
Deep Joint Entity Disambiguation with Local Neural Attention

在局部注意力机制(local neural attention)基础上利用条件随机场来建模全局项(joint)以进行消歧, 利用最大化似然函数MAP对条件随机场模型进行训练, 采用环路信念传播loopy belief propagation对条件随机场模型进行解码.
论文的主要贡献:
- Entity Embeddings:word embedding和entity embedding在同一个公共的向量空间;
- Context Attention:local ED, 通过候选实体集合选择最能够为ED提供信息的上下文,与CNN等黑盒方法,相比attention机制具有可视化,可解释性更强.
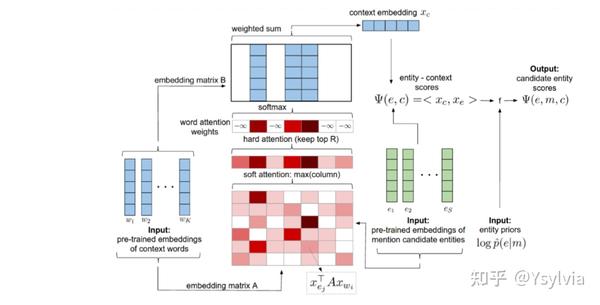

- Collective Disambiguation:collective ED, 使用CRF(条件随机场)进行联合消歧,使用LBP学习参数(第一个在NLP中使用可微分的信息传递message passing).
1. Entity embeddings(这一部分可以参考word2vec的实现)
目标函数J(z;e),使用max-margin objective, z表示将所有参数正则化(不确定?)限制在一个长度为1的超平面,w+ w-分别表示positive samples和negative samples,r是margin值,尽量拉大正样本和负样本之间的距离.
生成positive samples:words和entity的共现服从条件分布:p(w|e), 从收集到的word-entity对获得(w,e)的共现次数,(w,e)对来源于:(1)实体的维基百科页面,(2)标注语料entity的窗口中:
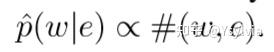
生成negative samples:q(w)是一个一般字概率分布,使用(Mikolov et al., 2013)word2vec中的smoothed unigram distribution:
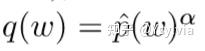
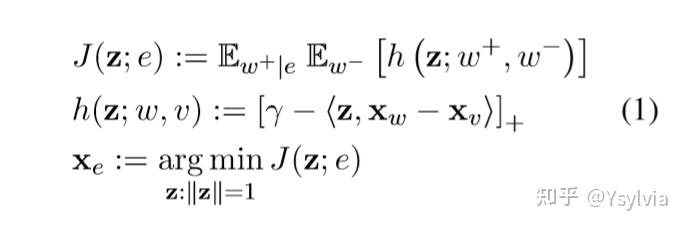



2. context attention,这一部分看图和论文很好理解,就不展开了
3. 环路信念传播LBP详解:


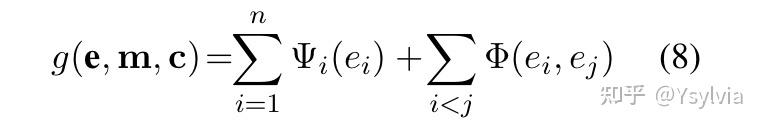

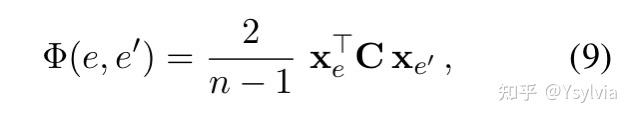

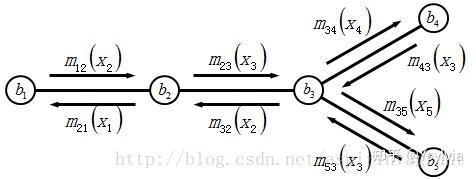
如果直接最佳entity组合,计算量将会很大,是NP hard问题,对于chain-like link, 假设每个mention有N个candidate entity,有K个mention,复杂度O(N^K),对于更加稠密的graph,复杂度更大。因此,在学习(learning)过程中,通常最大化可能性近似,在预测过程中,使用使用基于消息传递(message passing)的近似推理过程(inference).
3.1 LBP过程:置信度传播算法(Belief Propagation) :
BP算法主要弄清楚 节点之间概率消息在随机场中的传递message passing mij。

置信度belief替换为概率(marginal probability):
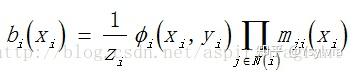
bi(xi) 为节点i的联合概率分布,是通过节点i的局部证据Фi(xi,yi)和他的邻接节点传播给他的消息mji得到的。
Фi(xi,yi) 表示节点i的局部证据,表示节点i的联合相容度,在本文中,这个值可以表示成local score,即entity i 是mention正确实体的证据。
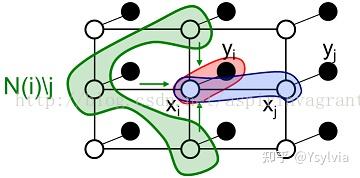
传播的消息mji:j给i关于i应该出于什么分布,代表隐含节点j传递给隐含节点i的消息,表明了隐含节点i对隐含节点j当前状态的影响,在本文中表示mention j entity j给mentioni entity i的影响。计算方式如图11表示,第一部分,表示j的取值有多个(不确定),Фi(xj,yj) 表示mention j取entity j的概率, \psi ji(xj,xi)表示转移概率,xj转移给xi的概率,N(j)\i表示节点j的MRF一阶邻域中排除掉目标节点i的邻域。
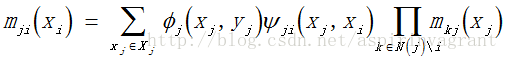

具体计算方式:首先对一些初始节点的消息赋初值mij=1,然后多次迭代消息传播和置信度更新直到它们稳定,最后就能从置信度中获取相应的概率。
标准最大乘置信度传播算法


第二步,随机选取相邻的两个点xs,xt,,取使当前第t+1次迭代mst最大max的xs,xt的值,更新mst值, 每一次迭代更新所有的点的取值xs, xt,以及mst. 经过T轮迭代,直到收敛。
3.2 LBP在本论文中的应用(相乘全部变为相加)
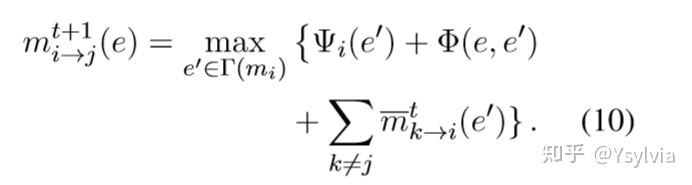

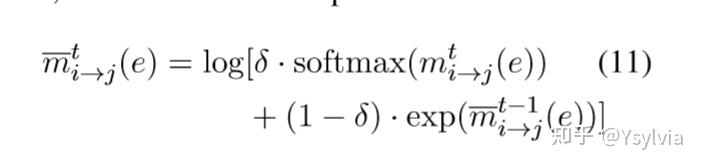

经过T轮迭代后的信念(边缘):
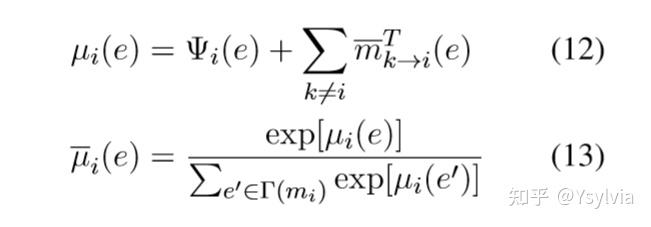

拼接先验得到全局得分:
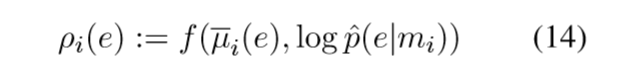

最后整体的目标函数:是a margin-based objective ei*表示正确的实体,h(mi,e)表示正确实体得分与当前实体的得分, 使用ranking loss和relu, 即如果错误entity和正确entity的具体大于r,那么就可不用管了,直接=0。需要训练的参数有A B C矩阵,网络f的权重( \gamma ,迭代的轮数T...)。
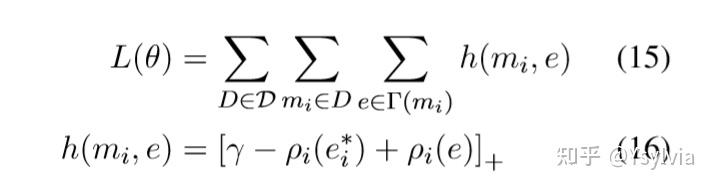

实验结果和分析略,代码参考:
