如何向深度学习模型中加入先验知识?

先验知识的种类有很多,最常见的可能是关于某个/某些特征的单调性、平滑性等。引入这样的先验知识,也可以称为引入单调性、平滑性约束。
这样的约束引入,可以避免因为数据不足或者数据分布的不均衡导致的模型拟合出的结果违反常识的问题,尽量避免数据采样中自然包含的幸存者偏差,同时也能让模型提供额外的解释性。
单调性约束
单调性约束是在实际场景最为常见的约束之一。比如在营销中给用户发红包,发放的红包越大,用户的领取率越高,产生的GMV转化越高[1][2];在导航搜索中,给用户推荐的餐馆越近,用户对结果的满意度越高;在授信中,给用户的额度越高,用户使用的频次越高[3][4].
如果不加入单调性约束,模型当然可以从足够数量的数据中学得这样的单调性特质,并且有更好的MAE,但是这样得出的结果不符合业务常识,在业务优化中的可用性就比较有限了。如果数据不够或者在分布上存在不均衡的问题(实际情况经常如此),那经常就学不到这样的单调性。
在模型中加入单调性约束,我们可以在模型设计上想办法,也可以在损失函数/优化上想办法。前者典型的如Deep Lattice Networks[5]:
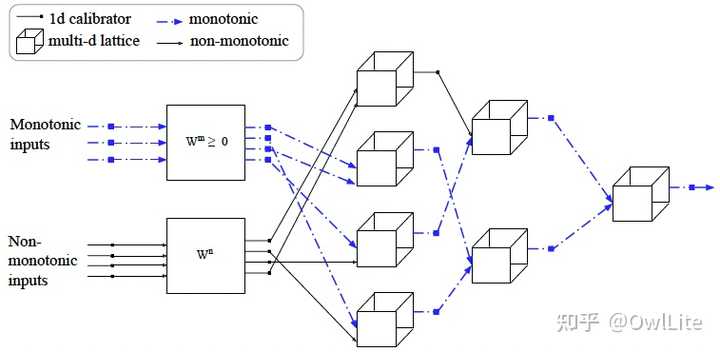

他通过把特征分为单调和非单调的进行分开处理,对于单调特征,采用分段线性变换(piecewise linear transform,本质上是一系列ReLU函数的叠加)引入单调性约束:
c\left(x[d];a,b \right )=\sum_{k=1}^{K}{\alpha[k]ReLU(x-a[k])+b[1]} .
但是Deep Lattice Networks要满足单调性,需要对每个layer进行处理,目前支持的layer种类较少,因此其应用比较受限,性能也比较平庸。
在损失函数上进行改造,典型的如引入Point-wise Loss[6]. 也就是把优化目标关于单调特征的散度最小化:
min \mathfrak{L}_{mono}=min\left\{ \sum_{i=1}^{n}{max\left( 0,- \mathbf{\nabla}\cdot _{M} f\left( x_i ;\theta\right) \right) + \mathfrak{L}_{NN}} \right\} .
当然,这种约束设计无法保证严格的单调性。
平滑性约束
我们经常希望训练出的模型关于某个值的输出结果是平滑函数,这不仅是为了符合业务逻辑,也是为了让模型对对抗攻击更为鲁棒。加入平滑约束的办法很多,通常是在损失函数上进行设计[7][8]. 这样的改造意味着广泛的可移植性和极低的改造成本[9].
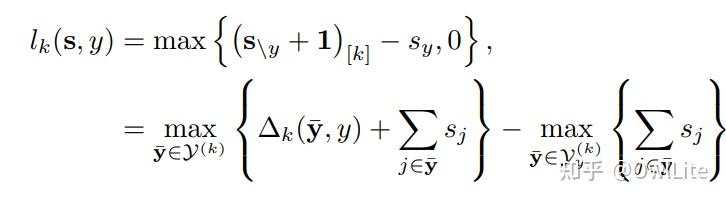

非负约束
这可能是我们在不知不觉中使用最广泛的约束,比如我们预测某个分类概率,这肯定不能是负值,所以最后经常加一个softmax. 有时候,我们的特征或者用户的embedding也希望是非负的,这能在业务中带来一些潜在的好处,在 embedding 中使用ReLU对embedding向量进行clamping是一种暴力而又简单的方法[10][11].
在深度学习中加入先验知识的方法很多,通常需要根据实际场景需求进行个性化的设计,并且常常需要大量的调参过程,偶尔也意味着模型结果(准确率,MAE等)的变差。
参考
- ^Zhang, W., Li, J., & Liu, L. (2021). A Unified Survey of Treatment Effect Heterogeneity Modelling and Uplift Modelling. ACM Computing Surveys (CSUR), 54(8), 1-36.
- ^Koehn, D., Lessmann, S., & Schaal, M. (2020). Predicting online shopping behaviour from clickstream data using deep learning. Expert Systems with Applications, 150, 113342.
- ^Chen, C. C., & Li, S. T. (2014). Credit rating with a monotonicity-constrained support vector machine model. Expert Systems with Applications, 41(16), 7235-7247.
- ^Baesens, B., Van Gestel, T., Stepanova, M., Van den Poel, D., & Vanthienen, J. (2005). Neural network survival analysis for personal loan data. Journal of the Operational Research Society, 56(9), 1089-1098.
- ^You, S., Ding, D., Canini, K., Pfeifer, J., & Gupta, M. R. (2017, December). Deep lattice networks and partial monotonic functions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (pp. 2985-2993).
- ^Gupta, A., Shukla, N., Marla, L., Kolbeinsson, A., & Yellepeddi, K. (2019). How to Incorporate Monotonicity in Deep Networks While Preserving Flexibility?. arXiv preprint arXiv:1909.10662.
- ^Rosca, M., Weber, T., Gretton, A., & Mohamed, S. (2020). A case for new neural network smoothness constraints.
- ^Ravi, S. N., Dinh, T., Lokhande, V. S., & Singh, V. (2019, July). Explicitly imposing constraints in deep networks via conditional gradients gives improved generalization and faster convergence. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 4772-4779).
- ^Berrada, L., Zisserman, A., & Kumar, M. P. (2018). Smooth loss functions for deep top-k classification. arXiv preprint arXiv:1802.07595.
- ^Hosseini-Asl, E., Zurada, J. M., & Nasraoui, O. (2015). Deep learning of part-based representation of data using sparse autoencoders with nonnegativity constraints. IEEE transactions on neural networks and learning systems, 27(12), 2486-2498.
- ^Ayinde, B. O., Hosseini-Asl, E., & Zurada, J. M. (2016, June). Visualizing and understanding nonnegativity constrained sparse autoencoder in deep learning. In International Conference on Artificial Intelligence and Soft Computing (pp. 3-14). Springer, Cham.