ViLBERT:视觉-语言任务预训练模型

原文链接:https://arxiv.org/pdf/1908.02265.pdf
Motivation
预训练+迁移学习(pretrain-then-transfer)是深度学习研究中常用的方法。如果在一个较大的数据集上预训练一个模型,那么完成特定的下游任务时可以使用该模型(简单修改模型结构或用作特征提取器),训练时并对参数进行微调即可,这样可以大大缩短训练时间。
计算机视觉领域通用的预训练模型包括在ImageNet上训练的各种卷积神经网络(CNN)。自然语言处理(NLP)领域在2018年提出的BERT模型(双向Transformer结构,利用了self-attention来增加上下文的相关性)逐渐成为了语言任务中首选的预训练模型。但在视觉与语言交叉的领域还没有出现一个通用的预训练模型。
本文作者基于BERT模型的思想提出了ViLBERT模型来解决视觉-语言任务的预训练问题。
Pipeline
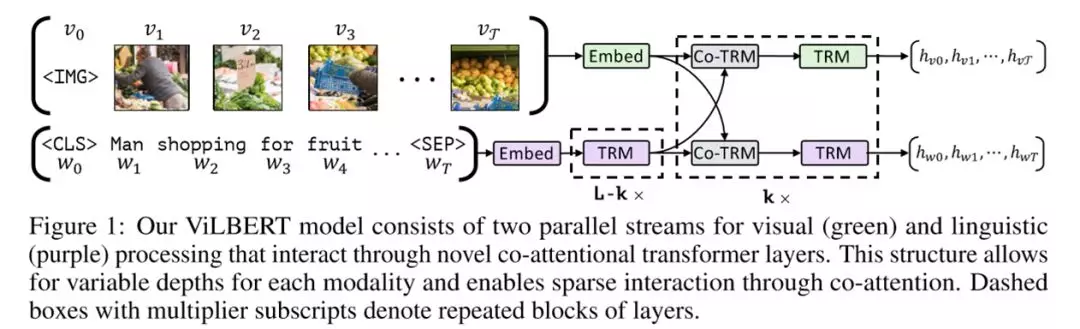
VilBERT的结构如上图所示。图片和文本分别经过两条不同的stream进入co-attentional transformer层中。其中图片经过Faster R-CNN生成候选区域提取特征生成embedding,而文本则在生成embedding后经过了额外的几个Transformer层。作者解释说这是因为文本经过Faster R-CNN后提取的特征已经是比较有较高层次,而文本的embedding需要通过Transformer来生成上下文之间的联系(context-aggregation)。
此后两条stream经过多层相互交叉的co-transformer和Transformer层。普通的Transformer中,query、key、value来自上一层Transformer。而这里提出的全新的co-transformer则同时利用了上一层中视觉和语言的信息,如下图所示。
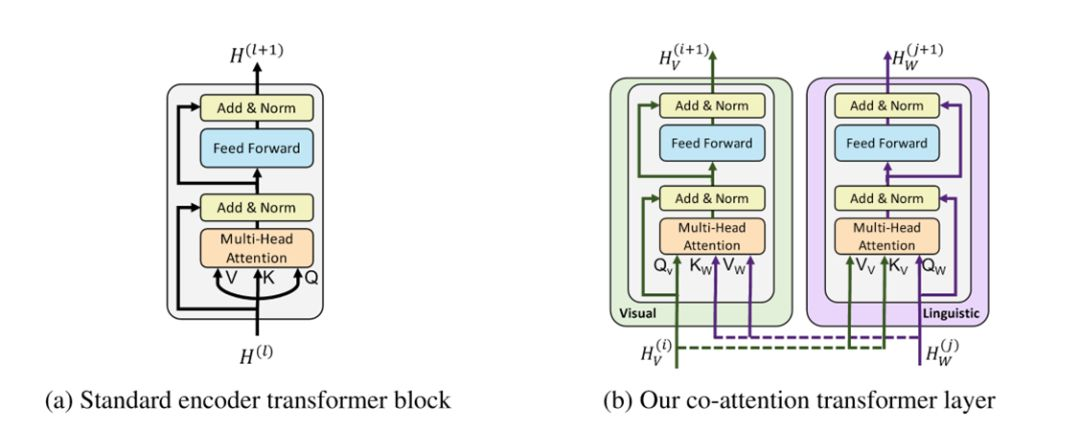
左侧是传统的Transformer层,而在右侧的co-attention transformer中,视觉和语言两条stream分别使用了自己的query和来自另一边的key和value向量,这就使得在通过attention产生文本特征时可以嵌入相应的视觉信息,反之亦然。
Pretraining Tasks
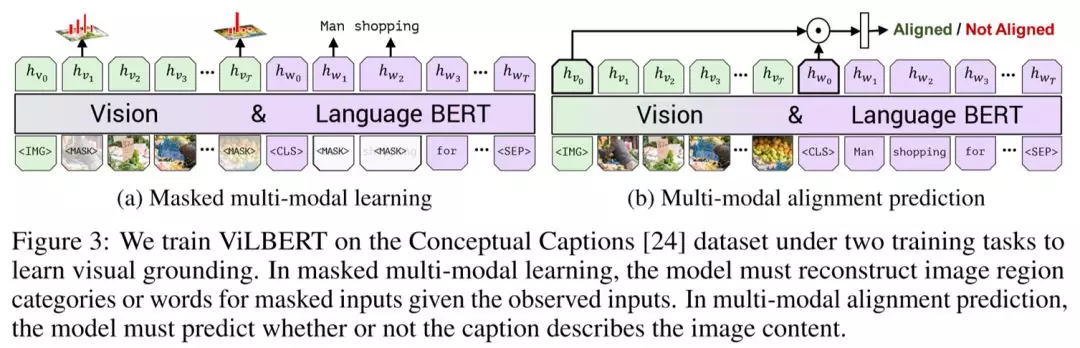
ViLBERT仿照BERT的思想,选定了两项预训练任务。Mased multi-modal learning是遮挡住部分图片和文本信息,让模型预测相应的图片区域和文本。Multi-modal alignment prediction即是给定标题和图片,判断两者是否契合。
Downstream Tasks

下游任务包括视觉问答(VQA)、视觉常识问答(VCR)、引用表达式理解(Referring Expressions)以及基于标题的图片检索(Caption-Based Imahe Retrieval).
Experiments
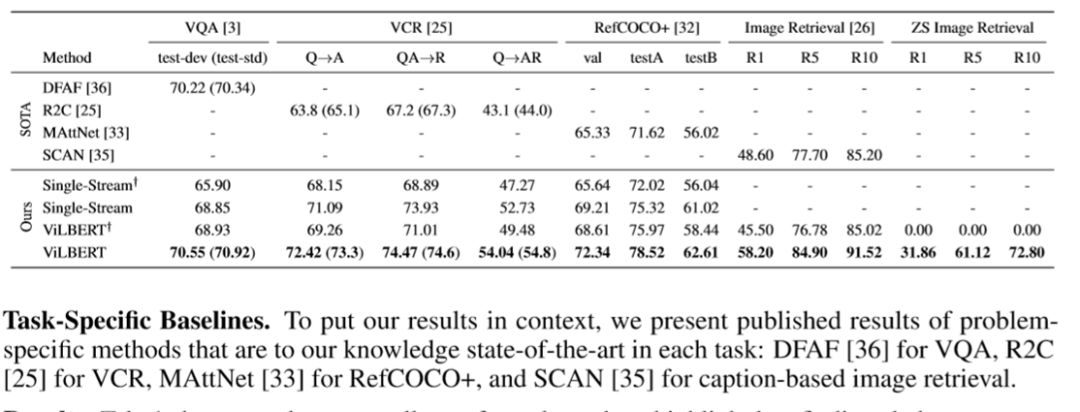
作者根据上述几个下游任务,对比了ViLBERT与其他视觉-语言预训练模型的效果。single stream代表图片与文字经过同一个stream的模型。右上角的十字符号代表未进行预训练。最右侧的ZS Image Retrieval是经过预训练但未经过微调的模型用于图片检索任务。可以看到,经过预训练的ViLBERT对于上述几个下游任务都有不错的效果。
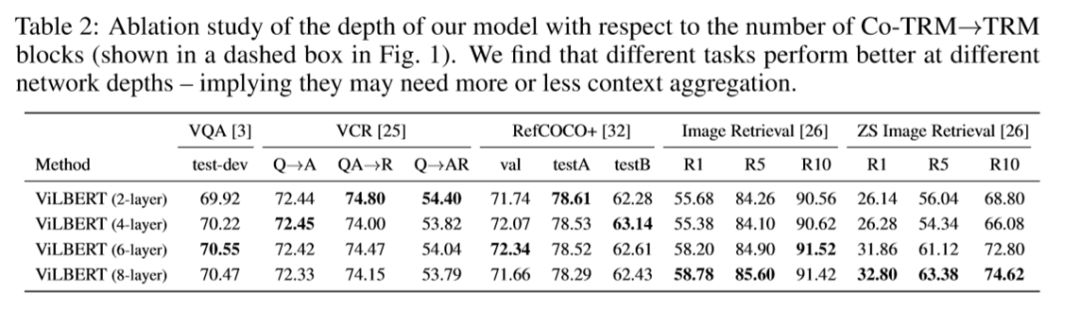
作者对各个任务下ViLBERT达到最好效果所需的TRM和Co-TRM层数进行了实验,实验表明VQA、VCR需要的层数较少,而其余任务则是准确率大致上随层数增大而增加。
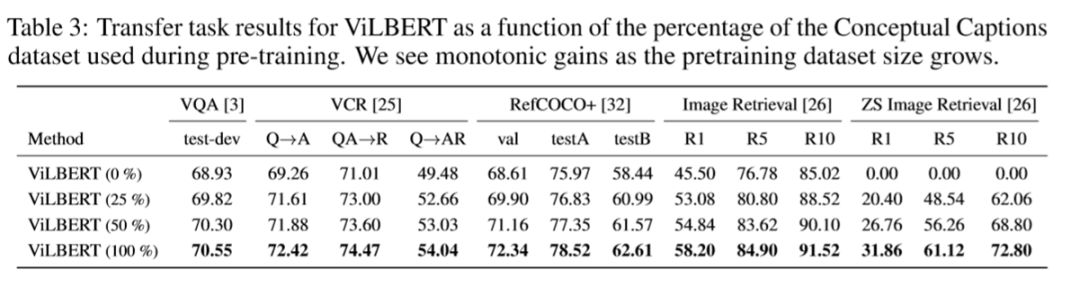
作者还分析了预训练数据集大小与模型效果的关系,分别使用了不同比例的Conceptual Captions(包含大量的图片及对应的标题)数据。结果表明预训练数据集越大模型效果越好,证明预训练中没有发生过拟合。

