
VLDB 2021 论文推荐(续)

本篇是之前回答的补充:
索引,事务和软硬件协同设计
RAMP-TAO: Layering Atomic Transactions on Facebook’s Online TAO Data Store
这篇获得了最佳工业论文奖(Best Industry Paper Award)。
2013 年 Facebook 就公布了 TAO 社交图谱存储系统,文中提到,开发团队渴望支持事务(跟Spanner的动机一样,由此可见事务还是蛮重要的),RAMP-TAO 是一个在 TAO(最终一致性)上提供事务的协议,同时仍保持系统的总体可靠性和性能。
Facebook 的研究表明,RAMP-TAO 在生产环境只带来 0.42% 的内存开销,但能使超过 99.99% 的读操作只需读一次本地缓存,其尾延迟(tail latency)与现有 TAO 的读操作相同。
RAMP-TAO 灵感来自于 Read Atomic Multi-Partition (RAMP) 协议,RAMP 协议的原论文提出了一个新的隔离级别——Read Atomic(RA),RA 隔离级别不允许出现 fractured reads,即每个事务的更新都应该对其他事务可见,例如,如果一个事务 T1 写了 x = 1 和 y = 1,事务 T2 不应该读到 x = 1 和 y = null 的旧版本数据。RA 隔离级别对一个最终一致性的存储系统来说非常有用。
fractured read 形式化的定义如下:

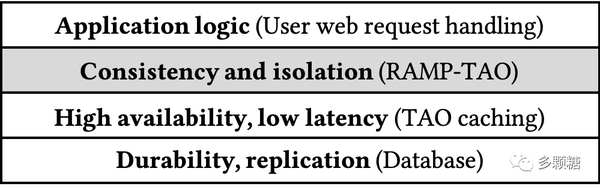
论文中提到,虽然这项工作基于 TAO 实现,但这些特性对于大规模、适合大量读工作负载的系统来说是至关重要且通用的,可以成为其他系统的解决方案。其系统架构如下图所示。
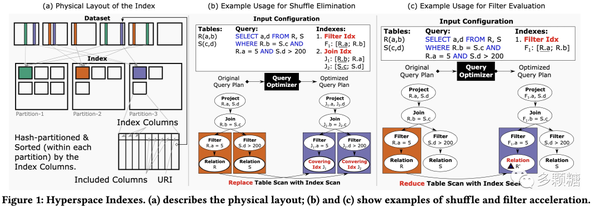
Hyperspace: The Indexing Subsystem of Azure Synapse
本文介绍微软 Azure 团队开源的 Hyperspace 的设计与实现经验。Hyperspace 脱胎于 Azure Synapse,后者是一个基于 Spark 和 T-SQL 的数据湖。而 Hyperspace 是 Spark 的索引子系统,微软宣称无需修改应用程序代码即可加速 Spark 查询和工作负载。
Hyperspace 支持非聚簇索引,有以下特性:
- 列存(Columnar)。索引使用列存(Parquet 格式),这样不仅能够从社区贡献和硬件进步中获益,还能利用向量化和剪枝等技术来加速索引扫描;
- 哈希分区 & (可选的)排序。索引支持哈希分区分散存储并按索引字段排序,能够提升查询效率;
- (可选的) Lineage Tracking。每个索引(可选的)持有指向底层表的指针/引用,如果该表没有主键或聚簇索引,可以通过文件/Blob/文件夹的 URI 来访问底层数据。
Big Metadata : When Metadata is Big Data
本文指出,云数据仓库的兴起,数据已经增长到 EiB 级别,这种增长伴随着存储对象和元数据的增长。Google 提出一种分布式元数据的管理系统,为表存储大量的列和块级元数据,并将其组织成一个系统表,其特点有:
- 支持 ACID 属性
- 支持批处理和流处理 API
- (几乎)无限的可扩展性,扩展方式跟底层数据类似(使用过 Dremel 的列存格式 Capacitor)
- 高性能。通过分布式执行技术和列存,将复杂度降到最低
Implementing DBMS
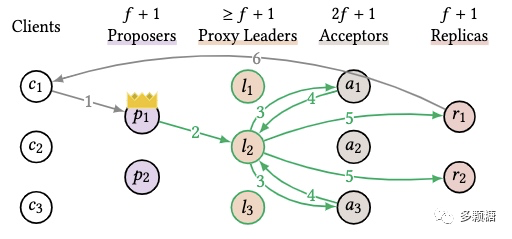
Scaling Replicated State Machines with Compartmentalization
复制状态机是许多分布式系统和数据库的重要组成部分,现有协议孤立地解决了不同的瓶颈,但仍没有完整的解决方案,当你修复一个瓶颈时,另一个瓶颈又出现了。本文提出 compartmentalization 优化方案,引入 Proxy Leaders 解决单领导者的性能和吞吐量问题。有趣的是文中提到,可以将此方案直接应用到 MultiPaxos 等协议中提升性能,而不必重新实现一个全新的协议。
本文一作 Michael Whittaker 写过一些非常优秀的分布式系统的博客,我基本都读过。博客地址:https://mwhittaker.github.io/blog/
事务
Database Isolation By Scheduling
本文提出一种将隔离性从整个事务管理器中单独拆分出来的方法,从而将事务管理器分解成各个模块化服务。本文还提出一个事务调度器 DIBS,用来优化谓词锁性能。数据显示 DIBS 能够提升现有数据库例如 SQLite 和 MySQL 的事务吞吐量。
Epoch-based Commit and Replication in Distributed OLTP Databases
许多现代分布式 OLTP 数据库都建立在两阶段提交和同步复制之上,本文介绍一个新的分布式 OLTP 数据库 COCO,COCO 将事务分成 epoch(共识算法的提案编号),并将整个 epoch 事务作为一个单元(被共识算法)提交,通过这种方式可以降低 2PC 和复制的开销。
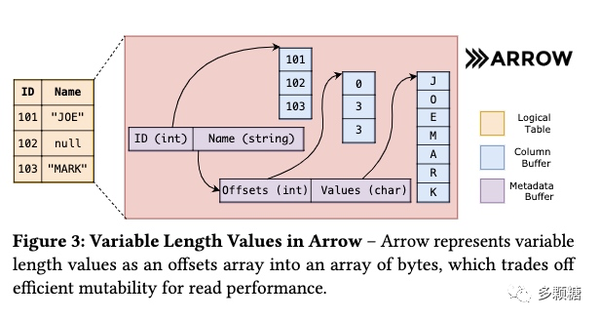
Mainlining Databases: Supporting Fast Transactional Workloads on Universal Columnar Data File Formats
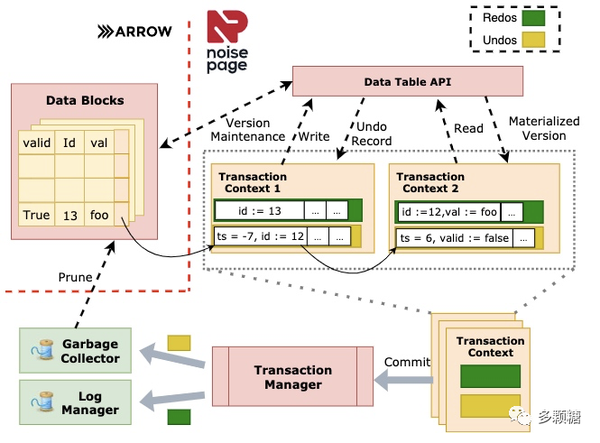
本文是数据库网红 CMU database group 的 paper,介绍他们的 NoisePage(一个 self-driving database)如何快速将来自 OLTP 系统的数据转换成列存格式。其主要基于 Apache Arrow 来实现,Arrow 现在已经成了许多内存列存数据库的首选,被用在 Apache Drill, Apache Impala, Pandas 中,ARROW 的原理如下图所示。
NoisePage 的整体架构也给了出来,本文主要介绍了其中事务管理器、表组织、垃圾回收和恢复组件。篇幅原因在此不再展开,这篇文章以后考虑展开来解读。
Encrypted Storage and Blockchain
Building Enclave-Native Storage Engines for Practical Encrypted Databases
达摩院孙园园博士等人发表的论文,探讨如何在云端构建安全数据库。本文讨论了加密数据库存储引擎,并提出了 Enclage 存储引擎,包括两个组件:一个类 B+-tree 索引的 Enclage 索引;一个类堆文件的表存储 Enclage store。架构图我就不放出来了,设计实现还是比较复杂的。
流数据(Data Streams)
这部分看得头疼(但也要看)。
Hazelcast Jet: Low-latency Stream Processing at the 99.99th Percentile
Jet 是由 Hazelcast 开源的分布式计算引擎,专为高性能流处理和快速批处理设计,Hazelcast 设计的内存数据网格(IMDG)能够在内存分区和复制的数据结构,以提供高性能和高扩展性。本文介绍 Jet 的设计和如何最大限度地使用每个 CPU 核的性能,以及吸取的经验教训。
Watermarks in Stream Processing Systems: Semantics and Comparative Analysis of Apache Flink and Google Cloud Dataflow
水位线(Watermark)在流处理引擎中非常重要,用来计算流数据时间的完整性。本文探讨了水位线及其重要性,也提出水位线不能满足的点,重点分析了 Flink 和 Google Cloud Dataflow 的水位线实现。
关于水位线的作用也会在我的新书中进行解释,新书预计2021年1月出版。
感想
华人大佬越来越多了,别人的成功彻彻底底。其实还有很多有趣的论文,比如 AI and ML Meets DB,但我搞系统不搞机器学习,属实一窍不通,就不献丑了。另外一些论文讨论的话题比较小众,遇到实际问题的时候再翻出来和大家讨论吧。
下一阶段想深入写写 LSM-Tree,感兴趣的读者,欢迎关注我的公众号: