
常识推理和NLI(natural language inference)

在上一篇文章中,我们介绍了什么是概念化和组合性,而常识推理对于判断新组合的可靠性是十分重要的。
往泛了说,常识推理是附属于自然语言推理(NLI)领域的一个子任务。除了之前提到的WSC之外,近年来面向NLI的benchmark任务数量在飞速增涨。尤其是2018年,涌现出了比以往任何时候都规模更大且数量更多的benchmark。


这些NLI benchmark主要涵盖了以下几种任务:指代消解(reference resolution),如Winograd Schema Challenge、WinoGrande;问答(question answering),如MCTest、RACE、NarrativeQA、CommonsenseQA;文本蕴含(textual entailment),如RTE Challenges、SICK;可信推断(plausible inference),如COPA、SWAG、ROCStories;直觉心理学(intuitive psychology),如Event2Mind、Story Commonsense;以及一些多任务benchmark,如bAbI、DNC等。
解决NLI问题的相关研究可以被大致分为三类:
1. 基于规则和知识的方法 (Rule and knowledge-based approaches)
2. 通用的人工智能方法 (Generic AI approaches)
3. 语言模型方法 (AI language model approaches)
【=== survey预警 不喜阅读综述的可直接跳到下方分割线 ===】
第一种基于规则的方法是从symbolic approaches延伸来的,它运用逻辑形式和过程(logical forms and processes)来推理。从亚里士多德的逻辑理论和演绎推理开始,人类历史上对于运用逻辑进行推理的研究已经持续了几百年。在此期间,逻辑学的理论在人工智能和语言学领域也得到了应用,比如Lakoff (1970) 用自然逻辑对语义进行表征。在1990s早期,符号方法在语言的知识表征和语义处理方面占据了主导地位,因此这一方法被大量用于解决NLI问题。
举例来说,Raina(2005) 将自然语言的句子解析成为逻辑形式,然后利用学习到的假设和似然对它们进行归纳,以确定是否可以用一组高似然的假设来证明一个句子蕴含另一个句子。Giampiccolo (2008) 运用了Wikipedia等外部语义知识源增强假设句中的信息,然后用人工撰写的逻辑规则将其映射到前提句中的单词。Gordon(2016) 创建了一套完备的人工编写的逻辑和常识规则,用于获取数据中的自然语言到逻辑形式的映射。
虽然手动编写逻辑规则以及构建语言到逻辑形式的映射的确在某些任务中非常有效,但这对于更大数量级的数据集来说是不可扩展的,因为在这些数据集中,所需的知识、语言和语义现象的变化要大得多。
从1990s中期到2010s早期,统计学方法在NLP领域占据了主导地位,也即后来的通用人工智能方法:基于数据的特征训练得到各种类型的统计模型。早期的方法常将各种词语匹配和其他词汇特征与人工编写的确定性规则或者传统的决策树模型相结合。其中词汇特征比如bag-of-words,语言特征比如有语义依赖、释义、同义词、反义词、超义词等。外部知识也常被用作训练数据特征的补充,例如第一次RTE挑战赛的最优方案使用了一个朴素贝叶斯分类器,其特征来自于在线搜索引擎的词共现率(co-occurrences)。
此后神经网络方法兴起,其最大优势在于模型能够主动地学到数据中的有用特征而不必依靠人为设定。随着ML和DL的发展,NLP领域形成了一种解决一般问题的范式:使用上下文词表示模型学习得到词表示(word representation)作为特征或直接用于下游任务的微调。在此类神经网络方法中,被重点关注的模块主要有注意力机制(attention mechanism)、记忆力增强(memory augmentation)、上下文模型和表示学习(contextual models and representations)。
第三种是语言模型方法。这一方法的基本假设是Wikipedia等文本中本身就隐含着常识性知识,而语言模型能够在训练时直接学到常识。这类方法通常需要两阶段的pipeline,首先做一个在大语料上自监督的预训练语言模型,然后在微调阶段将学习到的词嵌入运用于下游的任务,比如像WSC任务就可以在微调时当作普通的指代消解任务那样处理。然而,近期也有很多工作通过各类实验指出常识通常是隐式的,其实并不能被预训练语言模型很好地捕获到。
回到常识推理任务,一大难题就在于:常识要从哪里来?
据估计,典型的成年人所知道的常识性知识公理多达100,000,000条。而在NLI应用中,这些知识的缺乏正是目前的一大瓶颈。为了克服这一瓶颈,从早期的语义网络到最近的大规模常识知识图谱,人工智能领域几十年来一直在努力开发知识表征和各种知识资源。这些知识的表示形式通常有命题(propositions)、分类(taxonomies)、本体(ontologies)和语义网络(semantic networks)等。知识源主要包括有以下几大类:
一,语用知识资源(Linguistic knowledge)
在过去的30年以来,语言学资源一直是推动NLP领域发展的关键,这些句法、语义和话语结构的注释被大量用于机器学习模型的训练。1)标注语料库,如Penn Treebank,它的标注包括POS标签和基于无语境语法的句法结构,以及基于它构造的Penn Discourse Treebank添加了带注释的话语结构;2)词汇资源,如WordNet,与普通字典不同的是,WordNet是按照概念(即同义词列表)及其与其他词的语义关系(如反义词、次义词/超义词、蕴含等)来组织词的,类似的还有基于动词类的VerbNet等;3)框架语义,如FrameNet,所谓的框架(frame)是指关于原型事件和情境信息的认知数据结构,它也能表征动词语义;4)预训练语义向量,如著名的word2vec、GloVe等。
二,通用知识资源(Common knowledge)
这里的Common knowledge指的是经常被明确指出的、关于世界的众所周知的事实。由于这些事实经常在文字中得以陈述,因此直接从网络上挖掘这些事实创建知识库也相对容易。这类知识资源包括有YAGO、DBpedia、WikiTaxonomy、Freebase等,其中大多都是基于Wikipedia构建的。
三,常识知识资源(Commonsense knowledge)
与通用知识有所区别,常识对大多数人来说是显而易见的,几乎不会显式地阐述。需要注意的是,通用知识和常识知识并不总是完全区分开的,而且由于这些资源一般是从网络上收集得到的,所以许多常识知识库也包含有通用知识。
一些较出名的常识资源库有:
1)Cyc,它通过形式逻辑为基础的CycL语言编码了对象之间的本体关系,其中对象类型包括了实体、集合、函数和真理函数,库中含有700万个常识知识断言;
2)ConceptNet,它含有800多万个节点以及2,100多万条节点间的link,包括了来自多语种资源的知识,还有与其他知识图的链接,已经在许多NLI系统中得到了广泛使用;
3)SenticNet以及IsaCore,主要是用于情感分析的常识知识库;
4)COGBASE,它用一种新的形式表示了270万个概念和1000万个关于这些概念的常识,后来构成了SenticNet3的核心;
5)WebChild,基于从网页获取的一般性的"名词-形容词"关系构成的知识库。它与其他基于网页获取的知识库不同之处在于它主要是一个常识性知识库,这是因为WebChild是由各种语料库中收集的名词和形容词之间的细粒度概括性关系组成,而不是直接从维基百科获取结构化的通用知识。它的2.0版本含有200万个概念和活动以及1,800多万个断言;
6)TOMIC,是一个众包知识图谱,包含了30万个节点对应事件的文字描述以及约87.7万个"if-event-then"三段式,代表了日常事件之间的九种if-then关系。它表征的不是分类或本体,而是易于获取的推理知识;
7)ASER,和ATOMIC类似,也是一个含有活动、实体、事件和关系的知识图谱,但它的规模更大,包含了1.94亿个事件、6400万个关系和15种关系类型,并且是从非结构化文本数据中提取得到而非众包的。
虽然各类知识源众多,但由于人类拥有的知识量实在太大了,没有任何一种知识源是完整的,即使是最大的资源库也会缺少知识或出现错误,从而无法在NLI benchmark上得到过人的表现。
那么如何利用这些不完整知识库呢?主要有如下几种方法:
一,降维(Dimensionality reduction)。比如计算不同的知识图结构之间的相似度并进行类比,从而产生新的关系。这一方法的缺点在于无法创造新的term,而只是对知识图谱中的现有term产生置信度分数。
二,抽取式补全(Extractive knowledge base completion),通过生成新的关系来补全知识库。比如通过训练得到一个能分辨是错误关系还是知识库中的关系的神经网络,然后用来给拟议的新关系的真实性打分。
三,自动式补全(Automatic knowledge base completion)。这一方法的思路在于,新的关系除了能够从文本中提取,也能用现有的关系推断得到。比如对知识图中已有事件的时间关系进行概括,能排序获得新的时间关系。
【=============== 我是分割线 ===============】
上文介绍了几种方法和知识源,那么目前的SOTA在前面提到的benchmark上表现究竟如何呢?下图是一些公开了人类准确率的benchmark与目前SOTA的比较。
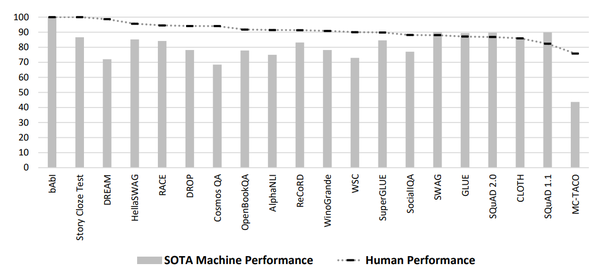

从图上可以发现bAbl这个benchmark似乎对于人类和模型是最容易的,都做到了100%(这可能也并不奇怪,因为bAbl的数据是按照简单的结构合成生成的,而这些更简单的语言模式可以被深度学习模型很好地捕获到)。在图中这些benchmark上,人类的准确率几乎都在80%~90%多,而模型在不同benchmark上的表现却差异很大。
虽然机器学习模型的确在部分数据集(如SQuAD 1.1和2.0)上的表现达到了人类基准甚至超过了人类,这是不是意味着这个任务已经得到解决了呢?奇怪的是,在模型表现超过人类的几个数据集上,人类的准确率是相对较低的。那是不是因为这些任务对于人类来说本身就太难了呢?
需要注意的是,这些对于人和机器的performance的衡量方法的确能让我们意识到任务的复杂性如何,但却并不能仅靠performance说明问题。这里有以下两个原因:
一、对于人类表现的衡量不一定准确。比如,评价方法对人类不友好。举例来说,SQuAD 1.1 中的人类错误大多是给出回答时遗漏了不必要的单词或短语导致的。另外,当人类数据是通过众包获得的时候,得到的performance也可能会偏低。比如在RACE数据集上,众包得到的准确率是73.5%,而人类专家的准确率是94.5%。因为众包的人一般是希望快速完成任务使收入最大化,所以可能不会像在日常环境中那样花很多时间去完成推理。
二、对于模型表现的衡量也不一定准确。比如,有些任务本身就是对机器更友好。举例来说,CBT语言建模的一个子任务:在无论是否有上下文段落的情况下,预测句子中的随机词。对于人类而言,预测某些类型的词(比如介词)是很困难的,在没有上下文语境时人类的准确率只有67.6%。但神经语言模型在捕捉模式的能力上更强,很容易就在这个子任务上超过了人类。另外,由于数据集本身是有bias的,加之机器学习模型的不可解释性(benchmark也没有要求解释性),模型的performance高并不一定能代表在这些任务上真正比人类做得好。
由此看来,对于NLI模型的评估亟需一个更广泛和多维度的评价指标,需要衡量的除了解决任务的能力,还需兼顾效率、可解释性、推广/泛化能力。
Ps:文中有些涉及到语言学的专业术语不确定有没有翻译正确,欢迎在评论区指正
参考文献:Recent Advances in Natural Language Inference: A Survey of Benchmarks, Resources, and Approaches