目标检测算法faster rcnn的主干网络替换成轻量化神经网络如mobilenet v2有意义吗?

YOLOv5 网络模型的结构图可知,模型的头部网络中有 3 个尺度检测,分别是 80x80,40x40,20x20,并且在每一层都设置了大小不同的 anchors。YOLOv5 原始网络所使用的训练数据集中包含着许多复杂的目标,并且这些目标大小也存在巨大的差异,采用多尺度多 anchors 检测能够有效提高模型的检测精度。但提出的动物实验平台监测过程中,检测目标只有实验体一种,检测目标明确,并且目标大小基本保持不变,因此最终制作的数据集也较为简单,过深的网络可能存在很多冗余的信息,对模型整体的训练反而没有特别大的帮助,需要对网络的结构进行轻量化处理,因此就不需要原始结构中三个尺度的检测,并且 anchors 的设置也需要重新选择。检测尺度的设置与 anchors 的设置都与感受野有关,感受野的计算方式如下:
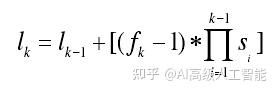
上式中l(k-1)为第k − 1层的感受野,任何改变特征图尺寸大小的操作都会导致感受野的改变,一般来说特征图的尺寸越小则对应的感受野越大, fk则是卷积核或池化区域大小。YOLOv5 网络模型的主干网络用于实现特征的下采样,其中 BottleneckCSP 和 SPP 这两个操作都没有改变特征图的大小,也就不涉及感受野的变化。从网络的结构可以知道输入图像首先通过 Focus 操作缩小一半的尺寸,之后又通过四次卷积操作最终得到 32 倍下采样后的特征图。为了得到网络各层级的感受野大小,将 Focus 操作也视为一次下采样,最终 YOLOv5模型中五次下采样的详细信息如表 1 所示。
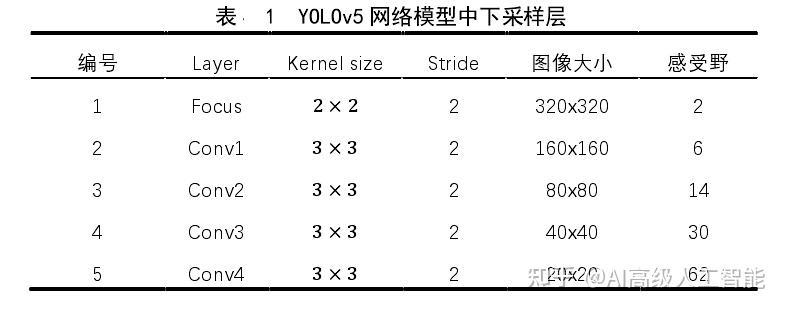

YOLOv5 网络会将输入图像的大小改变为 640x640,按照网络的原始结构,采用 32 倍,16 倍以及 8 倍下采样后的特征图作为最终的输出,并按照输出的感受野大小设置 anchors 的数值。
微信公众号:人工智能感知信息处理算法研究院
知乎主页:AI高级人工智能