长尾目标检测中简单有效的目标为中心图像方法


2021年2月17日arXiv上传论文"A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection",作者来自美国三所大学和谷歌研究。


日常场景的目标出现频率遵循长尾分布。许多目标在场景为中心(scene-centric)图像中(例如,观光,街景)出现频率不多,无法训练目标检测器。相反,这些目标在目标为中心(object centric)图像中以较高的频率出现,因为获取的就是感兴趣的目标。文章建议利用目标为中心的图像改善对场景为中心的图像的目标检测。一方面,通过减轻在输入和标签空间这两个图像源之间的域间隔(domain gap),将目标为中心的图像转变为在场景为中心的图像中训练目标检测的有用示例;另一方面,在目标检测采用多阶训练方法,这样在绑定场景为中心图像的应用域同时,检测器从目标为中心图像中学习多样的目标外观。
在检测常见目标(例如车,人等)方面目标检测取得了显着进步。 但是,对于一些其他目标,它们在日常场景出现频率较低甚至很少出现(例如,单轮脚踏车,喂鸟器等),有限的训练数据会导致检测精度急剧下降 。 因此,这种场景为中心图像的目标实例“长尾”分布需要开发更好的算法。不过,在目标为中心图像中,这些目标出现的长尾效应得到缓解。
如图比较一下这两种图像:单轮脚踏车为例


本文提出的方法:1.将多个目标为中心图像拼接成景物为中心的图像,带来更多目标实例和类别、更复杂的背景和较小的实例;2.研究估算缺失目标边框的不同方法,只需将图像标签用于固定图像位置(例如中心裁剪、边角裁剪等),即可获得高可靠性;3.多阶段训练方法。
如图是作者的思想:主要解决三个问题(a)两个图像源之间的域间隔;(b)缺失的边框标签;(c)整合两个图像源进行训练。
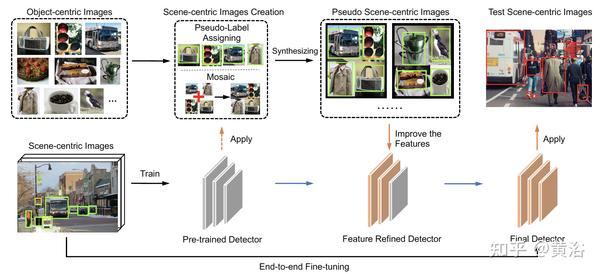

一方面,用可用标注的场景为中心图像对检测器进行预训练。 另一方面,将每个目标为中心图像的标签分配给内部的一组伪真值边框,然后将多图像拼接在一起形成用于检测的训练图像(称为伪场景为中心图像)。 用这些伪场景为中心图像微调这些预训练检测器以学习更好的特征,然后另一阶段是带标记的场景为中心图像进行训练,确保检测器的最终检测和定位性能。 绿色框表示(伪)真值; 红色框表示检测结果。
每个目标为中心图像都有一个目标类标签,但没有边框注释。 某些图像可能包含多个目标实例和类别,其中类标签仅指示最突出的目标。 因此,需要创建一组伪真值边框,它们可能包含每个图像的目标实例,并为每个实例分配一个类标签,以便用图像直接训练目标检测器。
如图是伪标签的产生方法:


(a) 固定位置, (b) 信任预训练检测器结果, (c) 信任预训练检测器和图像标注, (d) 区域抹去的定位(LORE),即抹除目标后分类器会失效。
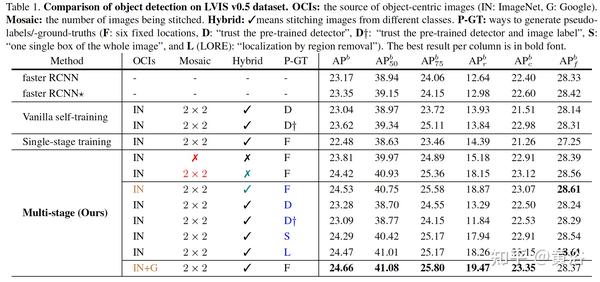
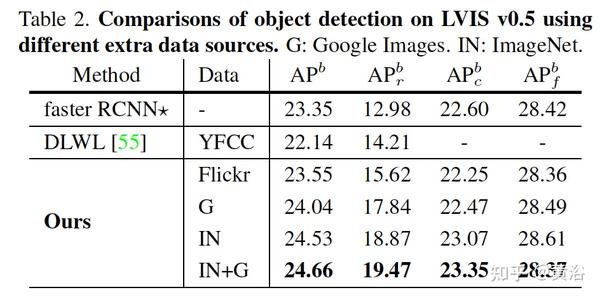
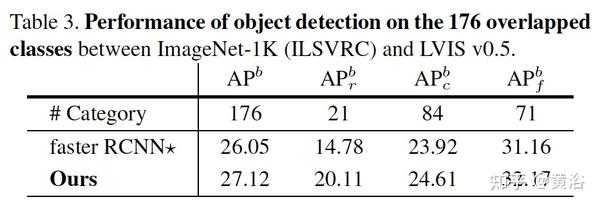
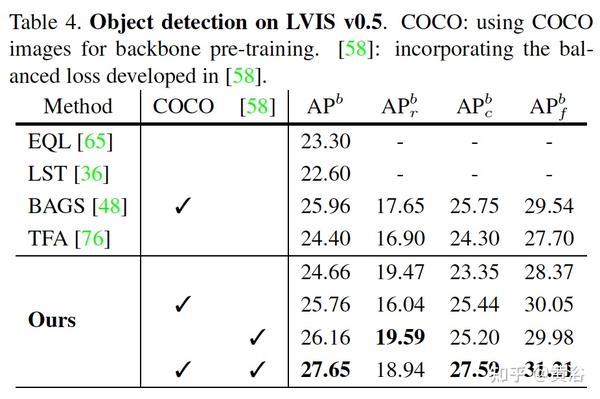
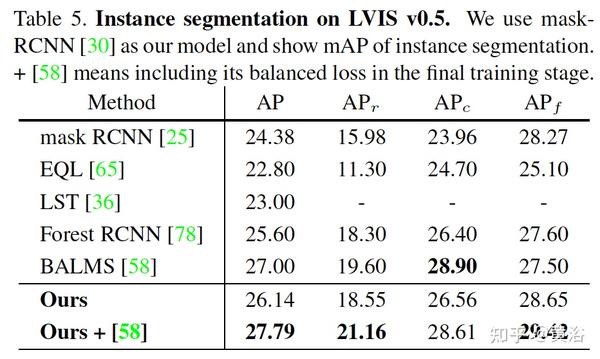
实验结果例子:检测器用faster-RCNN。
和几个baseline比较,包括self training,single stage training和 DLWL(Improving detection for low-shot classes with weakly labelled data)。