
ECML 2021 | 最佳论文!北大提出基于隐式重参数化MCMC的高效GAN采样算法

作者 | 王一飞,王奕森#,杨建生,林宙辰(北京大学)
欢迎关注 @机器学习社区 ,专注学术论文、机器学习、人工智能、Python技巧
本文Reparameterized Sampling for Generative Adversarial Networks被ECML-PKDD 2021接收,并获得Best (Student) Machine Learning Paper奖。
会议简介:The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases(ECML-PKDD)是欧洲顶级的机器学习与数据挖掘会议。因为疫情原因,今年于9月13到17日在线上进行,由ASML、Google、Amazon等企业赞助。本文获评为机器学习方向最佳论文。因为一作是学生,同时也是最佳学生论文。

文章链接:https://2021.ecmlpkdd.org/wp-content/uploads/2021/07/sub_600.pdf
奖项链接:https://2021.ecmlpkdd.org/?page_id=2148
更多有趣的文章,欢迎访问ZERO Lab:https://zero-lab-pku.github.io/
摘要
本文利用了生成器所建模的结构信息,为GAN设计了一种通用且高效的MCMC采样算法,称之为REP-GAN。它通过将高维样本空间的转移(transition)重参数化为低维隐层空间的转移,突破了原有独立采样的限制,又同时克服了高维空间采样的困难,提高了样本效率。同时,我们还证明了对于一般的隐层采样,它所对应的MH比率存在闭形式解,使其可以通过MH检验来保证算法的收敛性。实验上,与以前方法相比,我们发现REP-GAN可以显著提高样本效率,并同时改善了样本质量。
1
变废为宝:如何挖掘判别器D中的剩余价值
众所周知,GAN [1]是通过生成器G与判别器D之间互相对抗、交替迭代的minimax问题,来逐渐学习如何建模数据分布。
如下图所示,我们分别从训练样本中采样得到真实样本,从生成器G采样得到伪样本。然后,判别器D被用来区分这两类样本,而生成器G则努力改变自身,使判别器D无法区分真实样本与伪样本。在这个过程中,通过判别器D传递的信息会逐渐改善生成器G的质量,并在最后得到一个不错的图片生成器,我们假设它所对应的样本分布为。
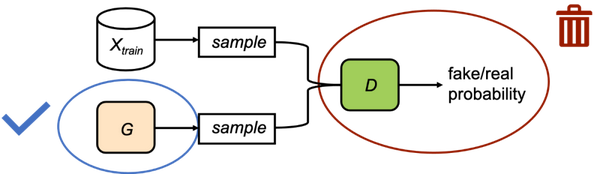
通常来说,当学习结束后,通过我们会把判别器D丢掉,只保留生成器G用来生成样本。但是,判别器真的没用了吗?事实上,在学习过程中,生成器一直是通过判别器来学习如何改进它的分布,这说明判别器中的确可能存在尚未完全被生成器消化的知识。而这启发我们可以通过循环利用D中的信息,来进一步提高生成器G的样本质量,使得它更接近于数据分布。
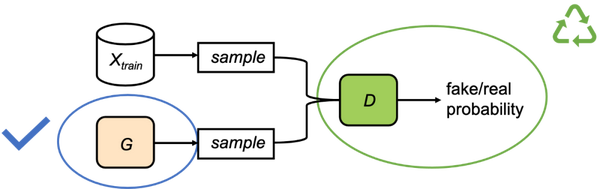
那么,D中到底包含什么有用的信息呢?Goodfellow等人的原始论文[1]中就指出,当D达到最优时,它本质上是估计了数据分布与生成器分布的密度比率(density ratio)。
利用这一信息,我们就可以进一步减小与这两个分布之间的差距。
MCMC(Markov chain Monte Carlo)算法恰好是一类通过构建合适的马氏链,让我们可以从一个(无法直接采样的)目标分布中进行采样的算法。将马氏链的k时刻状态的分布记为。在状态的基础上,MCMC会从一个提议分布(proposal distribution)中采一个提议样本。然后我们计算一个MH(Metropolis-Hastings)比率,并以这个概率扔一个硬币决定的接受与否。这个过程被称为MH检验。
假如被接受,则下一个状态;否则,将原地踏步。可以证明,在一定的条件下,如上的MH算法会保证这个马氏链的平稳分布即为目标分布。
2
MH-GAN的成功与致命问题
ICML 2019的一篇工作,MH-GAN [2],就成功地利用了密度比率这一信息,用MCMC算法来减小分布差距。具体来说,它将一条马氏链的初始化分布设置成生成器分布,并将目标分布设置为数据分布。另外,它使用生成器分布作为一个独立的建议分布,也就是说,它的建议与当前状态无关:
在这种情况下,它可以利用判别器的密度比率信息,使得MH比率有一个闭形式解,只与两个样本的判别器分数有关:
这样,按照上面的MH算法,MH-GAN就可以同时利用G和D的信息,使得得到的样本更接近数据分布。实验也表明,MH-GAN确实对于样本质量有明显的提高。
但是,我们可以注意到MH-GAN有一个致命的缺陷,即样本效率低下。由于采用了独立提议,提议的样本可能与当前状态差别很大,而这会使得MH ratio很低,也就是说,提议样本的接受率会非常低。在实际中,平均接受率经常不到5%。因此,马氏链会以很大的概率被长时间困在同一个地方,从而造成mixing缓慢,样本效率低。
3
从独立采样到相关采样:困难与解决之道
如何解决采样效率低的问题?一个自然的解决办法是使用相关(dependent)提议分布,,在附近找一个提议,这样接收的概率就大大提高了。但同时,MCMC的采样还存在一个所谓探索(exploration)与利用(exploitation)的权衡取舍:假如总是离很近,马氏链可能很长时间都陷在一个很小的区域附近;假如离很远,又容易因为差别太大而被拒绝。
事实上,在高维空间里,因为目标分布可能非常复杂、非凸非线性,去找到一个合适的提议分布,是非常难的一件事情。更雪上加霜的是,在GAN的语境下,目标分布是未知的,因此,对于一般的相关性提议分布,它的MH比率是无法计算的:
那么,这意味着我们无法使用相关性提议,而且无法使用MH检验吗?NO!我们发现,只要我们合理地利用GAN的结构信息,就可以设计出既可以有效探索又同时可以做MH检验的相关性提议!
4
REP-GAN:利用模型结构信息的重参数化MCMC
我们回忆一下,其实在GAN的训练中,我们不仅仅是学习到了生成器分布,还同时学习到了从低维的隐空间的先验分布(通常为标准高斯),到高维的样本空间的一个升维映射。因此,既然在高维空间直接设计提议分布是一件很难的事情,我们可以通过隐空间作为一个中介,对采样过程进行重参数化(reparameterization)。直观上,这个过程分为三步走:1)首先把样本 pull-back到低维的隐空间;2)然后我们利用隐空间的提议分布得到隐层样本;3)最后,我们将通过生成器push-forward到样本空间,得到。这样,我们就利用了GAN的结构信息,把一个复杂的高维采样问题,转化为一个相对简单的低维采样问题。再考虑到我们在GAN的训练过程中对隐变量作了标准高斯分布的假设,这会使得隐空间的能量景观会简单很多,因此,在隐空间设计提议分布是非常方便和高效的办法。我们将这种提议称之为重参数化(Reparameterized, REP)提议。
上面只是我们简单的直观,当我们实施的时候,就会发现一件棘手的事情,就是GAN并不是一一映射,我们无法直接同时做pull-back和push-forward。但幸运的是,我们如果一直利用这种重参数化的采样,就可以保证也是生成器的采样,而且有对应的隐层样本。这样,我们的采样过程就可以被描述成下面这种图的形式,它涉及到两条马氏链,一条在隐空间,一条在样本空间。在第k+1步,我们先在的基础上,通过隐空间的马氏链采样得到,然后我们将其push-forward得到样本,最后,我们在样本空间的马氏链上计算MH比率,通过MH检验判断是否接受。
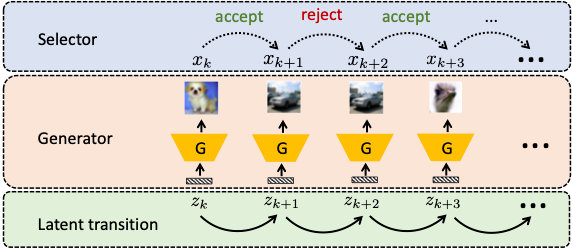
回忆前面的讨论,我们提到对一般的相关提议,不存在MH比率的闭形式解。那么,我们的重参数化提议也是如此吗?事实上,像下面的定理一所展示的那样,对于一般的隐层提议分布,我们可以证明:因为利用了GAN本身的结构信息,我们的重参数化提议所对应的MH比率是有闭形式解的,而且只和隐变量及其判别器的得分有关。特别地,当我们的隐层提议取标准正态分布的时候,我们就退化到了MH-GAN的MH比率。因此,MH-GAN可以被视为我们的一种特殊情况,而我们的REP-GAN成功地将MH-GAN从独立提议推广到了一般的(隐层)相关提议。

利用重参数化来改造目标分布的能量景观(energy landscape)的思想,其实在MCMC中并不罕见,之前的一些工作[3,4,5]都尝试过将神经网络用于改造、简化提议分布的设计。但这些方法通常都要借助于可逆的显式模型(比如flow)来完成pull-back和push-forward,而这要求变换前后维度相同,很难实现我们所期待的在低维空间设计提议的愿望。相比之下,GAN是一类隐式概率模型,它没有像flow、VAE等模型一样显式建模数据的概率分布。它的优点是它容许建模出更复杂的分布,不受模型假设的限制,缺点是我们无法显式计算它所建模的分布。在这里,我们利用了GAN的特殊结构(生成器与判别器),第一次证明了对于GAN这样的隐式概率模型,也可以使用重参数化的技巧来简化采样过程,这展现了重参数化技巧在MCMC采样中也适用于更一般的的应用场景,值得继续研究和发展。
这里,我们还可以展示了一个REP-GAN的实际例子。因为GAN是可微的,我们可以利用梯度信息来更有效的探索目标分布,但是,样本空间的Langevin采样,由于不知道目标分布的信息,其更新公式是无法计算的。
而我们如果转而在隐空间做Langevin采样,就会发现是其更新过程可以有闭形式解的!我们称之为隐层Langevin蒙特卡洛(L2MC, Latent Langevin Monte Carlo)
综上,我们把L2MC与我们的重参数化提议、MH检验组合在一起,就得到了一个完整的MH算法,我们称之为REP-GAN。其算法伪代码如下。

和之前的方法对比,我们同时使用了马氏链、MH检验、隐层梯度这些有效的机制,而以前的算法都可以被视为我们的退化形式。因此,REP-GAN是一个通用的GAN采样的算法框架。
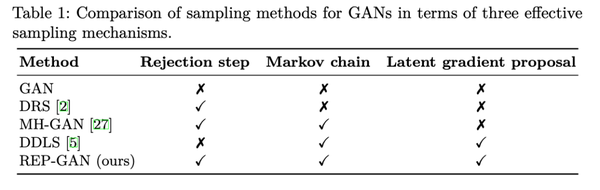
最后,我们的方法不仅适用于原始的GAN[1],在适当的近似下,也同样可以适用于WGAN[6],篇幅所限我们不作展开。
5
实验
我们在各种类型的模拟实验和真实数据上进行了实验。
1)流形(manifold)数据
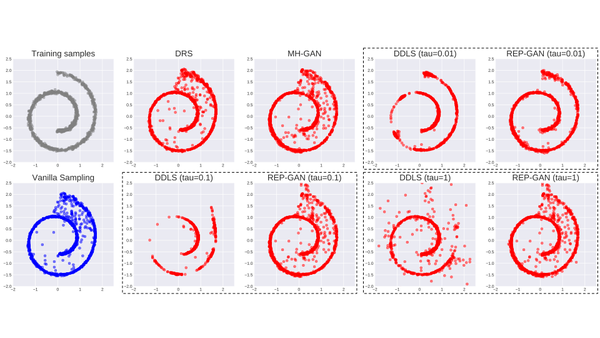
这里我们用了经典的二维瑞士卷(Swiss Roll)数据,其训练样本分布在下图(1,1)位置灰色点所示的瑞士卷形状的流形。而GAN所学到的判别器G生成的样本,见下图(2,1)位置蓝色点,有很多偏离流形的数据点。而右边的红色点则对应各种不同的GAN采样算法,我们发现他们都能利用判别器的信息,不同程度改善生成器的分布,使其更接近真实数据的分布。
其中,MH-GAN的作用非常有限,大部分噪声没有被移除;DDLS虽然噪声移除得很干净,但容易出现一些流形上断点的位置,这说明它容易坍塌到某些极值点上。而REP-GAN则很好地平衡了这两点,使得样本接近真实数据的样子。同时,当Langevin的步长增大时,REP-GAN也更鲁棒,而不会像DDLS一样出现崩塌的情况。这说明MH检验确实也起到了纠偏的作用。
2)多模式(multi-mode)数据
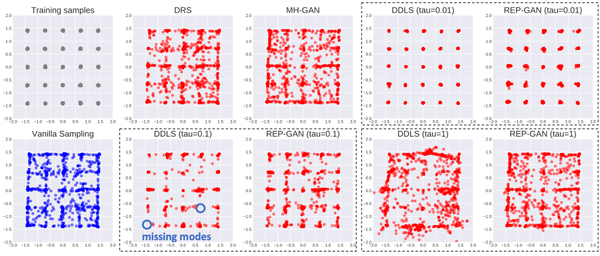
GAN容易做不好的另外一种数据,就是多模式数据。GAN由于其训练特点,容易出现模式崩塌(mode collapse)的问题。下图中,我们展示了一个二维空间中有5x5=25个模式的混合高斯分布。类似上面的分析,我们可以看到MH-GAN可以在移除噪声的同时,避免出现模式丢失(missing modes)的情况。
3)真实数据:CIFAR10与CelebA
我们跟随MH-GAN的实验设置,在两个真实数据集,CIFAR10和CelebA上,用两个不同的GAN模型,DCGAN与WGAN,对不同的采样算法进行了对比,使用Inception Score(IS)评估他们的样本质量(FID的结果类似,见附录)。
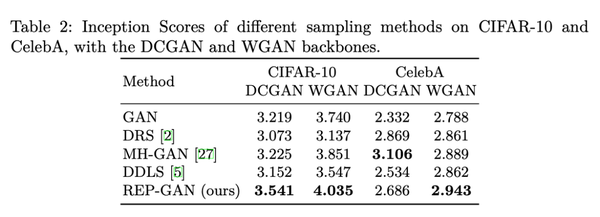
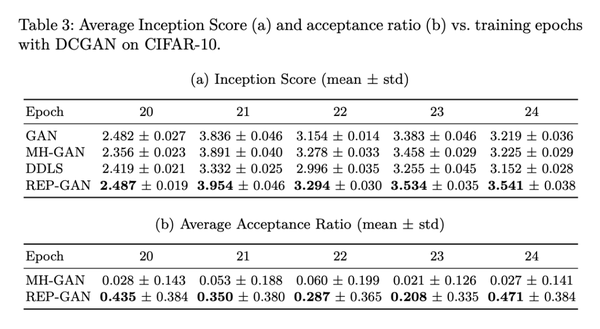
从上表我们可以看到,REP-GAN在大部分情况下,都取得了更好的样本质量。从下表的训练过程中的统计结果,我们也可以看到我们的平均接受率相比MH-GAN获得了很大提升,从5%左右提升到40%左右,大大提高了采样效率。
6
结语
综上,本文从重参数化采样的角度,提出了一个通用、高效的GAN采样框架,它利用GAN本身的结构信息,将一个复杂的问题(高维采样)转化为一个简单的问题(低维采样),把一个不可解的问题(一般的相关采样)转化为一个可解的问题(重参数化采样),同时实现了高效(相关采样)、准确(MH检验)的目标。它展示了重参数化技术的作用,并提示了从测度传输(measure transport)的角度来理解和利用神经网络的重要性。
本文的讨论仍然仅限于在GAN训练完成后,利用训练好的生成器和判别器进行采样的过程。事实上,未来我们的方法也可以用于训练过程中,可能会通过改善样本质量,起到改善训练稳定性的作用。欢迎大家与我们讨论交流。
最后,感谢梁家栋、崔胜宇在本文构思过程中的讨论。感谢ECML-PKDD组委会的认可和支持。
Contact:
yifei_wang AT pku DOT edu DOT cn
yisen.wang AT pku DOT edu DOT cn
参考文献
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. NeurIPS (2014)
[2] Turner, R., Hung, J., Saatci, Y., Yosinski, J.: Metropolis-Hastings generative adversarial networks. ICML (2019)
[3] Marzouk, Y., Moselhy, T., Parno, M., Spantini, A.: An introduction to sampling via measure transport. arXiv preprint arXiv:1602.05023 (2016)
[4] Titsias, M.K.: Learning model reparametrizations: implicit variational inference by fitting MCMC distributions. arXiv preprint arXiv:1708.01529 (2017)
[5] Hoffman, M., Sountsov, P., Dillon, J.V., Langmore, I., Tran, D., Vasudevan, S.: Neutralizing bad geometry in Hamiltonian Monte Carlo using neural transport. arXiv preprint arXiv:1903.03704 (2019)
[6] Arjovsky, M., Chintala, S., Bottou, L.: Wasserstein GAN. ICML (2017)
推荐文章
谷歌打怪升级之路:从EfficientNet到EfficientNetV2
不用1750亿!OpenAI CEO放话:GPT-4参数量不增反减
