知识图谱+推荐系统 RippleNet:论文解读+代码
论文:RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
代码:https://github.com/ZJJHYM/RippleNet
知识图谱+推荐系统的概述我在《学习学习再学习:知识图谱做推荐系统-前言》中 提到,知识图谱结合推荐系统主要有三个作用:
- 缓解冷启动
- 缓解数据稀疏
- 可解释性
RippleNet 的贡献:
- 首次将基于embedding-based和path-based的方法结合到基于知识图谱的推荐系统中;
- RippleNet使用的KG是item graph。何为item-graph?放在KG中作为实体的主要有用户(user)、商品(item)和属性(attribute)。KG中如果包含三者,则称之为user-item graph,如果KG中只包含item和attribute,则称之为item graph。
- RippleNet借鉴了GraphSage的思想。RippleNet将用户点击的结点作为源点,像水波纹一样向周围扩展,吸收1-hop和2-hop的信息,实现消息传递。
- 对三个真实世界的推荐场景(电影、图书、新闻)进行了实验,结果证明RippleNet在几个最好的基线上都是有提高的。
模型介绍
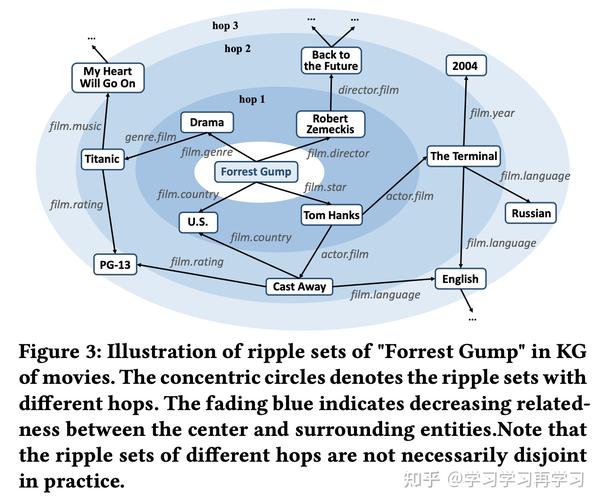
知识图谱通常包含有较多实体和实体之间的联系, 例如如图所示,电影“Forrest Gump”(阿甘正传)与“Robert Zemeckis”(导演)、“Tom Hanks”(明星)、“U.S.“(国家)和“Drama”(戏剧)联系在一起,而“Tom Hanks”则与他主演的电影“The Terminal”(幸福终点站)和“Cast Away”(荒岛余生)联系在一起。这些复杂的联系为我们提供了一个深刻而潜在的视角来探索用户喜好。 例如,如果用户曾经观看过“阿甘正传”,他可能会成为Tom Hanks(汤姆.汉克斯)的粉丝并对“The Terminal“或“Cast Away”也感兴趣。

模型框图下图所示:
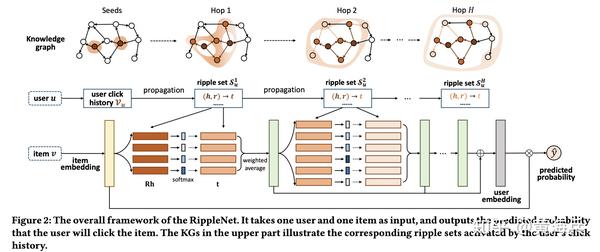

模型输入:一个user u与一个候选item v,对应着图中第二行和第三行(第一次看的时候误解了,以为只有第三行是模型的计算过程……)
模型输出:用户user u点击item v的概率值
图谱知识:提前构造好所有item的(h,r,t)图谱三元组:示例: <'Frost Gump', film.star, Tom Hanks>。这里只有item及其相关的属性,比如节点类别为“电影”,“导演”,“演员”等,用户的观看和点击并没有加入。
第零阶段(seeds):构建用户的seed集合
1. 先以用户u的历史点击的item作为seeds集合(用这些item作为用户的已有的偏好信息),这里的集合可以是多个;
2. 说明一下:用户u的seeds 跟输入待计算相似性item v的关系,item v如果是seeds中的一员,那就当做训练数据的正例(点击该item概率为1),如果不是seeds的一员,那就是负例(点击该item概率为0),论文代码实现里随机选择除点击外的item作为负例。
第一阶段(Hop1):获取用户的第一次Ripple表示
1.构建与用户u相关的第一次偏好传播的Ripple set(以初始的seeds 集合向外扩展,不同的seeds得到的set都放在一起),用(h,r,t)表示。这里为了避免Ripple set 过大,一般都会设定最大扩展长度进行截断,原论文里面设定的每个hop选取的最大个数是16,超过16就随机选取,如果总数量没到16的话,就重复采样(论文源码里的实现方式)。另一方面,构建的知识图谱都是有向图,这里只考虑item点的出度。
2. 根据embedding向量内积,计算item v与第一层Ripple set上的(h, r)的归一化相似度,根据归一化后相似度,对第一层Ripple set 的(t)进行加权求和,得到的结果作为这一层的输出o(本质上属于Attention,Q=item v,K=h*r,V=t);这里用到了图谱假设hR=t。
第二阶段(Hop2):
1. 重复Hop1过程,将第一层的Ripple set的tail作为第二层的head,先取出第二层的Ripple set,然后用用第二层的Ripple set跟item的相似度及加权表示作为输出o。
.......
第H阶段(Hop H):
1. 重复Hop过程
预测阶段(predict probability):
1. 最终的预测是通过item v的embedding和user u的表示进行内积得到,item embedding可以通过embedding 层查找得到。用户向量表征是通过上面的前向网络,上面多次Ripple得到输出是作为用户的表示,可以把多次的Ripple输出o累加作为最终的用户表示。
示例说明:
接下来,我们以第一个绿色矩阵向量为例,来看一下具体是如何计算的。第一个绿色矩形表示的向量,需要使用的是1-hop(KG中第一次向外扩展的item set)的Ripple set,对于set中的每一个(h,r,t),用(h*r)与item v相乘得到item v与1-hop里每个(hi,ri)的相关性得分,再通过softmax进行相关性得分的归一化pi,相关性计算公式如下:
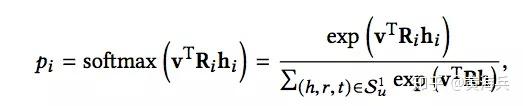

最后通过对所有t进行加权求和,就得到了第一个绿色矩形表示的向量,该向量表示用户在经过第一轮兴趣扩散后的得到的表示:
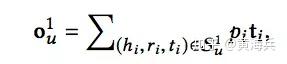
接下来,我们重复上面的过程,假设一共H次,将多次的兴趣扩散得到的表示进行相加最终user表示:
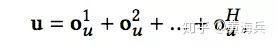
而最终的预测值是通过item的表示v与用户的表示u内积后再过一个sigmoid函数(sigmoid是为了得到概率),计算如下:
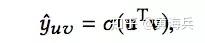
loss计算
这里的分成三个部分:分别是预测分数的交叉熵损失,知识图谱特征表示的损失,参数正则化的损失:
预测部分的损失很好理解,就是用户和该item之间的预测值和真实值的loss
知识图谱特征表示的损失:我们在计算每个阶段的加权求和时上面说了,假设前提是hR=t,这是假设,所以我们需要设一个loss让模型学习,学习的内容就是hR和t之间计算相似度后,预测0,1是否相似
l2正则化损失:每一个hop中h,r,t分别和自己相乘后,求和再求均值得到一个值,即为该loss(这里我理解的不是很深,有了解的可以评论区说说)