
Multi-modal Knowledge Graphs for Recommender Systems - 1 - 论文学习
Multi-modal Knowledge Graphs for Recommender Systems
ABSTRACT
在各种在线应用中,推荐系统在解决信息爆炸问题和增强用户体验方面显示出了巨大的潜力。为了解决推荐系统中的数据稀疏和冷启动问题,研究人员提出了基于知识图谱(KGs)的推荐,利用有价值的外部知识作为辅助信息。然而,这些工作大多忽略了多模态知识图谱(MMKGs)中数据类型的多样性(例如文本和图像)。在本文中,我们提出了多模态知识图谱注意网络(MKGAT)来利用多模态知识更好地增强推荐系统。具体地说,我们提出了一种多模态图注意技术来在MMKGs上进行信息传播,然后使用生成的聚合嵌入表示进行推荐。据我们所知,这是第一个将多模态知识图谱集成到推荐系统中的工作。我们在两个不同领域的真实数据集上进行了大量的实验,实验结果表明我们的MKGAT模型能够成功地利用MMKGs来提高推荐系统的质量。
1 INTRODUCTION
近年来,知识图谱(knowledge graph, KGs)由于其综合的辅助数据而被广泛应用于推荐系统(即基于KGs的推荐)中[24,28]。具体来说,基于KG的推荐通过引入高质量的侧面信息(KGs),缓解了user-item交互的稀疏性问题和冷启动问题。这些问题在基于协同过滤(CF)[11]的方法中经常出现。
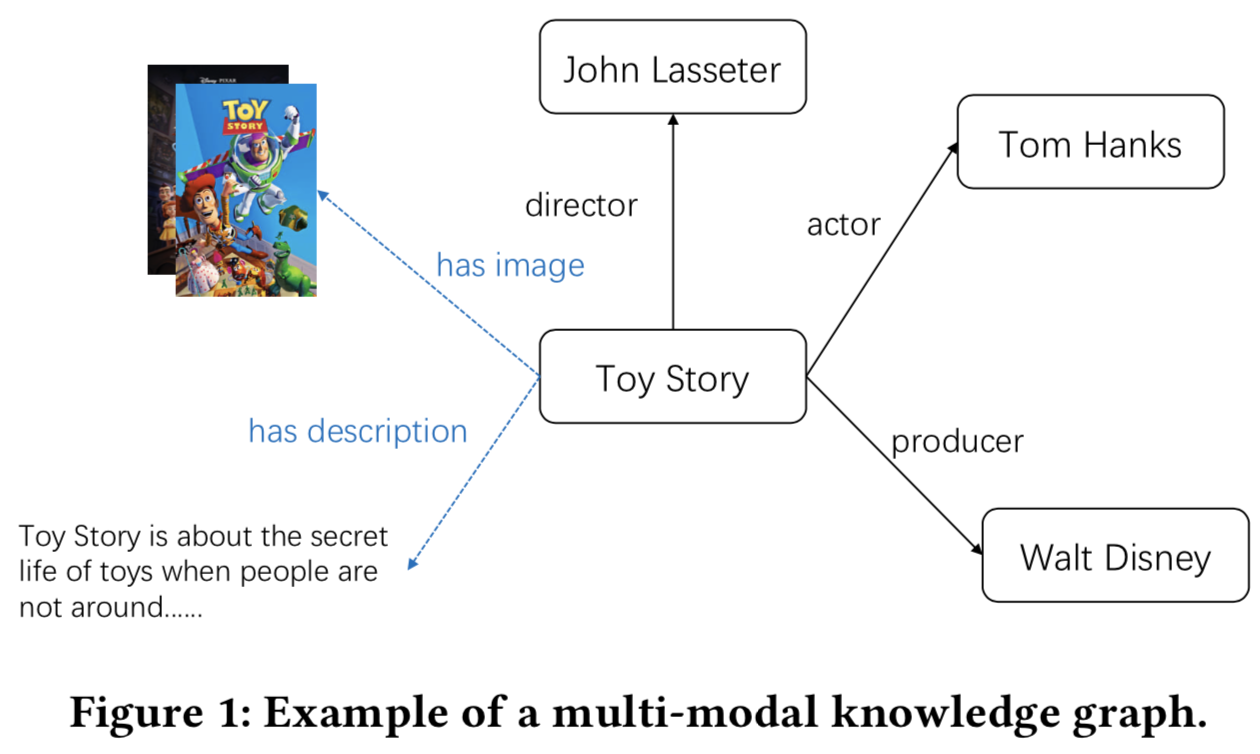
然而,现有的基于KG的推荐方法在很大程度上忽略了items的图像和文本描述等多模态信息。这些视觉或文本特征可能在推荐系统中发挥重要作用。例如,在看电影之前,用户往往会先看预告片或阅读相关影评。当去一家餐厅吃饭时,用户通常会先浏览一些在线平台上的菜肴图片或餐厅的评论,如Yelp或Dianping。因此,有必要将这些多模态信息引入知识图谱中。其好处是,多模态知识图谱(MKGs)将视觉或文本信息引入知识图谱,将图像或文本视为一个实体或实体的一个属性。它是获取外部多模态知识的一种更普遍的方式,无需给出视觉或文本信息的专家定义。图1显示了一个简单的MKGs示例。
知识图谱表示学习是基于KG推荐的关键。基于KG的推荐模型通常使用知识图谱表示模型来学习KGs实体的嵌入,然后将其反馈到下游的推荐任务中。多模态知识图谱表示学习有两种类型:基于特征的方法和基于实体的方法。
基于特征的方法[17,30]将模态信息作为实体的辅助特征。通过考虑从与知识图实体相对应的图像中提取的视觉表示,它扩展了平移模型(TransE)[2]。三元组的能量(例如,TransE中三元组的分数函数)是根据KGs的结构以及实体的视觉表示来定义的。然而,基于特征的方法对知识图谱的数据源提出了相对的要求,因为它要求知识图中的每个实体都具有多模态信息。
针对KGs数据源的严格要求,提出了基于实体的方法[19]。基于实体的方法将不同类型的信息(如文本和图像)视为结构化知识的关系三元组,而不是辅助特征,即知识图谱的一级公民。它通过考虑新的关系来引入视觉信息和文本信息,如h𝑎𝑠𝐼𝑚𝑎𝑔𝑒(表示实体是否有图像信息)和h𝑎𝑠𝐷𝑒𝑠𝑐𝑟𝑖𝑝𝑡𝑖𝑜𝑛(表示实体是否有描述它的文本信息)。然后,基于实体的方法通过独立应用平移模型[2]或基于卷积神经网络(CNN)的模型[18]来学习知识图谱的嵌入,对每个三元组(h,𝑟,𝑡)进行处理,其中h和𝑡分别表示头和尾实体,𝑟为h和𝑡之间的关系(如:h𝑎𝑠𝐼𝑚𝑎𝑔𝑒和h𝑎𝑠𝐷𝑒𝑠𝑐𝑟𝑖𝑝𝑡𝑖𝑜𝑛)。
基于实体的方法虽然解决了基于特征的方法对MKGs数据源要求高的问题,但其只关注实体之间的推理关系,忽略了多模态信息融合。事实上,多模态信息通常作为辅助信息来丰富其他实体的信息。因此,在建模实体之间的推理关系之前,我们需要一种直接的交互方式,将多模态信息显式地融合到对应的实体中。
考虑到现有解决方案的局限性,我们认为有必要开发一个能够有效利用MKGs的MKGs表示模型。具体来说,模型应满足两个条件:1)对MKGs数据源要求低;2)在保持实体间推理关系的同时考虑多模态信息融合。为此,我们采用基于实体的方法来构造多模态知识图谱。然后,我们提出了多模态知识图谱注意网络(multimodal Knowledge Graph Attention Network, MKGAT),它从两个方面对多模态知识图谱建模:1)实体信息聚合,聚合实体的邻居节点信息,丰富实体本身;2)实体关系推理,利用三元组的分数函数(如TransE)构建推理关系。首先提出了一种改进图注意神经网络(GATs)的新方法,该方法在考虑知识图谱关系的同时对相邻实体进行聚合,完成实体信息聚合。然后用平移模型对实体之间的推理关系进行建模。MKGAT模型的一个明显优势在于它不要求知识图谱中的每个实体都有多模态信息,这意味着它对知识图谱数据没有特别高的要求。此外,MKGAT模型并不是对每个知识图谱三元组都单独进行处理,而是对实体的相邻信息进行聚合。这样可以更好地学习能融合其他模态信息的实体嵌入。本工作的主要贡献如下:
据我们所知,这是第一次在推荐系统中引入多模态知识图谱。
- 我们开发了一个新的MKGAT模型,该模型利用多模态知识图谱上的信息传播来获得更好的实体嵌入来进行推荐。
- 在两个大规模的真实数据集上进行的大量实验证明了我们的模型的合理性和有效性。
本文的其余部分组织如下。第二节概述有关工作。第3节介绍了初步概念。然后我们在第4节给出了MKGAT模型,在第5节给出了实验结果。第六部分对本文进行总结。
2 RELATED WORK
在本节中,我们介绍了与我们研究相关的现有工作,包括多模态知识图谱和基于kg的推荐。
2.1 Multi-modal Knowledge Graphs
多模态知识图谱通过在传统知识图谱中引入其他模态信息丰富了知识的类型,实体图像或实体描述可以为知识表示学习提供重要的视觉或文本信息。大多数传统方法仅从结构化三元组学习知识表示,忽略了知识库中经常使用的各种数据类型(如文本和图像)。近年来,人们对多模态知识图谱表示学习进行了研究。这些工作证明了多模态知识图谱在知识图谱补全和triplet分类中发挥着重要作用[5,17,30]。从知识图构造的角度来看,多模态知识图表示学习工作可分为两类:基于特征的方法和基于实体的方法。
Features-based methods. [17,30]将多模态信息作为实体的辅助特征。这些方法通过考虑视觉表示来扩展TransE[2]。可以从与知识图谱实体相关联的图像中提取视觉表示。在这些方法中,三元组的能量(如TransE中的三元组分数函数)是根据知识图谱的结构和实体的视觉表示来定义的,这意味着每个实体必须包含图像属性。然而,在实际场景中,有些实体并不包含多模态信息。因此,该方法不能广泛应用。
Entity-based methods. [19]将不同的模态信息(如文本和图像)作为结构化知识的关系三元组,而不是预先确定的特征。在这些著作中,多模态信息被认为是知识图谱的一等公民。然后采用基于实体的方法,利用基于CNN的KGE方法训练知识图谱的嵌入。然而,现有的基于实体的方法对每个三元组独立处理,忽略了多模态信息融合,对多模态元组不友好。
由于多模态知识图谱的引入是近年来才出现的,在这一方向上的研究工作还很有限。
2.2 KG-based Recommendation
目前,一些研究尝试利用KGs结构进行推荐,可分为embedding-based方法、path-based方法和两者一起(unified)方法三种类型。
Embedding-based methods. 基于嵌入的方法[23,25,27]首先使用知识图谱嵌入(KGE,Knowledge Graph Embedding)[27]算法对知识图谱进行预处理,然后在推荐框架中使用学习到的实体嵌入,将CF框架中的各类side信息统一起来。基于嵌入的协同知识(CKE,Collaborative Knowledge base Embedding)[35]将协同过滤(CF)模块与知识嵌入、文本嵌入和项目图像嵌入结合在一个统一的贝叶斯框架中。深度知识网络(DKN)[25]将实体嵌入和文本嵌入作为不同的通道,然后使用卷积神经网络(CNN)框架将它们结合在一起进行新闻推荐。
基于嵌入的方法在利用知识图谱辅助推荐系统方面表现出了很高的灵活性,但这些方法中采用的KGE算法(平移模型或基于CNN的模型)不适用于多模态元组(原因与MKGs中基于实体的方法相同)。换句话说,这些方法对多模态知识图谱不友好。
Path-based methods. 基于路径的方法[33,36]探索知识图谱中项目之间的各种连接模式,为推荐提供额外的指导。例如,将知识图谱视为异构信息网络(HIN,Heterogeneous Information Network),个性化实体推荐(PER,Personalized Entity Recommendation)[33]和基于meta-graph的推荐[36]提取了基于meta-path/meta-graph的潜在特征,表示用户与项目之间沿着不同类型的关系路径/图的连通性。
基于路径的方法以一种更自然、更直观的方式利用知识图谱,但它们严重依赖于手工设计的meta-paths,在实践中很难进行优化。另一个问题是,在实体和关系不属于某个领域的特定场景中,设计手工制作的meta-paths是很难的。
Unified methods. Embedding-based方法利用KGs中实体的语义表征来推荐, 而基于路径的方法使用在KGs实体中连接的模式。两者都只使用了KGs中信息的一个方面。为了充分利用KGs的信息来进行更好的推荐,提出了统一的方法,将实体和关系的语义表示以及连接信息的模式集成在一起。然而,统一的方法也依赖于知识图谱嵌入技术。平移(Translational)模型被广泛用于训练知识图谱嵌入。代表作品有注意增强的知识感知用户偏好模型(AKUPM,attention-enhanced knowledge-aware user preference model)[12]和知识图谱注意网络(KGAT,knowledge graph attention network)[28]。它们独立地处理每个三元组,而不考虑多模态信息融合。与基于嵌入的方法类似,统一方法对多模态知识图谱不友好。
3 PROBLEM FORMULATION
在本节中,我们介绍了一组初步的概念,然后用公式表示基于多模态知识图谱的推荐任务。
定义1(知识图谱)。为了提高推荐性能,我们考虑了知识图谱中项目边(side)信息。通常,这些辅助数据由真实世界的实体和它们之间的关系组成,用来分析一个项目。
知识图谱(KG) 𝐺=(𝑉,𝐸)为有向图,其中𝑉 为节点集,𝐸 为边集。节点是实体,边是主体-属性-对象(subject-property-object triple facts)三重事实。每条边都属于一个关系类型𝑟∈R,其中R是一组关系类型。(head entity, relation, tail entity)形式的每条边(记为(h,𝑟,𝑡),其中h,𝑡∈𝑉,𝑟∈R)表示𝑟从head entity h到tail entity 𝑡的关系。
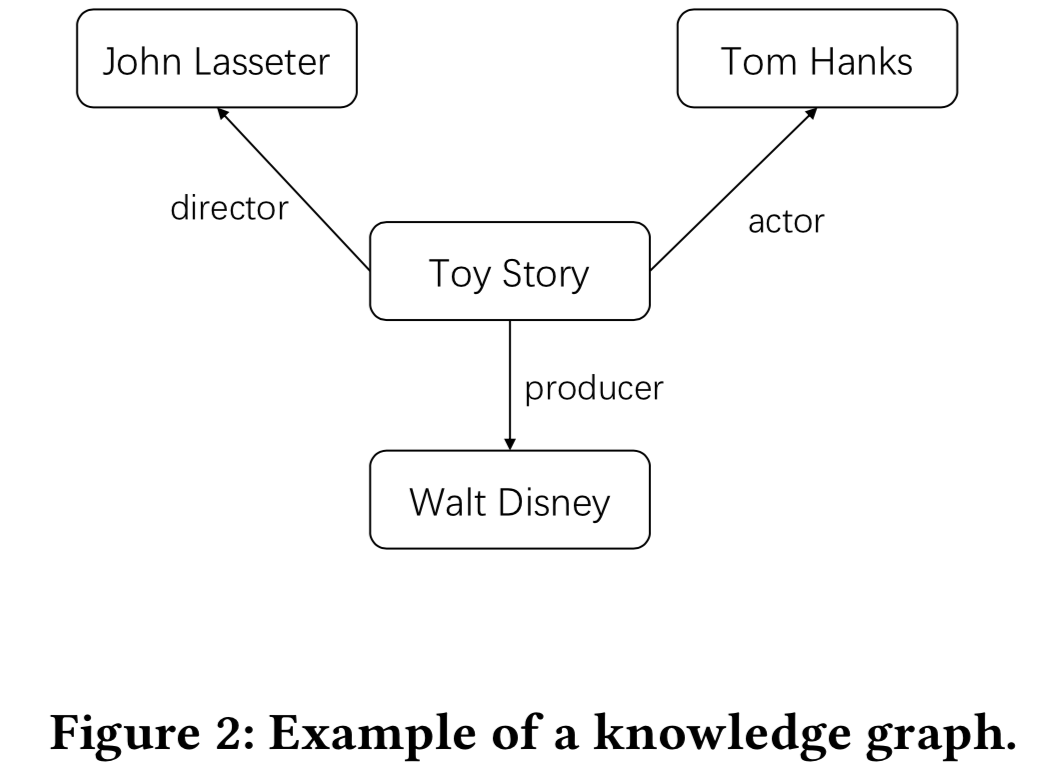
图2展示了一个知识图谱的例子,在这个例子中,由导演、演员和制作人描述了一部电影(称为《玩具总动员》)。我们可以用(Toy Story, DirectorOf, John Lasseter) 来说明《玩具总动员》是由约翰·拉塞特执导的。
定义2(多模态知识图谱)。多模态知识图(multimodal Knowledge Graphs, MKGs)是一类知识图谱,它额外引入了多模态实体(如文本和图像)作为知识图谱的一级公民。
以图1为例,它展示了一个多模态的知识图谱,我们使用 (Toy Story, hasImage, a picture of film promotion) 来表示电影实体(即Toy Story)有一个图像实体,这个图像实体描述了这个电影实体的一些视觉信息。
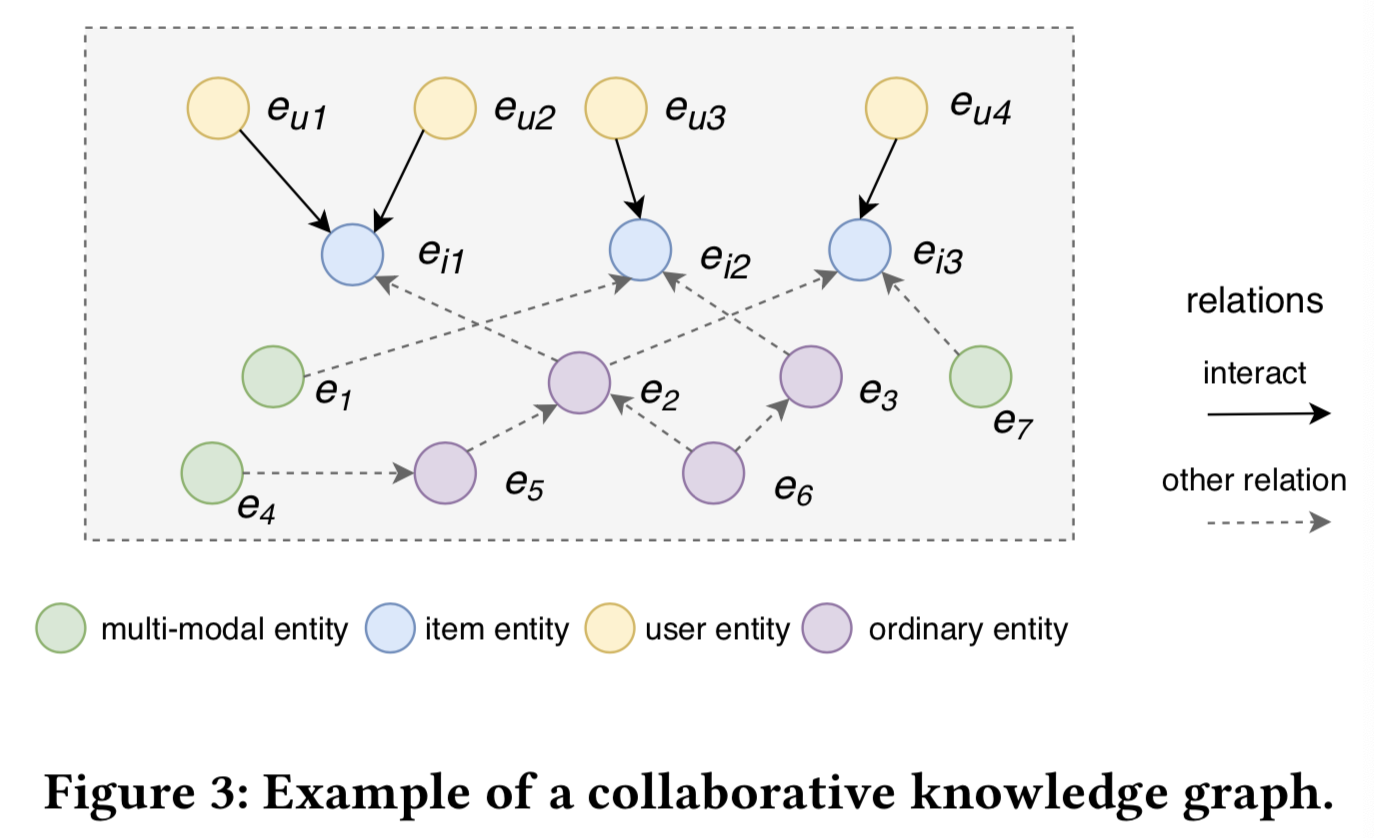
定义3(协同知识图谱,Collaborative Knowledge Graph)。协同知识图谱(CKG)将用户行为和项目知识编码为一个统一的关系图。CKG首先定义一个user-item 二分图(bipartite graph),公式表示为![]() , eu是一个用户实体,yui表示用户u和项目i之间的联系, ei表示一个项目实体,
, eu是一个用户实体,yui表示用户u和项目i之间的联系, ei表示一个项目实体,![]() 和
和![]() 分别表示用户和项目集。当eu与ei相互作用时,yui= 1;否则,yui= 0。然后,CKG将user-item二分图整合到知识图谱中,其中每个用户的行为表示为一个三元组(eu,Interact,ei)。𝐼𝑛𝑡𝑒𝑟𝑎𝑐𝑡= 1表示eu与ei之间存在额外的交互关系。基于item-entity对齐集,可以将user-item 图与知识图谱无缝集成为统一的图。如图3所示,ei1、ei2和ei3同时出现在知识图谱和user-item二分图中,CKG的对齐依赖于它们。
分别表示用户和项目集。当eu与ei相互作用时,yui= 1;否则,yui= 0。然后,CKG将user-item二分图整合到知识图谱中,其中每个用户的行为表示为一个三元组(eu,Interact,ei)。𝐼𝑛𝑡𝑒𝑟𝑎𝑐𝑡= 1表示eu与ei之间存在额外的交互关系。基于item-entity对齐集,可以将user-item 图与知识图谱无缝集成为统一的图。如图3所示,ei1、ei2和ei3同时出现在知识图谱和user-item二分图中,CKG的对齐依赖于它们。
Task description. 我们现在制定了基于多模式 KGs的推荐任务,将在本文中解决:
- Input 协作知识图谱,包括user-item二分图和多模态知识图谱。
- Output 一个预测函数,用于预测用户采用某个物品的概率。
4 METHOD
在本节中,我们将介绍本文提出的MKGAT模型。MKGAT模型的框架概述如图5所示,由两个主要子模块组成:多模态知识图嵌入模块和推荐模块。
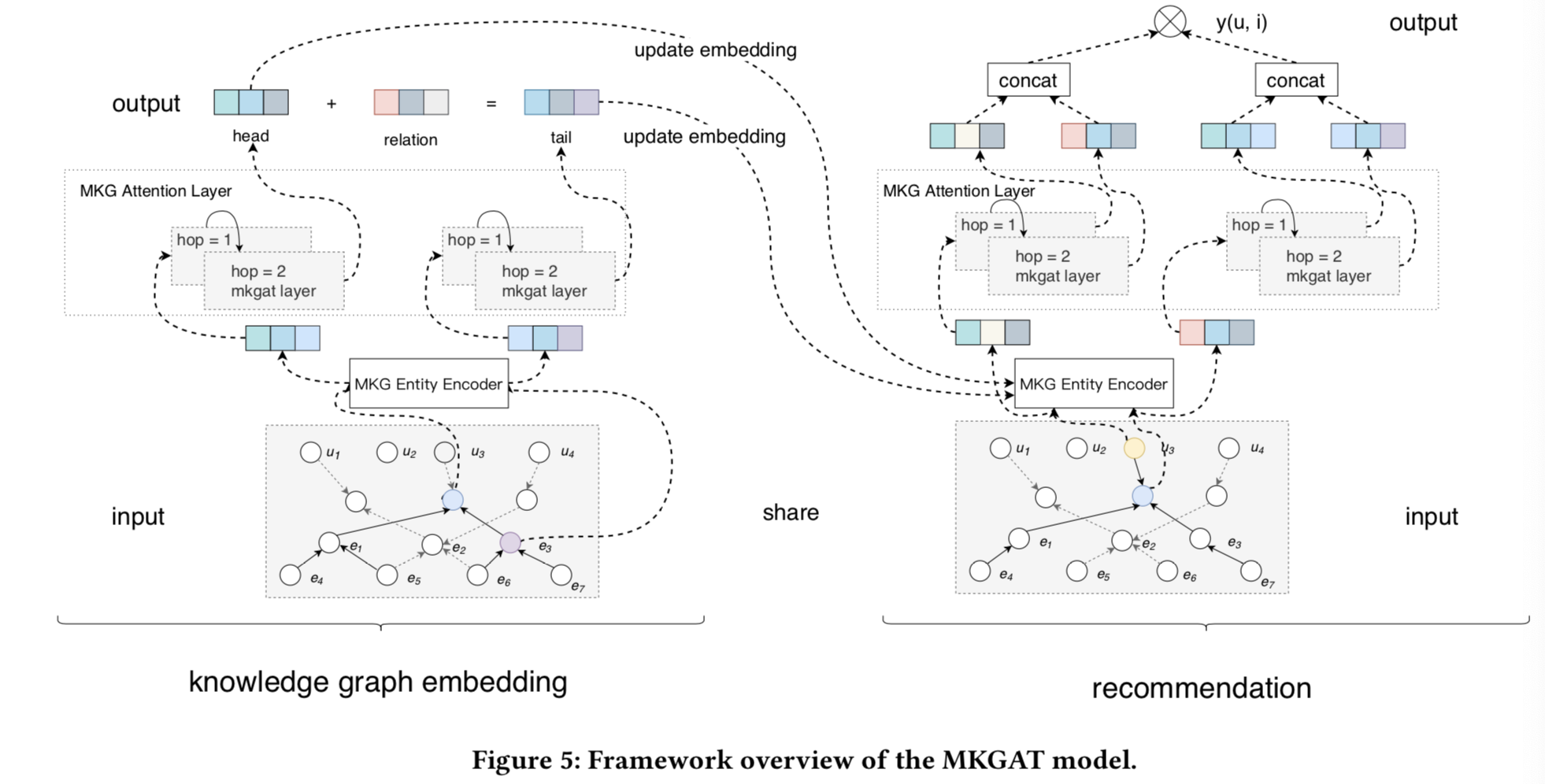
在讨论子模块之前,我们首先介绍了两个关键组件:多模态知识图谱实体编码器(multi-modal knowledge graph entity encoder)和多模态知识图谱注意层(multi-modal knowledge graph attention layer),它们是KG嵌入模块和推荐模块的基本构建块。
•多模态知识图谱实体编码器,使用不同的编码器嵌入每种特定的数据类型。
•多模态知识图谱注意层,将每个实体的邻居实体信息聚合到每个实体本身,学习新的实体嵌入。
现在我们介绍MKGAT中的两个子模块。
Multi-modal Knowledge Graph Embedding Module 知识图谱嵌入模块以协同知识图谱为输入,利用多模态知识图(Multi-modal knowledge graph, MKGs)实体编码器和MKGs注意层学习每个实体的新的实体表示。新的实体表示聚合了邻居的信息,同时保留了自己的信息。然后利用新的实体表示来学习知识图谱的嵌入,以表示知识推理关系。
Recommendation Module 推荐模块以实体的知识图谱嵌入(由知识图嵌入模块获取)和协同知识图谱作为输入,并利用MKGs实体编码器和MKGs注意层利用相应的邻居来丰富用户和项目的表示。最后,按照传统的推荐模型生成用户与商品之间的匹配分数。
下面我们将详细介绍知识图谱嵌入模块和推荐模块。
4.1 Multi-modal Knowledge Graph Embedding
在本节中,我们首先介绍了MKGs实体编码器和MKGs注意层,然后介绍了知识图谱嵌入的训练过程。
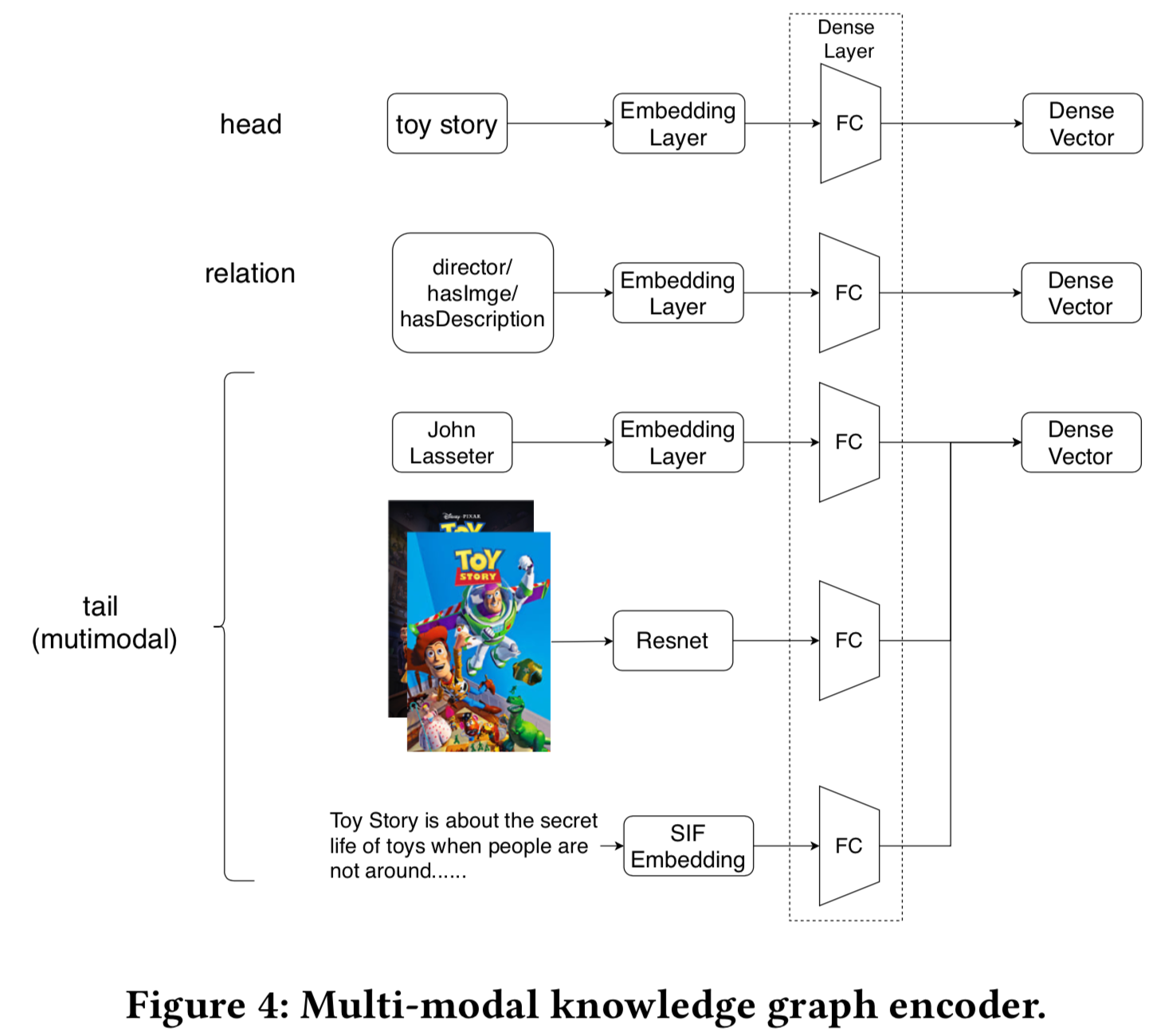
4.1.1 Multi-modal Knowledge Graph Entity Encoder. 为了将多模态实体合并到模型中,我们建议也学习不同模态数据的嵌入。我们利用深度学习的最新进展为这些实体构建编码器来表示它们,本质上为所有实体提供一个嵌入。这里我们描述用于多模态数据的编码器。如图4所示,我们使用不同的编码器嵌入每种特定的数据类型。
Structured knowledge. 考虑以(h,𝑟,𝑡)形式存在的三元组信息。为了将head entity h, tail entity 𝑡 和relation 𝑟表示为独立的嵌入向量,我们通过嵌入层传递它们的实体𝑖𝑑或关系𝑖𝑑来生成密集向量
Image. 人们已经开发了多种模型来简洁地表示图像中的语义信息,并成功地应用于图像分类[8]和问答[32]等任务。为了嵌入图像,使编码能够表示这些语义信息,我们使用了ResNet50[6]的最后一层隐藏层,该模型由Imagenet[3]预训练得到。
Texts. 这些文本信息与内容高度相关,可以捕捉用户的偏好。对于文本实体,我们使用Word2Vec[16]训练词向量,然后应用SIF (Smooth Inverse Frequency, SIF)模型[1]得到一个句子的词向量的加权平均,作为句子向量来表示文本特征。为了提高模型的效率,我们采用句子向量技术代替LSTM对句子进行编码。SIF将比简单地使用单词向量的平均值具有更好的性能。
最后,如图4所示,我们使用密集层将实体的所有模态统一到同一个维度中,这样我们就可以在我们的模型中训练它。
4.1.2 Multi-modal Knowledge Graph Attention Layer. MKGs注意层如图6所示,它沿着高阶连接性[10]递归地传播嵌入。此外,我们利用图注意网络(GATs)[22]的思想,生成级联传播的注意权值,以揭示这种连通性的重要性。GATs虽然取得了成功,但由于忽略了KGs之间的关系,不适用于KGs,因此我们对GATs进行了修改,考虑了KGs关系的嵌入。
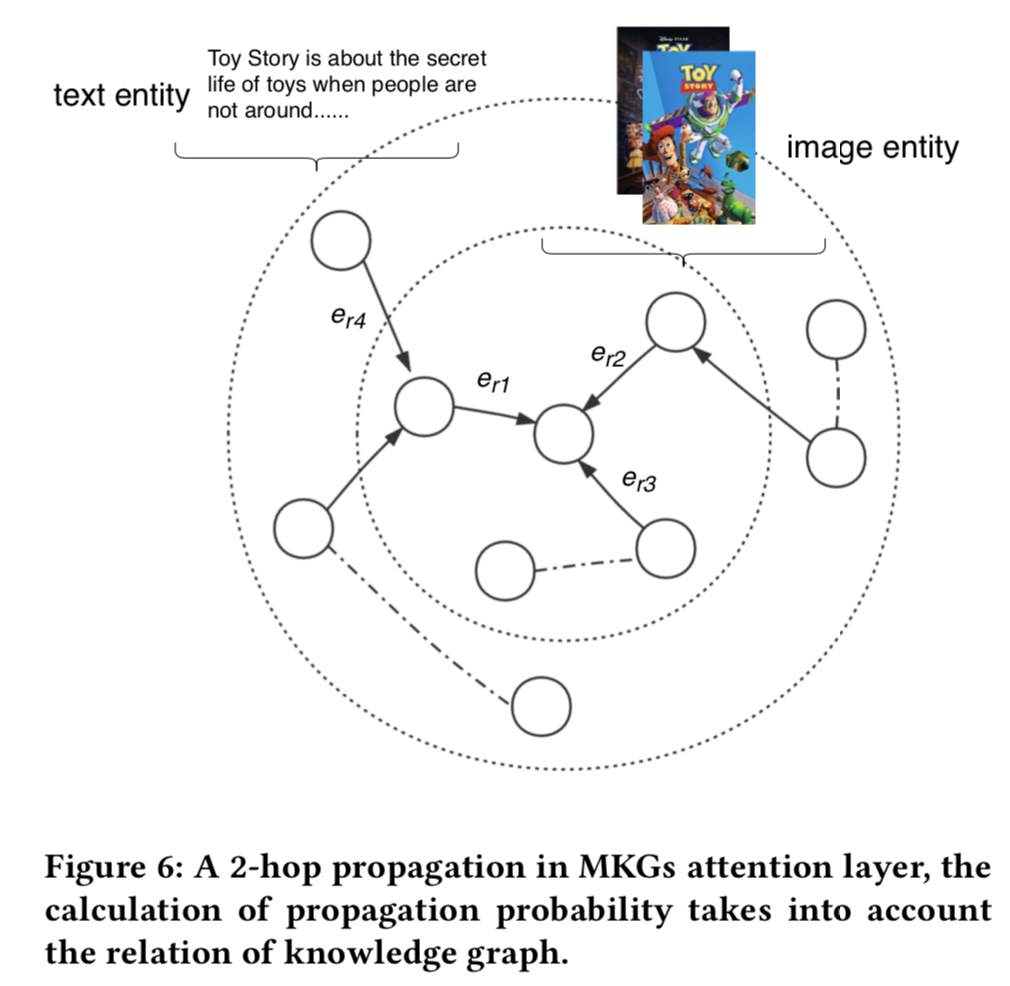
而注意机制[21]的引入可以减少噪声的影响,使模型关注有用信息。
在这里,我们首先描述一个单层,它由两个组件组成:传播(propagation)层和聚合(aggregation)层,然后讨论如何将其泛化为多个层。多模态知识图谱注意层不仅可用于知识图谱的嵌入,还可用于推荐。
Propagation layer(传播层). 给定一个候选实体h,在学习其知识图嵌入时必须考虑两个方面。首先,我们通过transE模型学习知识图谱的结构化表示,即h + r ≈ t。其次,对于实体h的多模态邻接实体,我们希望将这些信息聚合到实体h,以丰富实体h的表示。我们用![]() 表示与h直接相连的三元组集合。e𝑎𝑔𝑔是一个聚合邻居实体信息的表示向量,它是每个三元组表示的线性组合,可在公式1中计算。
表示与h直接相连的三元组集合。e𝑎𝑔𝑔是一个聚合邻居实体信息的表示向量,它是每个三元组表示的线性组合,可在公式1中计算。
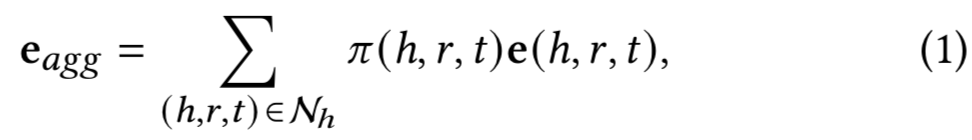
其中e(h,r,t)是每个三元组的嵌入,而𝜋(h,𝑟,𝑡)是每个三元组e(h,r,t)的注意力分数,𝜋(h,𝑟,𝑡)控制传播的三元组e(h,r,t)的信息量
由于关系在知识图谱中很重要,我们保留e(h,𝑟,𝑡)和𝜋(h,𝑟,𝑡)中的关系嵌入,其中的参数是可学习的。对于三元组e(h,𝑟,𝑡),我们通过对head entity, tail entity 和 relation的嵌入串联进行线性变换来学习这种嵌入,表达式为:
![]()
其中eh和et是实体的嵌入,er是关系的嵌入。我们通过关系注意机制实现𝜋(h,𝑟,𝑡),计算如下:
![]()
其中,我们按照[22]中的方法选择LeakyReLU[15]作为非线性激活函数。接下来,我们采用softmax函数对与h相连的所有三元组的系数进行归一化:
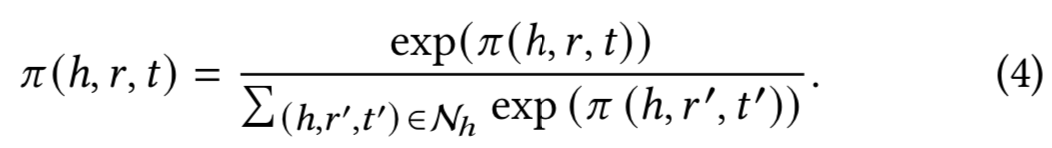
Aggregation layer(聚合层). 为了不丢失初始eh信息,这一阶段是将实体表示eh和对应的e𝑎𝑔𝑔聚合为实体h的新表示。在本工作中,我们通过以下两种方法实现聚合函数𝑓(eh, e𝑎𝑔𝑔)。
1)ADD聚合方法考虑了eh和e𝑎𝑔𝑔之间的基于元素的add特征交互,由等式5可得:
![]()
其中我们在初始的eh上进行线性转换,然后和eagg相加。W3是一个权重矩阵,用来将当前表示转移到一个常见空间,是一个可训练的模型参数。该操作和残差网络[6]相似。
2)Concatenation聚合方法使用线性转换将eh和eagg连接在一起:
![]()
其中||表示串联操作,W4是可训练的模型参数。
High-order propagation. 通过叠加更多的传播和聚合层,我们探索了协同知识图谱中固有的高阶连通性。通常,对于𝑛-layer模型,传入的信息是在𝑛-hop附近积累的。
4.1.3 Knowledge Graph Embedding. 在通过MKGs实体编码器和MKGs注意层之后,我们为每个实体学习新的实体表示。然后,我们将这些新的实体表示输入到知识图谱的嵌入中,这是一种将实体和关系参数化为向量表示,同时保持知识图谱结构中关系推理的有效方法。
具体地说,我们使用了在知识图谱嵌入中广泛使用的平移评分函数[2]来训练知识图谱嵌入。当一个三元组(h,𝑟,𝑡)有效时,通过优化平移原则eh + e𝑟 ≈ e𝑡学习如何嵌入每个实体和关系,其中eh和e𝑡是来自MKGs注意层的新实体嵌入,e𝑟是关系嵌入。方程7表示三元组(h,𝑟,𝑡)的分数:
![]()
知识图谱嵌入的训练考虑了有效三元组和无效三元组之间的相对顺序,并通过成对的排名损失来鼓励对它们的区分:
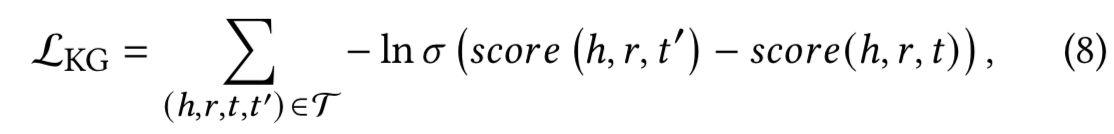
其中![]() ,(h,r,t')是通过随机替换有效三元组中的一个实体来构造得到的无效三元组。σ(.)是sigmoid函数。该层以三元组的粒度对实体和关系进行建模,作为正则化器并将直接连接注入到表示中,从而提高模型的表示能力。
,(h,r,t')是通过随机替换有效三元组中的一个实体来构造得到的无效三元组。σ(.)是sigmoid函数。该层以三元组的粒度对实体和关系进行建模,作为正则化器并将直接连接注入到表示中,从而提高模型的表示能力。
4.2 Recommendation
每个实体通过知识图谱嵌入模块得到相应的嵌入后,将其输入到推荐模块。与知识图谱嵌入模块类似,推荐模块也使用MKGs注意层聚合邻居实体信息。
为了保留1-𝑛跳信息,我们遵循[28]的设置,它保留了𝑙 层的候选user和item的输出。不同层的输出代表不同跳的信息。因此我们采用层聚合机制[31],将每一步的表示连接成单个向量,可以得到:
![]()
其中 || 为串联操作,𝐿为MKGs注意层数。通过这样做,我们不仅可以通过执行嵌入传播操作来丰富初始嵌入,而且可以通过调整𝐿来控制传播强度。
最后,我们通过等式10来做user和item表示的内积,来预测他们的匹配分数:
![]()
然后,我们通过使用Bayesian Personalized Ranking (BPR) loss [20]优化我们的推荐预测损失。具体来说,我们假设指示更多user偏好的观察到的记录应该比没观察到的记录被赋值更高的预测分数。BPR损失如等式11所示:

其中![]() 表示训练集,
表示训练集,![]() 表示user u 和 item i 之间被观察到的交互,
表示user u 和 item i 之间被观察到的交互,![]() 是采样的没观察到的交互集,σ(.)是一个sigmoid函数。Θ是参数集,λ是L2归一化的参数。
是采样的没观察到的交互集,σ(.)是一个sigmoid函数。Θ是参数集,λ是L2归一化的参数。
我们交替更新MKGs嵌入模块和推荐模块中的参数。特别地是,对于随机抽样的一个batch(h,𝑟,𝑡,𝑡'),我们更新所有实体的知识图谱嵌入。然后随机抽取一个batch(𝑢,𝑖,𝑗),从知识图谱嵌入中检索它们的表示。对两个模块的损失函数进行了交替优化。
5 EXPERIMENTS
在本节中,我们将使用两个来自不同领域的真实数据集来评估MKGAT模型。我们首先在5.1节介绍我们的实验设置,然后在5.2节讨论主要的实验结果。此外,我们还将在第5.3节进行详细的案例研究。
5.1 Experimental Setup
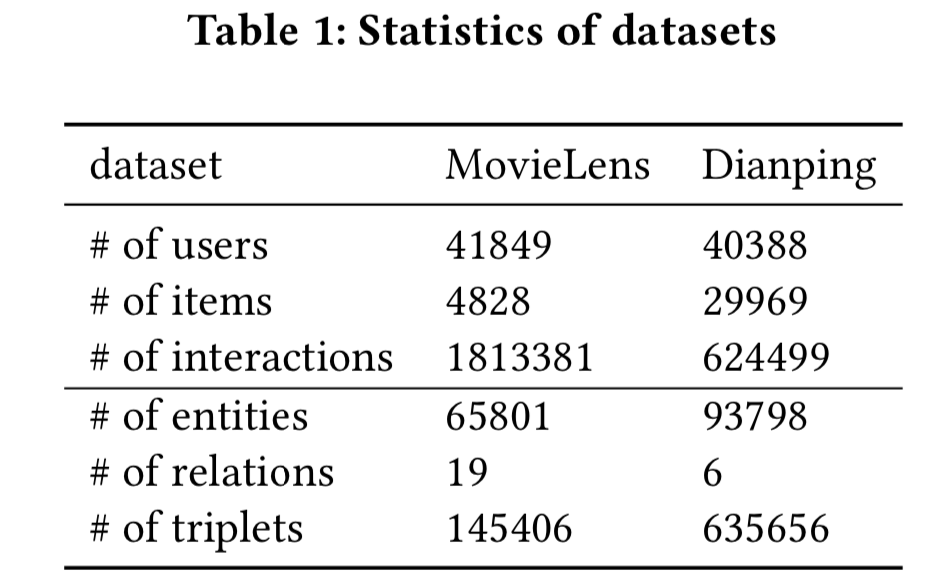
5.1.1 数据集。我们使用来自电影和餐馆领域的两个推荐数据集进行实验。具体内容如下。
- MovieLens (https://grouplens.org/datasets/movielens/)。该数据集已被广泛用于评估推荐系统。它由MovieLens网站上明确的评分(从1到5)组成。在我们的实验中,我们使用MovieLens-10M数据集。我们将评级转换为隐式反馈数据,其中每个条目标记为1,表示用户已经对该项目进行了评级,如果未评级则标记为0。MovieLens数据集的知识图谱来自[26],[26]使用Microsoft Satori为该数据集构建知识图谱。[26]首先从整个知识图谱中选取置信水平大于0.9的一个三元组子集。给定 子KG,[26]通过将所有有效电影的名字与三元组的tail匹配,收集所有有效电影的Satori IDs。[26]在获得item IDs集后,将这些item IDs与Satori 子KG 中所有三元组的head进行匹配,并选择所有匹配良好的三元组作为每个数据集的最终KG。为了构建MovieLens知识图谱的图像实体,我们抓取的是相应的预告片,而不是Youtube上的全长视频。我们使用FFmpeg(http://ffmpeg.org/ )抽取每个trailer中的关键帧,使用预训练后的ResNet50[6]模型从关键帧中抽取视觉特征。为了构建MovieLens知识图谱的文本实体,我们从TMDB(https://www.themoviedb.org/ )中爬取相关的电影评价。
- Dianping(大众点评, https://www.dianping.com/),中国的生活信息服务网站,用户可以在这里搜索和获取餐馆信息。大众点评由美团-大众点评集团提供,其中积极互动的类型包括购买、添加收藏。我们对每个用户的负面互动进行采样。大众点评的知识图谱来源于美团Brain,这是美团点评集团为餐饮娱乐构建的内部知识图谱。实体的类型包括POIs(即餐厅)、一级和二级类别、业务领域和标记。为了构建大众点评数据集知识图谱的图像实体,我们选择了POIs中排名靠前的菜品图像。与MovieLens数据集类似,我们使用预训练的ResNet50[6]模型从推荐菜肴的图像中提取视觉特征。为了构建大众点评知识图谱的文本实体,我们对每个POIs使用用户评论。
两个数据集的统计数据如表1所示。
5.1.2 评估指标。对于测试集中的每个用户,我们将未与用户交互的项视为负项。然后,每个方法输出用户对所有项目(除了训练集中的正项)的偏好得分。我们随机选择20%的交互作为测试的ground truth,其余的交互作为训练。为了评价top-𝑘推荐和偏好排名的有效性,我们采用了两个常用的评价指标:𝑟𝑒𝑐𝑎𝑙𝑙@𝑘和𝑛𝑑𝑐𝑔@𝑘。𝑘默认值为20。我们报告测试集中所有用户的平均结果。
5.1.3 基线。我们将我们提出的MKGAT模型与一些最先进的基线进行了比较,包括基于FM的方法(NFM),基于KG的方法(CKE, KGAT),多模态方法(MMGCN)。
- NFM: Neural Factorization Machines (NFM) [7]是最先进的因子分解机器(FM),它将FM纳入神经网络。特别地是,我们如[7]中所建议的在输入特性上使用一个隐藏层。
- CKE: 基于嵌入的协同知识(Collaborative Knowledge Base Embedding, CKE)[35]将协同过滤(Collaborative Filtering, CF)与结构化知识、文本知识和可视化知识结合在一个统一的推荐框架中。本文将CKE实现为CF +结构化知识模块。
- KGAT: Knowledge Graph Attention Network (KGAT)[28]首先应用TransR模型[13]获得实体的初始表示。然后,它从实体本身向外运行实体传播。这样,用户表示和项表示都可以用相应的邻居信息来丰富。
- MMGCN: Multi-modal Graph Convolution Network [29]是一种最先进的多模式模型,它考虑每个模式的个人user-item交互。MMGCN为每个模态构建user-item二分图,然后使用GCN对每个二分图进行训练,最后将不同模态的节点信息进行合并。
5.1.4 参数设置。我们使用Xavier初始化器[4]来初始化模型参数,并使用Adam优化器[9]来优化模型。mini-batch 大小和学习率分别在[1024;5120;10240]和[0:0001;0:0005;0:001]中选取。推荐组件和知识图谱嵌入组件的MKGAT层的数量在[1;2;3]三者中选取。对于视觉实体,我们使用Resnet最后一层隐藏层的2048维特征。对于文本实体,我们使用word2vec[16]训练300维的词嵌入,使用SIF[1]算法生成相应的句子向量。最后,我们将所有实体的维度设置为64。
5.2 Experimental Results
我们首先报告了所有方法的性能,然后研究了不同因素(即模式、模型深度和组合层)对模型的影响。
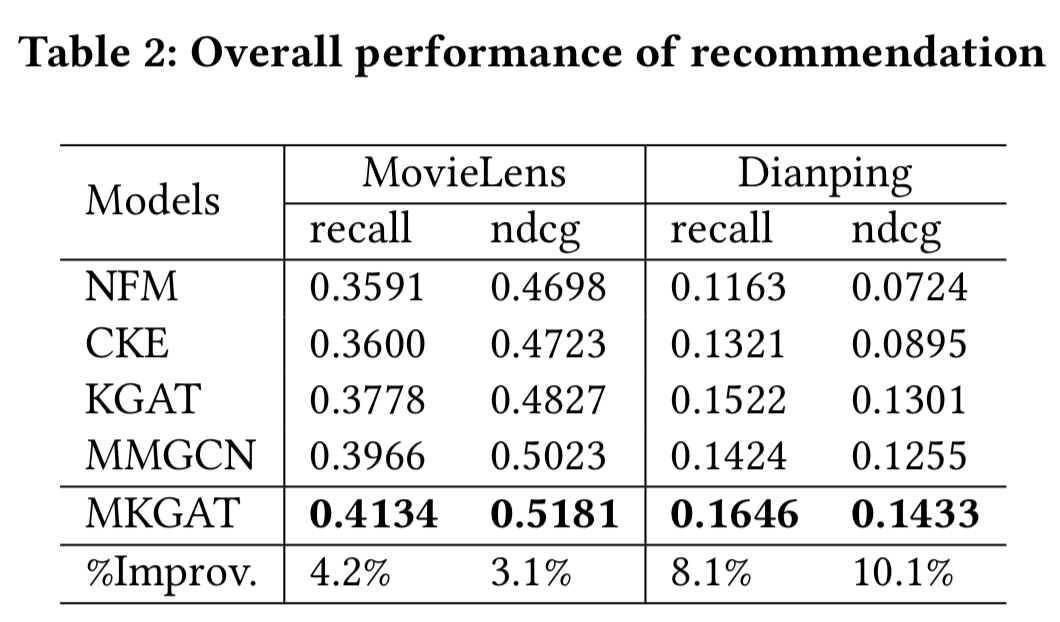
5.2.1所有方法的性能。所有模型的结果如表2所示。我们可以看到我们提出的MKGAT模型 (其中的模式包括结构化知识、文本和视觉;知识图谱部分和推荐部分的模型深度设置为2;组合层设置为Add聚合层) 在𝑟𝑒𝑐𝑎𝑙𝑙和𝑛𝑑𝑐𝑔两个数据集上都优于所有基线。此外,我们有以下观察。
- MKGAT始终在两个数据集上产生最佳性能。特别是,MKGAT在MovieLens和大众点评中分别比最强的基于KG的基线KGAT在ndcg@20方面提高了7.33%、10.14%和在recall@20方面提高了9.42%和8.15%。验证了多模式知识图谱的有效性。结合表2和表3,在引入多模态实体的情况下,我们的方法比其他基于kg的方法有更大的改进。这验证了我们的方法比其他方法对多模态信息更友好。
- 在所有的比较方法中,基于KG的方法(即CKE和KGAT)在两个数据集上优于基于CF的方法(即NFM),这表明使用KG确实大大提高了推荐性能。
- 通过比较两种基于KG的方法CKE和KGAT的性能,我们发现KGAT在两种指标上都比CKE有更好的性能,这说明了图卷积网络在推荐系统中的强大作用。
- 值得一提的是,MKGAT可以在MovieLens数据上击败MMGCN模型,这是一种最先进的多模式推荐方法。这表明我们的方法可以合理地利用多模态信息。
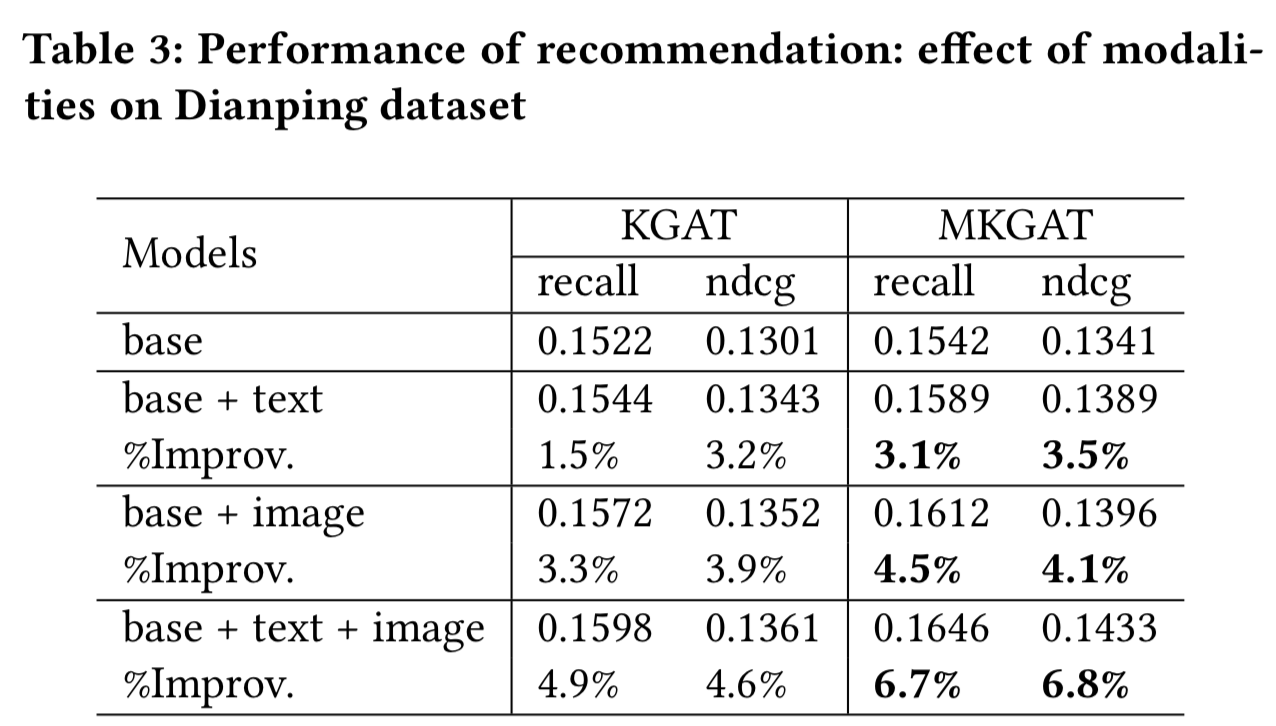
5.2.2 模式的影响。为了探讨不同模式的影响,我们比较了KGAT和我们的MKGAT模型在大众点评数据集上不同模式的结果。性能对比结果见表3。我们有以下几点看法:
- 正如预期的那样,在KGAT和MKGAT中,具有多模态特征的方法优于具有单模态特征的方法,如表3所示。
- 视觉模态在推荐效果中比文本模态更重要,因为用户在在线平台上浏览餐厅信息时,视觉信息(如图片)更容易引起用户的注意。
- 我们的MKGAT模型也是一种基于KG的方法,与KGAT相比,MKGAT模型可以更好地利用图像信息提高推荐性能。换句话说,与其他基于KG的方法相比,当引入多模态信息时,我们的方法会有更大的改进。这是因为在训练知识图谱嵌入时,MKGAT能更好地将图像实体的信息聚合成item实体,如表3所示。
5.2.3 模型深度的影响。为了评估分层叠加的有效性,我们对不同数量的层进行了实验。层数作为模型的深度。在我们的模型中,知识图谱嵌入和推荐组件都使用了MKGAT层,因此我们分别讨论了知识图谱嵌入组件和推荐组件。在知识图谱嵌入部分,我们将MKGAT推荐层数固定为2层。在讨论推荐部分时,我们将知识图谱嵌入的MKGAT层数固定为2层。实验结果如表4所示。
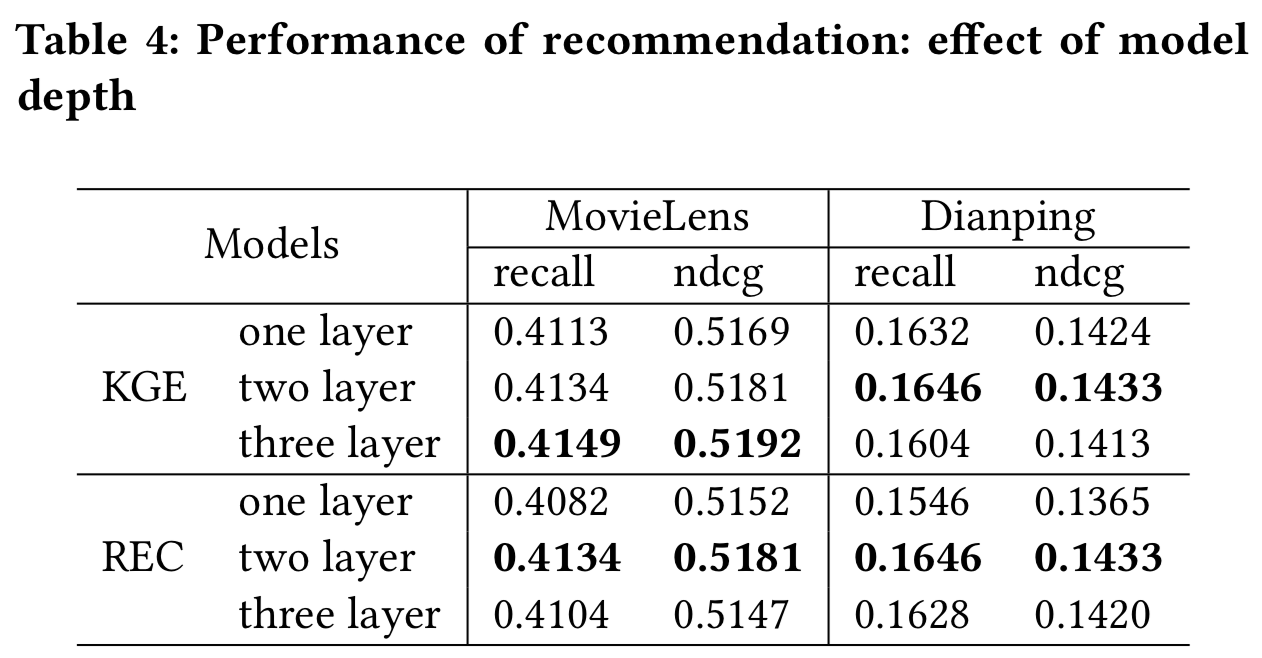
不同模型深度(即不同的MKGAT层数)对知识图谱嵌入(记为KGE)和推荐(记为REC)的影响可以总结为:
- 对于知识图谱嵌入,在MovieLens数据集中,随着MKGAT层数的增加,评价指标(即recall和ndcg)也会增加。证明了邻域信息融合在知识图谱嵌入中的有效性。在大众点评数据集中,随着MKGAT层数的增加,评价指标先增加后减少。这可能是由于大众点评数据的多跳信息相对稀疏造成的。结合结果在表3中,我们可以看到,我们的方法(在做知识图谱嵌入时考虑邻居的实体信息)可以为推荐提供更高质量的实体嵌入, 而这些方法(例如,KGAT)仅考虑知识图独立实体三元组。
- 在推荐部分,随着MKGAT层数的增加,评价指标首先在两个数据集中增长,验证了不同跳数的知识图谱嵌入对推荐系统是有帮助的。但是,当两个数据集中的层数大于2时,评价指标会下降。换句话说,当层的数量增加到某个级别时,评估指标就会下降。这可能是由于数据的稀疏性导致的过拟合。
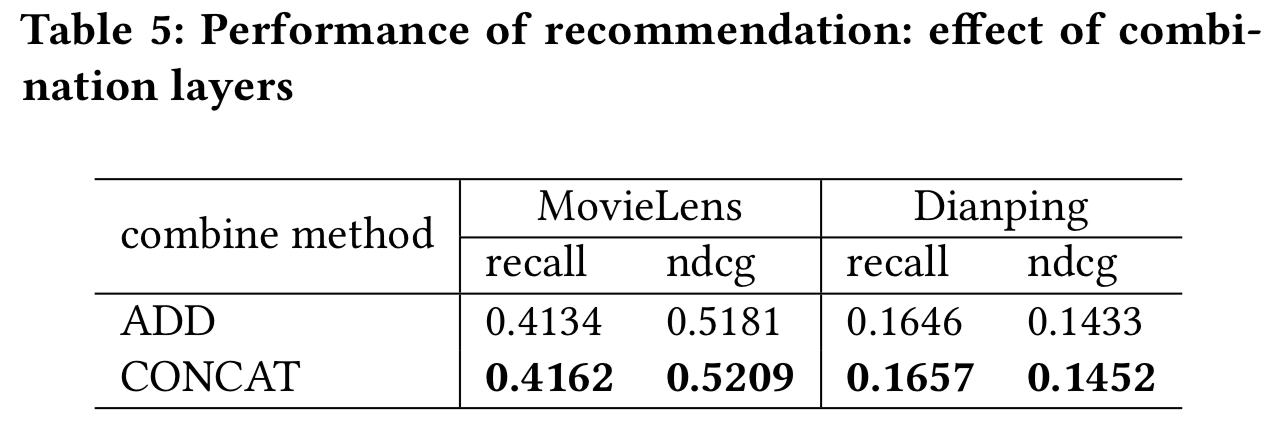
5.2.4 组合图层的效果。在这组实验中,我们研究了组合层在我们的模型中的作用。具体来说,我们使用两种类型的聚合层,即Add层和Concatenate层来学习知识图谱的嵌入。模型深度固定为2。实验结果如表5所示,用CONCAT标记的层连接方法优于用ADD标记的层连接方法。一个可能的原因是,每个实体的相邻实体包含文本和可视化信息,这些信息与知识图中的一般实体是异构的。它们不在同一个语义空间中。ADD实际上是一种元素与元素的特征交互方法,适用于相同语义空间中的特征。因为在相同的语义空间中,每个特征的每个维度的含义是相同的,所以把每个特征的每个维度相加是有意义的。而CONCAT是特征之间维度的扩展,更适合不同语义空间中特征的交互。
5.3 Case study
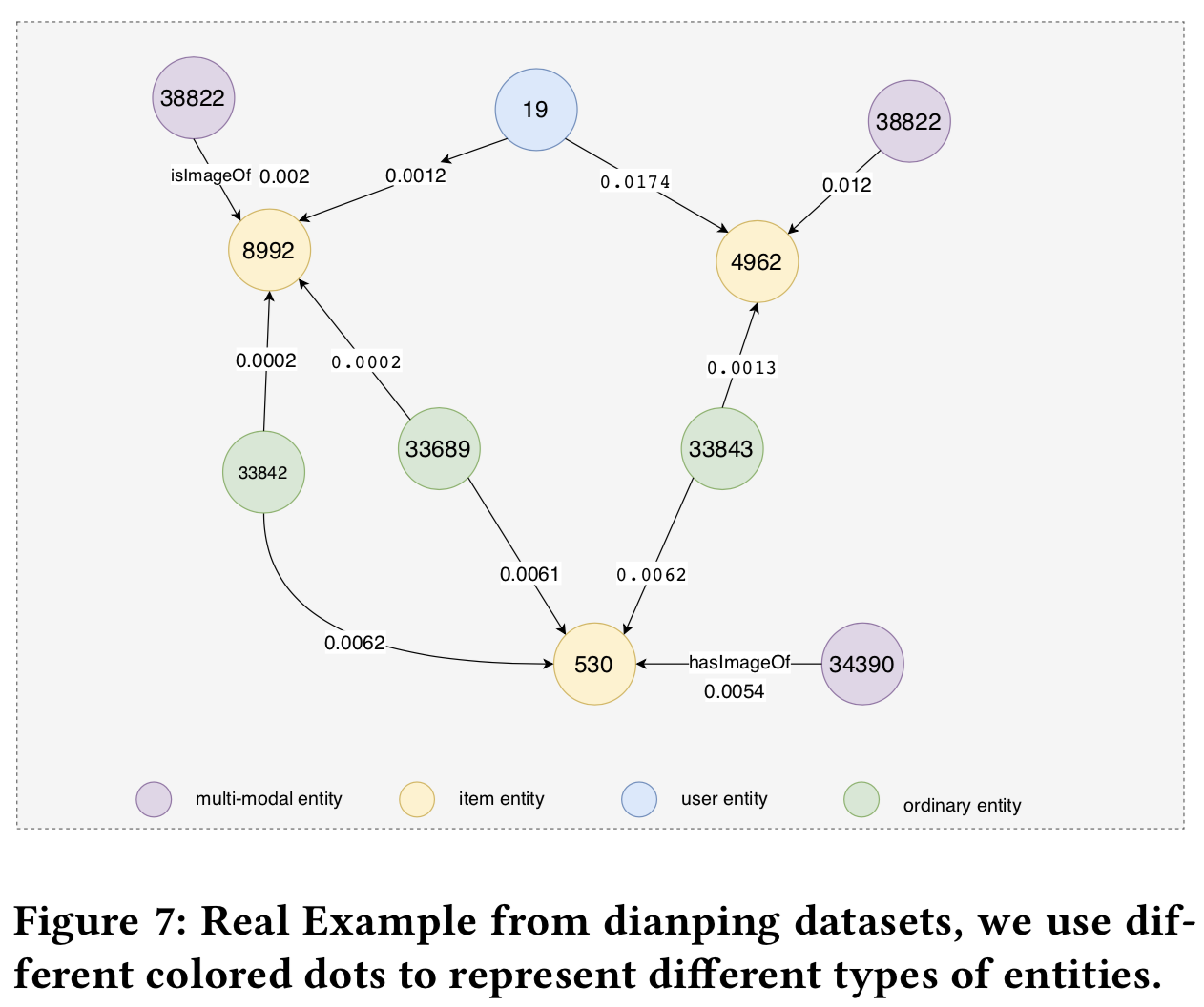
为了直观地展示多模态实体在MKGAT模型中的作用,我们给出了一个案例研究,从大众点评数据集中随机选择一个用户𝑢和一个相关item。得益于注意机制,我们可以计算候选items与实体(或items与users)之间的关联分数(非规范化)。我们还可以观察每个实体与其他实体之间的关联分数。相关性分数越高,模型认为当前实体对模型的影响越大。我们在图7中可视化了相关分数。
在图7中,对于item实体(即item实体8992,4962和530),它们的相邻实体包括多模态实体和非多模态实体(交互或普通KG实体)。我们可视化每个item实体及其相邻实体的边缘权重,如图7所示。在协同知识图谱中,多模态关系通常具有较高的关联评分,表明多模态实体的重要性。
6 CONCLUSION AND FUTURE WORK
本文提出了一种基于知识图谱的推荐模型——叫做多模态知识图谱注意网络(multimodal Knowledge Graph Attention Network, MKGAT),它创新性地将多模态知识图谱引入到推荐系统中。MKGAT模型通过学习实体之间的推理关系,并将每个实体的相邻实体信息聚合到自身,可以更好地利用多模态实体信息。在两个真实数据集上的大量实验证明了我们提出的MKGAT模型的合理性和有效性。
本文对多模态知识图谱在推荐系统中的应用进行了初步探索,并在此基础上进行了进一步有趣的研究。例如,在多模态知识图谱的框架下,自然会探索更多的多模态融合方式,如Tensor Fusion Network(TFN)[34]或Low-rank Multimodal Fusion(LMF)[14]。

