机器学习中的小样本学习一个问题,何为小样本?

本文首发于公众号“夕小瑶的卖萌屋”。
大家好,我是Severus,一个在某厂做中文自然语言理解的老程序员。
这个主题,源自于我之前在公司内做的一次技术分享。承接上一篇文章(格局打开,带你解锁 prompt 的花式用法),我想要继续分享一下,我们后续尝试的实验及分析,以及我对小样本的看法。
简单回顾一下
在我的上一篇 promt 推文中,我介绍到,我是用 prompt 做一个工业级的细粒度应用,即解语-NPTag:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_to_knowledge/nptag
在这个项目的实验过程中,考虑到,这个模型发布之后,用户可能会有定制化的需求。所以,我们也想要实验一下,能否快速定制该模型,
于是,我们就手动设置了一个定制实验:删除掉训练样本中所有的“博物馆”类,然后重新训练,得到一个模型。然后,我们使用这个模型直接去预测被删掉的样本,注意,这时模型是从来没有见过“博物馆”类样本的,神奇的是,在这2000多个样本的“博物馆”集合上,模型预测正确达75%。
这个结果本身很是让我震惊,我顺便也分析了一些错误 case。我们发现,case 中绝大多数是样本后缀不为“博物馆”的,比如“天文馆”、“文化馆”等;另有一些更加神奇的 case 则是,模型预测出了“大学博物馆”、“遗址博物馆”等更加细粒度的类别。
那么,我们可以说,模型具备了零样本学习的能力吗?
的确,博物馆类别的样本,模型从来没有见过,但是,与之相似的样本,模型真的没有见过吗?不,实际上,NPTag的样本中,有大量的样本类别,实际上就是样本的后缀。那么我们有理由相信,实际上,我们给了模型充分的提示,让模型能够分辨出,符合名词后缀的语义。
基于这种假设,在另一个挖掘模型(在之前的萌屋文章评论区,笔者看到,有的小伙伴提问:为什么 Prompt-tuning 不敢做信息抽取任务呢?别着急,这不就来了么?)研发过程中,我们针对性设计了一个实验,输入一个小说的描述句,同时抽取出小说的作者和小说类型,例如:
《烟雨剑歌》是连载于塔读文学的网络小说,作者是枕言。
其中,“网络小说”和“枕言”就是我们的目标,需要将二者同时抽出来。不出所料,仅需500个样本,即可达到95%的测试精度,同时我们也在测试过程中,发现了类似的 case:
《袖揽蓝颜》是一部连载于红袖添香网的言情类小说,作者是不懂的还是不懂。
上述样本中,ground truth 给的是“网络小说”(即我们原本数据的标签是网络小说),而模型预测出了“言情小说”,作者预测的也是对的。
那么,我们觉得,我们似乎摸到了一个东西的门槛,即某一任务下,样本的高效描述方法,我称之为样本的模式。
样本的模式?什么鬼?
模式在维基百科上的定义是:存在于人们感知到的世界、人造设计或抽象思想中的规律。在我的定义中,则是任务之下,样本的一种归组方式,可以将无限的数据按照一些任务下的规律,归组为有限的组合,而在构造样本集的时候,仅需覆盖所有的组合,即可认为构造了完备的样本。
所以,我一直在强调,样本与问题空间的关系。首先,我想和大家做一个小实验。
请大家和我一起想象一下,你的面前有一只鸟,这只鸟长什么样子?我想大多数的人和我一样,最直接想象到的形象,是麻雀的样子,可能外国人想到的是知更鸟的样子,体型不大, 身上有花纹、羽毛,长着翅膀,会飞,当然也会有一些小伙伴联想到鹰这种体型稍大的鸟。我们心中,“鸟”的原型可能就是这样,具备了一些绝大多数鸟类拥有的典型的特征,而形成了一种模式。
我们再想象一只不一样的鸟,可能我们就会去想鹰之类的大型鸟,这样做多几轮,可能我们逐渐就会想起孔雀、鸵鸟、家禽等长得不是那么典型的鸟。
其实,不知道大家有没有想到,企鹅也是鸟。

那么,在认知科学中,上述的思考过程,大致可以说是原型模型和样例模型。我们在记忆某一类概念,所感知到的东西的对应关系时,会将我们见到的东西抽象存储,抽象的结果即是原型,在面对一些匹配问题的时候,我们则可以快速将见到的东西和脑中的原型匹配,做出判断。当然也会有一部分不那么“典型”的感知信号,也要作为这一类别的对应,这些可能就作为样例而存在。
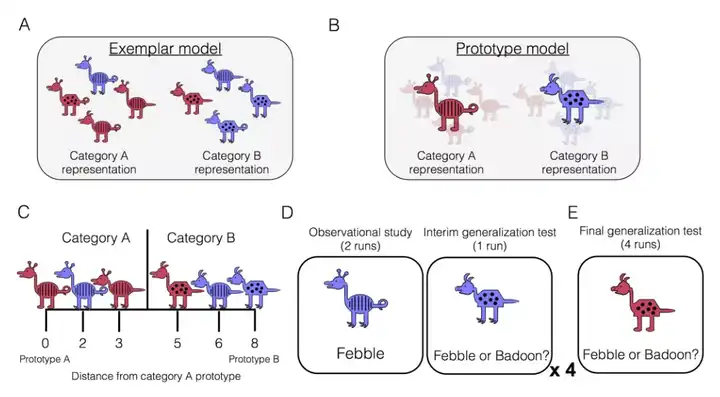

实际上,训练深度学习模型,我们也是希望模型最终能够学到,数据真实的原型的。而现在指导模型的方式,一定程度上,也是在模拟教小孩子的过程。那么问题来了,人类是通过小样本习得原型的吗?
人类能否通过一张图学会辨识一个物种?
如果是一个新生儿,能否仅仅通过一张图片,就大致认识一个物种呢?
比如,我们给一个新生儿看下面这张图,并且告诉他,这张图是马,他能否学会“马”是什么样子的呢?


读者朋友们可能本能地就会告诉我,这有什么难的,这张图里面就只有一个动物,其他的都是背景,甚至这张照片里面这个动物就处在焦点位置,你说这个是马,当然就是焦点位置的那个东西了。
但是,朋友们,不要忘了,天空、草地等作为背景板,马是个动物,甚至摄影构图的焦点,这些知识早已存在于你的脑海之中,但是对于新生儿来讲,这是一个完全空白的事情,对于一个新模型来讲亦然。
那么,请各位想一下,在不利用其他的任何知识的情况下,仅仅利用上述信息(这张图片是马),请问,你能否分辨,下面两张图片,哪张是马?


右图和上面给出的图片尚有共性,左图从视觉上看,不说是有共性吧,起码是没啥关系,是吧?如果按照人类概念形成的方式来看,是否与上图有更大相似点的右图会被认作是马呢?
所以,即便是人类,也难以通过小样本习得原型,而人类习得原型,起码需要:
- 注意力的指导
- 足够的模式覆盖
而具备了某一类问题中原型的人类,由于已经具备了抽取原型的能力,且脑海中有相应的原型去匹配,才得以具备在同类问题下,进行小样本扩展的能力。


在前面,我们讨论了,对于训练一个空白的模型,模式覆盖完全的样本的重要性。当然,如果模型的能力够强,训练的方法得当,那么每一种模式下,样本的量级反倒可能不需要那么大。而同时,小样本的前提则应该是,模型已经具备了目标任务,或与目标任务相似的原型,并且模型本身也具备灵活的扩展能力,方能 work。
那么回归到 prompt 的那个实验。实际上,我所作的扩展,看似是类别标签,或抽取要素的扩展,实则,我新增的所有样本,都是在我已定义好的任务模式之下的。即高度一致的上下文,或名词性短语的后缀,模型本质做的,还是生成任务,或者知识查询任务。
而 prompt 能在当前的小样本中拔得头筹,也是因为使用 prompt 的任务形式,和预训练任务是一致的,且使用 prompt 询问的知识,绝大多数也是在预训练过程编码了的,实际上也是同模式下的扩展。而我们也能看到,即便是 prompt,面对小样本任务,模式 OOD 的情况依旧是难以解决的。所以小样本归小样本,仍旧要覆盖完全目标问题空间的所有模式。
怎样描述样本模式
前面说了这么多,模式仍旧是一个看上去虚无缥缈的东西。怎么样去描述它,依旧是一个难题。
不过实际上,前辈们也已经做了很多的努力,试图去找到方法,优化数据。
基于统计的表示方法
深度学习时代,由于 DNN 模型实际上是表示学习模型,那么就有一个很直观的想法,任务模型的最终表示就可以当作是样本的表示。例如分类任务下,同一类别下的样本,训练过程中,其最终的表现一定是趋向于相似。于是,最简单的一种近似推定样本模式的方式,则是样本聚类分析。
我们可以将聚簇的结果分为纯簇、多数类簇、杂簇、低覆盖簇、未覆盖簇和散点6种情况,除散点一般照顾不到外,另外5种情况,都会有一些处理办法:
- 纯簇:即簇内所有样本都是一个类别。不用说,特征相当集中,直接采样就行了,且当前模型之下可以聚成纯簇,说明该簇内样本本身难度不大,或者可以说模式不复杂
- 多数类簇:即簇内所有样本不一定是一个类别,但某一类别占比具有绝对优势(例如99+%,随应用而定)。这种簇里面其实就可以看看里面的少数类样本,是不是标错了,或者是不是边缘样本,可以直接扔掉
- 杂簇:即簇内有多个类别,且各个类别的占比不具备优势。这种簇大概率是边缘样本,可能是在任务定义上,存在边界划分不清的地方,也可能是单纯簇的数量太多,可以对该簇重新聚类,观察效果,根据应用决定处理方案
- 低覆盖簇:后面的两种情况,是已标注样本与未标注的大规模数据混合聚簇的情况,通常在工业里面,我们会用这种方式检查样本的覆盖情况,以及决定是否需要扩充样本。低覆盖指的是,已标注样本在簇内占比较小,不过已标注的样本也可分为上述三种情况讨论
- 未覆盖簇:簇内全都是未标注样本,则也是重点需要覆盖的一批。如果模型学得比较好,簇内看上去模式集中,则可直接抽取覆盖,但如果看着也很散,也可以随机抽取一部分样本,标注后假如训练,迭代模型,进而迭代聚类结果
除模型的直接表示外,另外也有工作试图通过样本在模型训练中间的表现,用来衡量样本的模式,例如样本的遗忘事件,样本对模型更新参数的贡献等(具体参见往期推文:我删了这些训练数据…模型反而表现更好了!?)。另外就是数据集蒸馏,也就是将大规模的数据蒸馏到小规模的人工数据上。

不过我们发现,基于统计的方法,实际上都存在前提:即需要有相对较大规模的已标注样本,才能够利用 DNN 模型统计出来,并且,统计方法有其适用场景限制——其只适用于问题边界划分清楚,样本特征集中的场景。若问题边界难以界定清楚,或特征过于离散,或任务之下,样本单独的表示难以计算(如序列标注任务),则难以使用统计的方法。
基于符号知识的表示方法
实际上,针对自然文本数据,我们在试图探索一种,基于符号知识的表示方法。
首先,NLP 的基础问题是:从无结构的序列中预测有结构的语义,其通用目标则是,降低文本空间描述的复杂度。我们知道,描述自然文本空间,天然存在的问题是:词汇的数量是无限的,组合起来更是会爆炸。所以我们需要去基于一些相似度量,找到文本空间的描述方法。
当然,现在的 NLP 领域,已经有了类似的大杀器,即预训练语言模型(PTMs)。PTMs 通过其大规模的参数量,以及训练数据量,包含了绝大多数的统计共现知识,看上去,这个问题我们似乎是有解的。
但是,首先,PTMs 学到的表示我们没办法干涉或扰动,而如果想要利用 PTMs 学到的表示,如我前文所说,还是需要同任务模式之下方可。但,MLM 系列的表示非常复杂,难以计算;而[CLS]等全局观察位,或训练任务比较简单(BERT/ALBERT),或根本没有训练目标(RoBERTa),其表示在无任务监督的情况下没有意义。
同时,统计共现中,也会存在因训练语料中,分布的偏差,而导致对一些文本建模不好,也会有覆盖不到的东西。所以,在统计共现之外,我们同样需要一种与之互补的方式,去描述文本空间,即符号知识。
我们在理解语言的时候,使用到的知识,包括了脑海中存储的世界知识(事实知识),同时也包括了语言本身的通用知识。世界知识自不必说,目前知识图谱是形式化描述它的主流方式,而在我们面对描述未知事实的文本时,主要发挥作用的则是通用知识,只是通用知识是怎么样描述的,目前尚未有定论。
在英语中,文本的结构化解析可说是相当成熟,从词性,到语法结构、语义角色等,有非常好的结构化建模方法,或着说符号描述方法。早期的各种知识挖掘任务,使用不同层次的结构化解析结果,加上若干规则及特例,即可做出比较好的效果,可以说,在英语里面,这一套是很成熟的。
但,汉语的 NLP 研究路线,几乎都是照搬自英语。英语的解析方法非常符合英语的语言特性,但和汉语的语言特性就存在一定的不适应之处:
- 英语本身更偏屈折语,注重形合,依靠词形变化、连接词等显示的形式标记连词成句,词性、句法特征强。且其单词的词性与在句子中扮演的成分一一对应。
- 中文更偏孤立语(无词形变化),注重意合,依靠次序和词之间的意义联系成句,词性、句法特征弱。
那么,中文的词汇没有形态变化,词的兼类现象严重。在中文里,如果把句子成分和词的词性对应,则一个词可能会有多个词性(类有定职则词无定类);如果将一个词固定为一个词性,则该词性的功能不稳定(词有定类则类无定职)。因此,中文不能效仿WordNet,以词性划分为组织。
那么实际上,在机器学习中,我们是没有既成的体系以供参考的。
不过,对此,中文语言学的前辈们早已给出了属于中文的答案:凡本身能表示一种概念者,叫做实词;凡本身不能表示一种概念,但作为语言结构的工具者,叫做虚词。实词的分类,当以概念的种类为根据;虚词的分类,当以其在句中的职务为根据。 所以,我们可以以语义词类划分实词,以词性划分虚词,组织一套用于中文的,稳定的,词类划分体系,将文本空间无限的词汇归组到有限的词类上,将词汇序列转换成词类序列。
谈到这个,你想要体验我上面所提到,专为中文而生的解析体系吗?那就不得不再次提一下我的项目——解语啦!
项目链接:
https://www.paddlepaddle.org.cn/textToKnowledge
甚至可以挖掘词类之间的关系、词之间的关系,实现文本的结构化表示,甚至文本的框架(明斯基提出的知识框架理论)表示,用以建模文本空间。
而到了任务上,我们也可以使用不同层次的表示,与任务的目标相对应,用以组织任务样本的模式。例如,NER 任务中,可以使用上下文的词、词类组合,也可以使用答案的成分推断等;SPO 挖掘任务中,则可以根据已有的表示,抽象出 predicate 的触发词/触发句式,用以表示样本的模式;主题分类任务则更为简单,可能仅需要部分词/词类/词类组合对应类别即可;推断任务/相似性任务则可以直接比对语义结构。
而有了符号知识(实际上也是人的先验知识)的帮助,我们则也可以从零样本开始启动一个任务,真正做到使用规则搞定标的过来的,使用模型搞定标不过来的,结合上面提到的基于统计的方法,形成一个正向的迭代循环。
谈一谈任务的定义
在我的上一篇推文(Google掀桌了,GLUE基准的时代终于过去了?)中,我提到,通用基准任务定义,本来是应该根据其要考察的人工认知能力,系统化地定义出来的。而实际上,扩展开来,任务定义,应当是根据其所要应用的场景(或想要衡量的能力),抽象出相应的问题空间,再根据问题空间,总结模式,收集数据,从而定义具体的任务。当然,最大的前提是,这个问题得是算法能够解决的。而每当有“灵光一现”时,都应当按照上述标准检视一下,否则仅会增加一个无用的基准,误导广大的研究者。

很遗憾,很多基准任务都是这个样子的,例如,在我的“NLP 反卷宇宙”里出场率极高的 SPO 挖掘任务。当然,最近的 CUGE 数据集论文我简要扫了一眼,发现里面出现了数学推理这一神奇任务,当然现在先按下不表,后面我可能直接开一篇新的帖子吐槽。
例如,SPO 挖掘任务,除我之前经常吐槽的数据质量问题外,其存在的另一个根本问题则在于—— schema 定义问题。仍是以之前提过的数据集为例:人物类和组织机构类之间,P 的定义只有“董事长”、“创始人”、“校长”三个,而没有其他的东西。那么按照我们前文所说,如以句式为模式,来看待这个任务,那么同一个表达,我们将“董事长”替换为“秘书长”,则正例就会变为负例,数据的偏置,势必给模型造成困惑。而如果以应用来看待这个任务,SPO 挖掘本身是为了构建图谱,而残缺不全的关系定义,最终能发挥什么作用呢?
而本篇的主题——小样本则尤甚。小样本的各类任务,妄图使用个位数的样本数量,去比拼效果。不过,个位数的样本,怎么可能概括问题的空间。实际上,小样本的效果相比于满样本,绝大多数存在大幅的性能损失,然而,其研究互相之间,进入了“比谁的没有那么烂”的循环。而归根到底,大家认为这种小样本可行,无非是 GPT-3 和 prompt 发挥的作用。
甚至出现了专门用于评测小样本的“通用”基准——FewCLUE,雷区蹦迪了属于是。
可是别忘了,GPT-3 的生成任务,或 prompt 的小样本,包括 Google 提出的 MoE 小样本模型(更加包罗万象了,毕竟 MoE 甚至可以多任务头,做任务级的迁移指导),其大前提仍旧在于,这些小样本任务本身的模式,早已在预训练阶段编码到了模型之中,上述技巧无非是想办法将这些东西抽取出来而已,而面对数据、模式等的未知,又如何能指望小样本呢?(人能不能通过一句话学会一门语言?能不能通过一次对决学会围棋?能不能通过听一首曲子学会乐理?)
不过,虽然纯小样本不可取,不过也正如前文所说,单一样本模式下,是可以尝试做到样本规模相对小一些的。我们提出样本模式的目标,也就是为了让构造样本更加简单,同时也是为了能够去降低样本的规模,用更少量的样本逼近更好的效果,或许它如果真的实现了,对通用预训练也是更大的促进呢。