
可微编程-自上而下的产品形态 5 Swift中的自动微分

原文地址: Swift中的自动微分
介绍
自动微分(Automatic differentication,AD)又称算法微分(algorithmic differentication),是一类用来获得函数导数的技术。函数可以表示为初等算子的组合,其导数是众所周知的。虽然可以通过不同的技术计算偏导数,但最常见的是逆方向上链规则的递归应用,称为逆模式AD。逆模式AD计算矢量雅可比积,即对每个输入参数的偏导数,它已经成为实现基于梯度的学习方法的前提。AD有着丰富的背景知识,这里有一些很好的介绍:介绍机器学习中的自动微分综述和自动微分。
大多数AD实现工作在函数张量程序的图形表示上,而且许多AD实现的表示性和可扩展性有限。基于define-by-run编程模型(支持动态计算图)的框架通常缺乏执行完整程序静态分析和优化的能力,并且很难提前诊断错误和定位硬件加速器。
Swift for TensorFlow项目旨在为AD提供最佳的类内支持,包括最佳优化、失败情况下的最佳错误消息,以及最灵活和表现力。为了实现这一点,我们在Swift编译器中构建了对AD的支持。此外,由于AD对更广泛的科学和数值计算社区很重要,我们决定将AD构建为一个与TensorFlow支持完全正交的通用特性-TensorFlow Swift库使用Swift语言本身的AD特性计算梯度。
相关工作
半个世纪以来,自动微分一直是科学计算和高性能计算领域的研究课题。传统的工具,如OpenAD、TAPENADE和ADIFOR,是转换现有源代码的工具。有许多先进的技术可以提高用FORTRAN编写的派生程序的性能,但是这些工具并没有在机器学习领域得到广泛的应用。最近的AD系统,如 Stalin∇(发音为斯大林格勒,在Scheme中可用)、DiffSharp(在F∇中可用)和AD(在Haskell中可用)通过将差分运算符集成到语言中实现了良好的可用性,并配备了一整套AD功能(如正向/反向、嵌套AD、Hessians、Jacobians、定向衍生工具和检查点)。它们将AD与函数式编程语言紧密地结合在一起。
深入学习社区的研究人员在Python和C++中构建了很多的AD实现,包括Autograd、TensorFlow、Pytorch等。其中一些库被实现为一个独立的DSL(图)的转换,其中一组封闭的操作符。其他的则直接在源语言的一个子集上使用运算符重载来实现。尽管这些库已得到广泛采用,但那些提前利用AD的库并没有公开易于使用的编程模型,而那些具有更友好的编程模型的库则缺乏执行更优化的AD的静态分析。
最近的两个项目(Tangent和Myia)将他们的AD建立在源代码转换(SCT)的基础上,这种技术在深度学习时代(如斯大林)之前的高级AD系统中很常见。这两种工具都将Python子集解析为AST,并将函数转换为AST或函数IR中的派生函数。这两个项目属于深度学习工具中的一个类别,之前没有得到充分的探索:“前置微分”和“作为代码的模型”,如下图所示(引用:Tangent)。虽然这些工具正在突破Python的界限,但其他研究项目,如DLVM,直接在类似Swift中间语言(SIL)的编译器IR上试验SCT-AD。
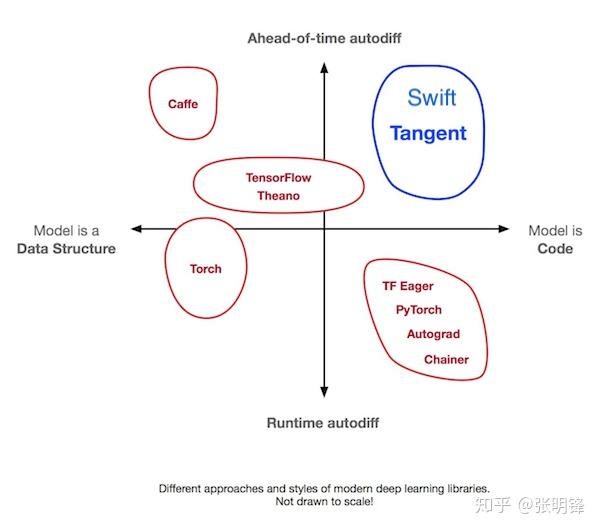

这个图的水平轴可能会提醒人们如何权衡紧急执行和图形构建:在紧急执行中,模型是用户代码的子集。在图形模式下,模型是一种数据结构,用迷你语言表示一些代码。图形程序提取技术通过将图形还原为由编译器管理的实现细节,将两者结合起来。图中的垂直轴添加了第二个维度,即自动微分,Swift通过将AD作为语言和编译器的核心特性来实现完全相同的功能。
反向模式AD的工作原理
自动微分的方法主要有两种:在运行时记录程序执行情况和提前对程序进行静态分析——主要区别在于解释与编译。define-then-run方法通常实现为类似于AD文献中的源代码转换(SCT)技术的计算图转换,define-by-run方法通常实现为运算符重载(OO)。
给定函数f:(T0,T1,…,Tn)->U,逆模AD将f转换为计算每个参数的偏导数的函数。如下图所示,新函数有两个部分:原始f_prim和伴随f_adj。f_prim计算原始结果,同时存储原始中间值以供f_adj重用。f_adj计算f相对于参数的偏导数。


用于存储这些值的数据结构称为tape,也称为Wengert list。它是一种数据结构,由程序跟踪和中间值组成。赋值的每一个右边都是一个具有相应导数的基元操作。在编译器术语中,Wengert列表是一个完全展开的静态单赋值(SSA)表单。在primal的执行过程中,由primal生成的将用于伴随计算的中间值被写入磁带。当涉及到控制流时,分支条件和循环计数器也被推送到磁带。
在f_adj中,然后调用f_prim中每个操作的导数,并按相反的顺序从磁带中读取中间值。当偏导数的积累达到参数时,我们得到了关于参数的偏导数。这些值有时也被称为f的灵敏度。
注意,f_adj有一个附加参数:seed。微分种子表示反向传播的偏导数。例如,如果f被g调用,我们想微分g得到∇g=∂g/∂(x0,x1,x2),那么g对应的伴随g伴随将把∂g/∂y作为f伴随的种子传递给f伴随,这样f伴随将产生∇g。当我们想计算∇f=∂f/∂(x0,x1,x2)时,我们只需传入∂y/∂y,即1作为种子。
Swift中的自动微分
在本节中,我们将深入研究语法扩展和特定于AD的api,这些api允许用户定义、使用和自定义AD。
使任意类型支持微分
我们希望我们的AD系统能够完全扩展到这样的程度:用户可以请求采用自己定义的数字类型的函数的导数,甚至可以使用这个特性来实现依赖于数据结构的算法,如树递归神经网络。因此,Swift编译器对单个数学函数或它应该支持的类型没有任何假设。我们使库设计人员和开发人员能够轻松地定义任何类型来表示实向量空间,或声明函数是可微的,所有这些都是纯Swift代码。
要做到这一点,Swift的AD系统需要知道一些与差异化兼容的类型的关键要素,包括:
- 类型必须表示任意排列的向量空间(张量所在的空间)。此向量空间的元素必须是浮点数字。有一个关联的标量类型也是浮点数字类型。
- 如何从标量初始化与此参数具有相同维数的参数的伴随值。当参数对输出没有贡献时,这将用于初始化零导数。
- 如何从标量类型的值初始化种子值。这将用于初始化微分种子-通常为1.0,表示dy/dy。注意:伴随中的种子类型可以是可选的,因此当没有反向传播的伴随时,该值将设置为nil。但是,这将导致TensorFlow的Tensor类型的性能问题(导致发送/接收的可选检查)。我们需要完成常量表达式分析的实现,以便能够折叠掉可选的检查。
- 这种类型的值在伴随计算中如何在数据流扇入处合并。根据和积规则,这通常是加法。加法是在数字协议上定义的。
浮点标量已经具有上述属性,因为它符合从数字协议继承的浮点协议。类似地,我们定义了一个矢量数字协议,它声明了表示矢量空间的四个要求。
public protocol VectorNumeric {
associatedtype ScalarElement
associatedtype Dimensionality
init(_ scalar: ScalarElement)
init(dimensionality: Dimensionality, repeating repeatedValue: ScalarElement)
func + (lhs: Self, rhs: Self) -> Self
func - (lhs: Self, rhs: Self) -> Self
func * (lhs: Self, rhs: Self) -> Self
}
矢量数字和数字/浮点在语义上是不相交的。我们说,当类型符合FloatingPoint时,它支持标量微分。我们说,当类型符合VectorNumeric时,它支持向量微分,而其ScalarElement支持标量微分(即,符合浮点协议)。
注意:根据标准库,Numeric只适用于标量,而不适用于向量等聚合数学对象,FloatingPoint也是如此。今天我们使VectorNumeric具有重复的运算符,但是我们希望在Swift标准库中为更通用的数字协议提供一个案例。
要微分类型支持,用户只需向FloatingPoint或VectorNumeric添加一致性。例如,TensorFlow的Tensor<Scalar>类型支持在关联的类型Scalar符合FloatingPoint时,通过有条件地符合VectorNumeric协议来进行微分。
extension Tensor : VectorNumeric where Scalar : Numeric {
typealias Dimensionality = [Int32] // This is shape.
typealias ScalarElement = Scalar
init(_ scalar: ScalarElement) {
self = Raw.const(scalar)
}
init(dimensionality: [Int32], repeating repeatedValue: ScalarElement) {
self = Raw.fill(dims: Tensor(dimensionality), repeatedValue)
}
func + (lhs: Tensor, rhs: Tensor) -> Tensor { ... }
func - (lhs: Tensor, rhs: Tensor) -> Tensor { ... }
func * (lhs: Tensor, rhs: Tensor) -> Tensor { ... }
}
由于VectorNumeric足够通用,可以提供微分所需的所有成分,而且编译器不会对已知类型进行特殊假设,因此用户可以使任何类型支持自动微分。下面的示例显示了一个通用树结构树<Value>,它以代数数据类型的形式编写,通过使用模式匹配递归地定义操作,在条件上符合矢量数字。现在,可以微分树上的函数<Value>!
indirect enum Tree<Value> {
case leaf(Value)
case node(Tree, Value, Tree)
}
extension Tree : VectorNumeric where Value : VectorNumeric {
typealias ScalarElement = Value.ScalarElement
typealias Dimensionality = Value.Dimensionality
init(_ scalar: ScalarElement) {
self = .leaf(Value(scalar))
}
init(dimensionality: Dimensionality, repeating repeatedValue: ScalarElement) {
self = .leaf(Value(dimensionality: dimensionality, repeating: repeatedValue))
}
static func + (lhs: Tree, rhs: Tree) -> Tree {
switch (lhs, rhs) {
case let (.leaf(x), .leaf(y)):
return .leaf(x + y)
case let (.leaf(x), .node(l, y, r)):
return .node(l, x + y, r)
case let (.node(l, x, r), .leaf(y)):
return .node(l, x + y, r)
case let (.node(l0, x, r0), .node(l1, y, r1)):
return .node(l0 + l0, x + y, r0 + r1)
}
}
static func - (lhs: Tree, rhs: Tree) -> Tree { ... }
static func * (lhs: Tree, rhs: Tree) -> Tree { ... }
static func / (lhs: Tree, rhs: Tree) -> Tree { ... }
}
函数何时可微?
一旦我们有了支持微分的类型,我们就可以在这些类型上定义任意函数。因为我们的目标是一个开放和可扩展的系统,所以我们使编译器不依赖于实际操作——它不具备数字标准库函数的特殊知识,也不微分原始运算符和其他函数。我们递归地确定函数的可微性基于:
- 它的类型标志:输入和输出是支持标量微分还是矢量微分
- 它的可见性:如果Swift编译器看不到函数体(例如C函数或是闭包的参数),那么它是不可微的
- 它的数据流:是否所有的指令和函数调用都可以沿着要微分的数据流进行微分
由于规则是递归定义的,所以它需要一个基本情况,这样编译器将停止查找函数调用并确定可微性。在AD中,表示这种基本情况的函数通常被称为“原语”。为此,我们引入了@可微属性。用户可以使用@differentiable来给出任何保证可微性的函数。该属性有几个相关参数:
- 差异化模式(目前只支持反向模式)
- primal(可选,如果伴随需要检查点,则应指定)
- 伴随
例如,可以定义tanh的导数,并使AD系统将其视为“原始”,这是确定可微性时的基本情况。


正如用户所期望的那样,为了排除具有无法微分的参数的函数,@differentiable可以使用with respect to:显式设置参数。此外,self可以设置为一个微分参数,因为self可以是一个数值类型-Swift标准库和TensorFlow库中的数学操作都被定义为实例方法,例如FloatingPoint.squareRoot()和Tensor.convalved(with filter:strips:padding:)。
extension Tensor {
// Differentiable with respect to `self` (the input) and the first parameter
// (the filter) using reverse-mode AD. The corresponding adjoint is `dConv`.
@differentiable(reverse, withRespectTo: (self, .0), adjoint: dConv)
func convolved(withFilter k: Tensor, strides: [Int32], padding: Padding) -> Tensor {
return #tfop("Conv2D", ...)
}
func dConv(k: Tensor, strides: [Int32], padding: Padding,
y: Tensor, seed: Tensor) -> Tensor {
...
}
}
使用自动微分
我们目前支持两个微分运算符:#gradient()和#valueAndGradient()。前者接受一个函数并返回一个计算偏导数的函数。后者接受一个函数并返回一个计算原始值和矢量雅可比积的函数。一个简单的例子如下所示:
@differentiable(reverse, adjoint: dTanh)
func tanh(_ x: Float) -> Float {
... some super low-level assembly tanh implementation ...
}
func dTanh(x: Float, y: Float, seed: Float) -> Float {
return (1.0 - (y * y)) * seed
}
func foo(_ x: Float, _ y: Float) -> Float {
return tanh(x) + tanh(y)
}
// Get the gradient function of tanh.
let dtanh_dx = #gradient(tanh)
dtanh_dx(2)
// Get the gradient function of foo with respect to the first parameter.
let dfoo_dx = #gradient(foo, withRespectTo: .0)
dfoo_dx(3, 4)
请注意,#gradient(foo,与:.0相关)的实现仍在进行中。
Swift编译器中的自动微分
Swift中的自动微分是作为静态分析实现的编译器转换。AD通过在功能性IR-like-SSA表单上实现而受益,因此我们的实现是对Swift中间语言的转换。微分过程是强制降低过程管道的一部分,在图形程序提取之前运行。
在反向模式下对一个函数进行微分时,编译器生成包含相应“原始代码”和“伴随代码”的单独函数,这些函数依次计算计算矢量雅可比积。
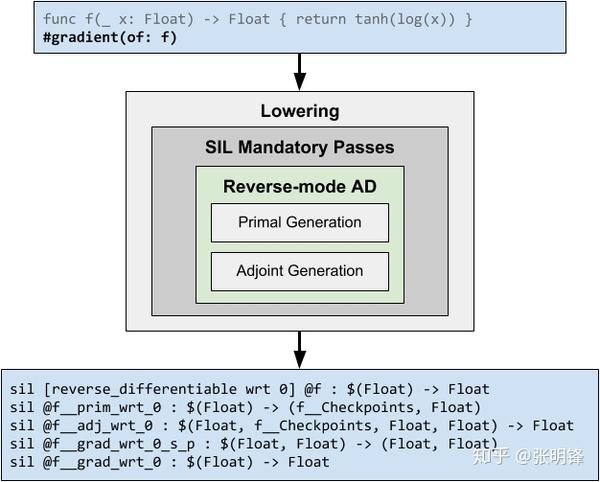

当#gradient()运算符应用于函数f:(T0,T1,…,Tn)->U时,编译器检查此函数上是否存在@differentiable属性。如果这样做了,编译器将直接调用这个已声明的伴随,并传入原始输入参数、原始结果和种子。否则,编译器会深入到函数中,并尝试区分其中的指令和函数调用。在此过程中,编译器生成:
- 一种结构类型C_f,其成员包括作为存储属性的原始中间值和强类型磁带(仅当存在任何控制流或循环时)。出于实现建模的目的,我们将此结构称为“检查点”。
- 一个原始函数f_prim:(T0,T1,…,Tn)->(C_f,U),返回原始检查点和原始结果。
- 一种伴随函数f_adj:(T0,T1,…,Tn,C_f,U,U)>(T0,T1,…,Tn),它接受原始检查点、原始结果和种子,并返回向量雅可比积。
- 一个“规范梯度”(一个可种子的,结果保持的差分函数)f}U可以梯度:(T0,T1,…,Tn,U)—>(U,T0,T1,…,Tn),它在内部调用f}U prim,并使用primal的返回调用f}adj。此函数的最后一个参数接受一个分化种子。此函数返回原始结果和矢量雅可比积。
最终确定的梯度函数∇f:(T0,T1,…,Tn)->(T0,T1,…,Tn),它使用默认种子1在内部调用f}u can}u grad,并丢弃第一个结果(如果}valueAndGradient()是微分运算符,则将使用第一个结果)。
存在多个函数来包装标准梯度函数fúu-canúu-grad,因为我们将支持各种AD配置,例如#gradient()和#valueAndGradient()。我们期望最终的梯度函数∇f是内联的,并应用其他常规优化过程,以公开原始伴随数据流并消除死代码。
Swift中的AD涉及对语法、类型检查器、标准库、SIL指令集、编译器传递管道甚至运行时(用于磁带操作)的更改。详细的实现超出了本白皮书的范围。综上所述,目前我们已经实现了基础设施和整个工作流程,但是原始生成和伴随生成中的代码合成,包括控制流图规范化、循环计数器插入和磁带管理,仍然是一项工作。这意味着今天的微分算子只在有一个@differentiable属性指定伴随(或同时指定原始和伴随)时才起作用。完成AD实施是我们的当务之急。
未来方向
更好的语法
在像Swift这样的通用编程语言中,AD是一个非常规的特性。为了允许用户指定要区分的形式参数,并使其能够很好地与类型检查器一起工作,我们使用35; literal语法,该语法接受参数索引或self,并在Swift AST中将其解析为一个不同的表达式。但是,我们更愿意将微分算子定义为正则泛型函数。
Flow-sensitive微分算子
如文中所述,我们最初在函数上提供两个微分算子:#gradient和#valueAndGradient。但是,区分功能并不能提供与
let y = log(x)
#gradient(y, wrt: x)
... 其中#梯度是一个有效的流敏微分算子。然而,从技术的角度来看,我们最初开发的函数到函数变换甚至是流敏感微分的基础。一旦完成了基础,就可以考虑并实现顶部的句法特征,例如,实现更具表现力的用户代码。
内联伴随定义
在为函数定义自定义伴随时,今天我们使用属性@differentiable(reverse,adjoint:someAdjointFunction),其中someAdjointFunction被定义为越界。但是,也存在一些问题:
- adjoints从来不是由用户直接调用的,所以要求用户用独立的函数名定义这样的函数是没有意义的,
- 伴随词的越界定义也使得用户很难在原始计算中自定义检查点,3)@differentiable使用混乱的索引来引用参数进行微分。为了解决这些问题,一个可能的解决方案是引入带关键字伴随和wrt的内联语法:
func foo(_ a: Float, _ b: String) -> Float {
let x = ... a ...
let y = ...
return y
adjoint let seed wrt a, b { // `seed` is the backpropagated value.
return ... x ... * seed
// ^
// The primal value `x` falls out of lexical scoping, and will be checkpointed.
}
}
不透明闭包的判别与动态方法调度
静态微分函数要求编译器可以看到函数体。然而,这限制了微分算子的表达能力。例如,用户不能对具有函数类型的函数参数应用渐变,因为编译器不能总是看到原始函数的主体。


一个潜在的解决方案是引入一个新的函数调用约定@convention(可微的),这将导致函数引用携带它们的原始和伴随函数指针。这使得编译器可以直接调用primal和adjoint,而无需查看函数声明。
微分属性
现实世界的模型通常被写成声明参数的结构类型,但是梯度表达式语法中的微分参数目前只支持参数索引或自。当预测函数被定义为类型上的实例方法时,如何表示“对所有参数的差异预测(for:)”?
一种可能性是利用程序综合生成表示模型类型中所有参数的聚合类型,并使微分算子梯度返回这样的聚合值。我们已经开始试验这种方法,但需要进一步发展这些想法。
衍生操作
一些机器学习模型需要对某些值操纵梯度,例如梯度剪裁。Tangent在Python中提供了语法扩展等特性。我们感兴趣的是找出表达衍生手术的最佳编程模型,例如:引入一个编译器已知的replacegradent(of:)API。
func prediction(for input: Tensor<Float>, parameters: Tensor<Float>) -> Float {
var prediction = input
for _ in 0...5 {
// Gradient clipping.
replaceGradient(of: prediction) { dPred in
max(min(dPred, 1), -1)
}
prediction = lstm.prediction(for: input, parameters)
}
return prediction
}
检查点
ML训练通常要求的一个特性是能够权衡计算和较低的内存消耗,因为向后传递保留原始计算的检查点,以防止伴随计算中的重新计算。有选择地丢弃和重新物质化原始值是一种常见的技术,称为检查点。已有数十年的研究成果,如二项式检查点。我们希望将这些技术直接集成到我们的模型中。
高阶微分
扰动混淆和灵敏度混淆是差分算子在SCT技术中嵌套使用的两个常见缺陷,需要用户注意才能正确解决。Haskell的ad包中rank-2多态性的应用消除了敏感性混淆,但是Swift的类型系统现在不支持这种情况。为了支持Swift中具有良好语义和可预测行为的高阶微分,我们需要教导编译器谨慎地发出诊断并拒绝格式错误的情况。
前进模式
我们现有的AD基础设施已经为前向模式广告预先分配了空间,例如@differentiable属性的第一个参数。虽然这不是一个通常要求的特征,但它将使Hessian向量积的有效计算成为优化方法研究的基础。它也比反向模式AD更容易实现,并且可以在正向和反向混合方面进行进一步的工程探索。
若有收获,就赏束稻谷吧
0 颗稻谷
