
The Google File System(GFS)学习笔记

引子
这篇文章是我学习极客时间徐文浩老师的《大数据经典论文解读》课程的学习笔记,大量的文字和图片来自专栏内容,如有侵权就删。
这篇2003年发表的论文,虽然时间比较久了,但是它依然是大数据领域中的经典论文。
论文地址:
这篇论文的核心是解决分布式环境下如何高效存储海量数据的问题。
GFS的架构
GFS是单Master架构,单Master让GFS的架构变得非常简单,避免了需要管理复杂的一致性问题。不过它也带来了很多限制,比如一旦Master出现故障,整个集群就无法写入数据。
在整个GFS中,有两种服务器,一种是Master,也就是整个GFS中有且仅有一个的主控节点;第二种是chunkserver,也就是实际存储数据的节点。
既然GFS是叫做分布式文件系统,那么这个文件,其实就可以不存储在同一个服务器上的。
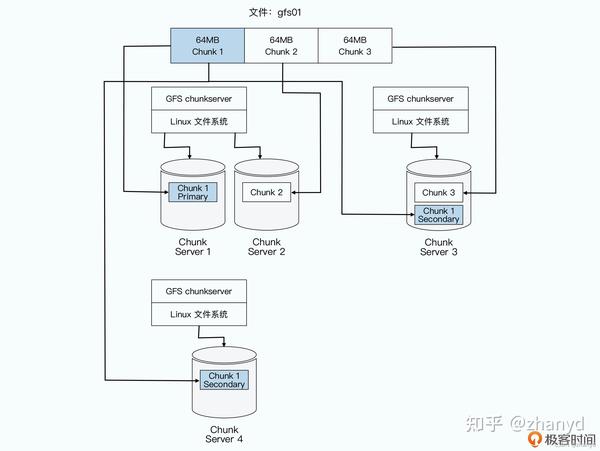
因此,在GFS里面,会把每一个文件按照64MB一块的大小,切分成一个个chunk。每个chunk都会有一个在GFS上的唯一的handle,这个handle其实就是一个编号,能够唯一标识出具体的 chunk。然后每一个chunk,都会以一个文件的形式,放在chunkserver上。
而chunkserver,其实就是一台普通的Linux服务器,上面跑了一个用户态的GFS的chunkserver 程序。这个程序会负责和Master以及GFS的客户端进行RPC通信,完成实际的数据读写操作。当然,为了确保数据不会因为某一个chunkserver坏了就丢失了,每个chunk都会存上整整三份副本(replica)。
其中一份是主数据(primary),两份是副数据(secondary),当三份数据出现不一致的时候,就以主数据为准。有了三个副本,不仅可以防止因为各种原因丢数据,还可以在有很多并发读取的时候,分摊系统读取的压力。

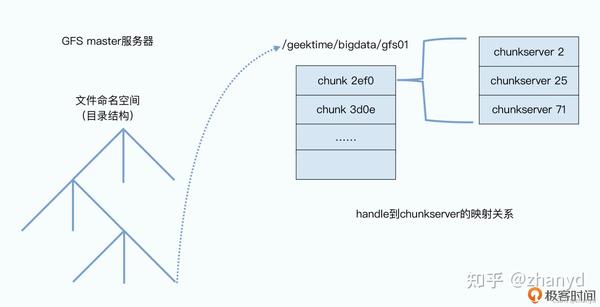
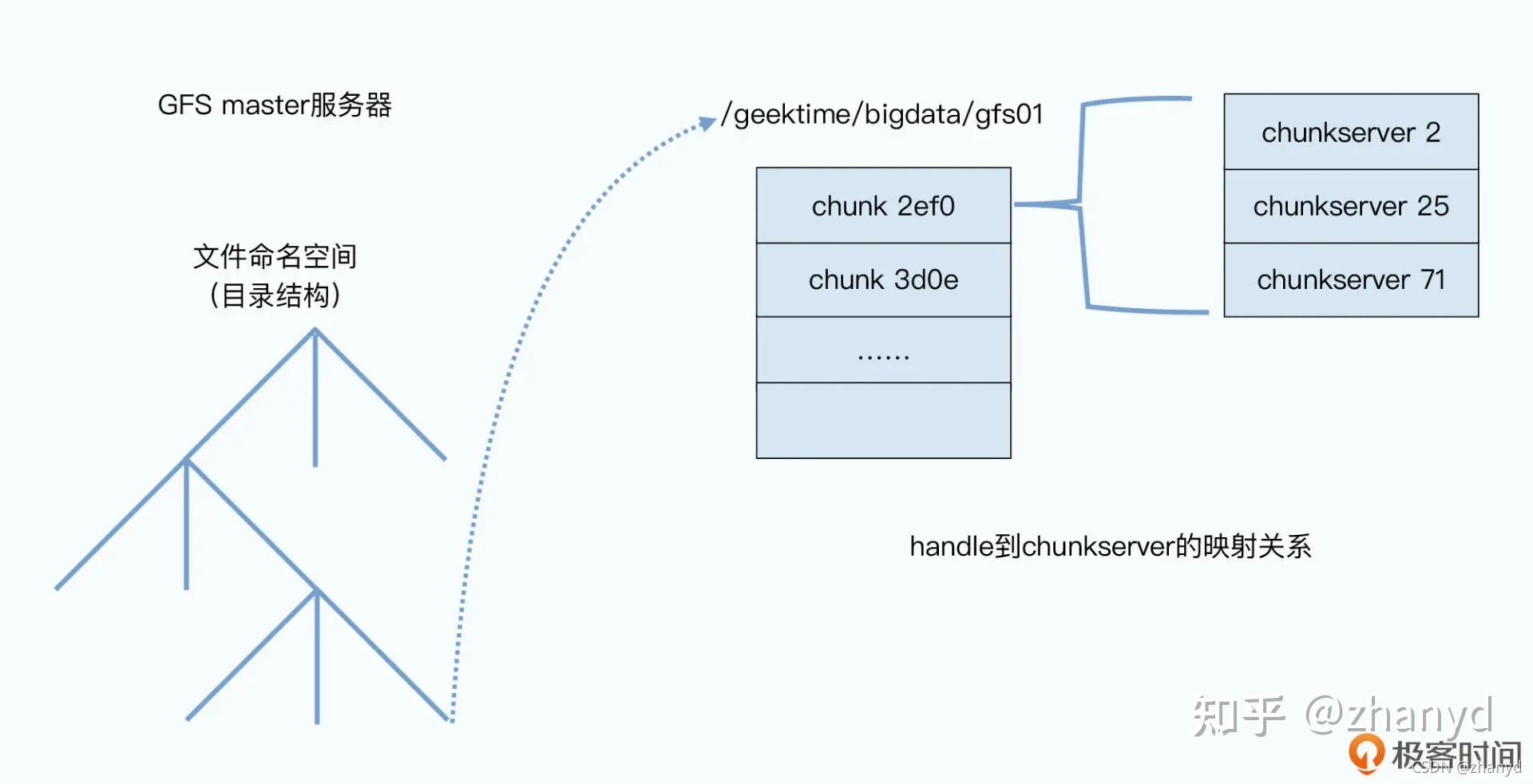
首先,master 里面会存放三种主要的元数据(metadata):
1.文件和 chunk 的命名空间信息,也就是类似前面 /data/geektime/bigdata/gfs01 这样的路径和文件名;
2.这些文件被拆分成了哪几个chunk,也就是这个全路径文件名到多个chunk handle的映射关系;
3.这些chunk实际被存储在了哪些chunkserver上,也就是chunk handle到chunkserver的映射关系。
关于Metadata,论文原文如下:
★ The master stores three major types of metadata: the file and chunknamespaces, the mapping from files to chunks, and the locations of each chunk’s replicas. All metadata is kept in the master’s memory. The first two types (namespaces and file-to-chunkmapping) are also kept persistent by logging mutations to an operation log stored on the master’s local diskand replicated on remote machines. Using a log allows us to update the master state simply, reliably, and without risking inconsistencies in the event of a master crash. The master does not store chunklocation information persistently. Instead, it asks each chunkserver about its chunks at master startup and whenever a chunkserver joins the cluster.
”
读数据
客户端需要读取数据时的步骤如下:
1.客户端先查找要读取的数据在第几个chunk中,因为每个chunk的长度是固定的64M,客户端根据要读取文件的offset和length就能够计算出需要的数据在第几个chunk上。客户端把文件名和chunk的信息发给Master。
2.Master拿到信息后,会把chunk对应的所有副本所在的chunkserver告诉客户端。
3.客户端拿到chunk所在的chunkserver信息后,客户端就可以去任意一个chunkserver中读取自己需要的数据。
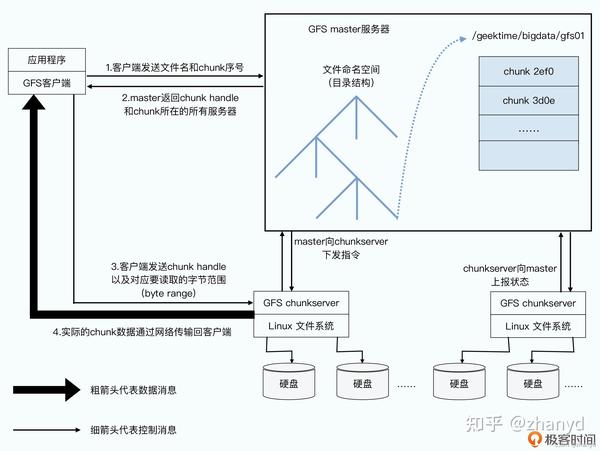

论文原图如下:
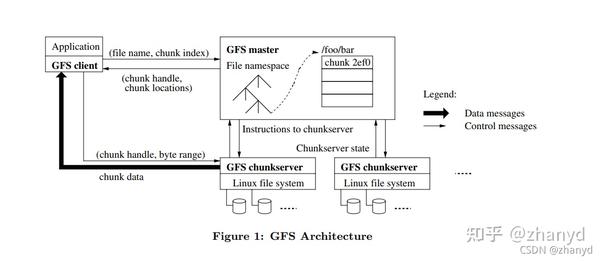

单Master节点很容易成为性能瓶颈,一旦Master挂掉,服务就会停止。为了提高性能,Master节点的所有数据,都是保存在内存里的,这样也同时会带来问题,就是一旦 Master 挂掉,数据就会都丢了。所以,Master会通过记录操作日志和定期生成对应的Checkpoints进行持久化,也就是写到硬盘上。
这是为了确保在Master里的这些数据,不会因为一次机器故障就丢失掉。当Master节点重启的时候,就会先读取最新的Checkpoints,然后重放(replay)Checkpoints 之后的操作日志,把Master节点的状态恢复到之前最新的状态。这是最常见的存储系统会用到的可恢复机制。
但是问题又来了,如果Master节点彻底废了呢?硬件故障,开机都开不了怎么办?
不要怕,我们还有备胎,它们叫做Backup Master,我们在Master上写操作,对应的操作记录会保存到磁盘上,并且Back Master上的数据也保存成功之后,整个操作才算成功。这整个过程是同步的,叫做“同步复制”。当Master挂掉之后,就会选一个Backup Master备胎转正,变成新的Master。
不过切换新Master的过程有可能也比较长,需要读取Checkpoints和操作日志,这样就有可能会影响客户端使用,为了防止这一小段时间的暂停服务,设计人员又添加了个叫“影子 Master”的东西,影子Master会不断同步Master里的数据,不过当Master出现问题的时候,客户端们就可以从这些影子Master里找到自己想要的信息。影子Master是只读的,而且是异步复制的,所以不会有太多性能上的影响。
写数据
客户端写数据的主要步骤如下:
第一步,客户端会去问 master 要写入的数据,应该在哪些chunkserver上。
第二步,和读数据一样,master 会告诉客户端所有的次副本(secondary replica)所在的 chunkserver。这还不够,master 还会告诉客户端哪个replica 是“老大”,也就是主副本(primary replica),数据此时以它为准。
第三步,拿到数据应该写到哪些 chunkserver 里之后,客户端会把要写的数据发给所有的replica。不过此时,chunkserver 拿到发过来的数据后还不会真的写下来,只会把数据放在一个 LRU 的缓冲区里。
第四步,等到所有的副本都接收完数据后,客户端就会发送一个写请求给到主副本。GFS 面对的是几百个并发的客户端,所以主副本可能会收到很多个客户端的写入请求。主副本自己会给这些请求排一个顺序,确保所有的数据写入是有一个固定顺序的。接下来,主副本就开始按照这个顺序,把刚才 LRU 的缓冲区里的数据写到实际的chunk里去。
第五步,主副本会把对应的写请求转发给所有的次副本,所有次副本会和主副本以同样的数据写入顺序,把数据写入到硬盘上。
第六步,次副本的数据写入完成之后,会回复主副本,我也把数据和你一样写完了。
第七步,主副本再去告诉客户端,这个数据写入成功了。而如果在任何一个副本写入数据的过程中出错了,这个出错都会告诉客户端,也就意味着这次写入其实失败了。
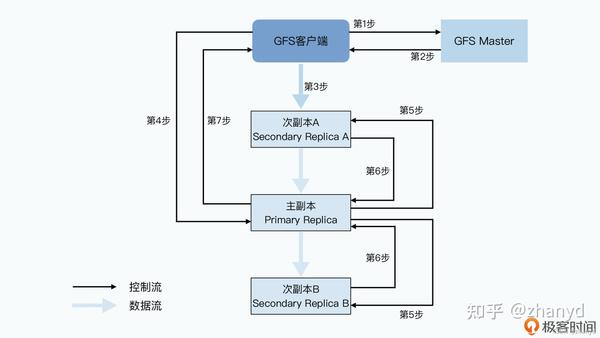

和之前从 GFS 上读数据一样,GFS客户端只从master拿到了chunk data在哪个chunkserver的元数据,实际的数据读写都不再需要通过master。另外,不仅具体的数据传输不经过master,后续的数据在多个chunkserver上同时写入的协调工作,也不需要经过master。
流水线式的网络数据传输
客户端不会把数据依次传给多个chunkserver,而是先把所有数据传给离自己最近的chunkserver,然后让chunkserver再把数据同步给其他副本。
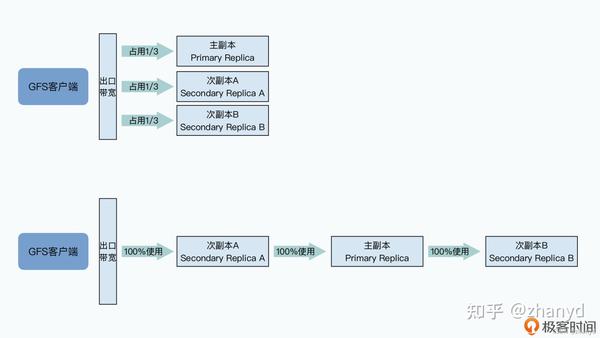

这样做的好处是,绕过了客户端的网络瓶颈,服务器之间的数据传输效率要比客户端快很多。
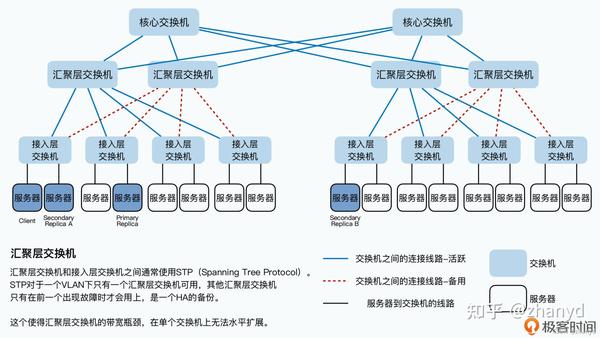

首先,客户端把数据传输给离自己“最近”的,也就是在同一个机架上的次副本A服务器;
然后,次副本A服务器再把数据传输给离自己“最近”的,在不同机架,但是处于同一个汇聚层交换机下的主副本服务器上;
最后,主副本服务器,再把数据传输给在另一个汇聚层交换机下的次副本B服务器。
在写入数据的时候,客户端只是从master拿到chunk所在位置的元数据,而在实际的数据传输过程中,并不需要master参与,从而就避免master成为瓶颈。
在客户端向多个chunkserver 写入数据的时候,采用了“就近”的流水线式传输的方案,避免了客户端的网络成为瓶颈。
记录追加
上面的这种写入方式很容易出现问题,也就是多个客户端同时写一个chunk的时候,会把对方的数据覆盖。为了解决这个问题,GFS推荐一种主要的数据写入方式,叫做“记录追加”,它能保证原子性(Atomic),而且能够做到在并发写入时候是基本确定的。
具体操作过程如下:
1.检查当前的 chunk 是不是可以写得下现在要追加的记录。如果写得下,那么就把当前的追加记录写进去,同时,这个数据写入也会发送给其他次副本,在次副本上也写一遍。
2.如果当前 chunk 已经放不下了,那么它先会把当前 chunk 填满空数据,并且让次副本也一样填满空数据。然后,主副本会告诉客户端,让它在下一个 chunk 上重新试验。这时候,客户端就会去一个新的 chunk 所在的 chunkserver 进行记录追加。
3.因为主副本所在的 chunkserver 控制了数据写入的操作顺序,并且数据只会往后追加,所以即使在有并发写入的情况下,请求也都会到主副本所在的同一个 chunkserver 上排队,也就不会有数据写入到同一块区域,覆盖掉已经被追加写入的数据的情况了。
4.而为了保障 chunk 里能存的下需要追加的数据,GFS 限制了一次记录追加的数据量是 16MB,而 chunkserver 里的一个 chunk 的大小是 64MB。所以,在记录追加需要在 chunk 里填空数据的时候,最多也就是填入 16MB,也就是 chunkserver 的存储空间最多会浪费 1/4。
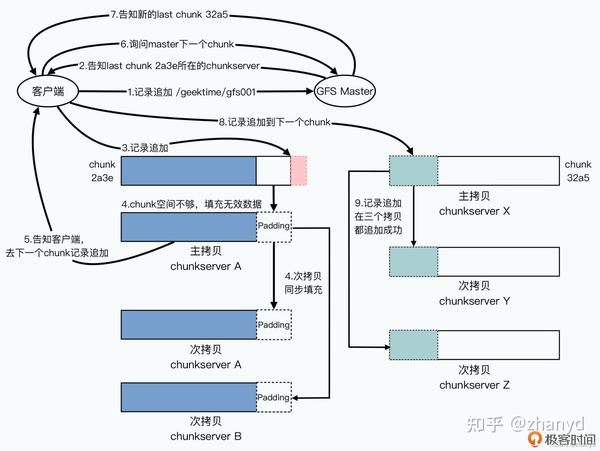

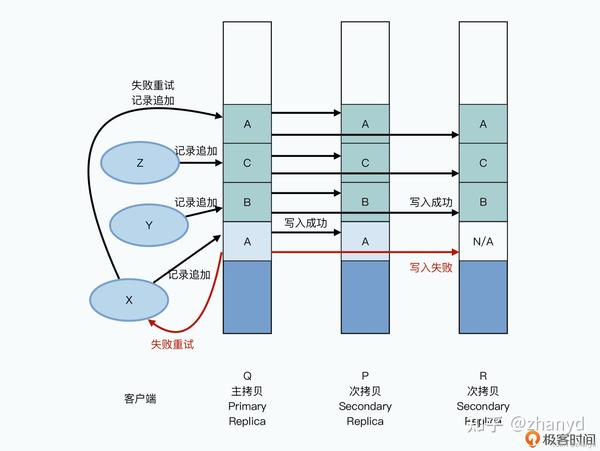
每个客户端会被分配到一个chunk上的独立空间,然后并发写入,由于每个客户端都各自写自己的独立空间,就不会有冲突。如果写入失败了再找个新的空间重新写,最多的是顺序不一样,能够保证数据是完整的。
比如客户端x要写入的数据A在chunkserver R上失败了,就会重新追加到C后面,虽然有一些重复的数据,但是能够保证数据最终是完整的。

总结
最后,我们看一下GFS的整体设计图如下:
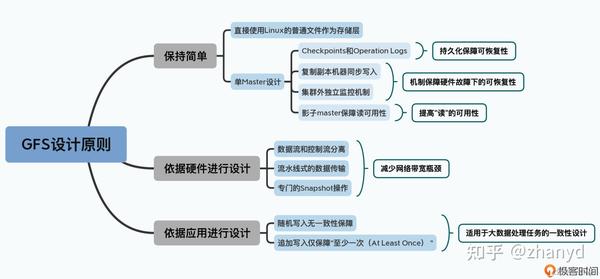

总结一下,GFS 的设计原则就是简单、围绕硬件性能设计,以及在这两个前提下对于一致性的宽松要求。
GFS的设计并没什么理论上的创新,而是根据硬件的限制条件在设计上创新。适合自己的就是最好的,我们不一定要去追求什么高大上的技术,能够低成本满足需求的就是好方案。创新不一定是要创造出什么新东西, 把一些东西按适当的方式组合在一起也是创新。
