, uses only 1D convolutions, batch normalization, ReLU, dropout, and residual connections. To improve training, we further introduce a new layer-wise optimizer called NovoGrad. Through experiments, we demonstrate that the proposed deep architecture performs as well or better than more complex choices. Our deepest Jasper variant uses 54 convolutional layers. With this architecture, we achieve 2.95% WER using a beam-search decoder with an external neural language model and 3.86% WER with a greedy decoder on LibriSpeech test-clean. We also report competitive results on the Wall Street Journal and the Hub5'00 conversational evaluation datasets.
中文摘要:
在本文中,我们报告了在没有任何外部训练数据的端到端语音识别模型中LibriSpeech的最新结果。我们的模型Jasper仅使用一维卷积、批量归一化、ReLU、dropout和残差连接。为了改进训练,我们进一步引入了一种新的分层优化器,称为NovoGrad。通过实验,我们证明了所提出的深度架构与更复杂的选择一样好或更好。我们最深的Jasper变体使用54个卷积层。使用这种架构,我们使用带有外部神经语言模型的波束搜索解码器实现了2.95%的WER,使用LibriSpeech test-clean上的贪婪解码器实现了3.86%的WER。我们还报告了华尔街日报和Hub5'00会话评估数据集的竞争结果。

3. 【Language Modelling】Adaptive Attention Span in Transformers
【语言模型】Transformers 中的自适应注意力范围


作者:Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, Armand Joulin
链接:
https://arxiv.org/abs/1905.07799v2
代码:
https://github.com/facebookresearch/adaptive-span
英文摘要:
We propose a novel self-attention mechanism that can learn its optimal attention span. This allows us to extend significantly the maximum context size used in Transformer, while maintaining control over their memory footprint and computational time. We show the effectiveness of our approach on the task of character level language modeling, where we achieve state-of-the-art performances on text8 and enwiki8 by using a maximum context of 8k characters.
中文摘要:
我们提出了一种新颖的自我注意机制,可以学习其最佳注意力跨度。这使我们能够显着扩展Transformer中使用的最大上下文大小,同时保持对它们的内存占用和计算时间的控制。我们展示了我们的方法在字符级语言建模任务上的有效性,我们通过使用最多8k个字符的上下文在text8和enwiki8上实现了最先进的性能。
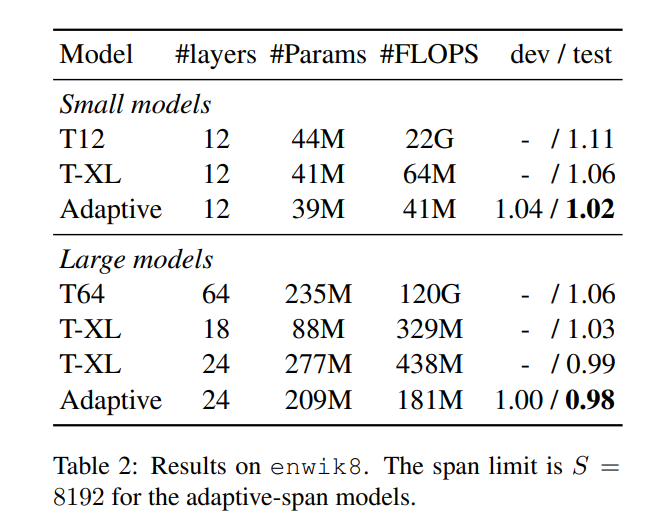

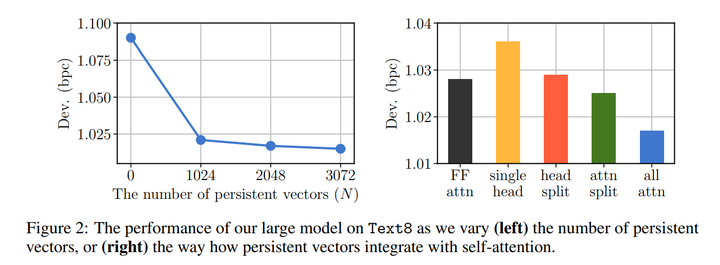
4. 【Language Modelling】Augmenting Self-attention with Persistent Memory
【语言模型】用持久记忆增强自注意力


作者:Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herve Jegou, Armand Joulin
链接:
https://arxiv.org/abs/1907.01470v1
代码:
https://github.com/lucidrains/x-transformers
英文摘要:
Transformer networks have lead to important progress in language modeling and machine translation. These models include two consecutive modules, a feed-forward layer and a self-attention layer. The latter allows the network to capture long term dependencies and are often regarded as the key ingredient in the success of Transformers. Building upon this intuition, we propose a new model that solely consists of attention layers. More precisely, we augment the self-attention layers with persistent memory vectors that play a similar role as the feed-forward layer. Thanks to these vectors, we can remove the feed-forward layer without degrading the performance of a transformer. Our evaluation shows the benefits brought by our model on standard character and word level language modeling benchmarks.
中文摘要:
Transformer网络在语言建模和机器翻译方面取得了重要进展。这些模型包括两个连续的模块,一个前馈层和一个自注意力层。后者允许网络捕获长期依赖关系,并且通常被认为是Transformer成功的关键因素。基于这种直觉,我们提出了一个仅由注意力层组成的新模型。更准确地说,我们使用与前馈层起类似作用的持久记忆向量来增强自注意力层。多亏了这些向量,我们可以在不降低变压器性能的情况下移除前馈层。我们的评估显示了我们的模型在标准字符和单词级语言建模基准上带来的好处。

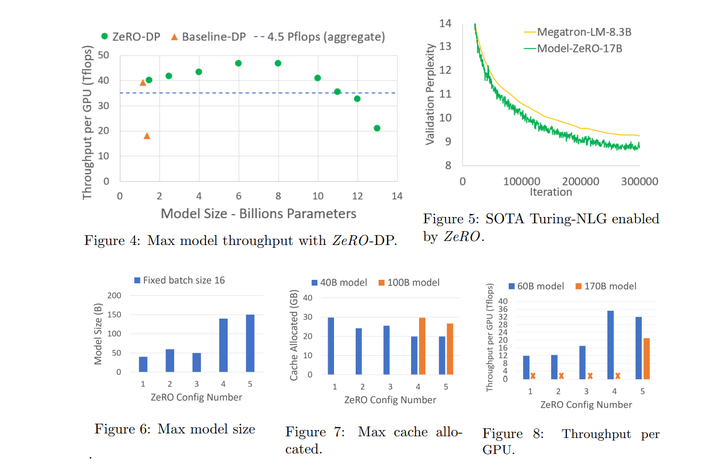
5. 【Language Modelling】ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
【语言模型】零:训练万亿参数模型的内存优化


作者:Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He
链接:
https://arxiv.org/abs/1909.01377v2
代码:
https://github.com/prolearner/hypertorch
英文摘要:
Large deep learning models offer significant accuracy gains, but training billions to trillions of parameters is challenging. Existing solutions such as data and model parallelisms exhibit fundamental limitations to fit these models into limited device memory, while obtaining computation, communication and development efficiency. We develop a novel solution, Zero Redundancy Optimizer (ZeRO), to optimize memory, vastly improving training speed while increasing the model size that can be efficiently trained. ZeRO eliminates memory redundancies in data- and model-parallel training while retaining low communication volume and high computational granularity, allowing us to scale the model size proportional to the number of devices with sustained high efficiency. Our analysis on memory requirements and communication volume demonstrates: ZeRO has the potential to scale beyond 1 Trillion parameters using today's hardware.
We implement and evaluate ZeRO: it trains large models of over 100B parameter with super-linear speedup on 400 GPUs, achieving throughput of 15 Petaflops. This represents an 8x increase in model size and 10x increase in achievable performance over state-of-the-art. In terms of usability, ZeRO can train large models of up to 13B parameters (e.g., larger than Megatron GPT 8.3B and T5 11B) without requiring model parallelism which is harder for scientists to apply. Last but not the least, researchers have used the system breakthroughs of ZeRO to create the world's largest language model (Turing-NLG, 17B parameters) with record breaking accuracy.
中文摘要:
大型深度学习模型提供了显着的准确性提升,但训练数十亿到数万亿个参数具有挑战性。现有的解决方案(例如数据和模型并行性)在将这些模型拟合到有限的设备内存中,同时获得计算、通信和开发效率方面表现出基本的限制。我们开发了一种新颖的解决方案,即零冗余优化器(ZeRO),以优化内存,极大地提高训练速度,同时增加可以有效训练的模型大小。ZeRO消除了数据和模型并行训练中的内存冗余,同时保持低通信量和高计算粒度,使我们能够以与设备数量成比例的方式扩展模型大小,并具有持续的高效率。我们对内存要求和通信量的分析表明:ZeRO有可能使用当今的硬件扩展超过1万亿个参数。
我们实现并评估了ZeRO:它在400个GPU上以超线性加速训练超过100B参数的大型模型,实现了15Petaflops的吞吐量。这表示模型大小增加了8倍,可实现的性能比最先进的方法增加了10倍。在可用性方面,ZeRO可以训练高达13B参数的大型模型(例如,大于MegatronGPT8.3B和T511B),而不需要科学家难以应用的模型并行性。最后但并非最不重要的一点是,研究人员利用ZeRO的系统突破创造了世界上最大的语言模型(Turing-NLG,17B参数),具有破纪录的准确性。

AI&R是人工智能与机器人垂直领域的综合信息平台。我们的愿景是成为通往AGI(通用人工智能)的高速公路,连接人与人、人与信息,信息与信息,让人工智能与机器人没有门槛。
欢迎各位AI与机器人爱好者关注我们,每天给你有深度的内容。
微信搜索公众号【AIandR艾尔】关注我们,获取更多资源❤biubiubiu~