
机器学习入门:简单线性回归

一、首先,我们来了解一下什么是机器学习?
简单地说,机器学习是让机器从数据中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好。
二、机器学习步骤
1. 提出问题 明确的问题为我们后续的研究提供目标
2.理解数据
a采集数据 b导入数据 c查看数据集信息
3.数据清洗
数据预处理-从数据中提取我们想要的特征
4.构建模型
训练数据构建模型
5.评估
通过测试数据评估模型,看模型的准确率是多少。
三、什么是特征,标签?
我自己的理解是特征是我们研究对象的各项特征,是数据的属性
标签是我们想要得到的结果,对数据的预测结果
四、训练数据和测试数据
训练数据是用来建立机器学习模型,一般是80%
测试数据是验证模型的正确率
一般用正确率来衡量:正确率=正确分类个数/数据总数
1.从机器学习包中导入train_test_split
from sklearn.cross_validation import train_test_split
在安装sklearn中遇到了问题 安装了三次
第一次 安装成功 py3不能运行
第二次 文件显示还在py3的环境 卸载不了 conda list却不显示 也不能重装
第三次 错误显示request. exceptions 10045错误
第四次 CONDAHTTPEEROR HTTP 000 CONNECTTON FALLED for ur1
最后把activate conda关闭再重新安装便安装成功了。
2.建立训练数据和测试数据


train_test_split 下面有5个参数
a.arrays 数组
要注意的是,如果数据只有一个特征,但是它导入时并不是一个一维数组,那就需要将其转换为以为数组,可以使用reshape函数,array.reshape(-1, 1),如果是-1,就是重新排一排 (-1,1)是变成一列 (1,-1)是变成一行。
b.test_size float自己设置 0-1中间 代表测试数据所占比例 , int代表全部, or None不设置 默认为0.25
c. train_size : float, int, or None (default is None)同上 如果是none 跟随test的设置 在建模型时一般设置为0.8
d. random_state 随机变量状态: int, RandomState instance or None, optional (default=None)
e.stratify : array-like or None (default is None)
五、机器学习常用来解决相关性的问题
(一)相关性
相关性是两个或多个变量之间的关联程度
在这里我们举一个简单的例子,研究一下学生的学习时间与分数的相关关系。
1.导入字典
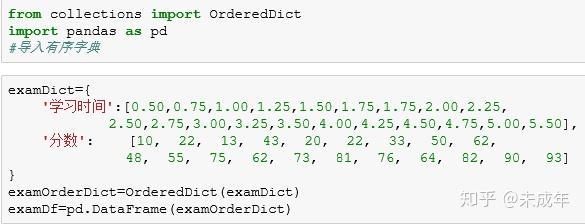

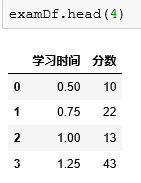
2.查看数据前五行
3. x叫做解释变量,y叫做被解释变量,在这里,学习时间作为解释变量,分数作为被解释变量。在机器学习中,特征是解释变量,标签是被解释变量,通过特征反映出来的结果就是标签。
exam_X=examDf.loc[:,'学习时间']
exam_y=examDf.loc[:,'分数']


一般用散点图来查看数据的基本状况。
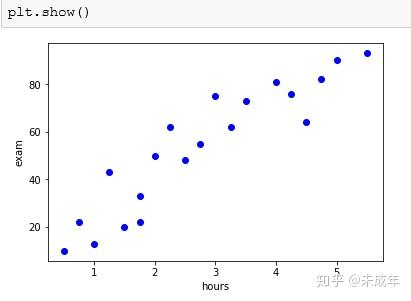
通过散点图我们可以看出随着学习时间的增大成绩也是提高的。
(二)协方差
公式 cov(X,Y)=E[(X-E[X])(Y-E[Y])]
协方差可以表示两组数据之间的相关性,但是容易受到数据的离散程度的影响
(三)相关系数
总体线性相关系数
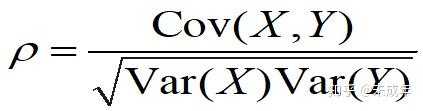

一般用的都是样本相关系数r
相关系数表示 除去标准差以后可以剔除变量变化幅度的影响,只是反应两个变量每单位变化的相似程度。
r=-1表示完全负相关(两个变量反方向变化 ), r=0表示不相关 (没有线性相关,可能有其他的关系), r=1表示完全正相关(两个变量同方向变化)。
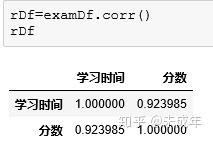
python中可以用corr函数求相关系数,r=0.923985表示学习时间与分数有很大的正相关关系。
值得注意的是:样本相关系数是总体相关系数的样本估计值,由于抽样波动,总体相关系数是个确定的值,样本相关系数是个随机变量,其统计显著性有待检验。
(四)最佳拟合线
在散点图上绘制一条误差和最小的直线
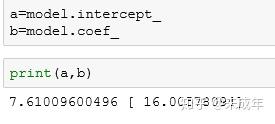
这里绘制出的直线方程式就是y=7.61+16x
(五)可决系数R平方
1.样本回归线是对样本数据的一种拟合,不同估计方法可拟合出不同的回归线,拟合的回归线与样本观测值总有偏离。
样本回归线对样本观测数据拟合的优劣程度称为拟合优度。
2.总变差的分解
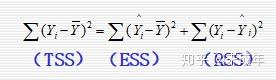
总变差 (TSS):应变量Y的观测值与其平均值的离差平方和(总平方和)
解释了的变差 (ESS):应变量Y的估计值与其平均值的离差平方和(回归平方和)
剩余平方和 (RSS):应变量观测值与估计值之差的平方和(未解释的平方和)
回归平方和(解释了的变差ESS) 在总变差(TSS) 中所占的比重称为可决系数,用r平方表示。
作用:可决系数越大,说明在总变差中由模型作出了解释的部分占的比重越大,模型拟合优度越好。反之可决系数小,说明模型对样本观测值的拟合程度越差。
特点:
●可决系数取值范围:0<= r^{2} <=1
●随抽样波动,样本可决系数是随抽样而变动的随机变量
●可决系数是非负的统计
(六)相关系数与因果关系
两个变量有相关关系并不能代表一定有因果关系。
一般要先去发现两个变量间的相关关系,再去研究它们之间是否有因果关系。
六、逻辑回归
1.逻辑回归本质上是用于一个二分类的算法,(二分类就是一个数据只有这两个标签,比如:好/不好)
2.逻辑函数
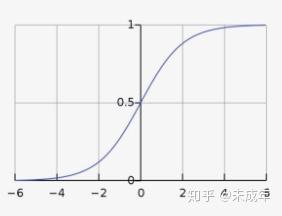
逻辑函数值y表示当分类结果的标签为1时x对应的值
3.决策面
对于分类问题,机器学习模型就是将训练数据集的特征和标签转换成一个决策面,在逻辑回归中的决策面就是当y>=0.5时特征=1,y<0.5时特征=1。
4.分类与回归的区别
a输出数据类型不一样,分类数据输出离散数据 回归输出连续数据类型
b分类算法得到的是决策面,回归算法得到的是最优拟合线
c分类算法中用正确率评估,回归算法用决定系数R平方评估
5.机器学习算法与机器学习模型的区别
机器学习算法处理某一类型问题的通用算法框架,机器学习模型是通过机器学习算法加上训练数据用来处理某一类问题的模型
简单地说:机器学习模型=机器学习算法+训练数据
