
混合线性模型的实现(更新20190607)

本文最早发布在本人的GitHub上,后来在R语言中文社区的公共号上发布过。在之后对其内容进行过几次更新,这一版为最新版,修改了一些错误的地方(如调整比较方式部分),增添了新的内容(随机斜率取舍部分)。
R 中混合线性模型可依靠lme4或者lmerTest数据包(强烈推荐后者,因为会输出显著性)
library(lmerTest)基本表达式
fit = lmer(data = , formula = DV ~ Fixed_Factor + (Random_intercept + Random_Slope | Random_Factor))
data - 要处理的数据集;
formula - 表达式;
DV - 因变量;
Fixed_Factor - 固定因子,即考察的自变量;
Random_intercept - 随机截距,即认为不同群体的因变量的分布不同 (可以理解成有些人出生就在终点,而你是在起点......);
Random_Slope - 随机斜率,即认为不同群体受固定因子的影响是不同的 (可以理解成别人花两个小时能赚10000元,而你只能挣个被试费......);
Random_Factor - 随机因子;数据整理形式
数据整理可参考data1:
data1 = readr::read_csv('https://raw.githubusercontent.com/usplos/Eye-movement-related/master/DemoData.csv')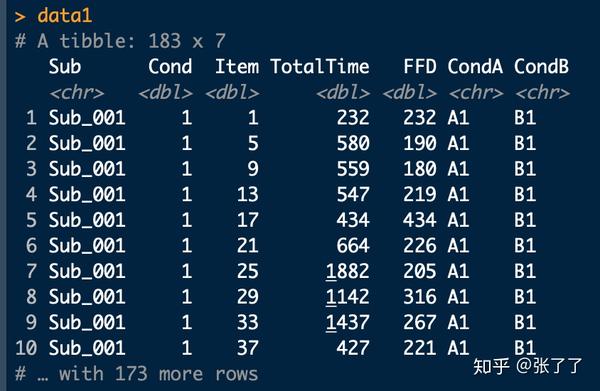

该数据收集了若干被试(Sub)在两种条件下(CondA,CondB)的首次注视时间(FFD)。 这是一个典型的被试内设计(2 × 2设计)。
结果查看
以data1为例, 首先将CondA和CondB设置为因子变量,加载lmerTest数据包。
data1$CondA = factor(data1$CondA)
data1$CondB = factor(data1$CondB)
data1$Item = factor(data1$Item)
data1$Sub = factor(data1$Sub)
library(lmerTest)建立模型,用summary()函数查看结果, 这里需要注意:
- 如果自变量是群体(个体)间的设计,就不能添加随机斜率,这里的两个条件是被试内的,所以可以设置为随机斜率,而像年龄(每个被试只有一个确定的年龄)、性别(被试不可能既是男的又是女的)等变量不可以作为随机斜率;
- 如果设置随机效应,模型可能无法收敛或者自由度溢出(见 《随机斜率的取舍》部分),这个时候需要调整或者取消随机效应;
- 一般同时加
Sub和Item的斜率,但是固定因子和因变量间的关系在不同项目间的差异是较小的,而在不同被试间的差异是比较大的,所以在模型无法收敛时,可以采取优先舍掉Item上斜率的方法(有待讨论):
fit1 = lmer(data = data1, FFD ~ CondA * CondB + (1 + CondA*CondB | Sub) + (1|Item))
summary(fit1)结果为
Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest']
Formula: FFD ~ CondA * CondB + (1 + CondA * CondB | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2201.9
Scaled residuals:
Min 1Q Median 3Q Max
-1.9039 -0.6365 -0.2383 0.4440 3.3754
Random effects:
Groups Name Variance Std.Dev. Corr
Item (Intercept) 1622.5 40.28
Sub (Intercept) 1457.5 38.18
CondAA2 781.2 27.95 -1.00
CondBB2 644.5 25.39 -1.00 1.00
CondAA2:CondBB2 358.5 18.93 1.00 -1.00 -1.00
Residual 10237.5 101.18
Number of obs: 183, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 268.066 27.629 2.116 9.702 0.00867 **
CondAA2 17.743 27.270 2.787 0.651 0.56489
CondBB2 -2.847 26.495 3.524 -0.107 0.92026
CondAA2:CondBB2 1.259 32.534 8.143 0.039 0.97006
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) CndAA2 CndBB2
CondAA2 -0.808
CondBB2 -0.789 0.679
CndAA2:CBB2 0.549 -0.745 -0.750
convergence code: 0
Model failed to converge with max|grad| = 0.0116944 (tol = 0.002, component 1)其中,随机效应的结果如下,可以看到确实每个被试的首次注视时间是有差别的;但是这里看到相关系数为1或-1,说明模型过度拟合,这时需对模型进行简化(见 《随机斜率的取舍》部分):
Random effects:
Groups Name Variance Std.Dev. Corr
Item (Intercept) 1622.5 40.28
Sub (Intercept) 1457.5 38.18
CondAA2 781.2 27.95 -1.00
CondBB2 644.5 25.39 -1.00 1.00
CondAA2:CondBB2 358.5 18.93 1.00 -1.00 -1.00
Residual 10237.5 101.18
Number of obs: 183, groups: Item, 64; Sub, 3固定效应的结果如下,这里是把A1 和 B1分别设为CondA和CondB的基线,然后CondAA2这一行的意思是CondA在CondB的B1条件下的主效应,也就是简单主效应,同理CondBB2也是在CondA的A1条件下的简单主效应。
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 268.066 27.629 2.116 9.702 0.00867 **
CondAA2 17.743 27.270 2.787 0.651 0.56489
CondBB2 -2.847 26.495 3.524 -0.107 0.92026
CondAA2:CondBB2 1.259 32.534 8.143 0.039 0.97006
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1注意,固定效应不是主效应和交互作用,要查看主效应和交互作用需要用anova()函数:
anova(fit1)结果如下,看出主效应和交互作用都不显著。
Type III Analysis of Variance Table with Satterthwaite's method
Sum Sq Mean Sq NumDF DenDF F value Pr(>F)
CondA 9941.7 9941.7 1 2.7714 0.9711 0.4024
CondB 157.1 157.1 1 4.0413 0.0153 0.9073
CondA:CondB 15.3 15.3 1 8.1427 0.0015 0.9701汇报结果的一般顺序是:1. 主效应和交互作用;2. 如果主效应或者交互作用显著,再汇报contrasts的结果,但是像这里每个因素只有两个水平,因此当比较矩阵设置恰当的时候,因素内contrasts的结果和主效应的结果是一样的(比较矩阵的设置方法见下文);3.如果交互作用显著则需要进行简单效应分析。
随机斜率的取舍
在上面建立的模型中,包含随机斜率和随机截距,但是有两个问题:
- 有两个自变量,随机斜率的组合有很多种,如何选取适当地模型?
- 选取的模型可能无法收敛或者自由度溢出,这时如何简化模型?
- 无法收敛的情况:当输出下面的warning的时候,说明模型无法收敛,这时候需要简化模型,使其收敛:


2. 自由度溢出的情况:当输出下面的错误时,说明自由度溢出(有时summary()输出的结果没有p值,也是模型无法收敛导致的),这时候也需要简化模型,使其收敛:


针对自由度溢出,需要将错误提示里的随机斜率剔除即可。
而针对模型无法收敛的问题,首先我们最终选取的模型要符合两个标准:1.可以收敛;2.不能过度拟合。
方法是:首先,考虑全模型,即如下命令:
fitA = lmer(data = data1, FFD ~ CondA * CondB + (1 + CondA*CondB | Sub) + (1|Item))执行命令后,如果无法收敛,第二步,增大模型的迭代次数:
fitA = lmer(data = data1, FFD ~ CondA * CondB + (1 + CondA*CondB | Sub) + (1|Item), control = lmerControl(optCtrl = list(maxfun = 20000)))
# 这里以20000次为标准,大多数两因素的模型迭代到20000次都是可以收敛;我曾试过3因素的全模型,在20000次迭代后,也是可以收敛的。无论增大迭代次数后,全模型是否可以收敛,都查看其随机效应(如果设置到20000次仍然不能收敛,那么继续增大迭代次数也是不太可能收敛的)。
观察全模型的随机效应:
Random effects:
Groups Name Variance Std.Dev. Corr
Item (Intercept) 1622.5 40.28
Sub (Intercept) 1457.5 38.18
CondAA2 781.2 27.95 -1.00
CondBB2 644.5 25.39 -1.00 1.00
CondAA2:CondBB2 358.5 18.93 1.00 -1.00 -1.00
Residual 10237.5 101.18
Number of obs: 183, groups: Item, 64; Sub, 3可以看到有很多相关接近1或-1,表明模型过度拟合,这是应该精简模型的随机斜率。
过度拟合有时是模型无法收敛的原因,有时不是,比如下面这种情况(模型可以收敛):
> modelFFD = lmer(data = data1, FFD ~ CondA * CondB + (1 + CondA | Sub) + (1 | Item))
boundary (singular) fit: see ?isSingular显示模型为奇异拟合状态,此时用isSingular()函数查看一下,确实为奇异拟合
> isSingular(modelFFD)
[1] TRUE出现以上的情况(无论模型是否收敛),是因为方差协方差矩阵的一些“维度”被估计为零,对于纯截距模型等标量随机效应,或截距+斜率模型等二维随机效应,奇异拟合相对容易检测,因为它导致随机效应方差估计(接近)为零,或(几乎)精确到-1或1的相关性估计。这时检查一下该模型的随机效应部分,会发现某一个或几个的随机斜率的相关估计等于(或接近1或-1):
> summary(modelFFD)
Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest']
Formula: FFD ~ CondA * CondB + (1 + CondA | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2202.7
Scaled residuals:
Min 1Q Median 3Q Max
-1.8855 -0.6308 -0.2354 0.4430 3.3675
Random effects:
Groups Name Variance Std.Dev. Corr
Item (Intercept) 1622.4 40.28
Sub (Intercept) 555.3 23.56
CondAA2 274.5 16.57 -1.00
Residual 10318.7 101.58
Number of obs: 183, groups: Item, 64; Sub, 3注意:1. 如果Corr的值如果为1,代表过度拟合了(有时大于0.9也被视为过度拟合),这时候需要将对应的随机斜率从模型中去掉;2. 过度拟合会导致模型的随机效应部分出现共线性,因此要查看Corr的结果,并将过度拟合的斜率去掉(Corr在0.9以上视为过度拟合)。
总结起来, 第三步:去除全模型中随机效应里过度拟合的斜率(Barr D. J., 2013)。 这里需要注意,这里的例子里只有三名被试的数据,因此随机斜率的Corr会很大,基本上都是1,但是真实的数据分析中,
- 会出现介于0.9到1之间的Corr,0.9以上的可以认定为过度拟合;
- 是否为过度拟合应该用
isSingular()函数检测一下,以免遗漏; - 可能会出现多个过度拟合的值,比如上面的6个Corr全是1,这种情况下:
- 先删除最高阶的交互作用,因为只要有最高阶的交互作用,删除其他作用对模型没有影响(Barr D. J., 2013);
- 删除交互作用后,如果仍不能收敛,请继续删除,这时如果两个主效应的Corr都大于0.9,请先删除Corr较大的那个;
- 删除较大的主效应后如果仍然不能收敛,保留较大Corr的主效应,删除Corr较小的主效应(如果两个主效应的Corr都大于0.9,不能直接删掉它们,因为随机斜率彼此相互影响,删掉一个,其他的Corr都会相应改变),以此类推,直至探索到符合上面两条标准的模型。
- 进行随机斜率筛选的时候,请保持最大迭代次数和全模型相同,这样方便比较模型的差异。
这里看到Sub的三个随机斜率都过度拟合了,因此移除它们:
fit2 = lmer(data = data1, FFD ~ CondA * CondB + (1 | Sub) + (1|Item))移除后不代表完事儿了,第四步:检查简化后的模型和全模型是否有差别:
anova(fit2, fitA)
Data: data1
Models:
fit2: FFD ~ CondA * CondB + (1 | Sub) + (1 | Item)
fitA: FFD ~ CondA * CondB + (1 + CondA * CondB | Sub) + (1 | Item)
Df AIC BIC logLik deviance Chisq Chi Df Pr(>Chisq)
fit2 7 2247.2 2269.7 -1116.6 2233.2
fitA 16 2264.2 2315.6 -1116.1 2232.2 0.9841 9 0.9995看到,两个模型之间没有显著差别 (p > 0.05 即可,一般去除过度拟合的成分后的模型和全模型都没有显著差别),简化后的模型为最终采用的模型。
调整固定因子比较基线
上面的固定效应的结果中,是以CondA的第一个水平,即A1作为基线,如果想人为设置比较基线,最核心的办法是改变比较矩阵,可以用contrasts()函数查看比较矩阵
> contrasts(data1$CondA)
A2
A1 0
A2 1这里是以A1作为基线,A2和A1比较。这里将其改为以第二个水平为基线,结果如下,看到固定因子的基线及其相应的数值都变化了,相应地可以修改CondB的基线:
> CMA = contrasts(data1$CondA)
> CMA[1:2] = c(1,0)
> colnames(CMA) = 'A1'
> CMA
A1
A1 1
A2 0
> fit1 = lmer(data = data1, FFD~CondA*CondB + (1|Sub) + (1|Item), contrasts = list(CondA = CMA))
> summary(fit1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: FFD ~ CondA * CondB + (1 | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2203.2
Scaled residuals:
Min 1Q Median 3Q Max
-1.8753 -0.6359 -0.2234 0.4351 3.3642
Random effects:
Groups Name Variance Std.Dev.
Item (Intercept) 1695.8 41.18
Sub (Intercept) 197.2 14.04
Residual 10325.4 101.61
Number of obs: 183, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 286.6679 18.0108 13.3749 15.916 4.45e-10 ***
CondAA1 -20.6232 21.9626 134.6747 -0.939 0.349
CondBB2 -1.9994 21.4169 138.1128 -0.093 0.926
CondAA1:CondBB2 0.1477 30.6915 136.8135 0.005 0.996
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) CndAA1 CndBB2
CondAA1 -0.587
CondBB2 -0.609 0.492
CndAA1:CBB2 0.423 -0.718 -0.694这种比较(和基线比较)只是R里的其中一种比较方式,R里的比较方式共有如下五种:
contrasts = contr.helmert:第二个水平对照第一个水平,第三个水平对照前两个的均值,第四个水平对照前三个的均 值,以此类推contrasts = contr.poly:基于正交多项式的对照,用于趋势分析(线性、二次、三次等)和等距水平的有序因子contrasts = contr.sum:对照变量之和限制为0。也称作偏差找对,对各水平的均值与所有水平的均值进行比较contrasts = contr.treatment:各水平对照基线水平(默认第一个水平)。也称作虚拟编码。(这个是无序因子常用的编码形式,也是LMM常用的和默认的)contrasts = contr.SAS:类似于contr.treatment,只是基线水平变成了最后一个水平。
比如不想和基线比较,而是想看每种水平和总体的均值的偏差程度,需要设置成contr.sum的格式 (如果因素只有两个水平,那么summary()中固定效应中的p值即为主效应的p值), 可以用options(contrasts = )来调节(注意,option()设置的时候需要同时设置无序因子(各水平间只有顺序的差异,没有大小差异,无法比较大小)和有序因子(各水平间有确定的大小关系,可以比较大小)的比较方法,我们的实验中的因子几乎都是无序因子,因此只需要改变下面的options( )命令中的第一个比较方式即可):
options(contrasts = c('contr.sum','contr.poly'))
fit1 = lmer(data = data1, FFD ~ CondA * CondB + (1 | Sub) + (1|Item))
summary(fit1)结果如下,看出两个条件的固定效应发生了相应改变(这里只展现基线以外的水平的结果,如果想查看基线水平的结果,请重新编码因子水平,如果采用的是sum编码,调整比较基线后的而结果是一样的),其它的比较方法读者可自行尝试。
Linear mixed model fit by REML. t-tests use Satterthwaite's method ['lmerModLmerTest']
Formula: FFD ~ CondA * CondB + (1 | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2208.8
Scaled residuals:
Min 1Q Median 3Q Max
-1.8753 -0.6359 -0.2234 0.4351 3.3642
Random effects:
Groups Name Variance Std.Dev.
Item (Intercept) 1695.8 41.18
Sub (Intercept) 197.2 14.04
Residual 10325.4 101.61
Number of obs: 183, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 275.39352 12.21818 2.87906 22.540 0.00025 ***
CondA1 10.27466 7.65178 133.60080 1.343 0.18162
CondB1 0.96279 7.71319 142.56605 0.125 0.90084
CondA1:CondB1 0.03692 7.67288 136.81347 0.005 0.99617
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) CondA1 CondB1
CondA1 -0.019
CondB1 0.022 -0.013
CndA1:CndB1 -0.002 0.027 -0.031这里需要注意,sum的比较方式中,虽然固定效应的p值等于主效应的p值,但是Estimate中的差异量却不是真实的差异量,而是原始差异量的一半,这也是由于其比较矩阵的关系:
> contr.sum(2)
[,1]
1 1
2 -1如果将比较矩阵的值改为-0.5, 0.5,差异量即为真实的差异量
> CMA[1:2] = c(-0.5, 0.5)
> CMB = contrasts(data1$CondB)
> CMB[1:2] = c(-0.5, 0.5)
> colnames(CMA) = 'MainA'
> colnames(CMB) = 'MainB'
> CMA
MainA
A1 -0.5
A2 0.5
> CMB
MainB
B1 -0.5
B2 0.5
> fit1 = lmer(data = data1, FFD~CondA*CondB + (1|Sub) + (1|Item), contrasts = list(CondA = CMA, CondB = CMB))
> summary(fit1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: FFD ~ CondA * CondB + (1 | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2203.2
Scaled residuals:
Min 1Q Median 3Q Max
-1.8753 -0.6359 -0.2234 0.4351 3.3642
Random effects:
Groups Name Variance Std.Dev.
Item (Intercept) 1695.8 41.18
Sub (Intercept) 197.2 14.04
Residual 10325.4 101.61
Number of obs: 183, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 275.3935 12.2182 2.8791 22.540 0.00025
CondAMainA 20.5493 15.3036 133.6008 1.343 0.18162
CondBMainB -1.9256 15.4264 142.5661 -0.125 0.90084
CondAMainA:CondBMainB -0.1477 30.6915 136.8135 -0.005 0.99617
(Intercept) ***
CondAMainA
CondBMainB
CondAMainA:CondBMainB
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) CndAMA CndBMB
CondAMainA -0.019
CondBMainB -0.022 0.013
CndAMA:CBMB 0.002 -0.027 -0.031
简单效应分析
注意,固定效应(Fixed Efeects), 主效应(Main Effects) 和 简单效应(Simple Effects) 是三个不同的概念。固定效应是因素内某个水平和基线水平的差异,相当于t检验;主效应是操纵某个因素(自变量)对因变量的影响,相当于F检验,即使固定效应显著,主效应也不一定显著;简单效应是指自变量A在自变量B的不同水平上对因变量的影响,其本质也是主效应,但是是在另一个变量某个水平上的主效应。 虽然这里交互作用并不显著,但是还是要演示一下如何进行简单效应分析:
library(emmeans) # emmeans数据包可以对我们组涉及的模型进行简单效应分析,结果可读性较强
emmeans(fit1, pairwise~CondA|CondB) # 比较CondB的不同水平上CondA水平之间的差别结果分为两部分,第一部分输出不同CondB水平下,CondA不同水平的均值、标准误、自由度、置信区间等信息,如下:
$emmeans
CondB = B1:
CondA emmean SE df lower.CL upper.CL
A2 287 18.1 13.5 248 326
A1 266 18.6 14.8 226 306
CondB = B2:
CondA emmean SE df lower.CL upper.CL
A2 285 17.7 12.7 246 323
A1 264 18.0 13.5 225 303
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95 第二部分是显著性检验的结果,如下:
$contrasts
CondB = B1:
contrast estimate SE df t.ratio p.value
A2 - A1 20.6 22.1 134 0.935 0.3514
CondB = B2:
contrast estimate SE df t.ratio p.value
A2 - A1 20.5 21.5 135 0.954 0.3417 Planed contrasts
以上做的是没有事先明确指向性地对比,但有时我们有明确的假设,有要明确比较的两个条件,这时要做 planed contrasts。为此需要对数据进行整理,将CondA和CondB整合为一个因子变量Cond,同时规定相应地因子水平:
data1 = data1 %>% mutate(Cond = paste(CondA,CondB, sep = '') %>% factor(levels = c('A1B1','A1B2','A2B1','A2B2')))
data1
# A tibble: 183 x 7
Sub Cond Item TotalTime FFD CondA CondB
<fct> <fct> <fct> <dbl> <dbl> <fct> <fct>
1 Sub_001 A1B1 1 232 232 A1 B1
2 Sub_001 A1B1 5 580 190 A1 B1
3 Sub_001 A1B1 9 559 180 A1 B1
4 Sub_001 A1B1 13 547 219 A1 B1
5 Sub_001 A1B1 17 434 434 A1 B1
6 Sub_001 A1B1 21 664 226 A1 B1
7 Sub_001 A1B1 25 1882 205 A1 B1
8 Sub_001 A1B1 29 1142 316 A1 B1
9 Sub_001 A1B1 33 1437 267 A1 B1
10 Sub_001 A1B1 37 427 221 A1 B1
# … with 173 more rows
levels(data1$Cond) # 查看因子的顺序
[1] "A1B1" "A1B2" "A2B1" "A2B2"下一步,建立contrasts的矩阵。矩阵建立的规则是:如果有2个自变量,分别有n和m个水平,那么建立的矩阵有n × m行,比如这里的矩阵是2 × 2 = 4 行;每一列代表一个要比较的效应,在某列内对不同的条件赋予“权重”,以数字的形式赋予,要保证该列所有权重的总和为0。比如我们要比较CondA的主效应,因为A1为Cond的前两个水平,A2为后两个水平,因此建立如下的矩阵
> CMA = matrix(c(0.5,0.5,-0.5,-0.5), nrow = 4)
> rownames(CMA) = levels(data1$Cond)
> colnames(CMA) = 'MainCondA'
> CMA
MainCondA
A1B1 0.5
A1B2 0.5
A2B1 -0.5
A2B2 -0.5之后建立模型,这时需要放的自变量和随机斜率是Cond,而不是CondA*CondB,同时要设置contrast选项:
> fit1 = lmer(data = data1, FFD ~ Cond + (1|Sub) + (1|Item), contrasts = list(Cond = CMA))
> summary(fit1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: FFD ~ Cond + (1 | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2219.2
Scaled residuals:
Min 1Q Median 3Q Max
-1.9008 -0.6339 -0.2193 0.4469 3.3910
Random effects:
Groups Name Variance Std.Dev.
Item (Intercept) 1733.0 41.63
Sub (Intercept) 197.3 14.05
Residual 10168.9 100.84
Number of obs: 183, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 275.357 12.206 2.913 22.559 0.000232 ***
CondMainCondA -20.638 15.187 135.257 -1.359 0.176436
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr)
CondManCndA 0.018 这时有CondA的主效应了。相似地,可以对比CondB的主效应。也可以进行简单效应的planed contrasts,比如比较CondA的不同水平上,CondB的主效应:
> CMS = matrix(c(0.5, -0.5, 0, 0,
+ 0, 0, 0.5, -0.5),
+ nrow = 4)
> rownames(CMS) = levels(data1$Cond)
> colnames(CMS) = c('SimpleOnCondA1','SimpleOnCondA2')
> CMS
SimpleOnCondA1 SimpleOnCondA2
A1B1 0.5 0.0
A1B2 -0.5 0.0
A2B1 0.0 0.5
A2B2 0.0 -0.5
> fit1 = lmer(data = data1, FFD ~ Cond + (1|Sub) + (1|Item), contrasts = list(Cond = CMS))
> summary(fit1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: FFD ~ Cond + (1 | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2212.3
Scaled residuals:
Min 1Q Median 3Q Max
-1.7799 -0.6124 -0.2304 0.4840 3.4527
Random effects:
Groups Name Variance Std.Dev.
Item (Intercept) 1563.0 39.53
Sub (Intercept) 209.4 14.47
Residual 10474.8 102.35
Number of obs: 183, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 275.725 12.330 2.765 22.36 0.000331 ***
CondSimpleOnCondA1 2.676 22.212 143.030 0.12 0.904272
CondSimpleOnCondA2 1.728 21.540 139.964 0.08 0.936167
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) CSOCA1
CndSmplOCA1 0.016
CndSmplOCA2 0.014 0.005 比较CondB不同水平上CondA的主效应:
> CMS2 = matrix(c(0.5, 0, -0.5, 0,
+ 0, 0.5, 0, -0.5),
+ nrow = 4)
> rownames(CMS2) = levels(data1$Cond)
> colnames(CMS2) = c('SimpleOnCondB1','SimpleOnCondB2')
> CMS2
SimpleOnCondB1 SimpleOnCondB2
A1B1 0.5 0.0
A1B2 0.0 0.5
A2B1 -0.5 0.0
A2B2 0.0 -0.5
> fit1 = lmer(data = data1, FFD ~ Cond + (1|Sub) + (1|Item), contrasts = list(Cond = CMS2))
> summary(fit1)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: FFD ~ Cond + (1 | Sub) + (1 | Item)
Data: data1
REML criterion at convergence: 2210.6
Scaled residuals:
Min 1Q Median 3Q Max
-1.8928 -0.6330 -0.2181 0.4448 3.3823
Random effects:
Groups Name Variance Std.Dev.
Item (Intercept) 1713 41.39
Sub (Intercept) 196 14.00
Residual 10249 101.24
Number of obs: 183, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 275.36 12.19 2.90 22.582 0.000238 ***
CondSimpleOnCondB1 -20.74 21.88 135.31 -0.948 0.344786
CondSimpleOnCondB2 -20.48 21.30 136.65 -0.961 0.338148
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) CSOCB1
CndSmplOCB1 0.014
CndSmplOCB2 0.012 -0.002广义混合线性模型
如果因变量不是连续变量,比如兴趣区内是否接受回视、是否从兴趣区内发出回视、是否跳读兴趣区等等,则需要用广义线性模型。
R中做GLMM(Genaralized Linear Mixed Model)用到的函数是:
glmer(data = , formula = , family = ,...)
其中 family = 有多种不同的选择(注意是字符型的),分别如下:
binomial-link = “logit”(如果自变量为0,1变量,family要设置为binomial);gaussian-link = "identity";gamma-link = "inverse";inverse.gaussian-link = "1/mu^2";poisson-link = "log";quasi-link = "identity", variance = "constant";quasibinomial-link = "logit";quasipoisson-link = "log";
我们常用的是二项分布 (binomial) 和正态分布 (gaussian)(如果因变量是两个类别以上的称名变量,应该是泊松分布(存疑)),其余的很少见,所以不做介绍了 其他参数设置和lmer()是一样的。这里我们以兴趣区接受回视的情况为例,数据如下:
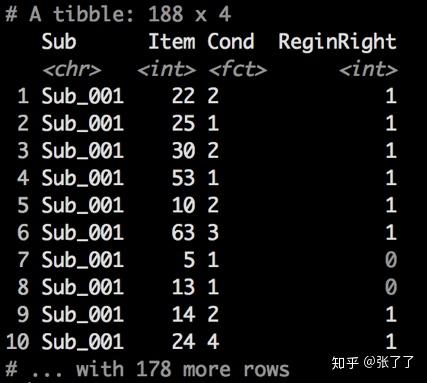

建立模型如下:
fit3 = glmer(data = data2, ReginRight ~ Cond + (1|Sub) + (1|Item), family = 'binomial')
summary(fit3)
Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) [glmerMod]
Family: binomial ( logit )
Formula: ReginRight ~ Cond + (1 | Sub) + (1 | Item)
Data: data2
AIC BIC logLik deviance df.resid
254 273 -121 242 182
Scaled residuals:
Min 1Q Median 3Q Max
-2.391 -0.884 0.418 0.769 1.383
Random effects:
Groups Name Variance Std.Dev.
Item (Intercept) 6.63e-09 8.14e-05
Sub (Intercept) 2.52e-01 5.02e-01
Number of obs: 188, groups: Item, 64; Sub, 3
Fixed effects:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.2895 0.3295 0.88 0.380
Cond1 -0.4642 0.2629 -1.77 0.077 .
Cond2 -0.3080 0.2660 -1.16 0.247
Cond3 -0.0994 0.2660 -0.37 0.709
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) Cond1 Cond2
Cond1 -0.026
Cond2 -0.017 -0.296
Cond3 -0.013 -0.302 -0.309
convergence code: 0glmer() 和 lmer() 只是因变量的类别不同,其他操作都是一样的(包括随机斜率取舍问题 [改变迭代次数时,lmerControl() 改为 glmerControl()],简单效应分析,主效应和交互作用查看,调整因子水平,planed contrasts)。
REML 和 ML
有时会遇到选择REML和ML的问题,两种方法得出的固定效应的值稍有不同,比如可尝试一下命令:
modelFFD = lmer(data = data1, FFD ~ CondA * CondB + (1 | Sub) + (1|Item), REML = T)
summary(modelFFD)
modelFFD = lmer(data = data1, FFD ~ CondA * CondB + (1 | Sub) + (1|Item), REML = F) # REML 设为F,即使用ML估计方法
summary(modelFFD)关于REML和ML的基本知识,可参考最大似然估计(ML)和限制性最大似然估计(REML)。
我在这里只做一下总结:
- REML的估计是无偏的,ML的估计是有偏的;
- 如果建模的目的是比较不同固定因子的效应,建议使用ML估计方法;如果不是,建议使用REML估计方法(即lmer()默认的方法)
在进行模型优化时,若只有一个固定因子,模型数量较少,筛选起来较容易,但若有两到三个固定因子(都能加到随机斜率上),模型数量会急剧增加(以两个随机因子——被试和项目——为例,2个固定因子–35个模型,3个固定因子–288个模型)。此时显然不能通过人力来遍历,本人编了一些函数可以实现模型遍历(只适用于2或3个可加到随机斜率上的固定因子的情况)。
函数版请见:
shiny可视化版请见:
此外还有混合线性模型分析的可视化版本:
