解析一篇多人姿态估计反思论文: Simple Pose

Simple Pose: Rethinking and Improving a Bottom-up Approach for Multi-Person Pose Estimation,AAAI 2020
一个开源的简单快速版本的多人姿态估计论文,在COCO人体姿态估计数据集上取得0.64 AP, 35 FPS的速度-精度表现,方法缺点是使用了Hourglass网络预测热力图,GPU内存占用大。项目代码地址如下:
1. 首先看一下论文中提到的数据预处理(坐标点变换和ground truth heatmap生成)过程中的中心点对齐问题。
论文Section Definition of Heatmaps 中强调,将像素当作是位于一个1*1单元格(cell)的中心,这一观点遵从经典的图像缩放原则(比如opencv和PIL的resize函数),同时也是OpenPose生成关节点高斯热图时采用的。


像素块中心点对齐的计算方法
我们常常需要得出缩放前后某个像素位置和原始位置的精确坐标值,这时候就需要考虑几何中心点对齐,以下分析都是基于中心点对齐的缩放。缩放过程中,我们需要为目标图像dstImg上的每个像素位置找到与之对应的原图像srcImg的位置,并把srcImg上对应的像素值填入dstImg的该坐标位置处。若映射回原图srcImg的坐标位置不是整数,那么就需要做插值,算出映射回去的非整数坐标位置上的原图上的像素值是多少,因此就会有缩放过程中选择使用几阶插值算法了。
注意:图像坐标系从0开始,0,1,2,3… 像素分别位于每一个像素单元cell的中心。
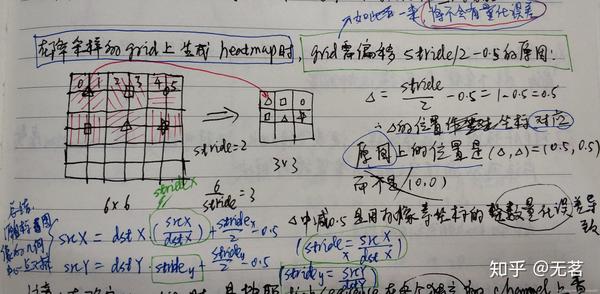

上面的公式可以这样理解,对于x坐标的映射关系为:srcX = dstX*(srcX/dstX) + [0+(stride-1)] / 2,其中[]内左侧0是srcImg上第一个像素方格的坐标,右侧(stride-1)是srcImg上的stride长度的右侧图像坐标,两者的均值就是中间点坐标(因为把像素pixel看成了有面积的cell,那么精确的位置应该在cell中心)。其中stridex=srcW/dstW。
为了加强理解,再来一个例子,这个例子是为了说明图像的放大或者缩小将会影响 [0+(stride-1)] / 2 的符号。
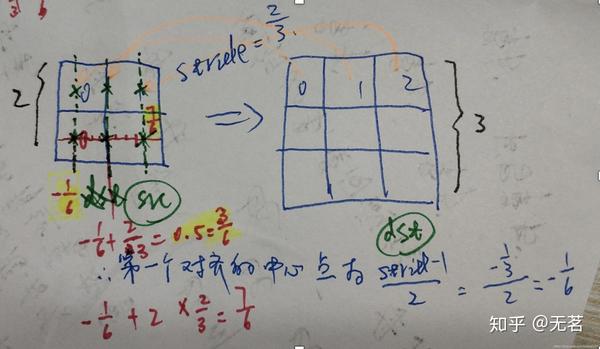
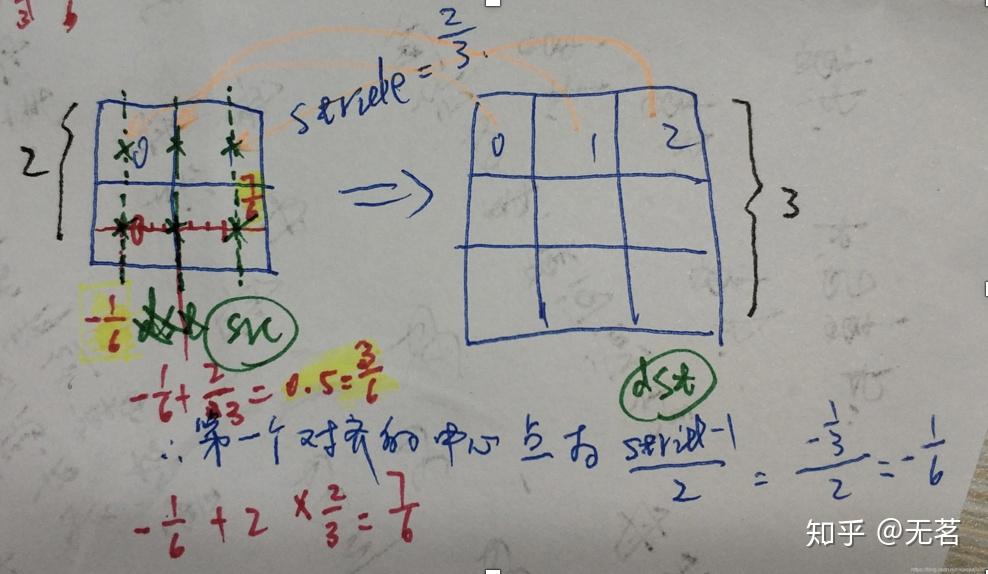
下图的例子是把原图放大了,即放大了3/2倍(即stride=2/3),我们来计算一下在dst中的第一个像素位置应该对应于原图src中的位置是(stride-1)/2=-1/6,映射到了原始图像src的第一个像素的左侧了。
为了加强理解,我们用一个真正的2-D图像缩放并采用双线性灰度插值的例子详细说明这个过程。
np_image = np.zeros((5, 5))
np_image[2, 2] = 1.0
image = PIL.Image.fromarray(np_image)
PILImg = torchvision.transforms.functional.resize(image, (10, 10)) #(等价于PIL中的resize)
opencvImg = cv2.resize(np_image, (10, 10)) # 和PIL中的resize相同
我们查看一下np_image矩阵如下:


然后查看一下PILImg或opencvImg如下:


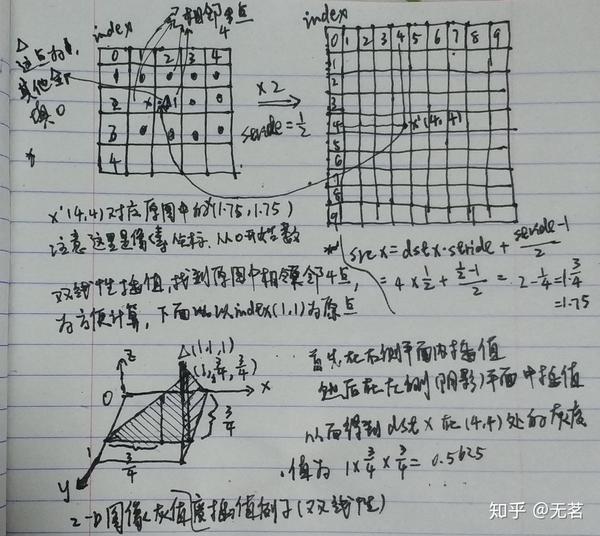
以上面(4,4)位置灰度值为例,我们来看这个灰度值是如何计算得到的,见下图:
我们先把变换后的图像中待求位置映射回原图中的位置(1.75, 1.75),然后沿着平行于zoy平面上插值一次,接着再在另一个平行于xoz平面上插值一次,就得到了双线性插值的结果为1*0.75*0.75=0.5625。
注意:图像坐标系从0开始,0,1,2,3… 像素分别位于每一个像素单元cell的中心。

到了这里,就不难理解项目中生成keypoint Gaussian heatmap和body part Gaussian heatmap的这段代码:
# x, y coordinates of centers of bigger grid, stride / 2 -0.5是为了在计算响应图时,使用grid的中心
self.grid_x = np.arange(width) * stride + stride / 2 - 0.5 # x -> width
self.grid_y = np.arange(height) * stride + stride / 2 - 0.5 # y -> height
# x ,y indexes (type: int) of heatmap feature maps
self.Y, self.X = np.mgrid[0:self.config.height:stride, 0:self.config.width:stride]
# 对<numpy.lib.index_tricks.MGridClass object> slice操作,比如L[:10:2]前10个数,每隔两个取一个
# # basically we should use center of grid, but in this place classic implementation uses left-top point.
self.X = self.X + stride / 2 - 0.5
self.Y = self.Y + stride / 2 - 0.5如此一来,我们其实是让网络直接预测输入图像空间下的gaussian peak的采样,并且在预测阶段插值回原始输入分辨率。生成的ground truth heatmap例子:


2. 使用多尺度监督引导网络生成热度图(论文中将此视为空间注意力机制)
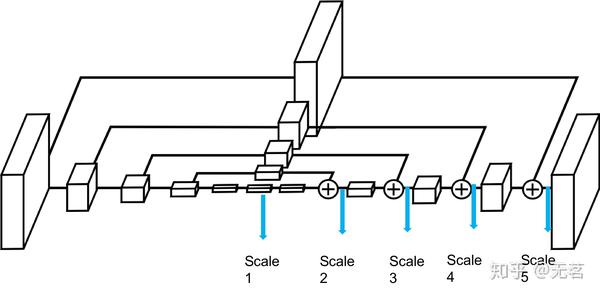

当然多尺度监督技术不是这篇论文的首创,但是具体使用方法上与先前的工作不同。生成Hourglass Network整个结构中所有分辨率的ground truth heatmap,作者认为这样会辅助引导生成高质量高分辨率的热图,并且增加网络对人体姿态的尺度变化的鲁棒性(尤其是使用输入图像金字塔放大时,网络内部其实在低分辨率下做了多次前向推理,获得了粗略的位置信息编码热图)。
要求在低分辨率下生成精确热度图是比较苛刻的,先前的工作都是重新生成在其他分辨率下的精确热图,这其实就是特征金字塔的方式。而本文选择生成平均池化后的热度图放置到网络输出的不同分辨率特征空间下做直接监督,以此把它们当作是空间上的注意力机制。试验发现这种操作将减少网络多尺度监督学习的难度,在低分辨率特征空间下只预测关键点响应的大致区域,比如4*4大小的输出特征空间中仅仅有1个cell会有高响应值。本文使用自适应平均池化后的“热度图”作为关键点定位信息的引导,是一种显式且粗糙的引导。原始的Hourglass Network仅仅做了多尺度的特征融合。论文中显示加入这种引导机制后,带来了1+%AP的精度提升。
论文中multi-scale ground truth heatmap的生成描述如下:


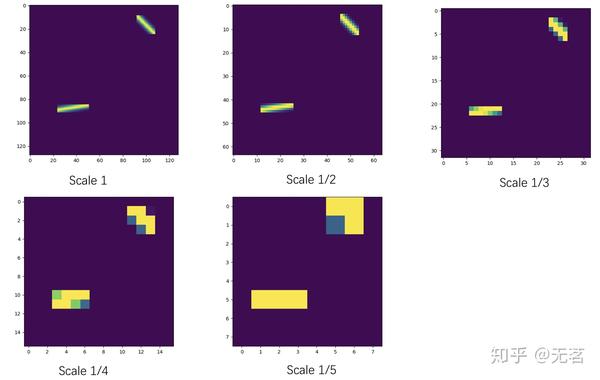

和Rethinking章节中提到的生成heat map时的不平衡问题类似,我们也应该对所引入的不同分辨率特征的监督损失做好平衡,否则容易出现训练失败(主要是梯度爆炸或者某个分辨率下学习不良)的情况。本文对不同尺度下的损失进行加权的依据是根据输出特征图的面积进行数值上的超参数调节。论文中所有使用多尺度监督的实验结果都用如下的参数配置:


3. Focal L2 loss: 用于keypoint和body part heatmap监督的损失函数,从而更好地学习关键点以及关键点的配对信息
提出的动机是用来监督学习两种高斯热图(regression task),并且结合文章提出的关键点和人体部件高斯热图的相似外观,巧妙便捷地解决类内(难样本挖掘)和类间(正负样本平衡)的不平衡问题。CNN本质上其实是模版匹配,不管是预测body part area还是keypoint area,它们都有比较符合视觉感官的表征。回归gaussian peak比直接回归两个相邻关键点之间的offset更加容易;另外,热图编码本身就包含了定位信息,这样我们就避免了多任务学习(classification 和offet regression)之间的平衡麻烦。
这个损失函数非常显著地提高了多人姿态估计的精度,在COCO test-dev dataset上带来3% AP的提升!这从侧面说明我们要关注文章提出的不平衡问题,并且同时对关键点和关键点之间的连接信息做好挖掘学习。值得注意的是,这个损失函数实现起来非常简单:
def focal_loss(s,sxing,thre=0.01):
s = torch.tensor(s,requires_grad=True)
sxing = torch.tensor(sxing)
gamma = 1.0 # 2.0 # 经验上使用gamma=1从头训练更稳定
st = torch.where(torch.ge(sxing, thre), s, 1 - s)
factor = torch.pow(1. - st, gamma)
print('the factor is \n', factor)
out = torch.mul((s-sxing), (s-sxing)) * factor
out.backward()
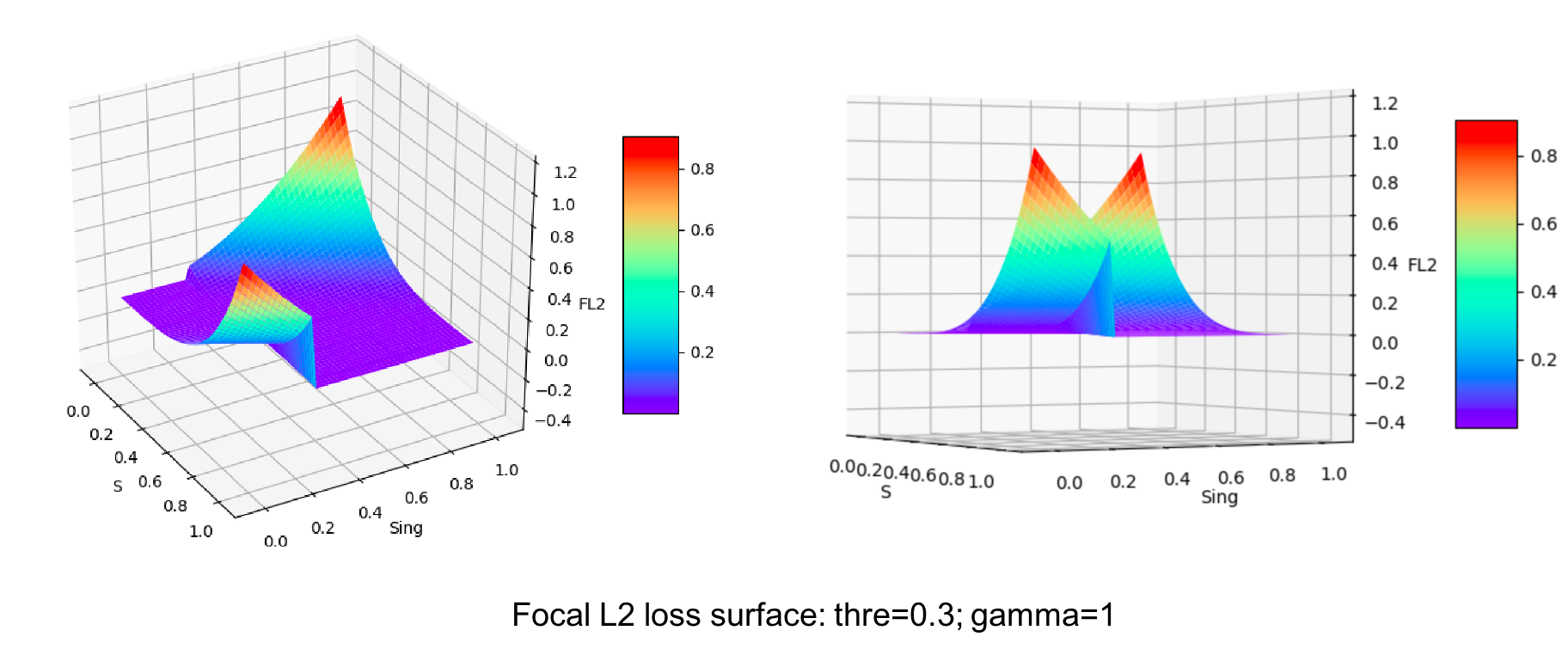
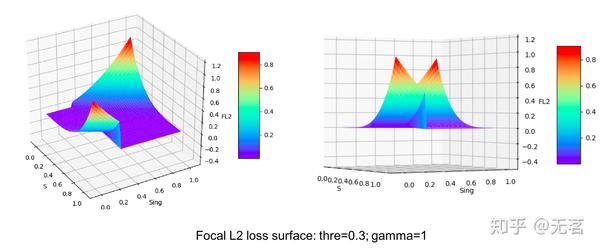
print(s.grad)为了直观地了解本文提出的Focal L2 loss的作用,我们作出曲面图,通过观察发现其实Focal L2 loss就是前景损失曲面和背景损失曲面的拼接,拼接位置threshold是一个超参数,用于平衡前景(有高斯响应的区域)/背景。当前景或者背景很容易预测的时候,Focal term就会把这些像素样本的损失拉得很低,从而平衡了难样本/容易样本。值得注意的是,thre其实反应了网络学习得到的能区分前景和背景的一种“能力”。

当然,为了加快计算速度,最好对网络生成的所有热度图进行concatnate,然后使用矢量化的代码实现,损失函数位于:
https://github.com/hellojialee/Improved-Body-Parts/blob/master/models/loss_model.py
4. 人体关键点分组后处理算法细节
基于OpenPose的改编,具体细节请参考代码,这里把人体关键点分组规则总结如下




