
学习型数据系统(上)

某人说,封面要用喵图片!
今天来介绍一波学术界里机器学习应用在数据系统中的技术和研究。(您还知道回来更新啊!)开门见山的说,这篇文章可能比较长,根据B乎后台的统计,以前的文章大概有一半的人看不完。(您以为我会把这篇写短一点吗?不,并不会,我只是跟你说一哈)。
先来个目录:
- 先说一哈Tim Kraska组现在的进展,主要讲下ALEX和 SageDB
- 回顾下学习型技术早期在数据库领域是怎么玩的
- 讲下近几年学习型技术在数据库相关领域的发展,包括 cache,disk error prediction,database(除了第一点),semantic storage 等等
=== 这大概是第一部分 ===
OK,有大佬应该记得我之前写了一篇Learned Index的文章介绍Tim Kraska组在SIGMDO2018 发表的论文 The Case For Learned Index Structures. 那么他们现在咋样了呢?不出意外,这篇文章的确在学术界(数据库领域)进一步把机器学习之风挂了起来。可以看下近几年DB三大顶会中出现 “learn”字样的 research/industry track 的paper的数量,的确是呈明显上升趋势的(其中VLDB截止至今年五月份,数据是我自己统计的,可能会有统计错误,建议不要引用)。
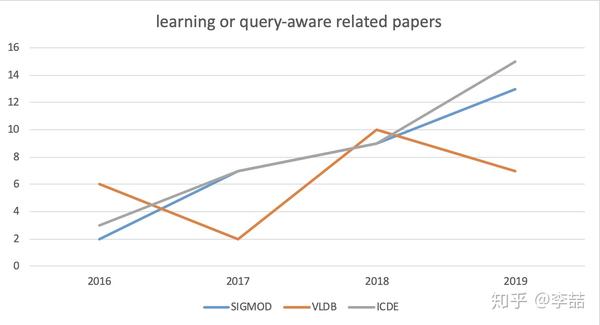

Tim Kraska也顺利成章的成为了学习型索引的开衫(误,山)鼻祖(谁让他在每篇paper后面都写一吨future work)。另外他之前的另一篇从省空间角度出发构建 学习型(其实这里更应该叫data-aware型)索引的论文 A-Tree (后改名为FITing-Tree)也被SIGMOD2019 接收了。这里还挺让我惊讶的,毕竟都在arXiv挂了那么久了,这双盲机制有点形同虚设啊。
OK,来说一波SageDB。好像原文是公开的了,不过在Google不知道天朝能不能打开。总之先放出来了。
Tim Kraska and Mohammad Alizadeh and Alex Beutel and Ed H. Chi and Ani Kristo and Guillaume Leclerc and Samuel Madden and Hongzi Mao and Vikram Nathan (2019).SageDB: A Learned Database System. InCIDR 2019
SageDB牛逼的地方就在于完整的提出了一个革新性的数据库系统蓝图(贤者数据库。。。),把所有能用机器学习替代、结合的地方都替代、结合了。其中最重要的几点就包括之前的学习型索引,以及新提出的学习型排序和学习型数据排布(即切分)。这些我们稍后会细讲。其他的比如cost model,aggregation等其实都存在蛮久了,我们放到第二部分讲。
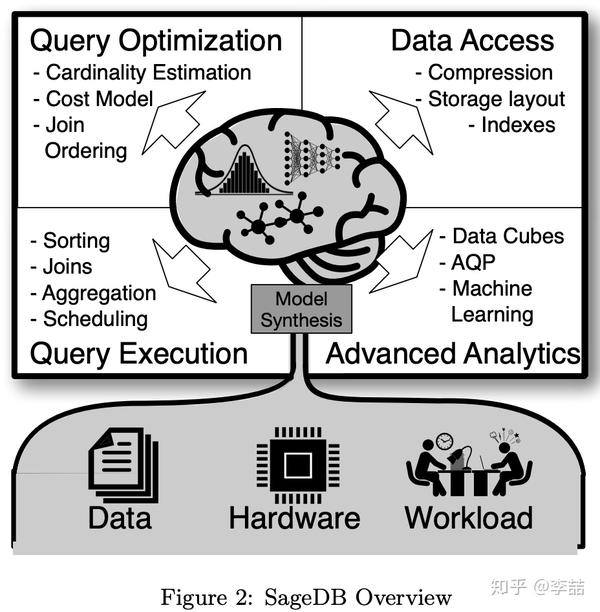

学习型排序,这个技术听起来比较优秀。其实非常简单,其核心思想是使得数据先大致排好序,然后再进行细微的调整。没啦。嗯。。还是说哈具体步骤吧:
- 先sample一部分数据 train 个RMI 出来(就是learned index里的那个RMI)
- 把所有数据用RMI predict一下,放在预测的位置
- 把相互顺序不对的调整一哈
其实可以算是Timsort 思想的一个延展,都是基于数据大致有序的情况下排序较快的原理。而learned sort只是多了一步如何使数据大致有序的操作。poster上给的实验结果是比已有算法快1.2~3.8倍。但其实在实习期间发现这和sample的效果和数据的分布都有很大关系。实际情况下能有50%提升已经非常不错。
再说下数据排布(以及数据切分 data partitioning,因为一般都是先排好了再切)。这个技术是用来解决多维查询用的。我在之前的blog也说过,单纯的降维扩展learned index对于多维查询并木有什么帮助。因为多维范围查询有个显著不同点是,你没法使得数据在存储器上按照任意维度连续。而且范围查询最大的瓶颈在于提取的数据量,在于IO,而不是从索引到达数据的速度。这就使得如何对数据进行切分显得尤为重要(特别是在外存数据库)。
举个栗子 。现在隔壁大郎养了1000只各种各样的喵,如果把喵随机分布后编号并按照编号等量划分到10个床上(为啥是床啊?)那么大郎在每个床上都能看到各种各样的喵。现在问题来了,如果大郎只想宠幸布偶(RMB),那么他要把10张床都睡(误,走)一遍,才能把RMB都拿出来。但是每到一张床,剩下的喵能让大郎想来就来想走就走吗?不能!这就是赤裸裸的IO啊!你不能只拿一只喵,要拿就拿一床!
后来大郎想了一个办法,现在他把喵按照品种分。所有布偶放一床,所有大橘放9床。现在大郎轻松多了!每次只需要一次IO!
诶!这就是根据 historical query 去改变数据排布(数据切分)来降低IO的基本思想!把经常要查询的数据聚集在一起,而不是分散在炒鸡多的节点里(在HDFS里一般算block,128MB,在其他DB里一般算page,4KB,不过这取决于具体实现了),这样可以显著地减少IO。在Tim Kraska组的poster里(Learned Multi-Dimensional Index for Data Warehouses),他们使用了贝叶斯优化的方式来确定切割的维度,每个维度切割的间隔以及维度的先后顺序(还是蛮一目了然的,我就不讲细节了)。


其实这种方法可以当做是一个模型,这个模型究竟能不能完美拟合最优解呢。我觉得是不行的,因为他有蛮多限制,比如每个切分必须是等间隔的。这使得该方法的表达空间大大受限。但也没办法,如果是非等间隔,则自由度实在太多,训练成本太大(想想RL的训练时间,当然可能还有其他原因)。
其实我在华为实习期间的主要研究就放在这方面了(成果目前还不能透露)。
那么以前的人类是咋做data partitioning的呢?其实我觉得有两篇论文讲的不错。一篇是AQWA(VLDB2015),一篇是Amoeba(SoCC2018)。
Aly A M, Mahmood A R, Hassan M S, et al. AQWA: adaptive query workload aware partitioning of big spatial data[J]. Proceedings of the VLDB Endowment, 2015, 8(13): 2062-2073.
Shanbhag A, Jindal A, Madden S, et al. A robust partitioning scheme for ad-hoc query workloads[C]//Proceedings of the 2017 Symposium on Cloud Computing. ACM, 2017: 229-241.
简单说一下吧。前一种方法利用query对KD-Tree切分进行改进。并用histogram统计数据和查询,来快速搜寻解空间,以最低化自己提出的cost model(总访问数据量)。其实比较直观。
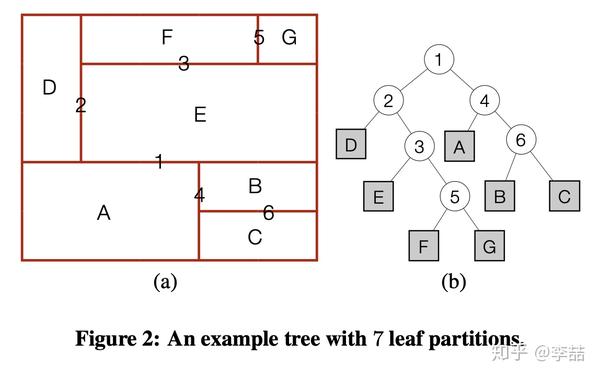

第二种是针对Ad-Hoc query,每来一个query对partition进行一次尝试改进。并提出了三种repartition方式,即置换,提升和旋转。来使得经常查询的维度上升到partition的更高层。缺点是每来一个quey都要这样做一遍,有点过于频繁。


这些方法,其实不能叫机器学习的learning,但更符合一种人类通俗意义上的learning,即对事物进行感知而做出改变。这里对query进行感知。所以可以称之为 query-aware techniques。
最后来说一哈 ALEX。目前这篇文章还在arXiv上挂着。ALEX就有点意思了,他解决了学习型索引插入删除老大难的问题(同样是Tim Kraska组的)。
Ding J, Minhas U F, Zhang H, et al. ALEX: An Updatable Adaptive Learned Index[J]. arXiv preprint arXiv:1905.08898, 2019.
说到这,就不得不再回顾(误,鞭尸)一下RMI和FITing-Tree。基于静态数据构建的CDF(cumulative distribution function)模型在插入元素后,插入点后面的所有key-value值都会变,如果变化超过error threshold,必须重新训练所有模型,这也太令可达鸭爆炸了。
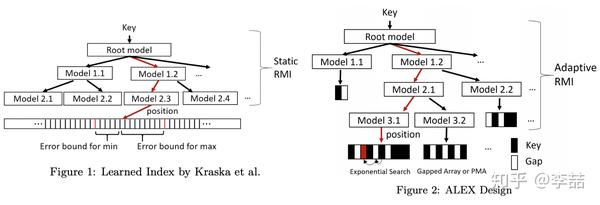
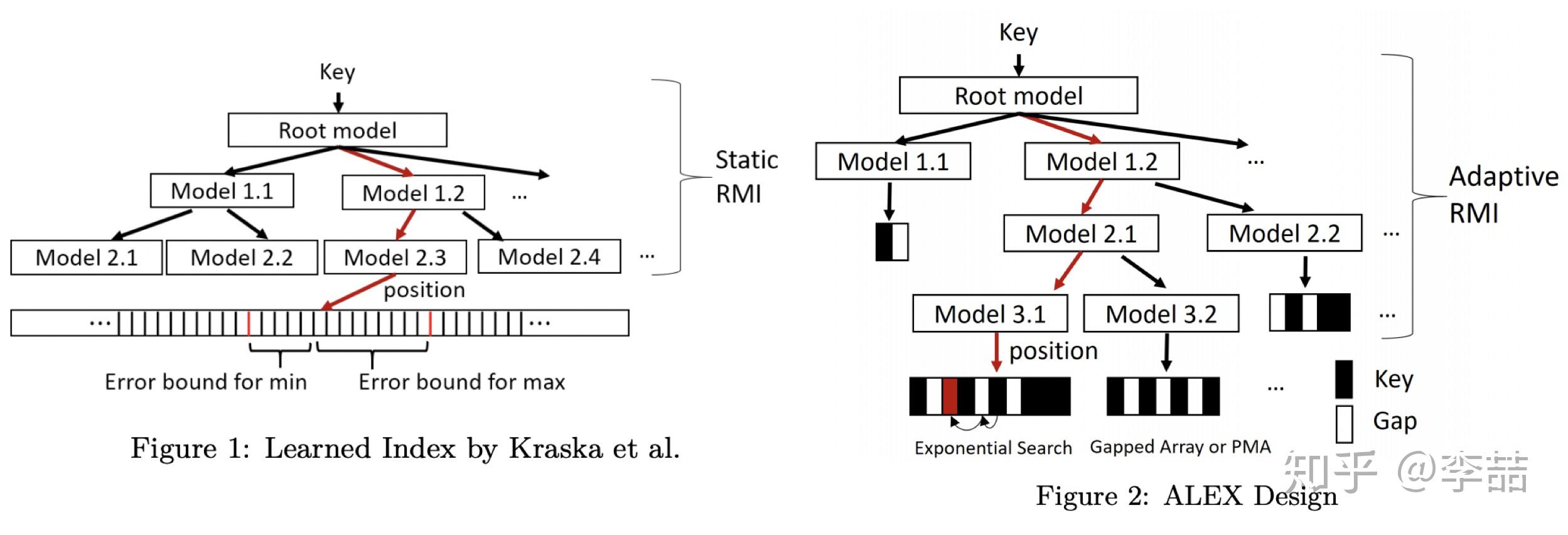
ALEX的核心解决思路是:
- 让每个模型独立管理自己的数据。即插入到自己这部分的数据变化不影响其后的模型。
- 更改数据存储结构。使得插入、删除更为迅速。
可以看到上图中,左边的RMI用多个模型直接模拟整条array,而右边的ALEX则每个模型下挂自己的数据结构。这样当一个插入,比如右图红色箭头来的时候,只要调整自己的模型就好了,而不影响其他的模型。(当然可能还会影响父节点模型进行分裂)
关于数据结构。ALEX使用了gapped array和 packed memory array两种。其实就是有间隙的array。后者提供了间隙的管理机制。这样做的好处是是的插入性能大大提升。直观理解就是如果插入的地方没有元素,直接放进去就好了,少了个挪动的步骤,即用空间换时间。可以参考在gapped array中 insertion sort是 O(nlogn)的栗子。
M. A. Bender, M. Farach-Colton, and M. A. Mosteiro. Insertion sort is o(n log n). Theory of Computing Systems, 2006.
除此之外还有一些细节的区别点。比如:
- ALEX提供了动态调整RMI结构的能力。比如在插入一个模型的数据超过threshold后可以以当前模型为父节点,生出若干个子节点来重新分配数据。
- ALEX将数据插入在自己predict的地方。这和RMI有很大的不同。RMI是先排好序,让后训练模型去拟合数据。而ALEX是在模型拟合完数据后,将数据在按照模型的预测值插入到对应的地方。这大大降低了预测的错误率。(如果预测的地方被占了,再进行挪动或分裂啥的)
- 由于每个模型各自管理自己的数据等因素,ALEX不再有absolute error guarantee,也就不能用binary search去定位。作者给出的替代方法是exponential search,这在误差下的情况下效果会比binary search更好。
在这解答一些问题。可能有人会问,那如果真是值被预测到错误的模型管理的array咋整?您可以仔细想一下,这种情况并不会发生(因为有插入在预测点的这一操作)。那插入后会不会需要重新训练父节点或爷爷节点呢?也是不需要的。在同一个节点中数据是相对有序的吗?是的。那么节点之间可以保持相对有序吗?比如A节点的末尾一定比B节点的开始要小吗?我觉得不一定。如果是这样的话,range query应该就不支持了。
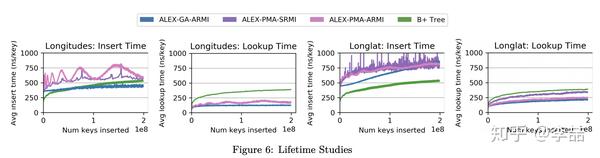
那么ALEX是不是就是完全体形态呢?我觉得不能叫完全体(至少还不完美,比如在下图的life long性能测试中,在第三组波动比较大的数据上插入性能比Btree差了很多),但短期内可能也难以再提升了(看看他们在arXiv上挂的文章的方向就知道了)。

看比赛去了...今天就到这...真香!
=== 这大概是第二部分 ===
有可能在以后的 学习型数据系统(中)
=== 这大概是第三部分 ===
有可能在以后的 学习型数据系统(下)